




视频讲解1:B站视频讲解
视频讲解2:https://www.douyin.com/video/7575066691655290131
论文下载:https://arxiv.org/abs/1803.03095
代码下载:https://github.com/xialeiliu/CrowdCountingCVPR18/tree/master
人群计数中常用数据集的总结以及使用方式(Python/PyTorch)
论文CrowdCLIP(基于CLIP的无监督人群计数模型)详解(PyTorch,Pytorch_Lighting)
本文提出一种基于排序的自监督人群计数方法,旨在解决标注数据稀缺问题。通过互联网自动收集无标签人群图像,并设计多任务网络联合学习计数(密度图回归)和排序(人数比较)任务。创新性地提出三种训练策略,其中多任务联合训练效果最佳。该方法无需人工标注即可构建大规模排序数据集,显著提升模型性能。实验验证了多尺度采样和排序数据对性能的重要性,为无监督人群计数提供了新思路。
大家注意看这篇论文和上面链接中的CrowdCLIP论文算法。
目录

存在的问题
人群计数旨在估计拥挤场景中的人数,在视频监控、安全监测等领域有重要应用。尽管基于卷积神经网络的方法取得了显著进展,但一个主要瓶颈是缺乏大规模标注数据。标注需要精确标记每个人的位置,成本极高,导致现有数据集通常只有几百张图像,使得训练深度网络容易过拟合。
基于排序的自监督学习(本文方法)
1. 无标签数据收集与排序序列生成
研究者通过两种方式从互联网(Google Images)自动收集人群图像:
关键词查询:使用“Crowded”, “Demonstration”等关键词搜索,收集了1180张高分辨率人群图像。
以图搜图:使用现有数据集的训练图像作为查询,检索相似图像,为不同数据集定制了额外的未标注集。
2. 网络架构与多任务学习
论文设计了一个多任务网络,同时学习两个任务:
主任务(计数):基于VGG-16架构,移除全连接层,修改为输出人群密度图。使用欧几里得损失监督。
辅助任务(排序):在密度图网络后接一个全局平均池化层,将密度图转换为总人数估计。使用成对排序铰链损失,确保网络学会区分图像对的人数多少。
3.三种训练策略对比
论文系统地比较了三种结合标注数据(有密度图)和排序数据(无密度图)的策略:
排序预训练 + 微调:先在排序数据上训练,再在标注数据上微调。这是自监督学习常见做法,但本文发现该策略效果不佳。
交替任务训练:在计数和排序两个任务间交替进行训练。
多任务训练(最佳策略):在每个批次中同时采样标注数据和排序数据,联合优化计数损失和排序损失。

方法对比

排序数据集生成算法
生成排序数据集的算法流程:
输入:人群场景图像,补丁数k,比例因子s。
步骤1:从锚点区域中随机选择一个锚点。锚点区域定义为原图像大小的1/r, 以原图像中心为中心,与原图像具
有相同的纵横比。
步骤2:找到以锚点为中心且包含在图像边界内的最大正方形patch。
步骤3:裁剪k−1个额外的正方形补丁,迭代减少尺寸的比例因子s。保持所有 补丁在锚点的中心。
步骤4:将所有k个补丁的大小调整为网络的输入大小。
输出:根据补丁中人员的数量排序的补丁列表。
无标签训练数据收集
获取人群计数的数据是费力的,因为图像通常包含数百人,需要精确的注释。相反,本文提出了一个自监督的人群计数任务,该任务利用了在训练期间没有手工标记人数的人群图像。不是回归到图像中的绝对人数,而是训练一个网络来比较图像并根据图像中的人数对它们进行排名。
将采用更加简单的方式收集可用于训练这些方法的等级标记数据。其主要思想是基于这样一种观察,即大补丁中包含的所有补丁的人数必须少于或等于大补丁的人数(见图1)。这种观察使本文能够收集相对等级存在的人群图像的大型数据集。而不是辛苦地注释每个人,只需要验证图像是否包含人群。给定一幅人群图像,根据上面提出的生成秩数据的算法提取排序补丁。
关键词查询:从谷歌图像中收集了一个人群场景数据集,使用不同的关键词:拥挤,示范,火车站,商场,工作室,海滩,所有这些都有很高的可能性包含人群场景。然后删除与问题无关的图像。最后,收集了一个包含1180张高分辨率人群场景图像的数据集,大约是UCF CC 50数据集大小的24倍,是sha_partA部分数据集大小的2.5倍,是sha_partB部分数据集大小的2倍。注意,没有对图像进行其他注释。
按例查询图像检索:对于每个特定的现有人群计数数据集,通过使用视觉图像搜索引擎谷歌images使用训练图像作为查询来收集数据集。选择前十个相似的图像,并删除不相关的图像。对于UCF CC 50,收集了256张图像,对于sha_partA部分,收集了2229张图像,对于sha_partB部分,收集了3819张图像。

学习排序数据集
人群密度评估网络
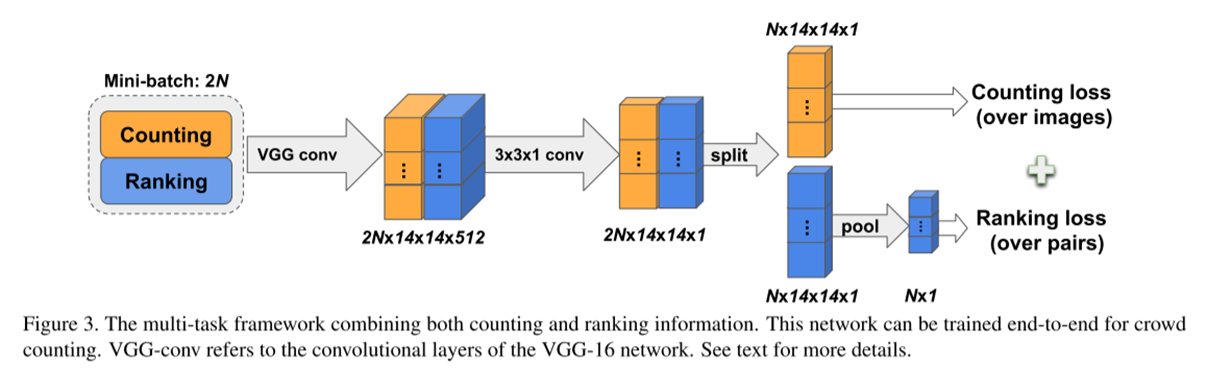
从可用的标记数据集中引入了多尺度采样。没有使用整个图像作为输入,而是随机采样不同大小的正方形块(从56到448像素)。在实验部分,我们验证了这种多尺度采样对于良好的性能是重要的。
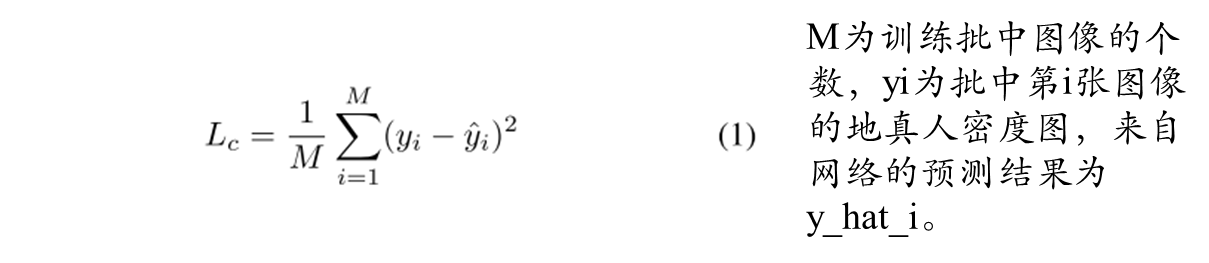
人群排序网络

排序损失

联合统计和排序数据集
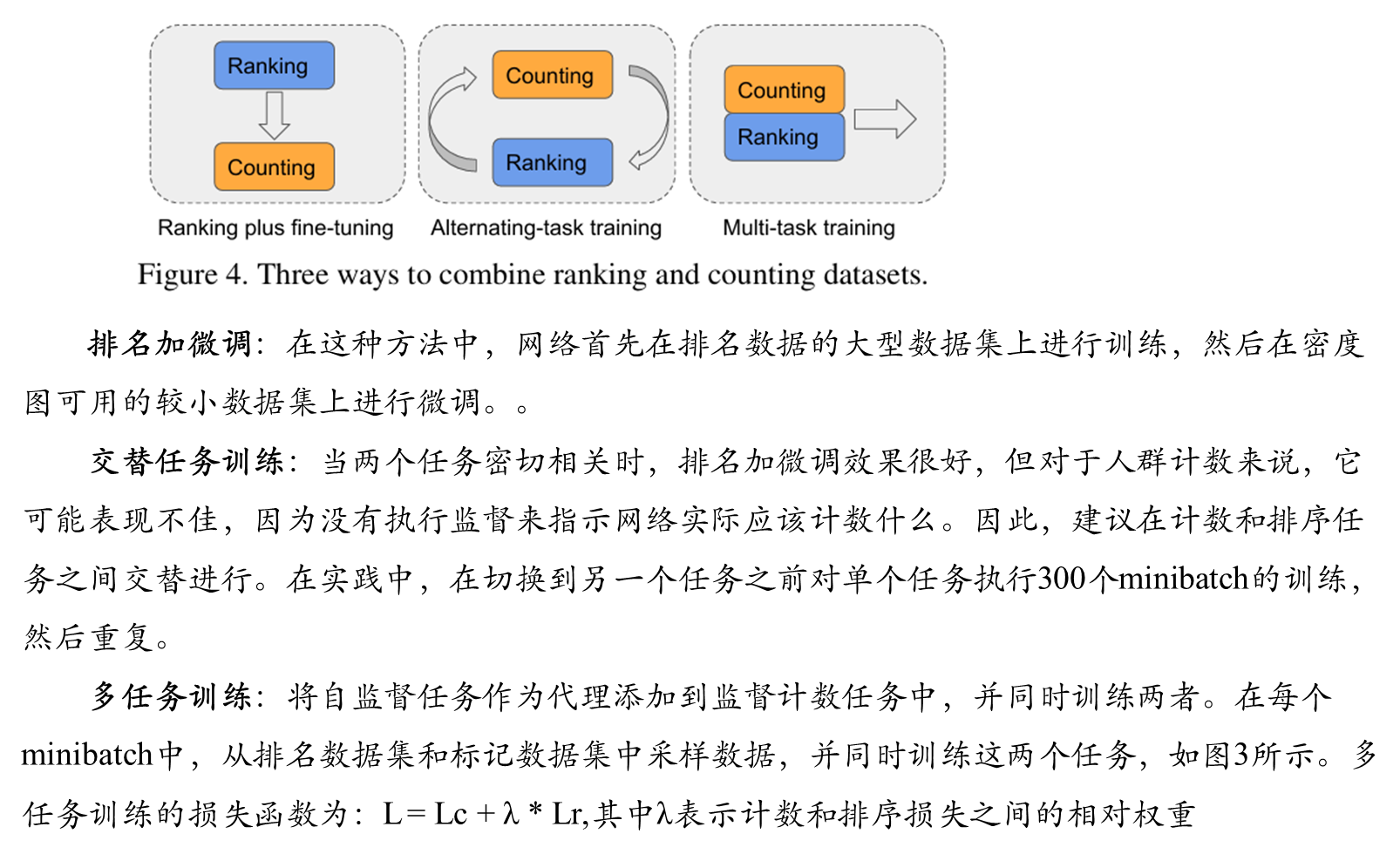
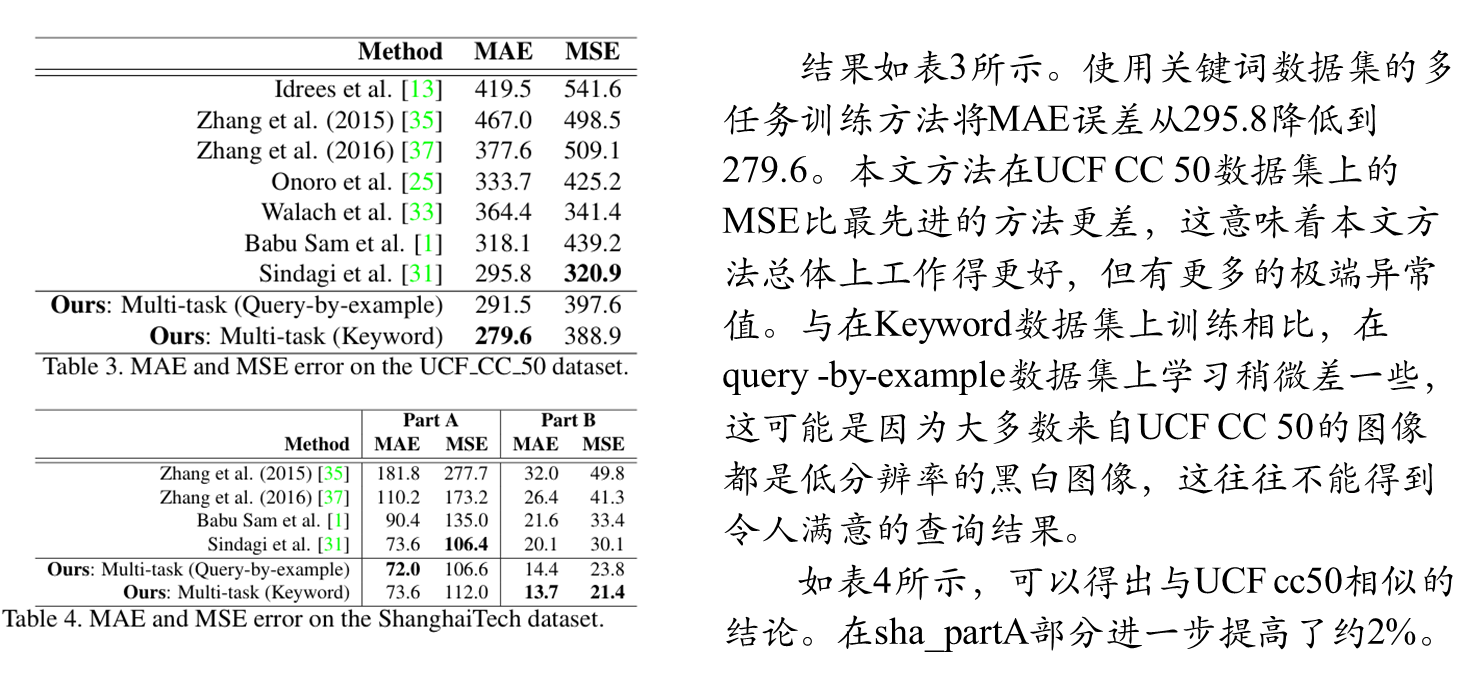
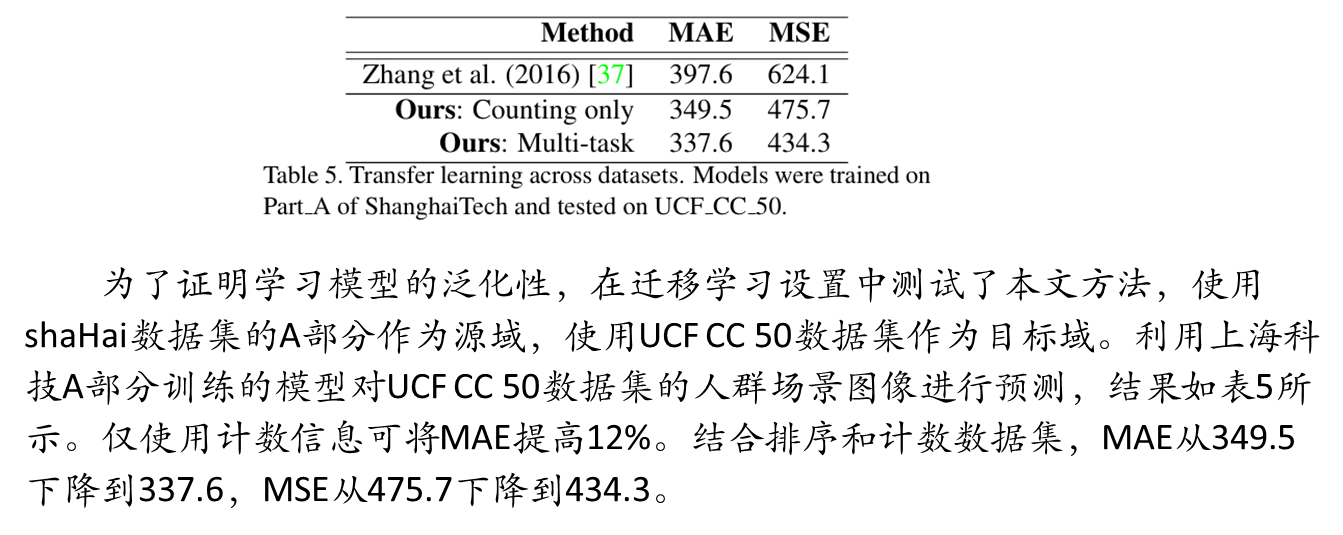
综合实验
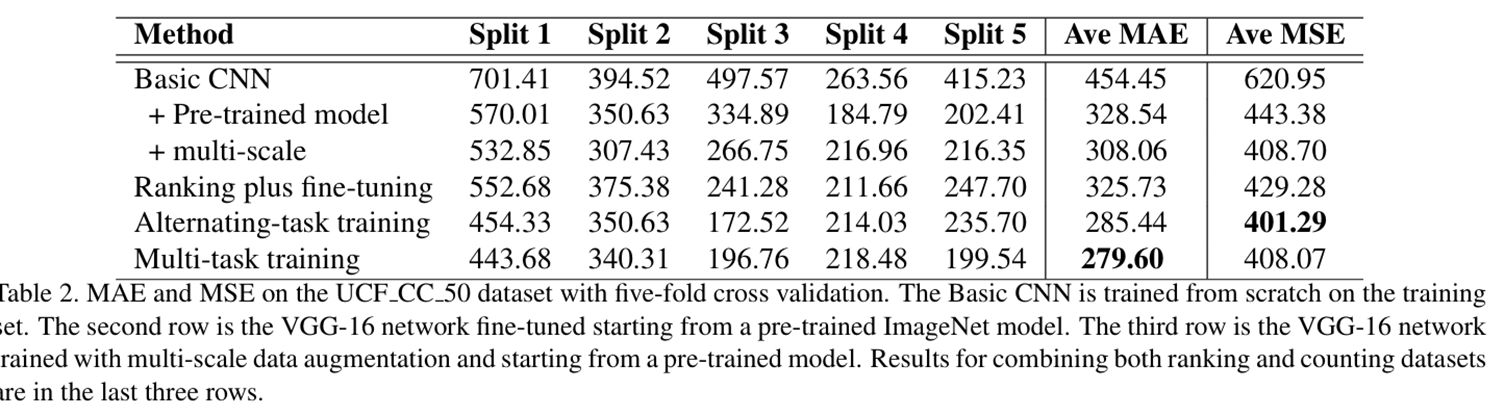




















 9551
9551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









