




论文下载:https://arxiv.org/abs/2302.12066
代码下载:https://github.com/SforAiDl/CountCLIP
https://github.com/KeepTryingTo
基于Zero-Shot的计数算法详解(T2ICount: Enhancing Cross-modal Understanding for Zero-Shot Counting)
统一的人群计数训练框架(PyTorch)——基于主流的密度图模型训练框架
算法VLCount详解(VLCounter: Text-aware Visual Representation for Zero-Shot Object Counting)
人群计数中常用数据集的总结以及使用方式(Python/PyTorch)
基于Zero-Shot的目标计数算法详解(Open-world Text-specified Object Counting)
基于zero-shot目标计数方法详解(Zero-Shot Object Counting)
基于Transformer的目标统计方法(CounTR: Transformer-based Generalised Visual Counting)
基于zero-shot目标统计算法详解(Zero-shot Object Counting with Good Exemplars)
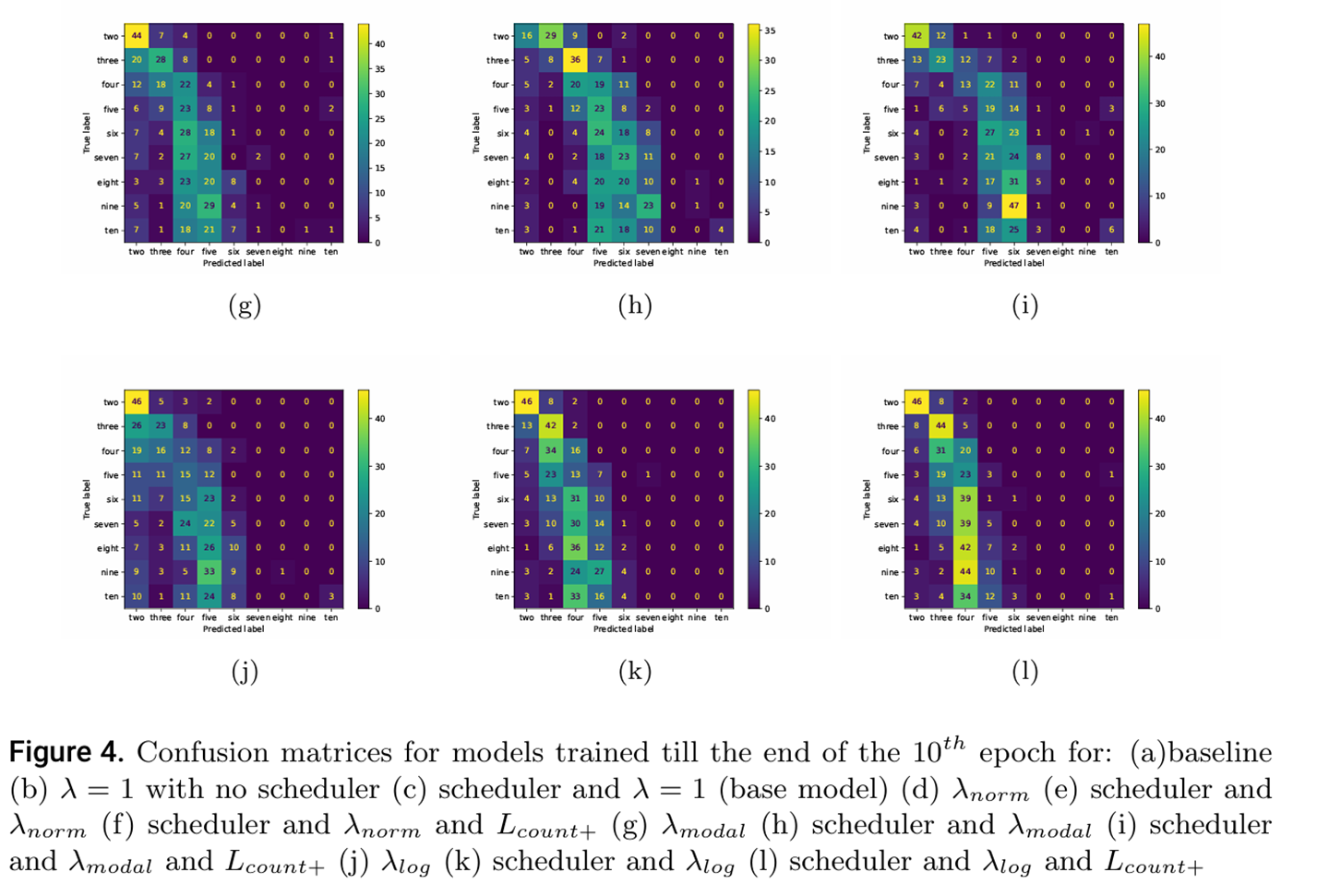
本文提出改进的零样本目标计数方法,针对现有视觉-语言模型在数量理解方面的不足进行优化。主要创新包括:1)设计CountPlus多元对比损失函数;2)提出三种动态λ平衡机制(λ_norm、λ_modal、λ_log)解决类别不平衡问题;3)开发高效的小数据集训练策略,仅需2000张图像(比原方法少640倍)。实验表明,该方法在有限计算资源下显著提升计数性能,并公开了相关代码和数据集。研究解决了计数感知表示不足、资源需求大和类别不平衡等关键问题。
目录

现有方法局限性
1.计数感知表示能力不足:
2.训练数据规模与计算资源需求大:
原始论文CLIP使用LAION-400M数据集中的约200,000张计数图像进行训练,需要巨大的计算资源和存储空间。这种方法对于资源有限的研究者来说不可行,限制了该技术的普及和应用。
3.类别不平衡问题严重:
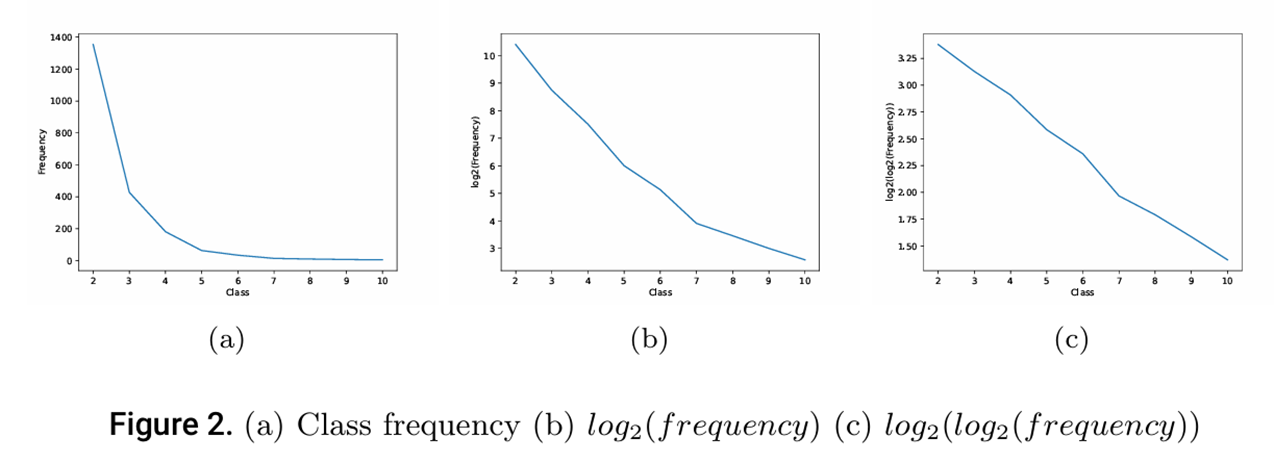
计数训练数据中存在严重的类别不平衡,较低数字(如2-6)的样本数量远高于较高数字(如7-10)。这种不平衡导致模型对高频类别的学习过度,而对低频类别的学习不足。
提出的方法
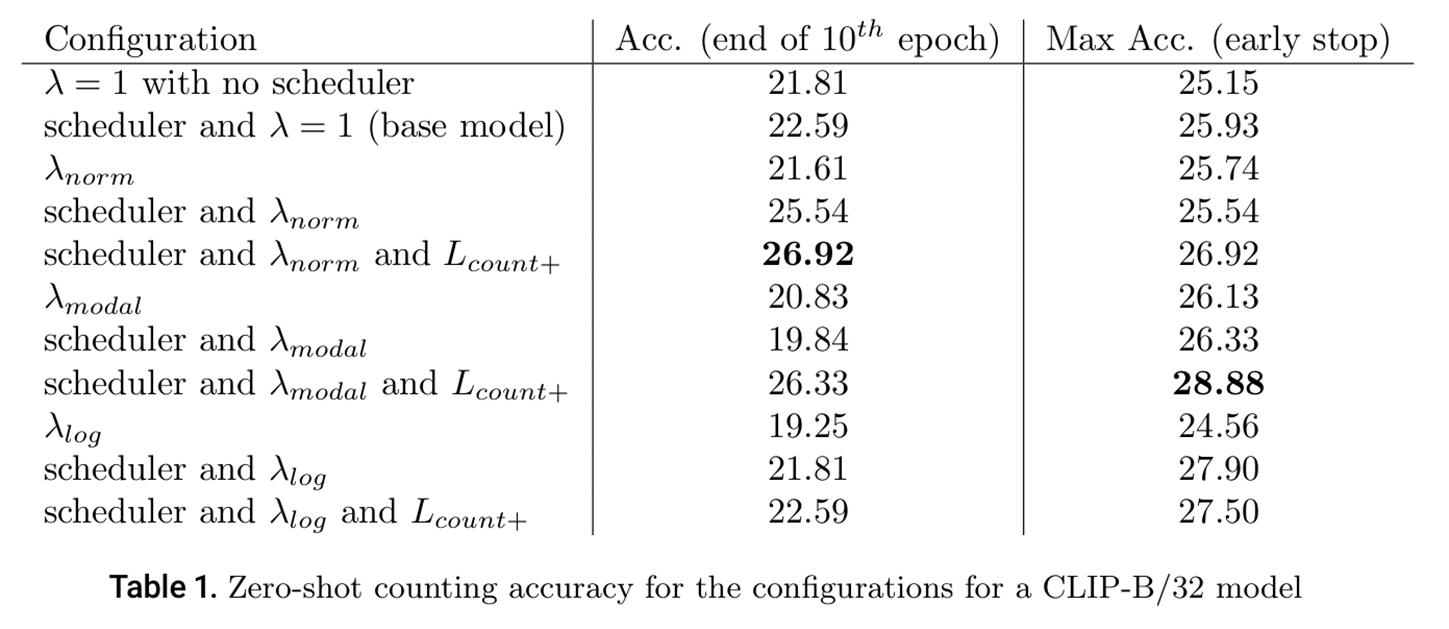
1.改进的损失函数设计:
CountPlus损失函数:将原始的二元对比损失扩展为多元对比损失,使模型能够同时对比正确标题与所有可能错误计数标题。
2.动态λ平衡机制:
提出三种λ平衡方案来应对类别不平衡:λ_norm:基于类别频率的比例加权;λ_modal:重点关注低频类别;λ_log:通过对数变换实现线性缩放;这些方案确保模型在训练过程中对不同频率的类别给予适当关注。
3.高效的小数据集训练策略:
使用仅2,000张计数图像(比原始数据小640倍)进行训练,证明在有限资源下也能实现性能提升。
训练数据集
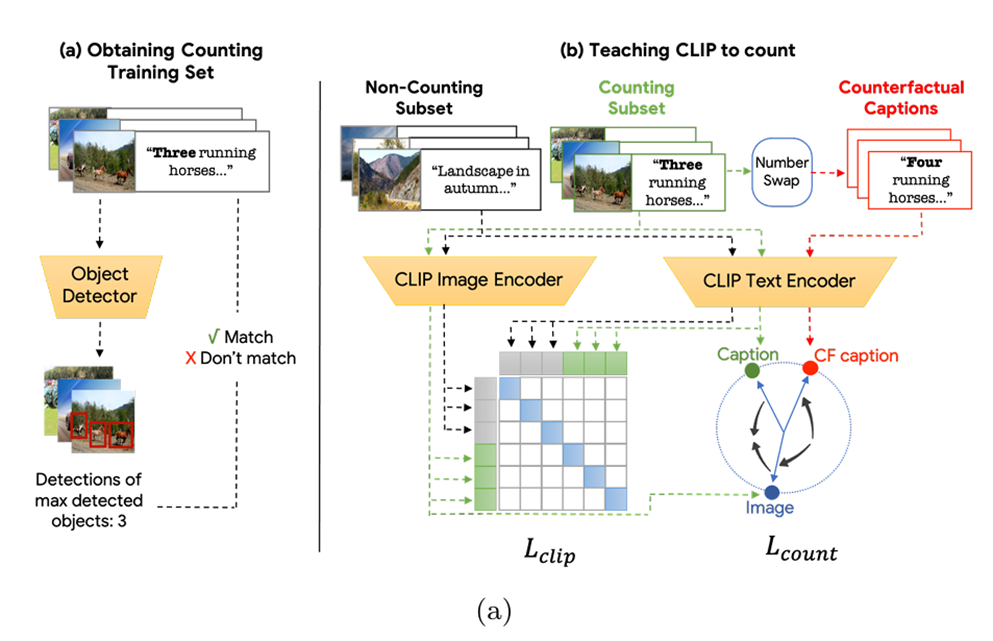
在4亿张图像中,原研究团队获得了约20万张计数图像。由于本文规模和计算资源限制,本文处理了200万张图像,获得了约2000张计数图像。本文已公开了代码和计数数据集。寻找包含"two"到"ten"数字单词的句子。图像通过YOLOv8目标检测器处理,并将最常见实体的数量与标题中的计数进行核对。
具体方法

用于平衡的λ


损失函数

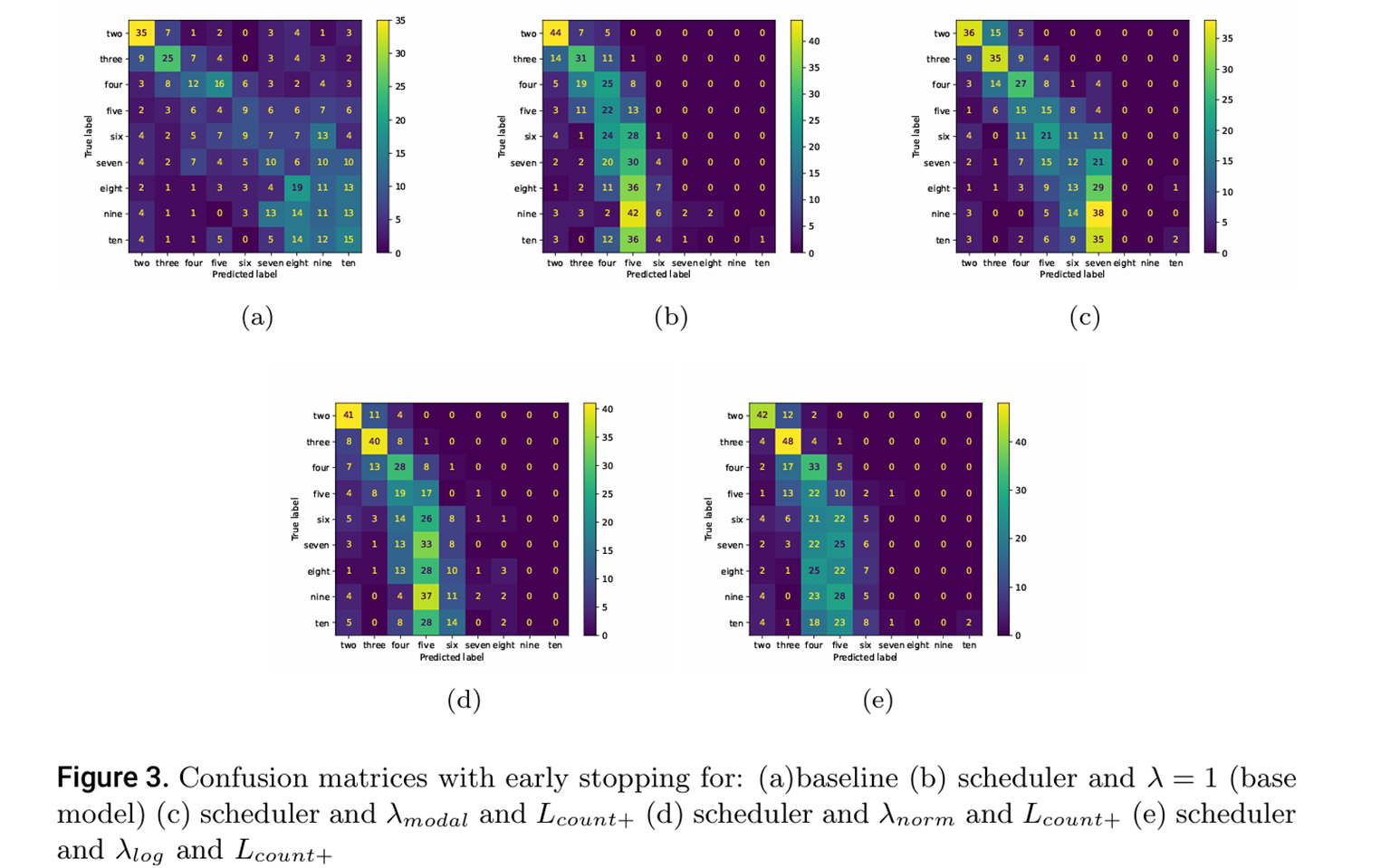
实验结果



















 3226
3226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









