






HIVE中的数据模型
-
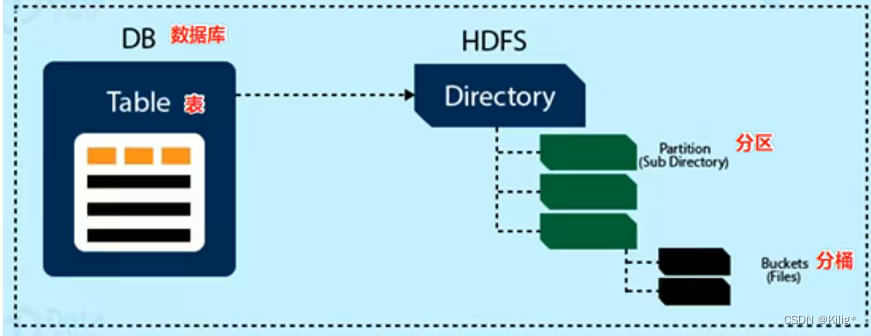
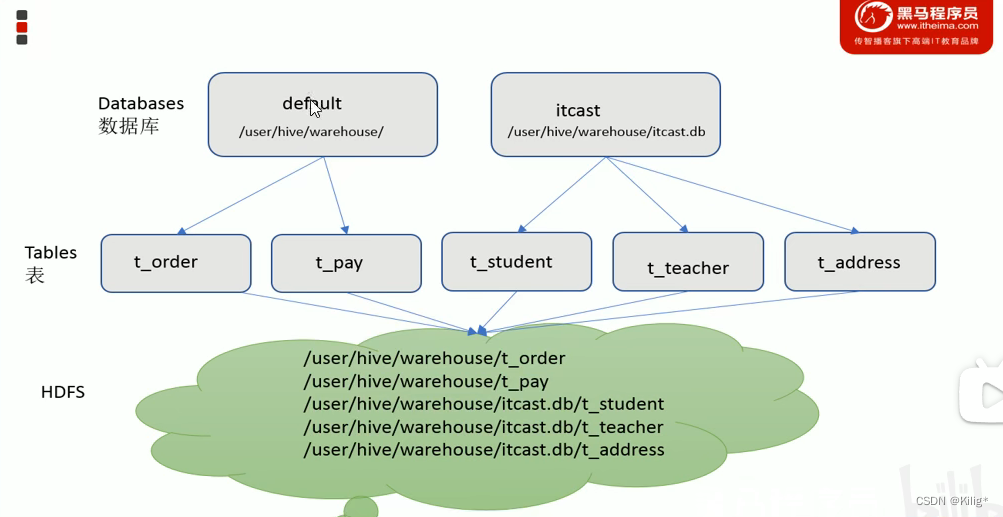
Table-表
-
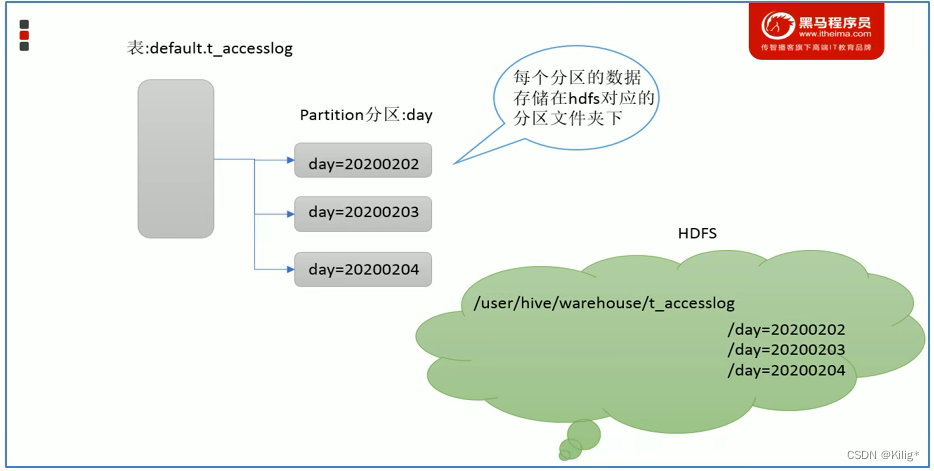
Partition-分区
HIVE的一种优化手段,根据分区列(比如日期“day”)的值将表划分为不同分区,可以提高查询效率。各个分区以子文件夹的形式存在。一个文件夹表示一个分区
-
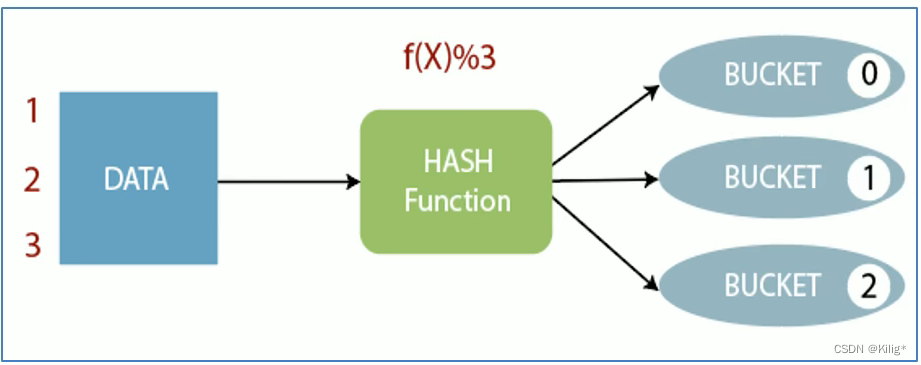
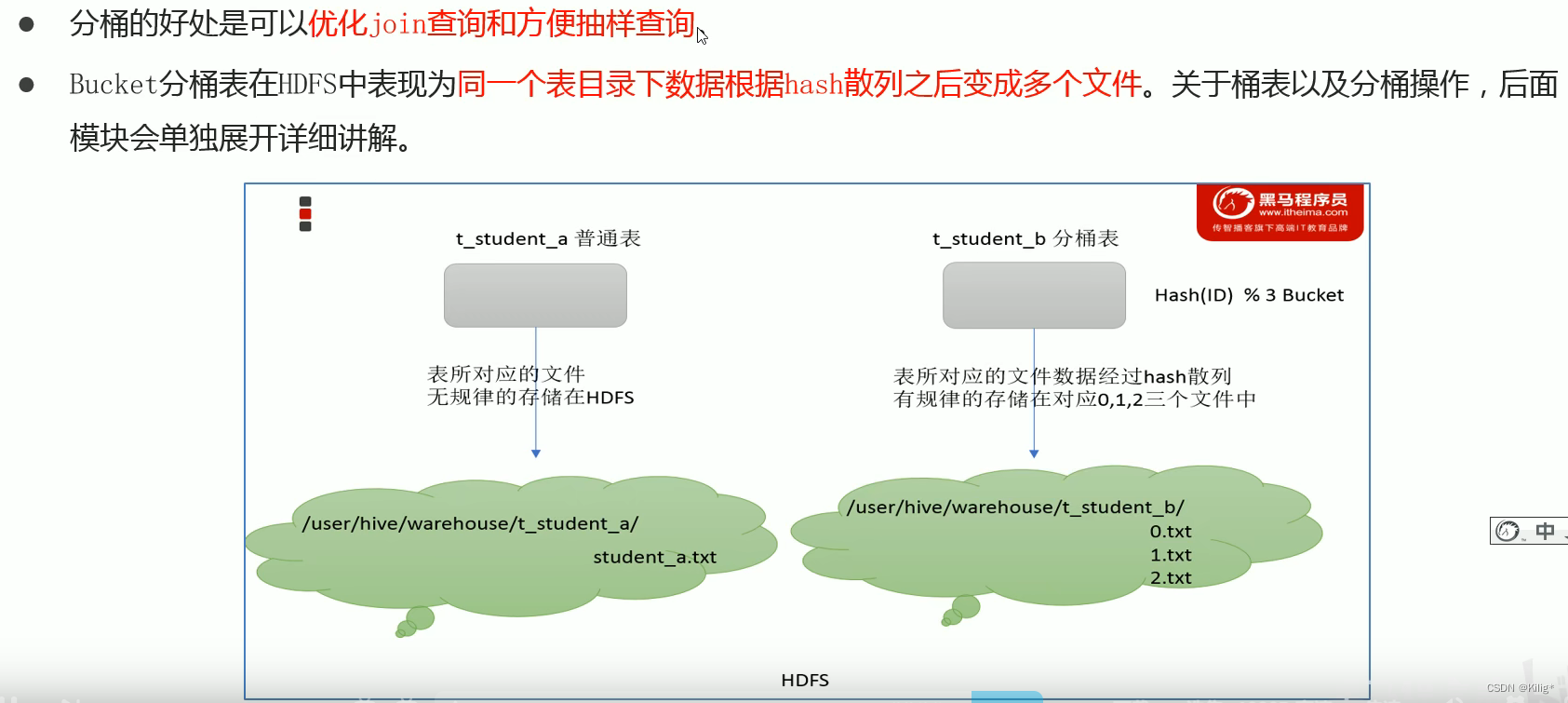
Bucket-分桶
HIVE的一种优化手段,根据表中的字段,比如“编号ID”经过Hash计算将数据继续划分为若干个小文件。
分桶与不分桶的对比
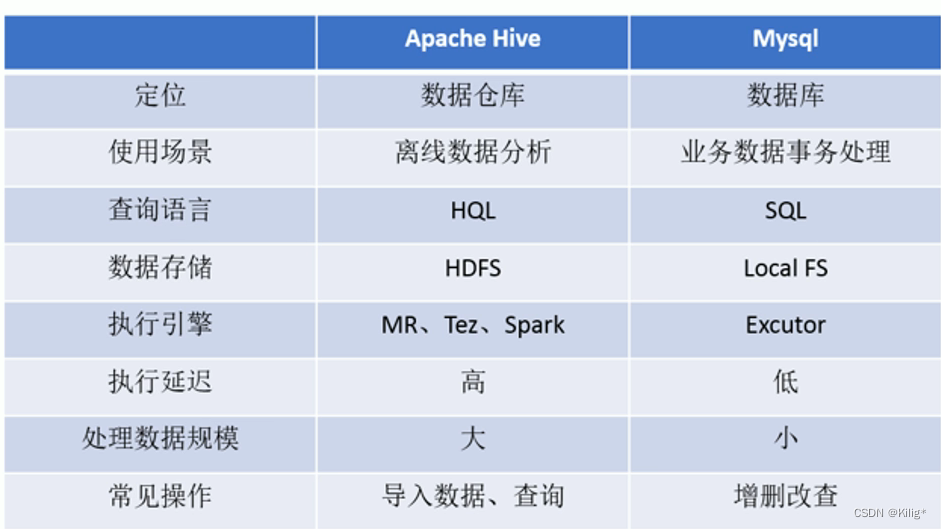
HIVE与MySQL的对比
HIVE是做海量数据的离线分析是OLAP,而SQL是OLTP
OLAP和OLTP对比
 HIVE利用分区和分桶来优化大规模数据的处理,分区通过日期等列将表划分为不同部分,提高查询效率,表现为子文件夹结构。分桶则是基于特定字段的Hash计算,进一步细化数据存储,便于数据分析。与MySQL比较,HIVE专注于海量数据的离线分析(OLAP),而MySQL更适合在线事务处理(OLTP)。
HIVE利用分区和分桶来优化大规模数据的处理,分区通过日期等列将表划分为不同部分,提高查询效率,表现为子文件夹结构。分桶则是基于特定字段的Hash计算,进一步细化数据存储,便于数据分析。与MySQL比较,HIVE专注于海量数据的离线分析(OLAP),而MySQL更适合在线事务处理(OLTP)。
Table-表
Partition-分区
HIVE的一种优化手段,根据分区列(比如日期“day”)的值将表划分为不同分区,可以提高查询效率。各个分区以子文件夹的形式存在。一个文件夹表示一个分区
Bucket-分桶
HIVE的一种优化手段,根据表中的字段,比如“编号ID”经过Hash计算将数据继续划分为若干个小文件。
分桶与不分桶的对比
HIVE是做海量数据的离线分析是OLAP,而SQL是OLTP
OLAP和OLTP对比
 486
2242
1758
693
486
2242
1758
693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言






























