




视频讲解1:Bilibili视频讲解
视频讲解2:https://www.douyin.com/video/7592511338140683535
论文下载:[2211.08217] A Low-Shot Object Counting Network With Iterative Prototype Adaptation
代码下载:https://github.com/djukicn/loca
https://github.com/KeepTryingTo
基于Zero-Shot的计数算法详解(T2ICount: Enhancing Cross-modal Understanding for Zero-Shot Counting)
统一的人群计数训练框架(PyTorch)——基于主流的密度图模型训练框架
算法VLCount详解(VLCounter: Text-aware Visual Representation for Zero-Shot Object Counting)
人群计数中常用数据集的总结以及使用方式(Python/PyTorch)
基于Zero-Shot的目标计数算法详解(Open-world Text-specified Object Counting)
基于zero-shot目标计数方法详解(Zero-Shot Object Counting)
基于Transformer的目标统计方法(CounTR: Transformer-based Generalised Visual Counting)
基于zero-shot目标统计算法详解(Zero-shot Object Counting with Good Exemplars)
开发词汇的目标计数COUNTGD:Multi-Modal Open-World Counting算法详解
Class-Agnostic Counting类别无关的统计算法讲解
基于无监督backbone无需训练的类别无关目标统计CountingDINO算法详解
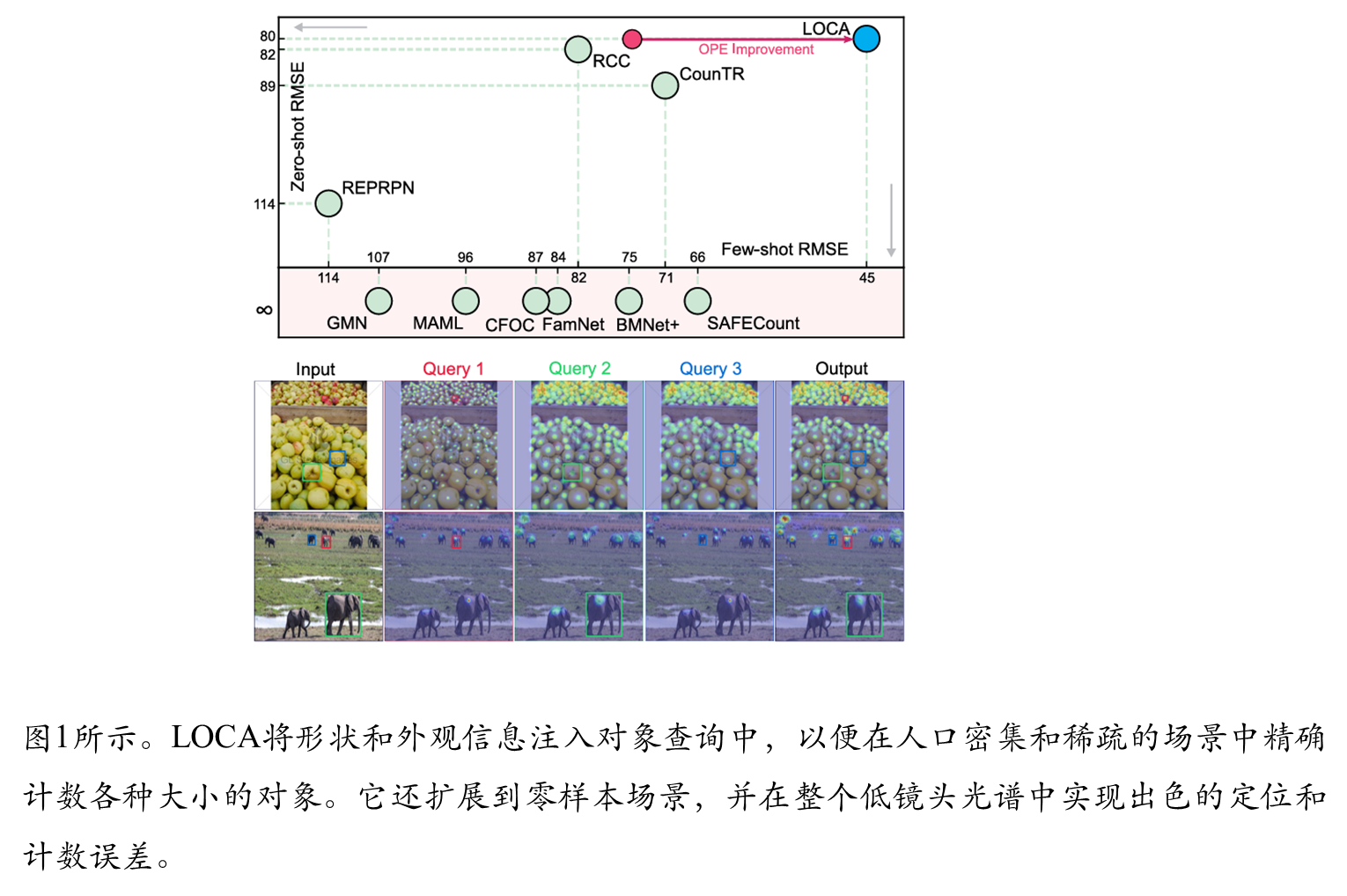
本文提出了一种低样本目标计数网络LOCA,通过迭代原型自适应方法解决现有计数算法忽略形状信息导致定位不准的问题。针对现有方法(如GMN、FamNet)通过特征池化丢失物体尺寸/长宽比信息、原型泛化能力有限等缺陷,LOCA创新性地分离处理示例的形状和外观信息。网络采用ResNet-50骨干提取特征,通过目标原型提取模块显式编码形状信息,再经深度互相关匹配生成响应图,最终回归为密度图实现计数。实验表明该方法在保持简洁架构的同时,有效提升了高密度场景和尺寸变化情况下的计数精度。论文代码已开源,为类别无关的统计算法研究提供了新思路。
目录

现有方法的局限性
忽略形状信息,导致定位不准:现有方法(如GMN, FamNet, CFOCNet等)通常通过特征池化 来从示例的边界框中提取固定大小的物体原型。这个过程是形状无关的,因为它将不同尺寸和长宽比的示例对象都池化到相同大小的特征图上。这导致了关键的物体形状信息(如尺寸、长宽比)的丢失。
原型泛化能力有限:由于形状信息的缺失,提取出的物体原型在图像中进行匹配时,定位精度会下降。这在高密度场景或物体尺寸变化大的情况下尤为明显,最终影响计数的准确性。
方法复杂化倾向:为了弥补上述缺陷,一些近期工作(如BMNet+)试图通过设计复杂的架构来学习非线性的相似度度量函数,但这增加了模型的复杂性和计算开销
提出的方法
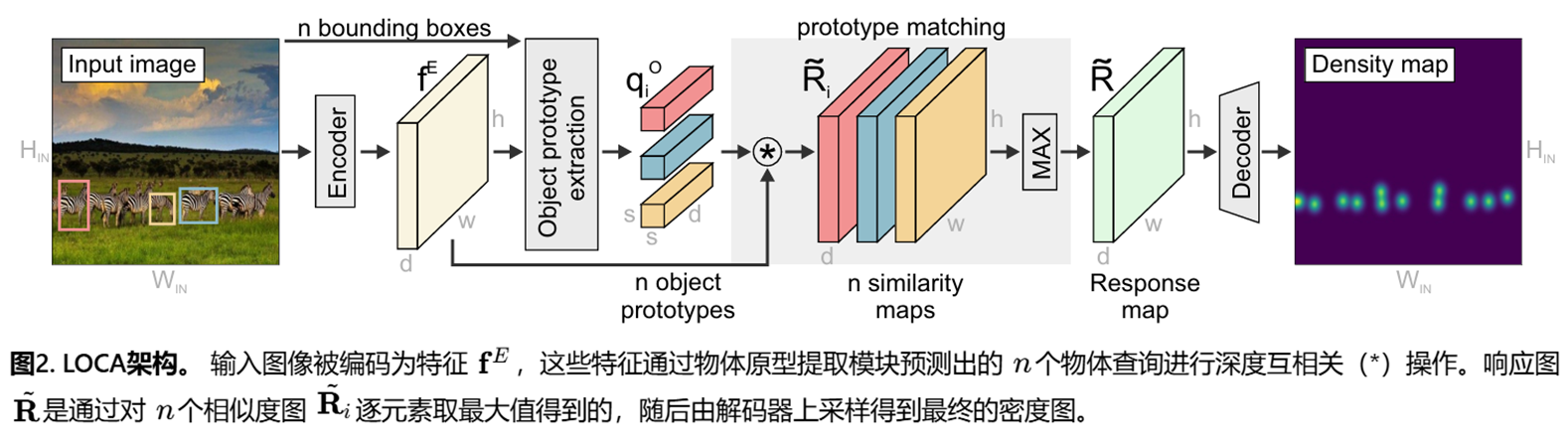
图像特征提取:使用ResNet-50 backbone和全局自注意力块提取图像特征。
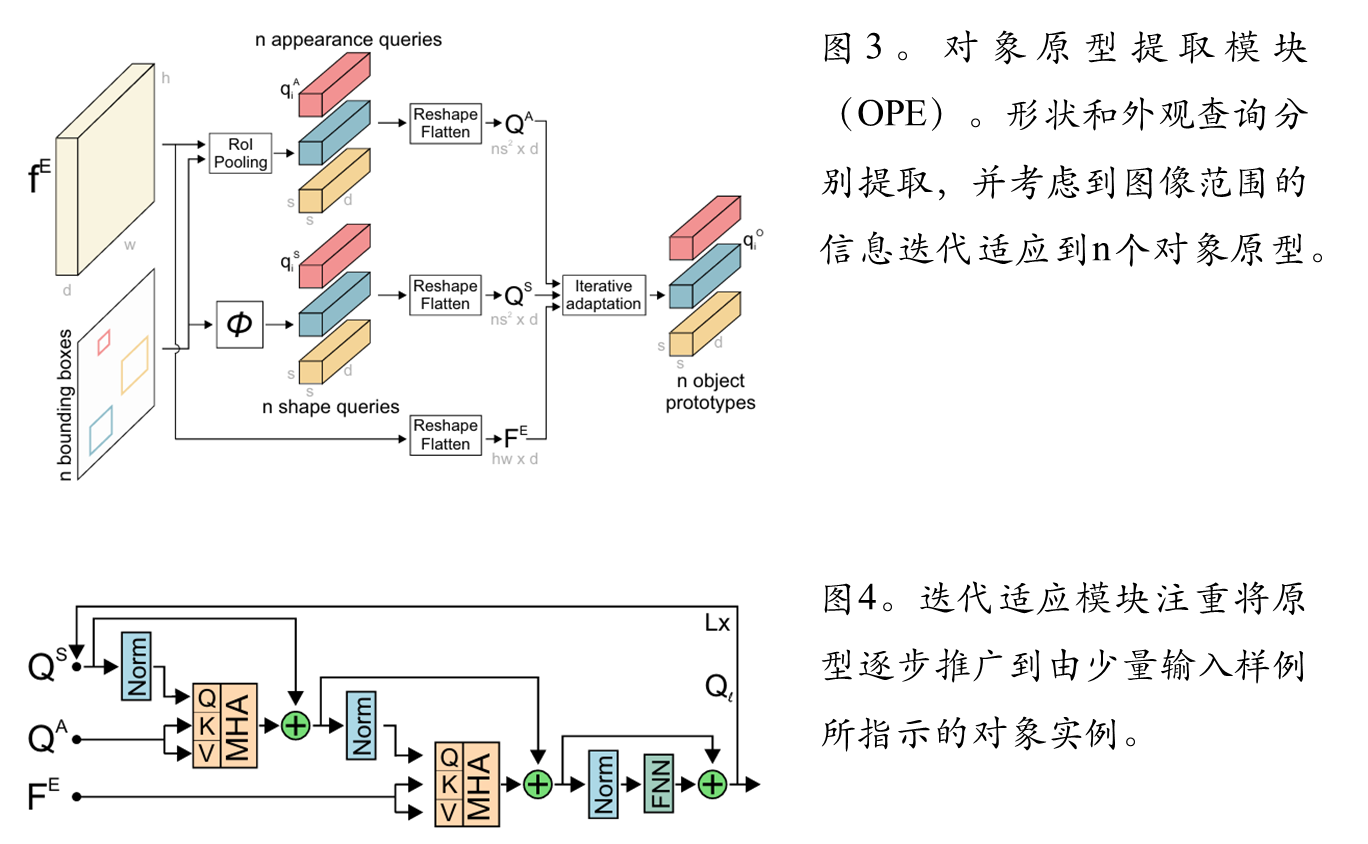
物体原型提取:这是本文的主要贡献。该模块显式地、分别地处理示例的形状和外观信息。
原型匹配:将学习到的物体原型与图像特征进行深度互相关,得到相似性响应图。
密度图回归:通过一个解码器将响应图上采样为最终的密度图,求和即得物体数量。
具体方法

目标原型提取模块

自适应到zero-shot中

损失函数

模型结构细节配置
LOCA将输入图像的大小调整为H_IN = W_IN = 512像素,并应用swv[5]预训练的ResNet50骨干,将最后三个块的特征上采样到h = w = 64像素。这就产生了一个有3584个通道的激活图,通过一个1 × 1的卷积层进一步投影到d = 256个通道。全局自关注块是一个3层的变压器编码器。MHA模块由8个注意头组成,隐藏维数d = 256,而FFN的隐藏维数为1024。每个MHA和FFN模块后应用Dropout,概率为0.1。迭代自适应模块包含L = 3层,具有相同的MHA和FFN维度。对象原型空间大小为s × s, s = 3,不使用dropout。ground truth真密度图是通过在物体位置上放置单元密度并使用高斯核平滑生成的,高斯核的大小是为每个图像单独确定的。特别是,内核大小被确定为样例边界box平均大小的1/8。
实验结果
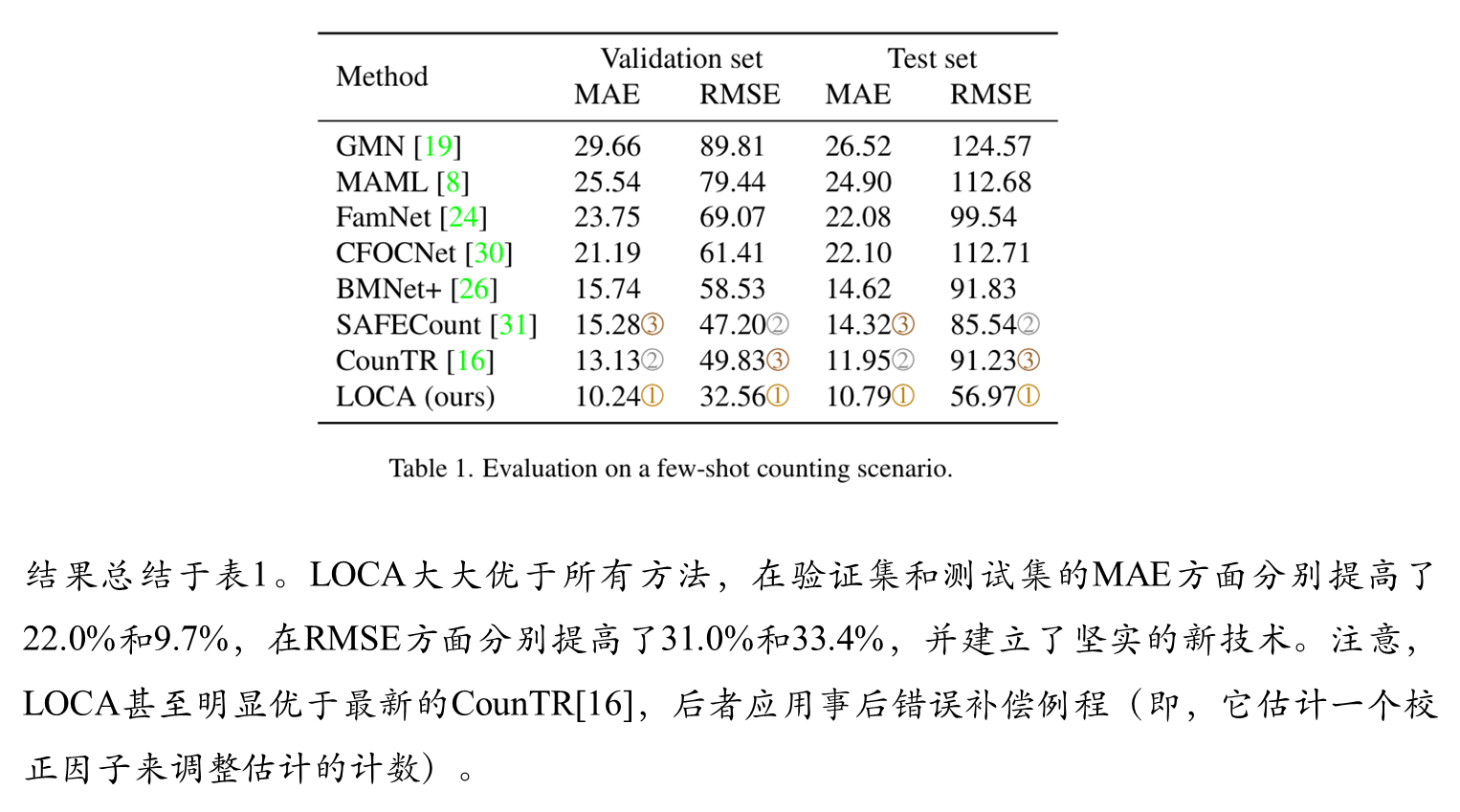
综合比较
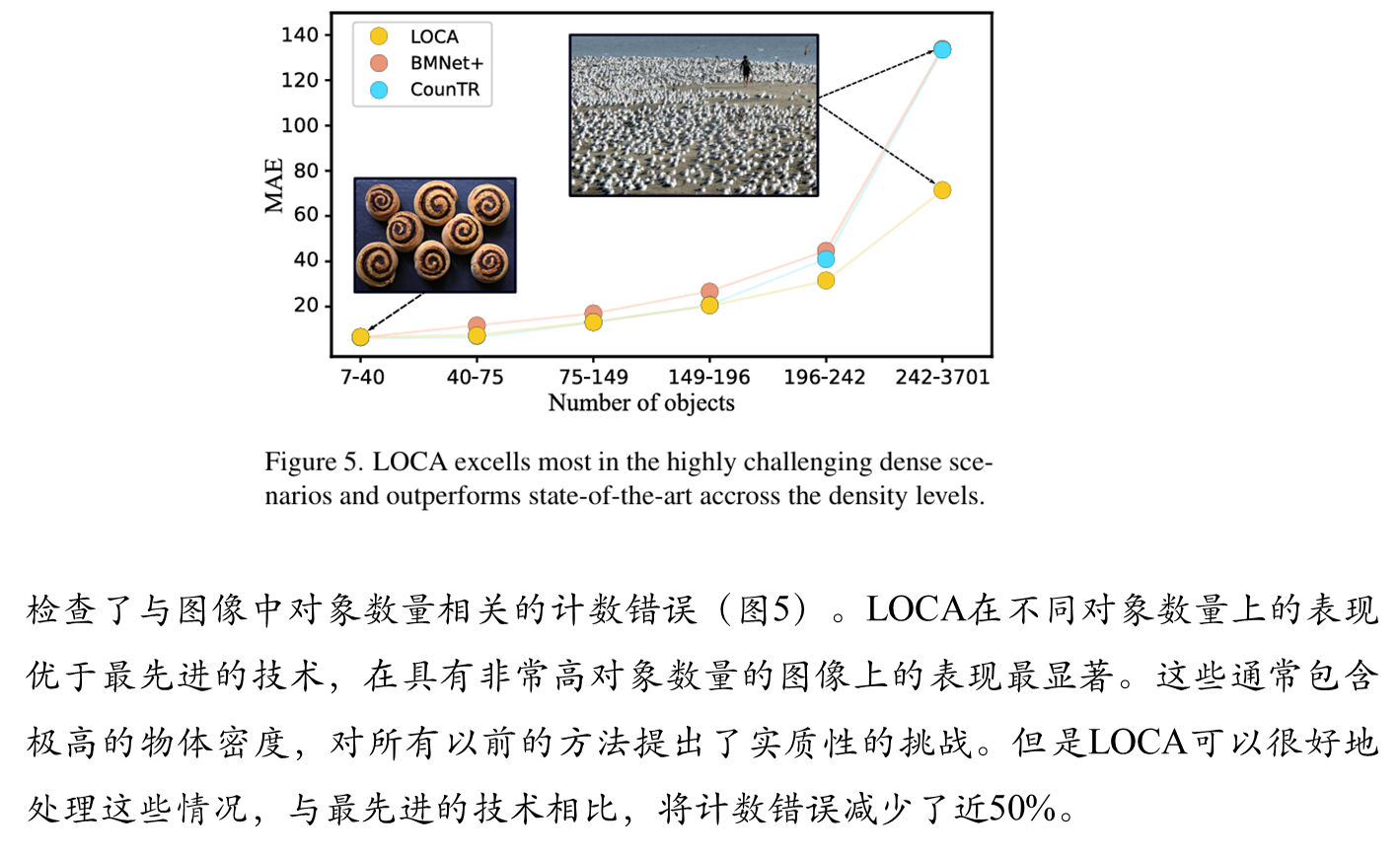
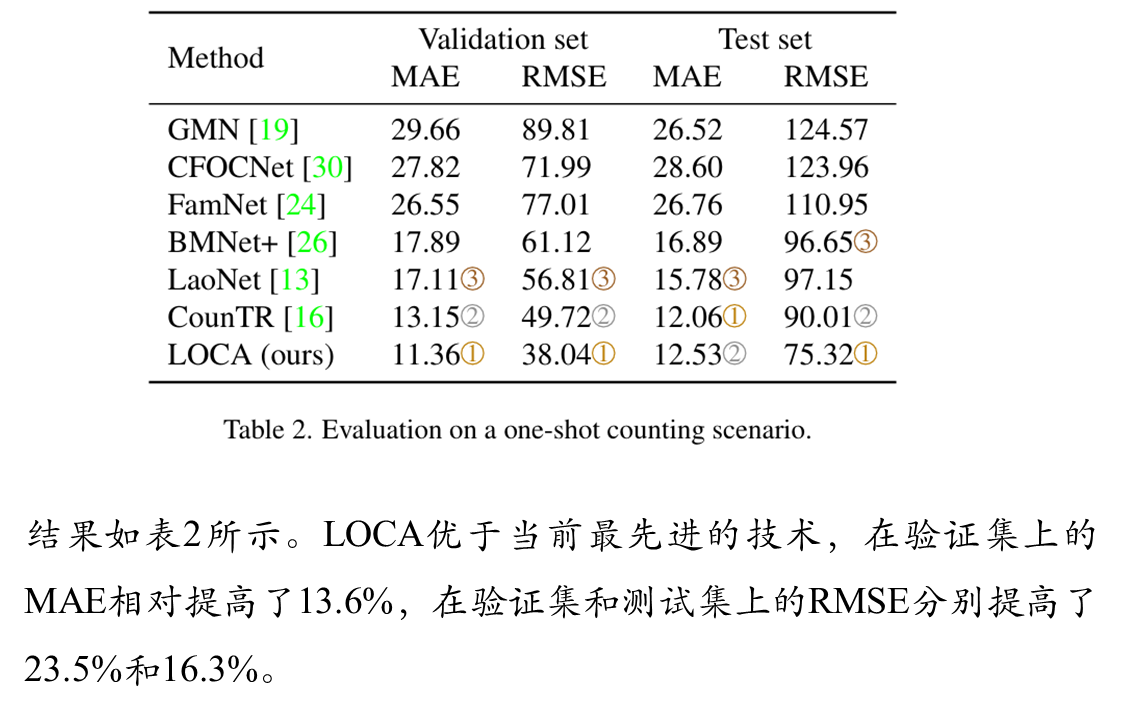
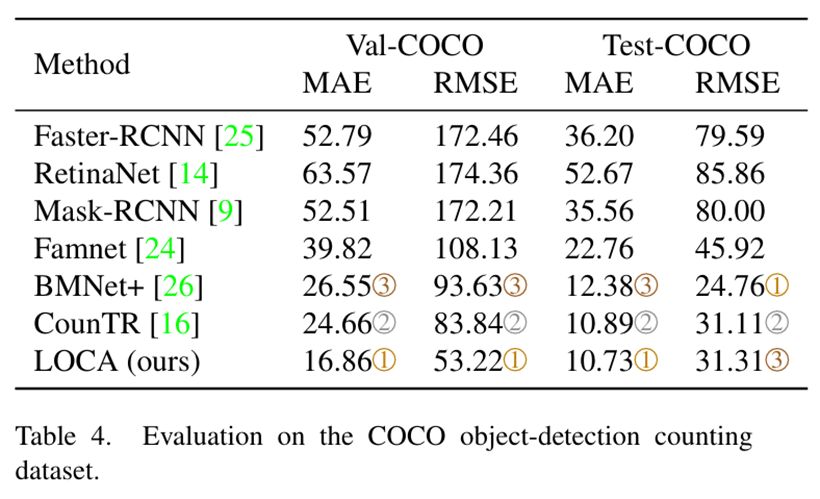
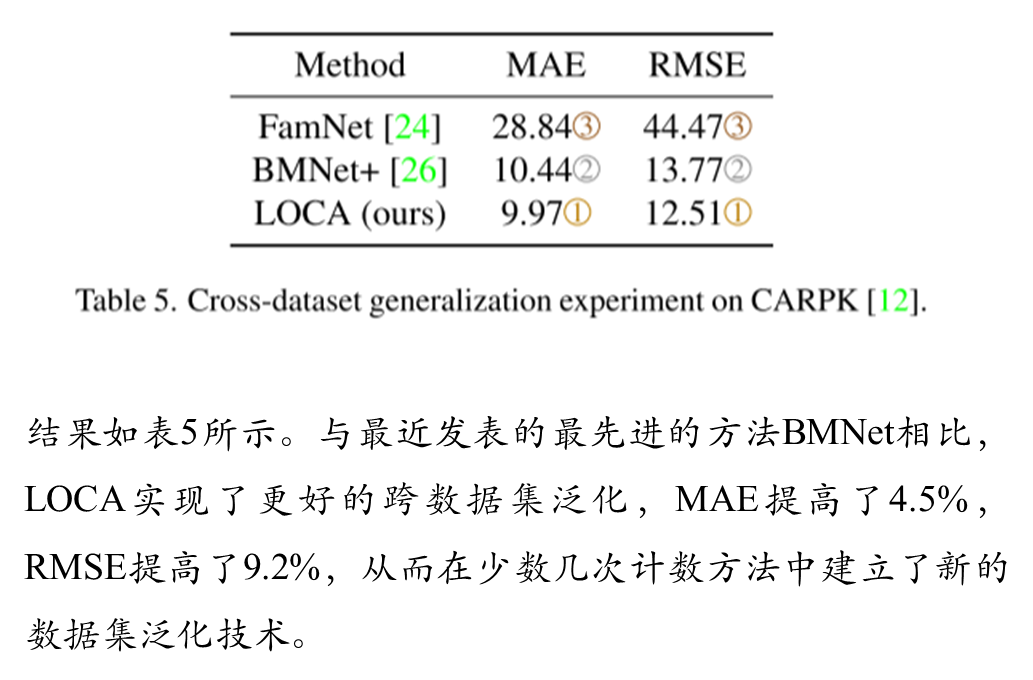
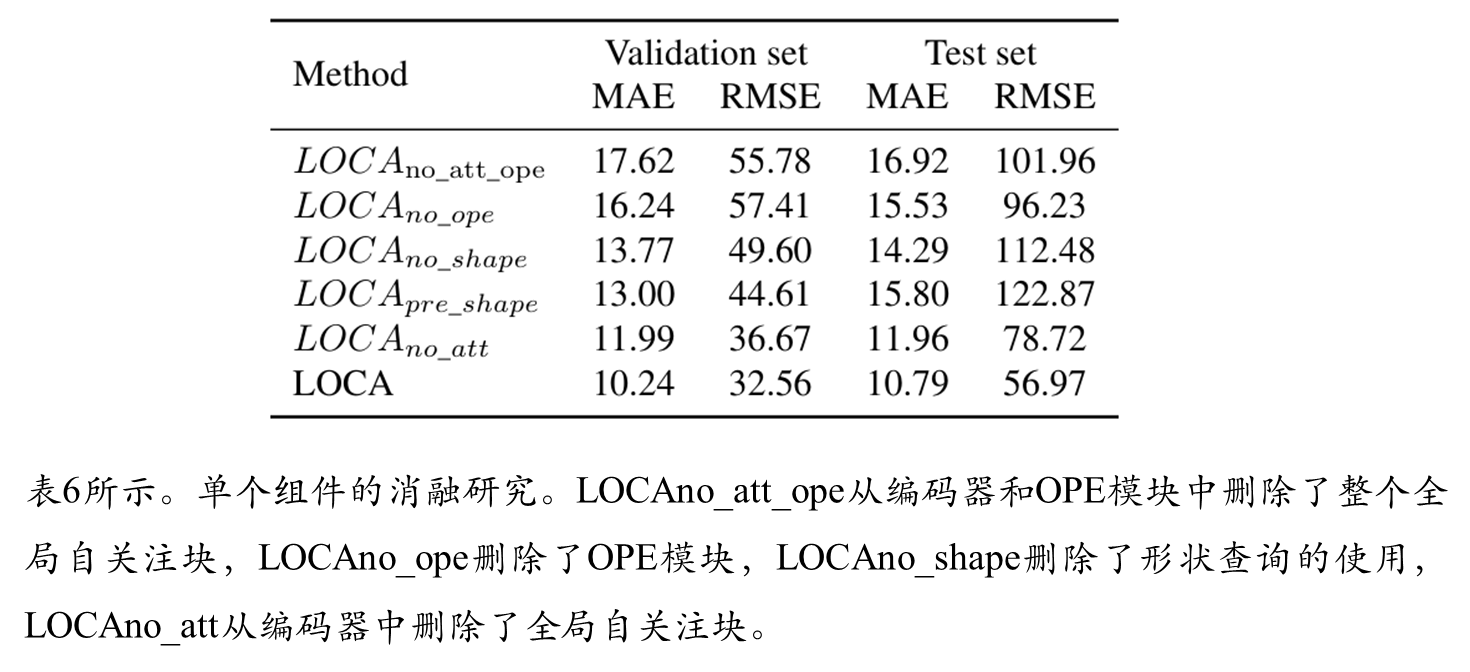
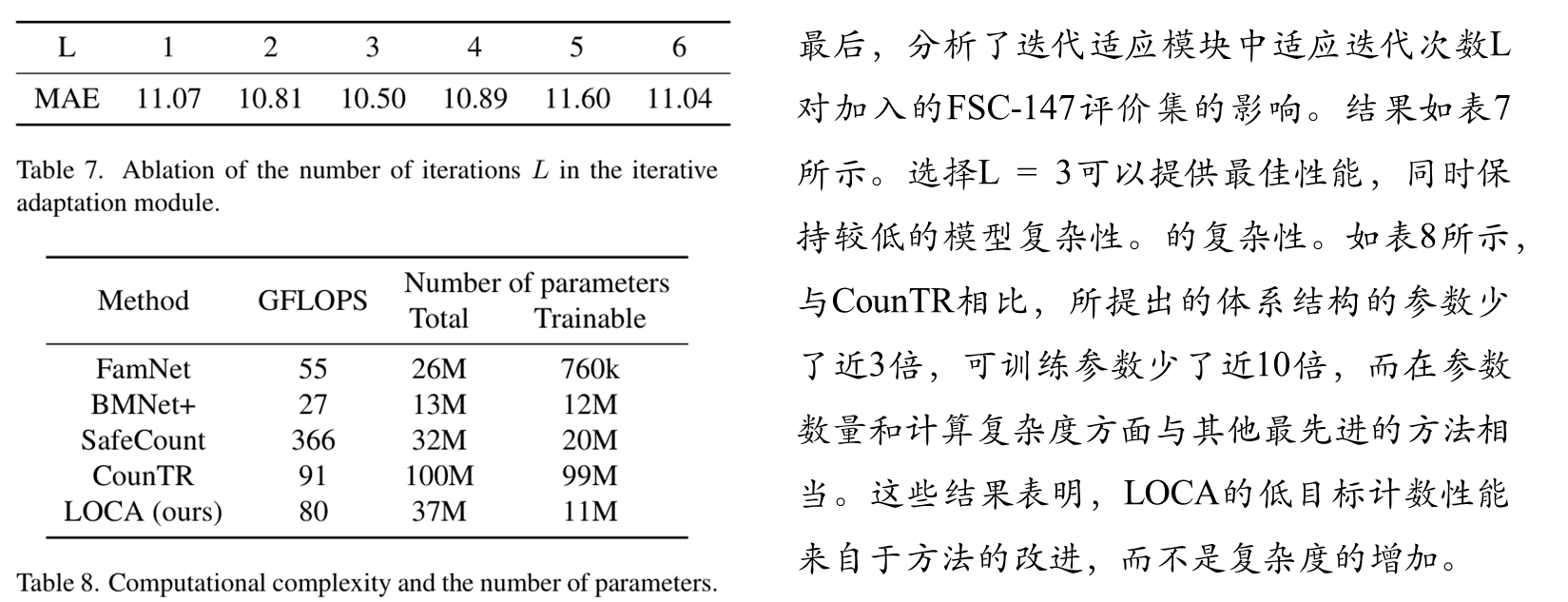
消融实验
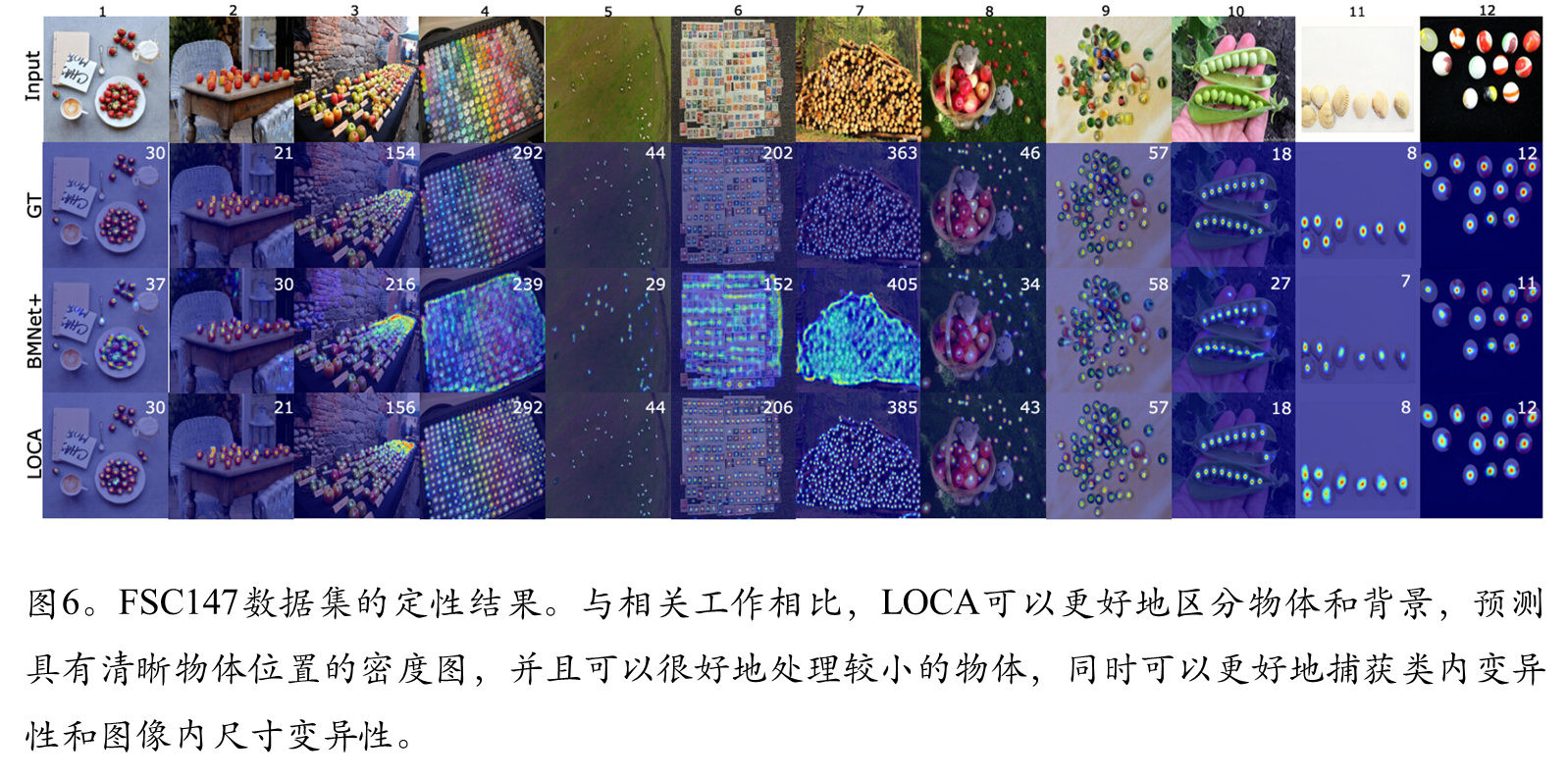
可视化实现
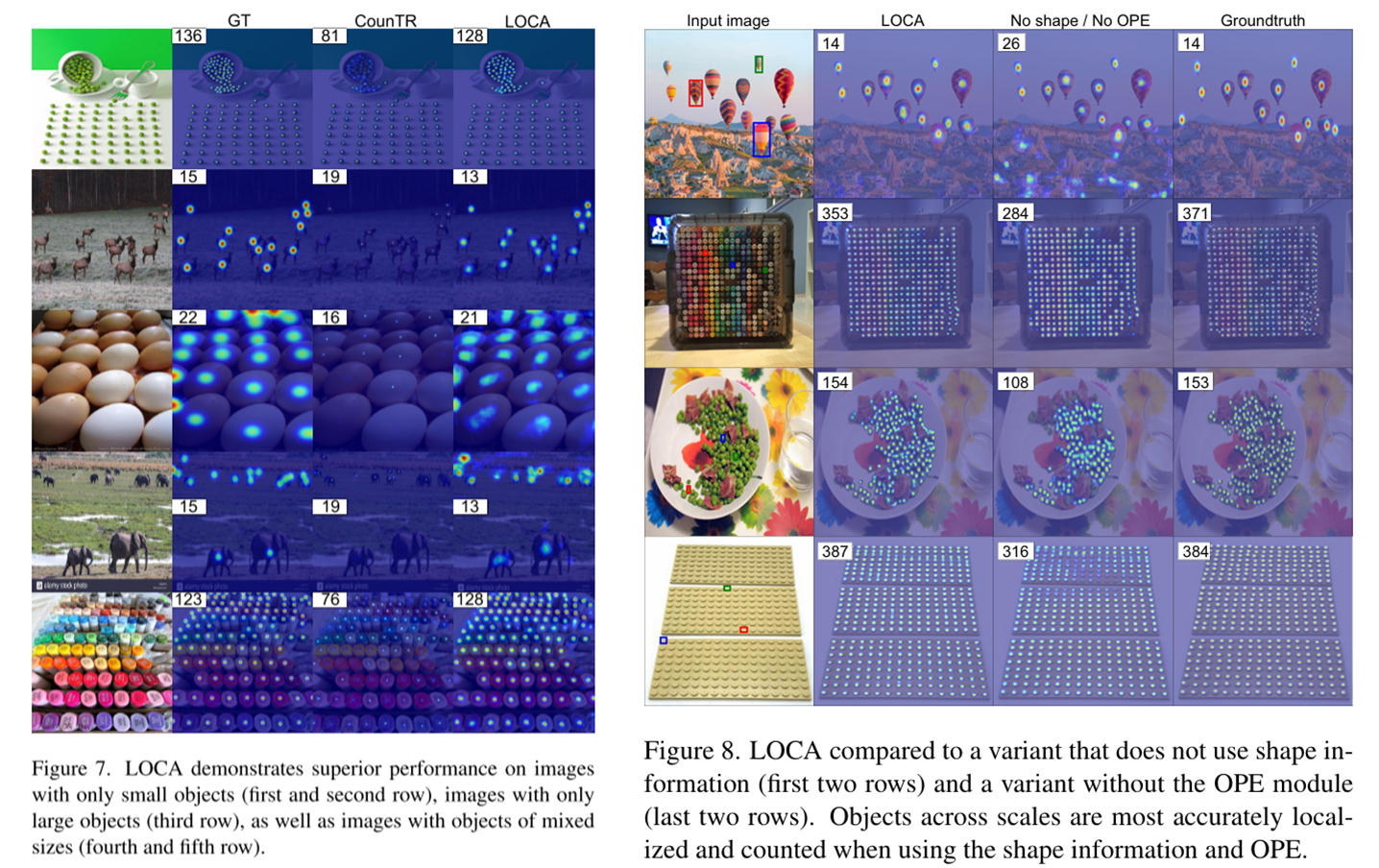


















 1296
1296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









