






论文下载链接:https://arxiv.org/pdf/1906.00446v1.pdf
TensorFlow代码:https://github.com/deepmind/sonnet
PyTorch代码:https://github.com/rosinality/vq-vae-2-pytorch
VQ-VAE(论文Neural Discrete Representation Learning(VQ-VAE)详解(PyTorch))
前面我们已经讲过了关于VQ-VAE的原始论文,其中主要是采用一种离散隐变量的自编码方法,通过向量量化(Vector Quantization, VQ) 实现隐空间的离散化,从而提升表征的可解释性和生成质量。正是VQ-VAE在大规模的模型当中得到应用,也证明了它的成功。
目录
基于似然的模型,基于有损压缩的高效生成建模和隐式生成模型对比
一 提出目的和方法
提出目的
探索了向量量化变分自编码器(VQ-VAE)模型在大规模图像生成中的应用。
提出方法
扩展并增强了VQ-VAE中使用的自回归先验,使生成的合成样本具有更高的连贯性和逼真度,远超以往水平。采用简单的前馈编码器和解码器网络,使得该模型在编码和解码速度关键的应用场景中具备较大优势。此外,VQ-VAE仅需在压缩的潜在空间中对自回归模型进行采样,这比在像素空间采样快一个数量级,尤其适用于大尺寸图像。
基于似然的模型,基于有损压缩的高效生成建模和隐式生成模型对比
本文系统性地对比了两类主流生成模型——基于似然的模型(如VAE、流模型、自回归模型)和隐式生成模型(如GAN)——的优缺点,并提出了基于有损压缩的高效生成建模方法。
1. 生成对抗网络(GAN)的局限性
2. 基于似然的模型的优势与挑战
3.基于有损压缩的高效生成建模
本文提出利用向量量化(VQ)和离散隐空间建模来提升生成模型的效率和质量:
压缩表示:将图像编码至比原始数据小30倍以上的离散隐空间,减少计算负担。
高效采样:采用PixelCNN + 自注意力(PixelSnail)建模隐空间先验,采样速度提升30倍,适用于高分辨率图像生成。
保持质量:解码后的图像仍保持高视觉保真度,适用于需要快速编解码的应用场景(如大规模图像处理)。
二 回顾VQ-VAE方法


三 PixelCNN自回归模型

四 VQ-VAE-2方法
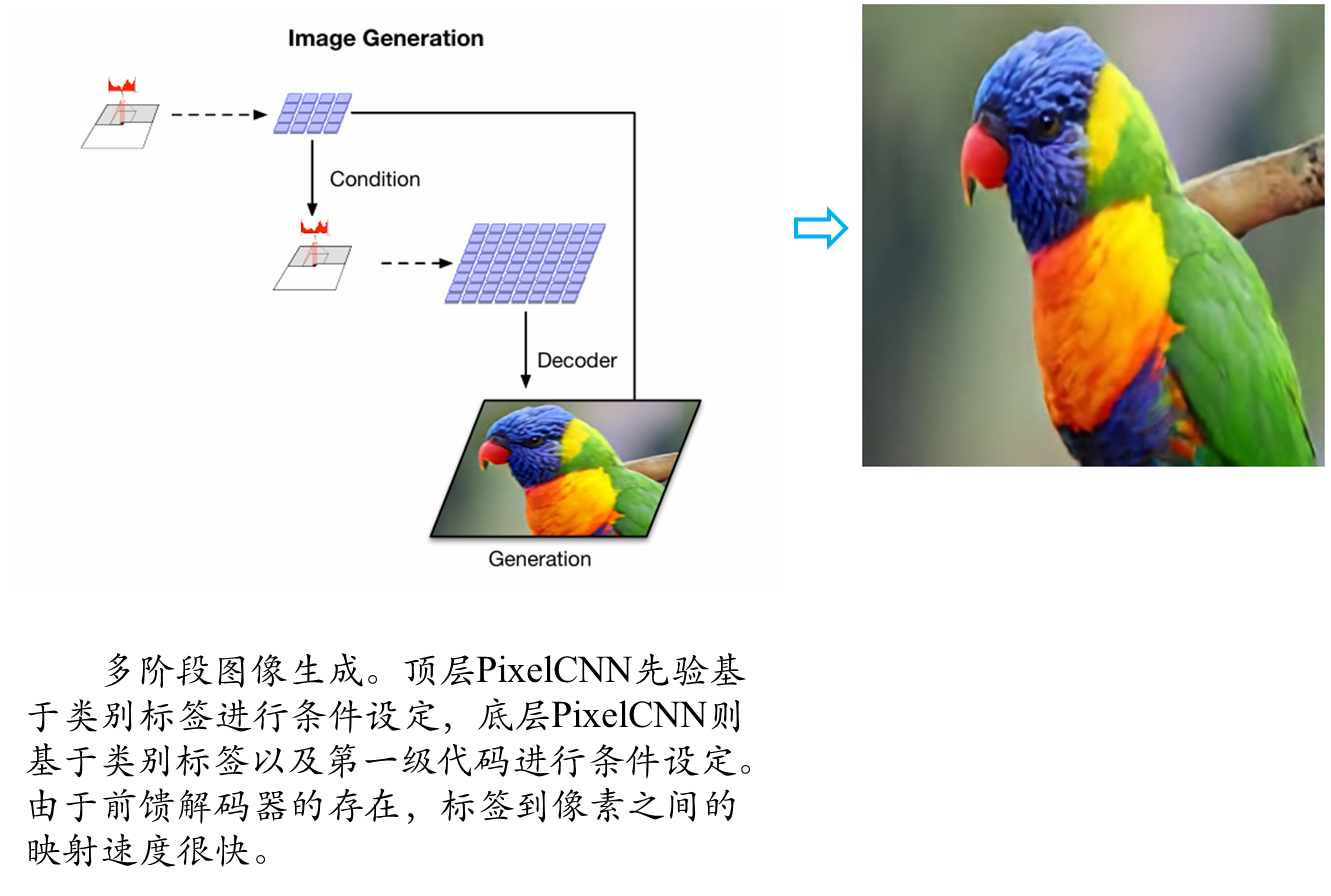
第一阶段:学习分层的影藏编码


第二阶段:在影藏编码中学习先验

五 综合实验对比
为验证多尺度方法捕捉长距离依赖关系的有效性,研究在1024×1024分辨率的FFHQ数据集(含7万张多样化人像)上训练了三级分层模型。高分辨率人脸建模的独特挑战在于:面部对称性(如两眼相距数百像素的强相关性)要求模型具备大感受野,否则可能导致生成样本出现眼色不匹配等问题

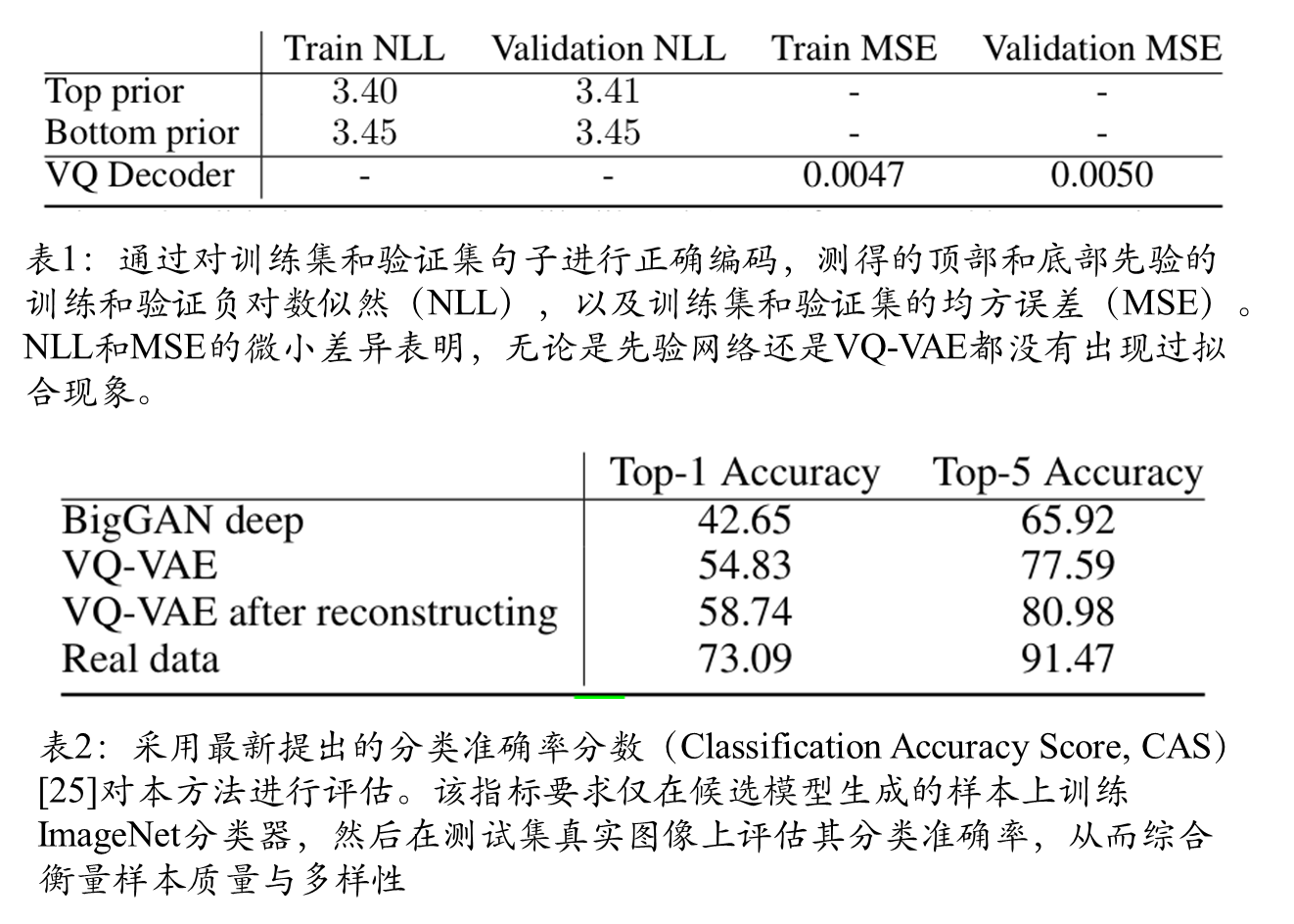
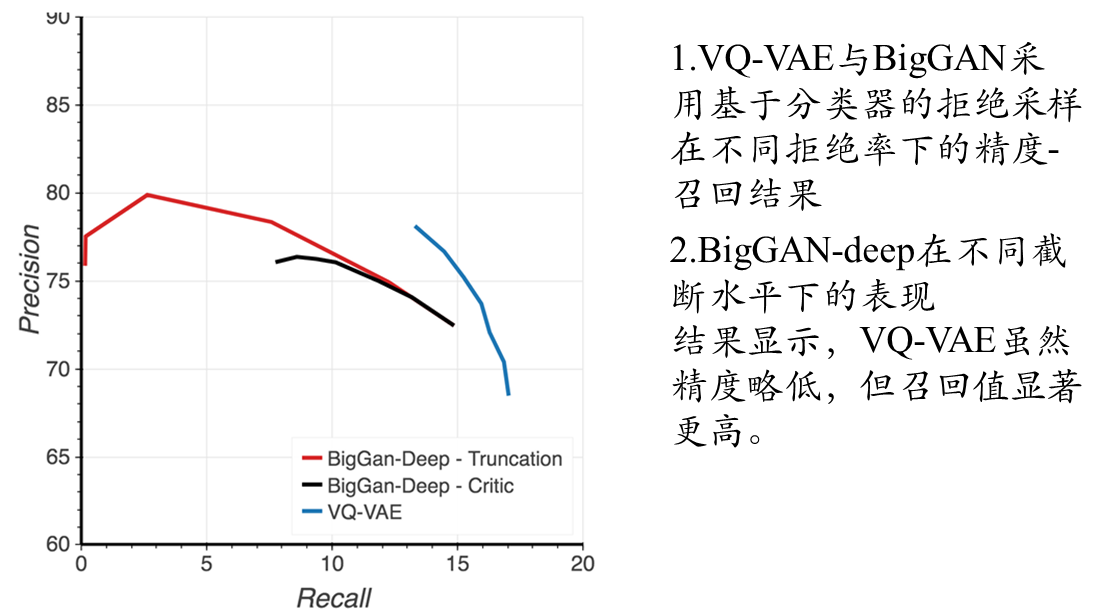
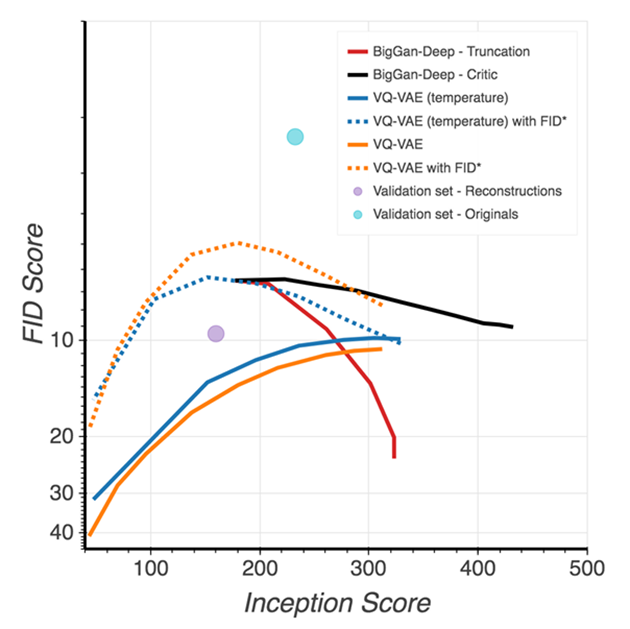
该文段系统比较了GAN评估中常用的Inception Score(IS)和Fréchet Inception Distance(FID)指标,指出其固有缺陷后,重点分析了基于分类器拒绝采样方法对VQ-VAE和BigGAN-deep模型的优化效果:该方法使VQ-VAE的FID从30显著降至10,同时发现Inception分类器对VQ-VAE重建的微小扰动异常敏感(FID从原始压缩的2升至10),为此创新性提出FID*指标,证实VQ-VAE生成样本的统计特性比标准FID指标所反映的更接近真实图像分布。
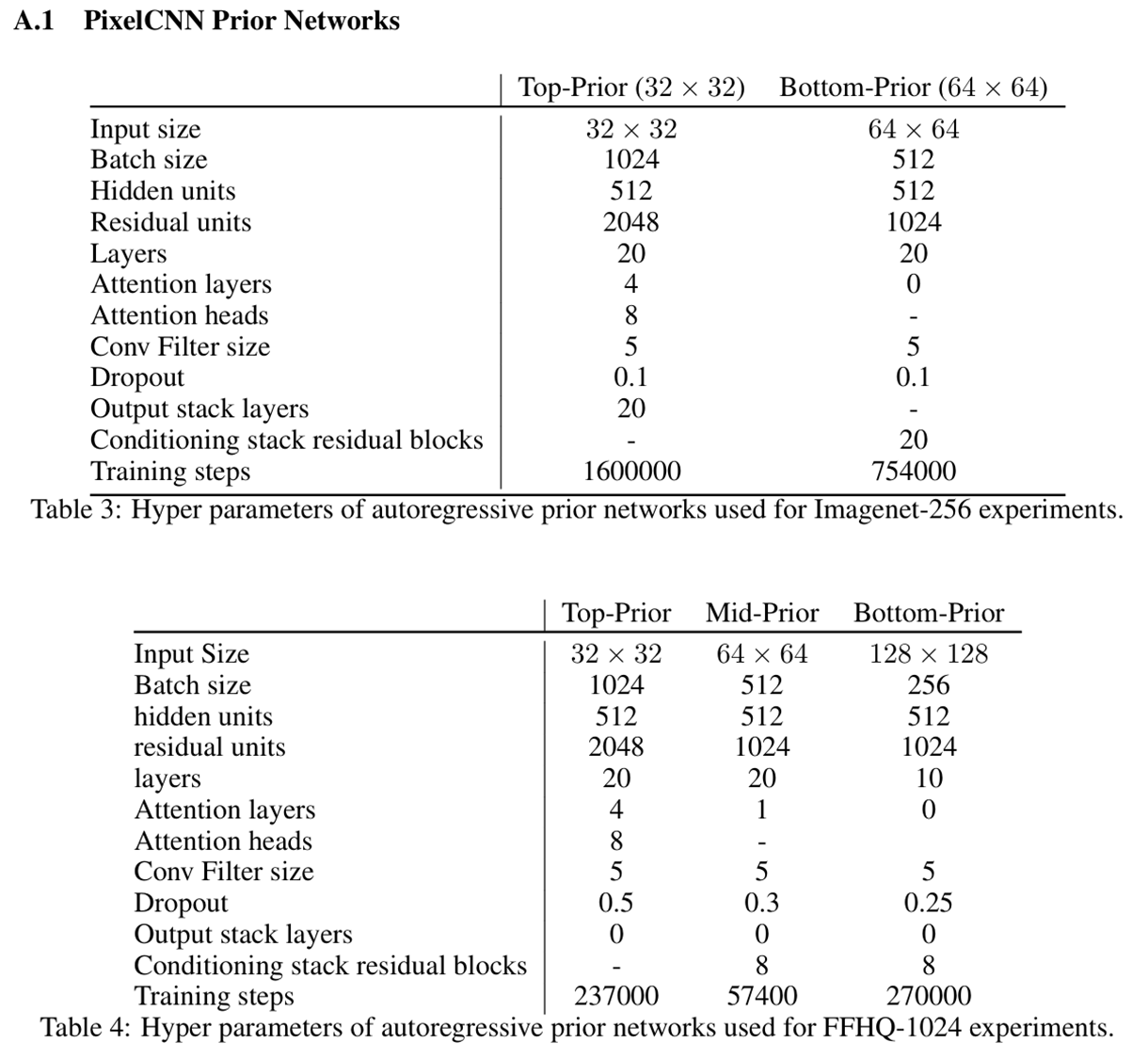
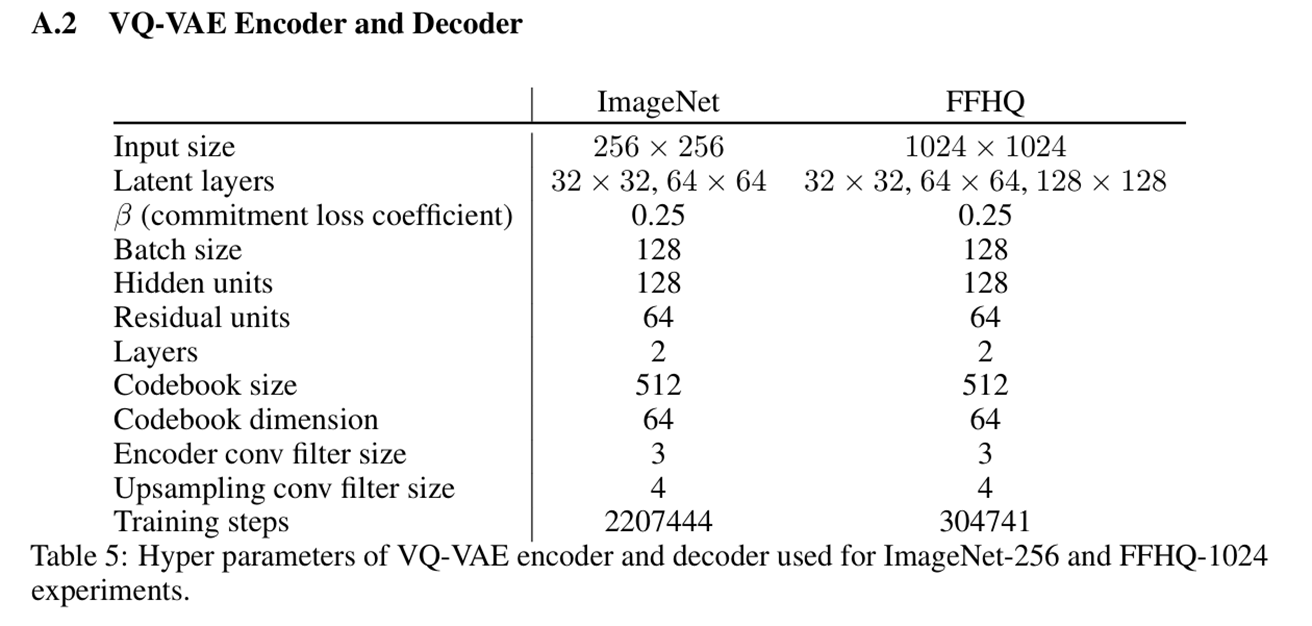
模型架构细节

注:使用pytorch代码实现的采样结果,我这里在训练pixelsnail模型的时候top层只训练了69个epochs和bottom层训练了72个epochs,所以效果非常的差,大家也可以自己去训练更多的epochs,其中数据集我使用的FFQH(64 x 64)大小的原始图像。



















 2322
2322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









