






视频讲解:视频讲解(推荐结合视频看)
代码下载地址:https://github.com/dogehhh/reclip
论文 Completely Self-Supervised Crowd Counting via Distribution Matching无监督算法详解
论文CrowdCLIP(基于CLIP的无监督人群计数模型)详解(PyTorch,Pytorch_Lighting)
论文CLIP-Count(基于文本指导的零样本目标计数)详解(PyTorch)
前面我们已经讲过了两篇论文关于人群计数的无监督算法,其中一篇是基于人群计数符合自然幂律分布,而另外一篇是基于CLIP的无监督算法,充分利用了CLIP的泛化性能。而本文要讲的是关于语义分割领域的一篇基于CLIP的无监督算法,但是这篇算法的理解不是太容易,因此需要花较多的时间去阅读和理解。上面视频我们讲的是改进版的代码实现,其实也差不多,看懂改进版的,那么基础也可以看懂(本文是基础版)。

目录
AttributeError: module 'clip' has no attribute 'load'
一 目的和方法
提出目的
近期研究利用CLIP模型完成极具挑战性的无监督语义分割任务——该任务中仅有无标注图像可用。然而发现当CLIP被应用于此类像素级理解任务时,会出现难以预料的偏差。先前工作未能显式建模此类偏差,严重制约了分割性能。
提出方法
本文提出通过显式建模并校正CLIP中存在的偏差来提升无监督语义分割效果。具体而言,设计可学习的"参考"提示词来编码类别偏好偏差,同时将视觉Transformer的位置嵌入投影为空间偏好偏差表示。通过简单的逐元素减法操作,校正了CLIP分类器的逻辑输出。基于校正后的逻辑值,采用Gumbel-Softmax运算生成分割掩码。随后通过建立掩码视觉特征与各类别文本特征间的对比损失,促进有效的偏差建模。为进一步提升分割质量,通过最小化设计的掩码引导、特征引导和文本引导损失项,将校正后CLIP的知识蒸馏至先进分割架构。
对比结果
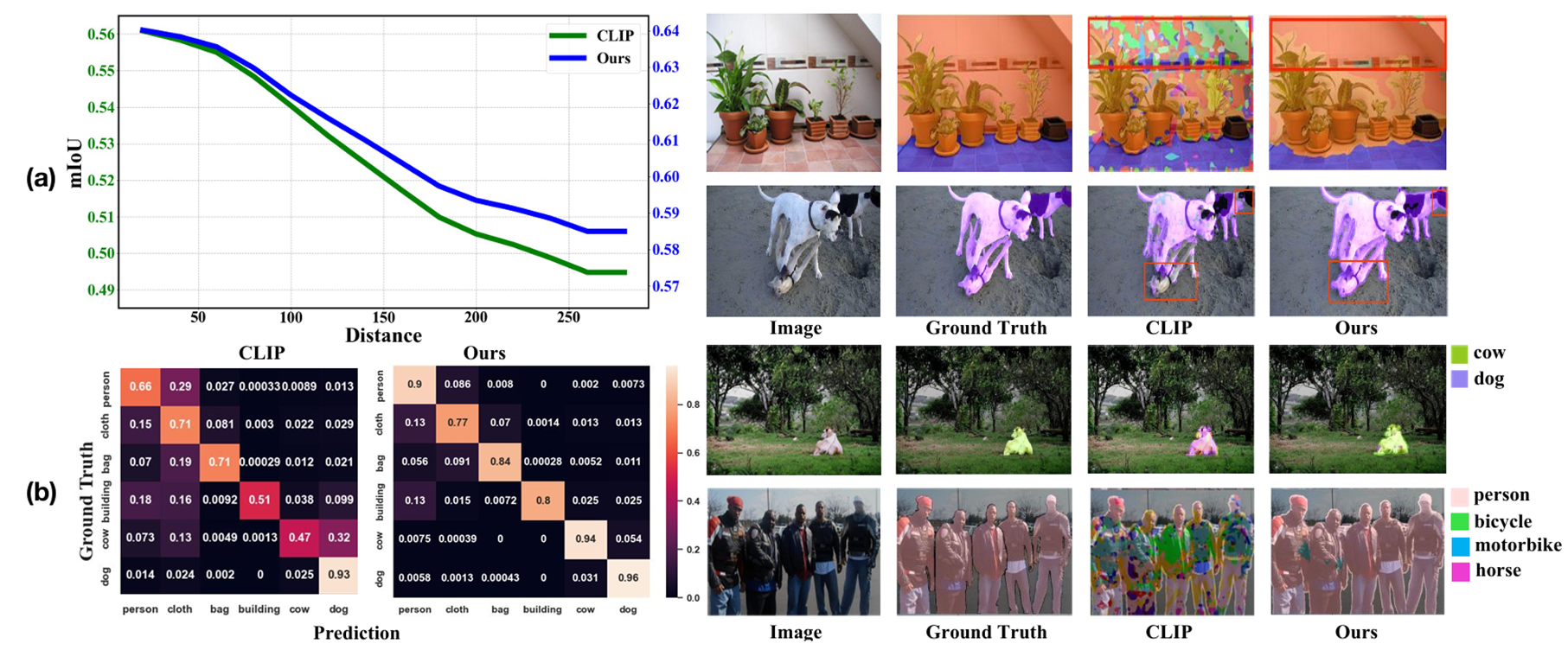
图1.(a)空间偏好偏差。(左)在PASCAL VOC数据集上绘制了距离(x轴)与mIoU(y轴)的关系曲线,其中距离表示物体质心与图像质心之间的空间距离,mIoU基于预测结果与真实值计算得出。曲线显示CLIP模型(绿色)对中心物体的分割效果明显优于边缘物体,而本文的方法(蓝色)有效缓解了这种偏差。(右)可视化结果从定性角度展示了本文在空间偏好偏差上的改进效果。(b)类别偏好偏差。(左)本文从PASCAL Context数据集中随机选取6个类别,分别绘制了CLIP模型与本文模型的混淆矩阵。结果表明除真实标签外,CLIP在多数情况下倾向于为像素分配错误但相关的类别标签,而本文的方法显示出显著改进。(右)可视化结果与混淆矩阵的观察结论一致,例如对于"牛"这类物体,CLIP会错误地将其分类为"狗"。
具体方法总结
本文提出通过显式建模与校正CLIP的偏差来提升弱监督语义分割性能。具体实现包括:
1)为每个类别设计可学习的"参考"提示词和手动设计的"查询"文本,分别生成反映类别偏好偏差的参考对数几率和代表原始分割能力的查询对数几率;
2)将CLIP视觉Transformer的位置嵌入投影为空间偏好偏差表示;
3)采用对数几率减法机制,从查询对数几率中减去参考和位置对数几率以消除偏差;
4)基于校正后的对数几率,通过Gumbel-Softmax生成分割掩码,并构建掩码视觉特征与文本特征的对比损失。
进一步通过掩码引导、特征引导和文本引导的三重蒸馏策略,将校正后的CLIP知识迁移至先进分割架构。
主要贡献包括:
二 整体模型架构
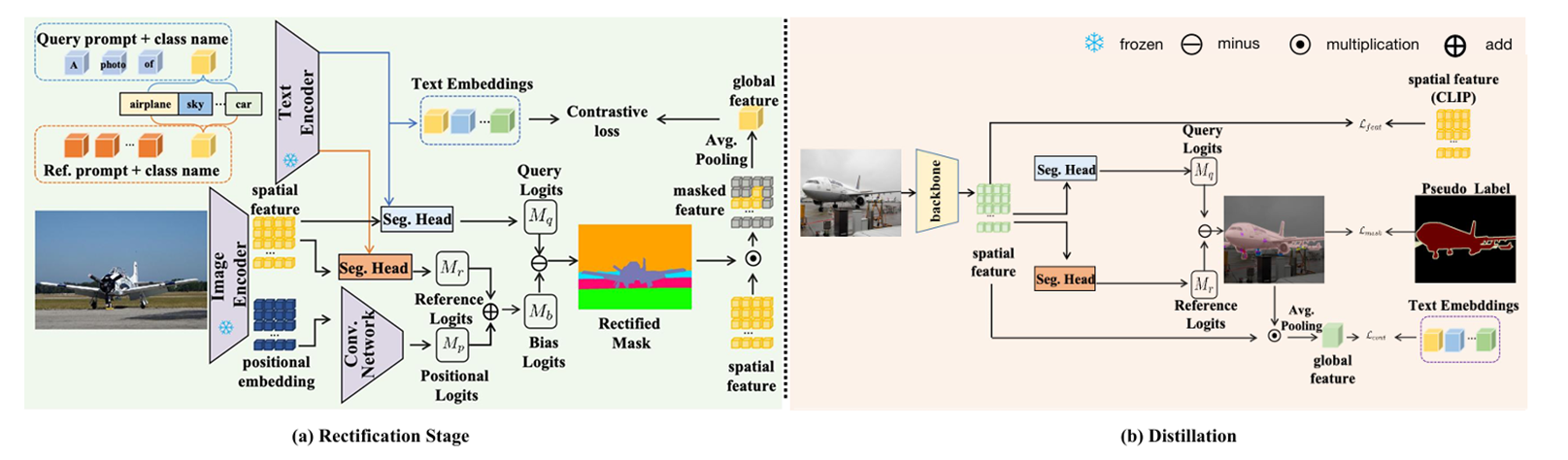
图2展示了本文提出的语言引导无监督语义分割新方法框架。该方法包含两个核心阶段:(a)校正阶段:通过设计可学习的"参考"提示词编码类别偏好偏差,并将视觉Transformer位置嵌入投影为空间偏好偏差表示,采用对数几率减法机制对CLIP的两种偏差进行联合校正;(b)蒸馏阶段:通过掩码引导损失、特征引导损失和文本引导损失三项联合优化目标,将校正后CLIP的知识蒸馏至先进分割架构中,其中掩码引导损失确保分割结果的结构一致性,特征引导损失保持视觉特征的判别性,文本引导损失维护视觉-语言对齐关系。整个框架实现了从偏差建模到知识迁移的端到端优化,在保持CLIP原始语义理解能力的同时显著提升了像素级分割精度。

直接使用CLIP作为语义分割模型

学习类别偏好

学习空间偏好

通过对比学习损失校正偏差


Gumbel-Softmax公式
论文链接:https://arxiv.org/pdf/1611.01144v5.pdf
参考代码:https://github.com/AntixK/PyTorch-VAE/blob/master/models/cat_vae.py
Gumbel-Softmax 分布是一种用于生成离散型变量的概率分布。它是由两个部分组成:Gumbel 分布和 Softmax 函数。
参考链接:https://blog.youkuaiyun.com/weixin_43808402/article/details/139803974

蒸馏以提升效果


三 综合实验
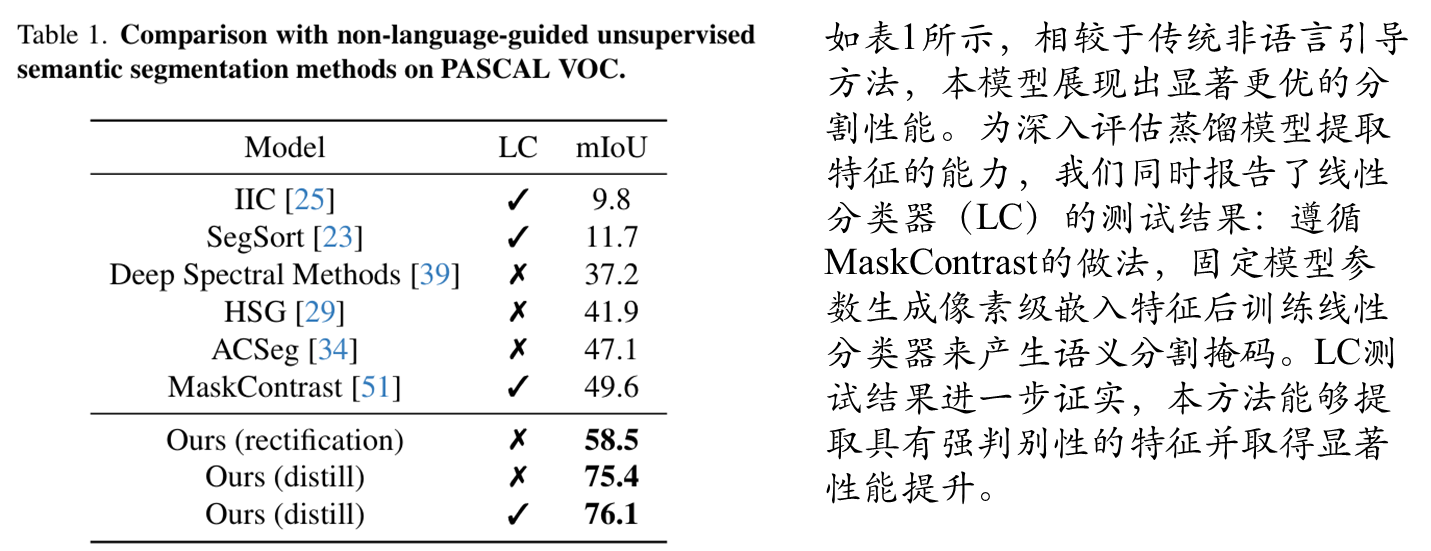
非语言指导的无监督语义分割对比
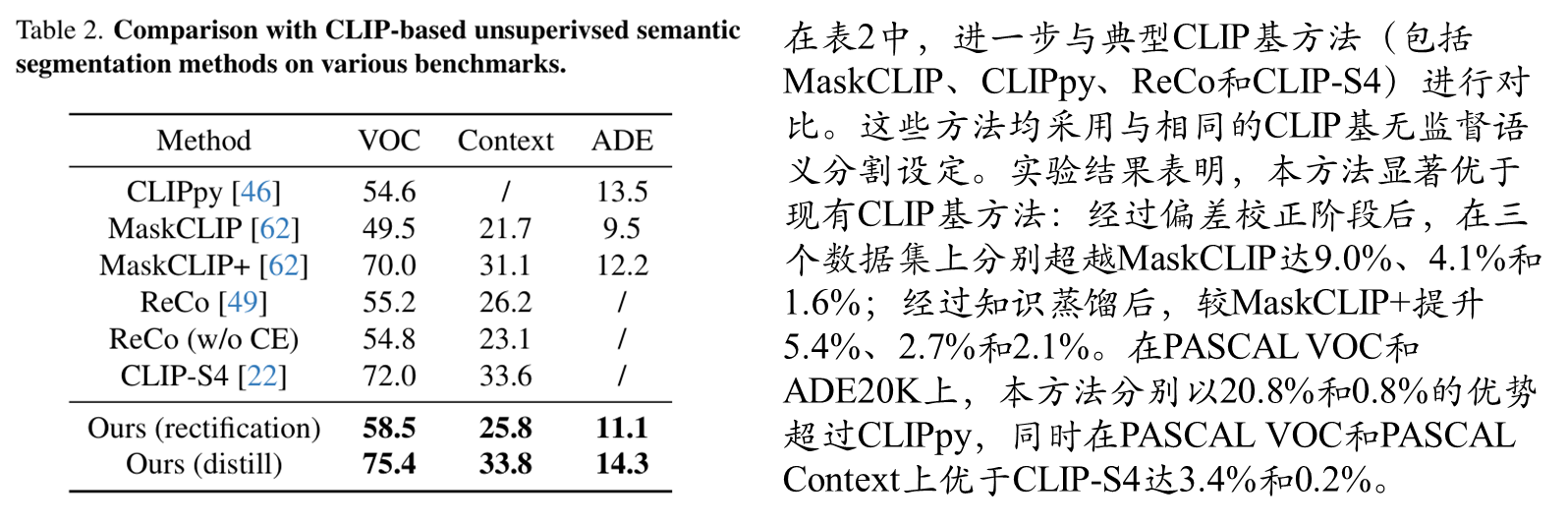
具有CLIP的无监督语义分割对比
消融实验
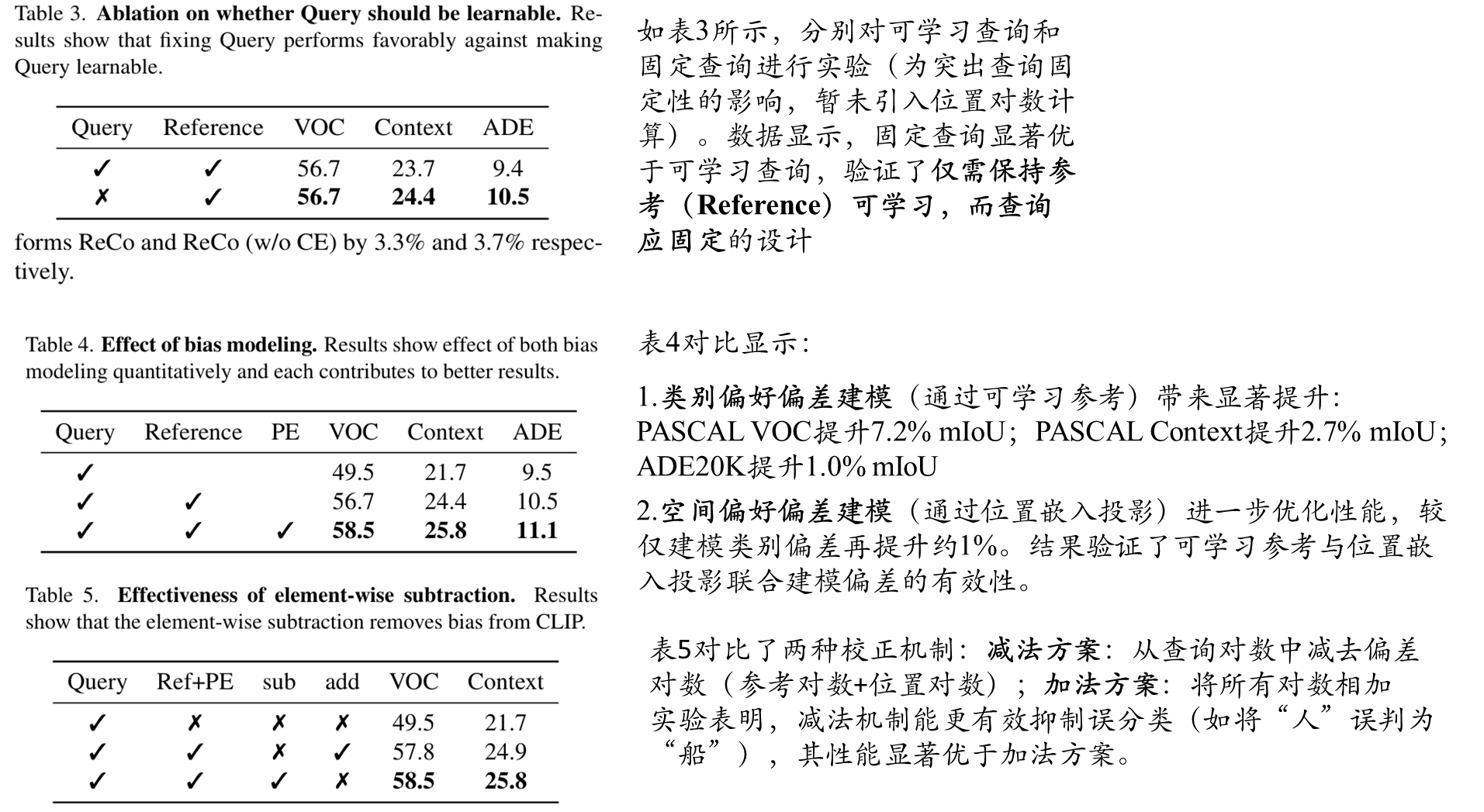
可视化对比

图3展示了本方法在偏差建模与校正方面的可视化验证结果。(a)在PASCAL Context数据集上的定性结果显示,通过同时校正类别偏好偏差和空间偏好偏差,本文模型显著优于MaskCLIP(+)。(b)类别偏好偏差校正的可视化分析:原始CLIP("Query"掩码列)存在将"人"(GT标注)误分类为"船"的问题,通过对比"人"和"船"通道的对数热图可见,在误分类区域"船"通道的激活值异常偏高;参考对数热图显示"人"通道激活值极低而"船"通道普遍偏高;经过提出的对数减法操作后,"船"通道激活被有效抑制,最终获得更准确的分割结果("Ours"列)。(c)空间偏好偏差校正效果:通过对比虚线框区域有无位置嵌入(PE)投影校正的结果,证明PE投影能有效编码空间偏好偏差,校正后显著提升了边界区域的分割性能。这些可视化结果验证了可学习参考提示对类别偏好偏差的建模能力,以及位置嵌入投影对空间偏好偏差的校正效果,共同证实了本方法通过元素级对数减法实现双重偏差校正的有效性。
蒸馏效果

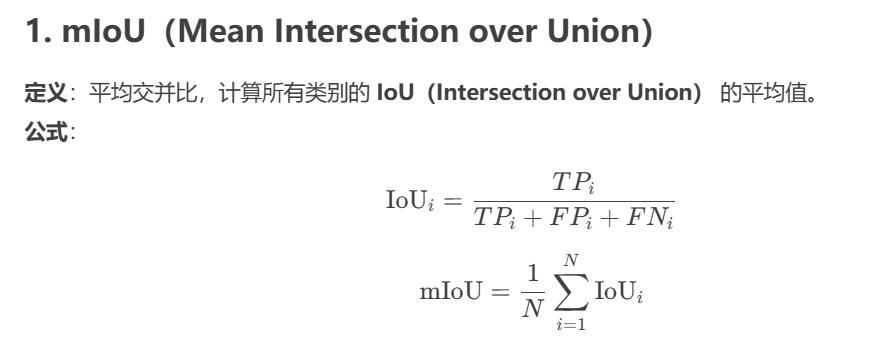
附录:评价指标
平均交并比MIOU
说明:
-
TPi(True Positive):预测为类别 i 且正确的像素数。
-
FPi(False Positive):预测为类别 i 但实际不属于 i 的像素数。
-
FNi(False Negative):实际为类别 i 但未被预测到的像素数。
-
N:类别总数(不包括背景类,如
255)。
特点:
-
衡量预测区域与真实区域的重叠程度,范围
[0, 1],值越大越好。 -
对类别不平衡敏感,适用于多类别分割任务。
MDICE

说明:
-
与 IoU 类似,但更关注 预测正确的区域,对 FP 和 FN 的惩罚较轻。
-
常用于医学图像分割(如肿瘤检测)。
特点:
-
范围
[0, 1],值越大越好。 -
对类别不平衡较敏感,但比 IoU 更平滑。
mFScore

说明:
-
Precision(精确率):预测为正类的样本中,真实为正类的比例。
-
Recall(召回率):真实为正类的样本中,被正确预测的比例。
-
F1-Score 平衡 Precision 和 Recall,适用于类别不平衡数据。
特点:
-
范围
[0, 1],值越大越好。 -
适用于类别不平衡问题(如小目标检测)。
准确率Accuracy

说明:
-
TNi(True Negative):不属于类别 i 且未被预测为 i 的像素数。
-
不考虑类别不平衡,容易受背景类主导(如 90% 背景时 Accuracy 可能虚高)。
特点:
-
范围
[0, 1],值越大越好。 -
适用于类别均衡的数据,但对小目标不敏感。
AttributeError: module 'clip' has no attribute 'load'
注:直接clip代码拿过来放在自己的代码目录下面,进行加载即可,也不用去下载clip,而且直接看clip的仓库代码反而感觉好一点。



















 1684
1684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









