






论文下载地址:https://arxiv.org/pdf/2305.07304v2.pdf
代码下载地址:https://github.com/songrise/clip-count
论文CrowdCLIP(基于CLIP的无监督人群计数模型)详解(PyTorch,Pytorch_Lighting)
Reference-less Counting,Zero-shot Counting,Few-shot Counting,单域泛化以及域自适应之间的区别?
前面我们已经讲过了关于基于CLIP的人群统计两篇文章,也希望读者可以去看前面两篇文章,因为这对于学习CLIP在计数方面具有很好的启发。前面两篇文章主要是从有监督和无监督两方面来进行研究的,而这篇文章也可以说是从无监督的方面来进行研究的,不同的是这篇文章不仅仅是针对人群计数,主要是面对所有的目标,通过文本指定要统计的目标达到效果(零样本计数)。

目录
Reference-less Counting,Zero-shot Counting,单元域泛化以及域自适应之间的区别?(非常重要)
ShanghaiTech crowd counting实验效果
一 提出目的和方法
提出目的
最新研究表明,视觉语言模型(VLMs)虽在零样本图文匹配任务中展现出卓越性能,并可迁移至目标检测与分割等下游任务,但其在物体计数领域的应用仍存在重大挑战。
提出方法
本研究首次探索了视觉语言模型在类别无关物体计数中的迁移方法,提出首个端到端的开放词汇物体密度图预测框架——CLIP-Count,其核心创新包括:
通过引入块- 文本对比损失函数,实现文本嵌入与密集视觉特征的对齐,指导模型学习适用于密集预测的块级视觉表征。
设计分层块- 文本交互模块,在多层次视觉特征间传递语义信息,充分挖掘预训练 VLMs 的图文对齐知识。
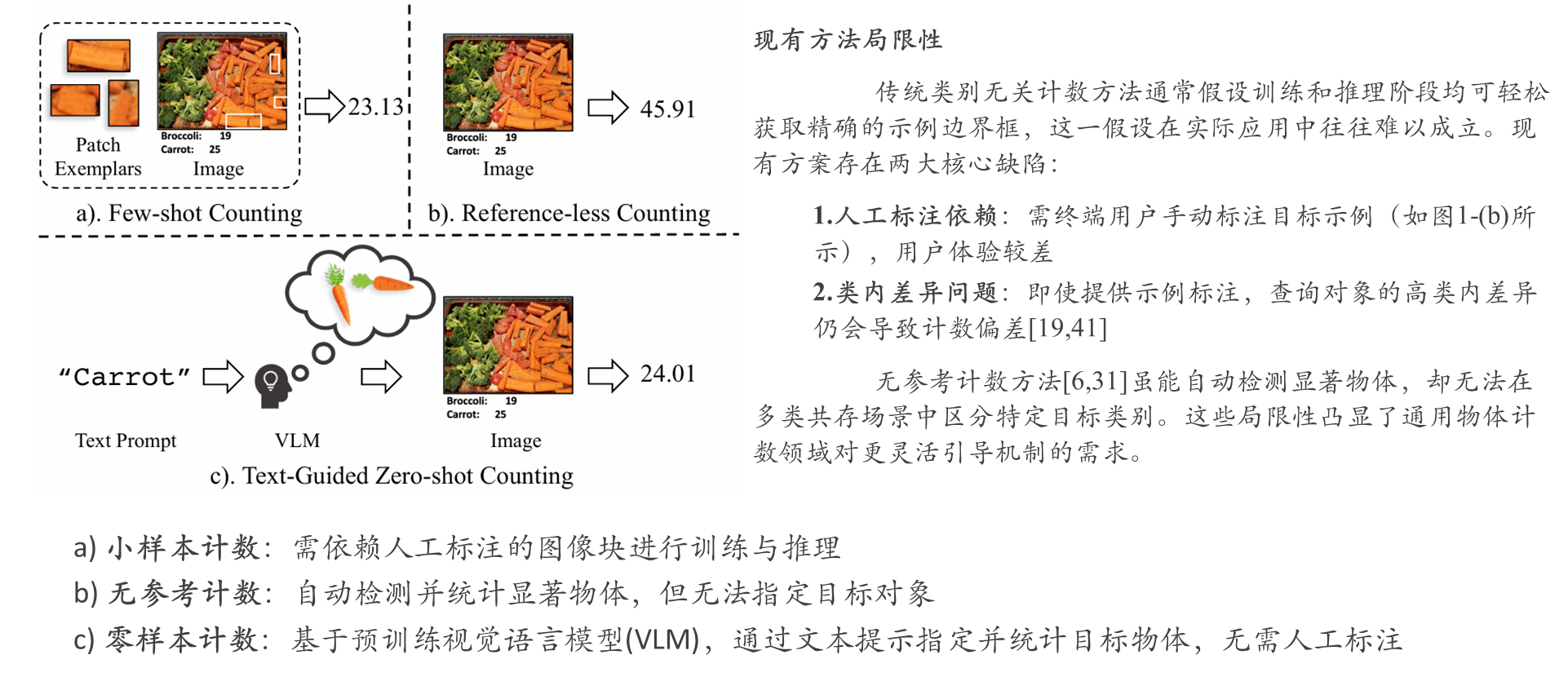
文本引导零样本计数
本研究突破"示例与查询图像必须具有自相似性"的传统认知,提出文本引导的零样本物体计数新范式(图1-(c)),其核心优势包括:
技术挑战与解决方案
文本引导面临三重挑战:
针对上述问题,基于对比语言-图像预训练模型(CLIP)提出CLIP-Count框架:
少样本目标统计
小样本物体计数算法致力于建立通用模型,通过示例对象作为推理引导实现任意物体的计数。
开创性工作
后续技术发展
当前方法主要沿两个方向推进:
采用视觉 Transformer ( ViT )等先进架构增强特征提取能力(如 CounTR[19] 、 LOCA )
无参考计数方法
无参考计数技术作为无需人工标注的类别无关计数新方向,近期取得显著进展:
核心局限:现有方法虽无需示例输入,但无法在多类共存场景中指定目标对象
零样本计数创新
最新研究提出仅需类别名称即可完成推理的零样本计数:
该方案仍需块级监督训练,而本文方法可实现完全端到端的无监督学习
Reference-less Counting,Zero-shot Counting,Few-shot Counting,单元域泛化以及域自适应之间的区别?(非常重要)
| 方法 | 核心目标 | 数据依赖 | 适用场景 |
| Reference-less Counting | 无需任何参考示例(但是训练的时候还是需要标签作为损失更新模型的),直接计数图像中的物体(依赖通用特征或启发式规则)。 | ❌ 无参考信息 | 通用物体计数(如人群、车辆),无需特定类别先验。 |
| Zero-shot Counting (ZSC) | 计数训练中未见过的新类别(但是训练的时候还是需要标签作为损失更新模型的),依赖语义信息(如类别名称或文本描述)。 | ❌ 无目标类别标注(不同类别) | 新商品盘点、稀有物种监测等开放世界场景。 |
| Few-shot Counting | 通过极少量参考示例(如1~5张标注图像)计数新类别(但是训练的时候还是需要标签作为损失更新模型的)。 | ⭕ 少量目标类别参考 | 数据稀缺场景(如医学细胞计数),需快速适应新类别。 |
| 单域泛化 (SDG) | 在单一源域上训练,泛化到未知的多个目标域(域偏移)(但是训练的时候还是需要标签作为损失更新模型的)。 | ❌ 仅单一源域数据(同一类别) | 模型需部署到未知环境(如自动驾驶在不同天气下的鲁棒性)。 |
| 域自适应 (DA) | 利用源域数据和无标签(或少量标签)目标域数据,对齐分布以减少域偏移(但是训练的时候还是需要标签作为损失更新模型的)。 | ⭕ 需目标域数据(无监督DA可无标签-同一类别) | 跨设备/场景迁移(如合成数据→真实数据)。 |
❌:表示不包含(不具有);⭕表示包含(或具有)
| 方法 | 典型技术 | 挑战 |
| Reference-less | • 密度图回归(如MCNN) | 难以区分相似背景的物体,依赖手工特征。 |
| Zero-shot | • 多模态对齐(CLIP + 文本提示) | 依赖预训练模型的语义泛化能力,对新类别描述敏感。 |
| Few-shot | • 度量学习(如匹配网络) | 参考示例过少可能导致计数偏差。 |
| 单域泛化 | • 对抗生成(如StyleGAN) DCCUS和MPCount方法 | 仅用单一域数据模拟多样性困难。 |
| 域自适应 | • 域对齐(MMD/CORAL) | 需目标域数据,无监督DA易受噪声影响。 |
| 场景 | 适用方法 | 原因 |
| 商场人流统计 | Reference-less Counting | 无需知道行人具体身份,直接估计密度。 |
| 新品上架商品计数 | Zero-shot Counting | 新商品无历史数据,但可通过文本描述(如“蓝色保温杯”)定位。 |
| 病理细胞计数 | Few-shot Counting | 标注成本高,但可提供少量示例快速适配。 |
| 自动驾驶跨天气泛化 | 单域泛化 (SDG) | 训练数据仅为晴天,需泛化到雨雪天气。 |
| 合成数据训练→真实测试 | 域自适应 (DA) | 合成数据与真实数据存在分布差异,需对齐特征。 |
| 需求 | 推荐方法 |
| 无先验信息,直接计数 | Reference-less Counting |
| 新类别计数,仅有语义描述 | Zero-shot Counting |
| 新类别计数,有少量标注示例 | Few-shot Counting |
| 单一训练域,需泛化到未知环境 | 单域泛化 (SDG) |
| 源域与目标域数据分布不同但部分相关 | 域自适应 (DA) |
注:询问了一点模型和参考链接:https://blog.youkuaiyun.com/festaw/article/details/139475358
CLIP对比语言预训练模型

二 整体模型架构
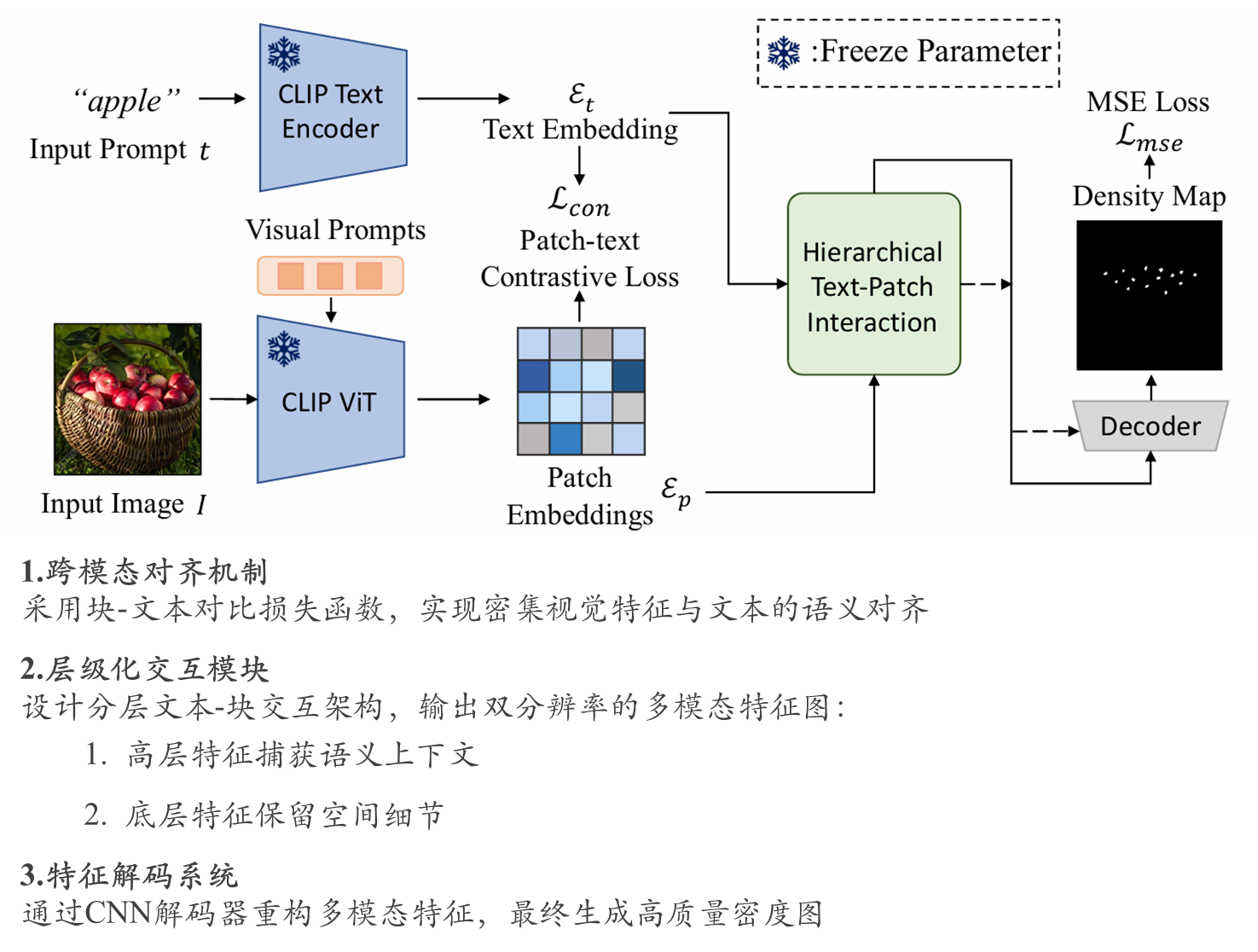
本文的目标

文本和密集视觉特征

class ContrastiveLoss(nn.Module):
def __init__(self, temperature=0.07, noise_text_ratio=0.0, normalize=False):
super(ContrastiveLoss, self).__init__()
self.temperature = temperature
self.noise_text_ratio = noise_text_ratio
self.normalize = normalize
def forward(self,
patch_embedding,
img_embedding,
gt_text_embedding_map,
noise_text_embeddings,
gt_density
):
"""
Args:
patch_embedding: TODO (B, 196, 512) embedding of image patch feature
img_embedding: (B, 1, 512) embedding of image feature
text_embedding: (B, 1, 512), ground truth text embedding
noise_text_embeddings:TODO (N, 1, 512), noise text embeddings
gt_density: (B, 384, 384), ground truth density map
"""
#TODO 将GT Density map缩放到指定大小
gt_density = F.interpolate(gt_density.unsqueeze_(1), size=(224, 224), mode='nearest')
#TODO 下采样操作,和VIT的conv1一样操作
density_mask = F.max_pool2d(gt_density, kernel_size=16, stride=16, padding=0) #same as ViT conv1
#TODO 对于大于0的位置,表示存在人群或者物体
density_mask = density_mask > 0.
density_mask = density_mask.permute(0, 2, 3 ,1) # (B, 14, 14, 1)
#TODO 文本嵌入向量,维度转换为何图像的patch embedding一样大小
gt_text_embedding_map = gt_text_embedding_map.unsqueeze(1).expand(-1, 14, 14, -1)
# TODO [B, 14, 14, 512], contains both gt and noise text embedding
fused_text_embedding_map = gt_text_embedding_map
pos_mask = density_mask.squeeze_(-1) # (B, 14, 14, 1)
#TODO 图像的patch embedding
patch_embeddings = patch_embedding.reshape(-1, 14, 14, 512)
#TODO 自动归一化向量并计算余弦相似性 batch cosine similarity, this function automatically normalizes the vectors
sim_map = F.cosine_similarity(patch_embeddings, fused_text_embedding_map , dim=-1) # (B, 14, 14)
# TODO 对二值密度图求和 得到正样本数量 sim_global = F.cosine_similarity(img_embedding, fused_text_embedding_map , dim=-1) # (B, 1)
n_pos = torch.sum(pos_mask, dim=(1, 2)) # TODO (B) how many positive samples in each batch
# if n_pos == 0, set to 1 to avoid nan TODO 得到正样本
n_pos = torch.where(n_pos == 0, torch.ones_like(n_pos), n_pos)
#infoNCE
sim_map = torch.exp(sim_map / self.temperature)
#TODO 分别求解负样本数量和正样本数量
pos_sum = torch.sum(torch.where(pos_mask, sim_map, torch.zeros_like(sim_map)), dim=(1, 2)) + 1e-5
neg_sum = torch.sum(torch.where(~pos_mask, sim_map, torch.zeros_like(sim_map)), dim=(1, 2)) + 1e-5
loss = -torch.log(pos_sum / (pos_sum + neg_sum))
if self.normalize:
loss = loss / n_pos
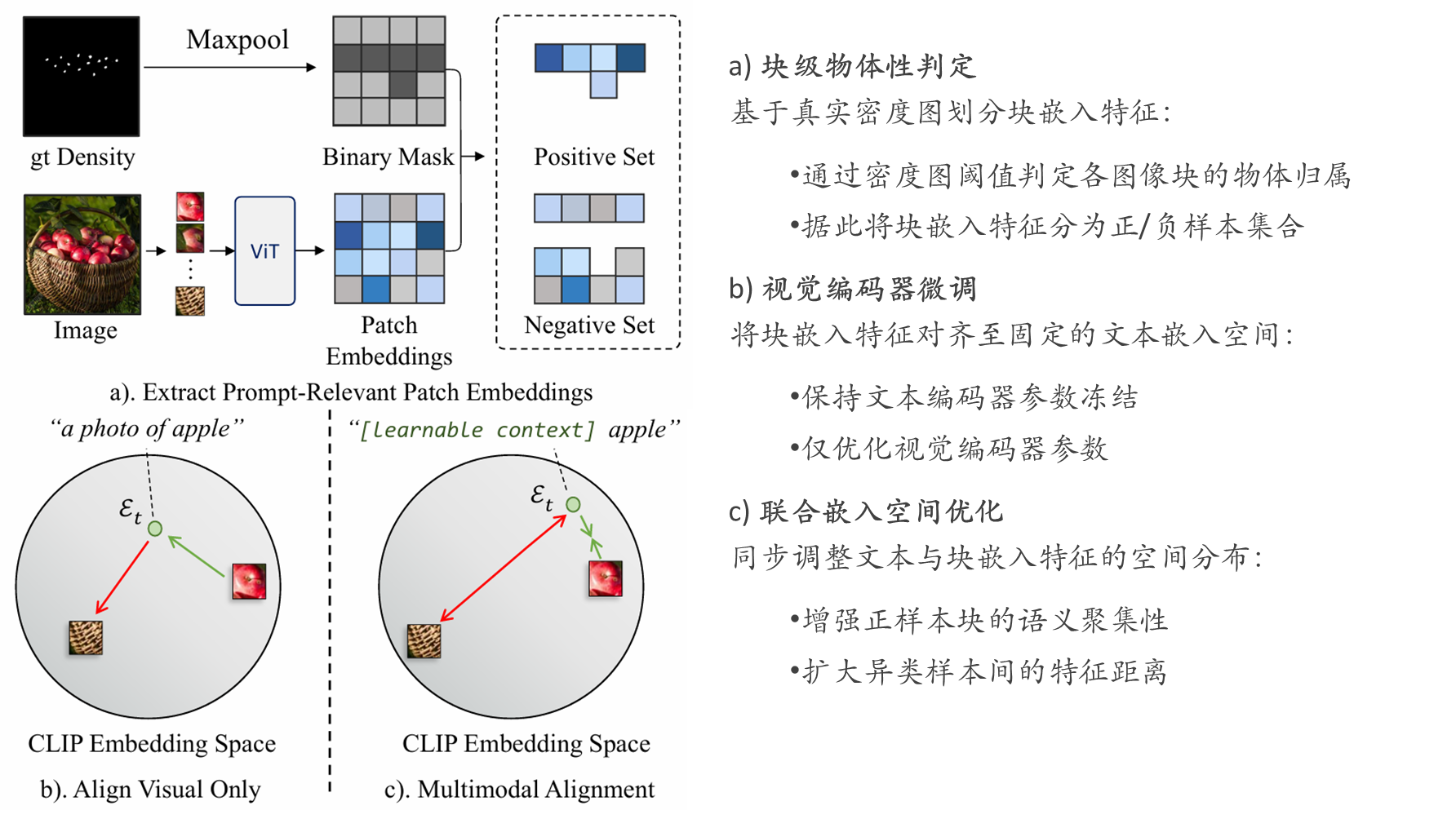
return loss.mean()视觉提示微调
传统"预训练+微调"范式存在两大局限:
高效迁移方案:采用以下策略实现CLIP预训练知识的高效迁移:
该方案优势:
关于视觉微调:https://arxiv.org/pdf/2203.12119v2.pdf
分层的文本patch交互模块
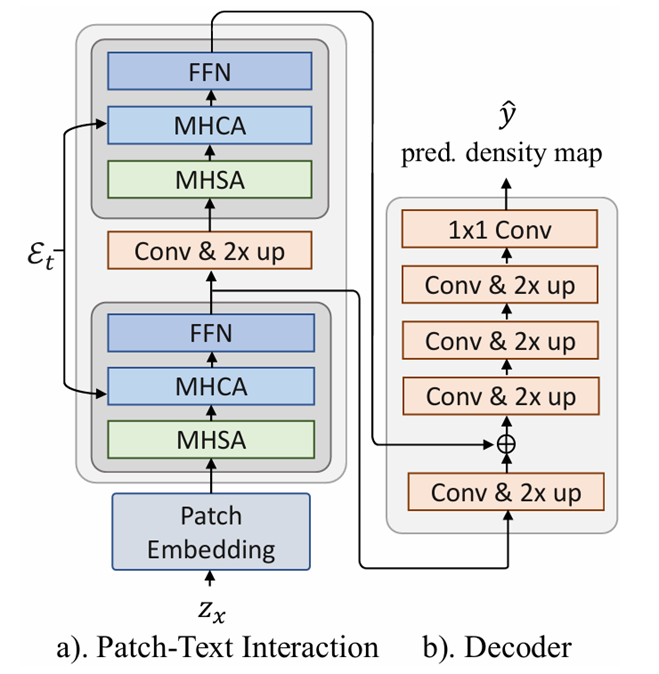

MHSA(多头自注意力)和MHCA(多头交叉注意力)
class CrossAttention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.wq = nn.Linear(dim, dim, bias=qkv_bias)
self.wk = nn.Linear(dim, dim, bias=qkv_bias)
self.wv = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x, y):
B, Nx, C = x.shape
Ny = y.shape[1]
# BNxC -> BNxH(C/H) -> BHNx(C/H)
q = self.wq(x).reshape(B, Nx, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
# BNyC -> BNyH(C/H) -> BHNy(C/H)
k = self.wk(y).reshape(B, Ny, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
# BNyC -> BNyH(C/H) -> BHNy(C/H)
v = self.wv(y).reshape(B, Ny, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
attn = (q @ k.transpose(-2, -1)) * self.scale # BHNx(C/H) @ BH(C/H)Ny -> BHNxNy
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, Nx, C) # (BHNxNy @ BHNy(C/H)) -> BHNx(C/H) -> BNxH(C/H) -> BNxC
x = self.proj(x)
x = self.proj_drop(x)
return x
class CrossAttentionBlock(nn.Module):
def __init__(
self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
#TODO 注意:自注意力和交叉注意力之间的区别是,交叉注意力的query和key来自不同的输入
self.norm0 = norm_layer(dim)
self.selfattn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop
)
self.drop_path0 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm1 = norm_layer(dim)
self.attn = CrossAttention(
dim, num_heads=num_heads, qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop
)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path1 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio),
act_layer=act_layer, drop=drop)
self.drop_path2 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x, y):
x = x + self.drop_path0(self.selfattn(self.norm0(x)))
x = x + self.drop_path1(self.attn(self.norm1(x), y))
x = x + self.drop_path2(self.mlp(self.norm2(x)))
return x密度图回归

综合实验对比
数据介绍
| 数据集名称 | 图像数量 | 主要特征 | 实验用途 |
| FSC-147 | 6,135 | - 涵盖147个物体类别 | 类别无关计数基准测试 |
| CARPK | 1,448 | - 俯视角停车场图像 | 跨数据集迁移能力评估 |
| ShanghaiTech | 1,198 | Part A: 482张(训练400/测试82) | 人群计数任务性能验证 |
实验细节

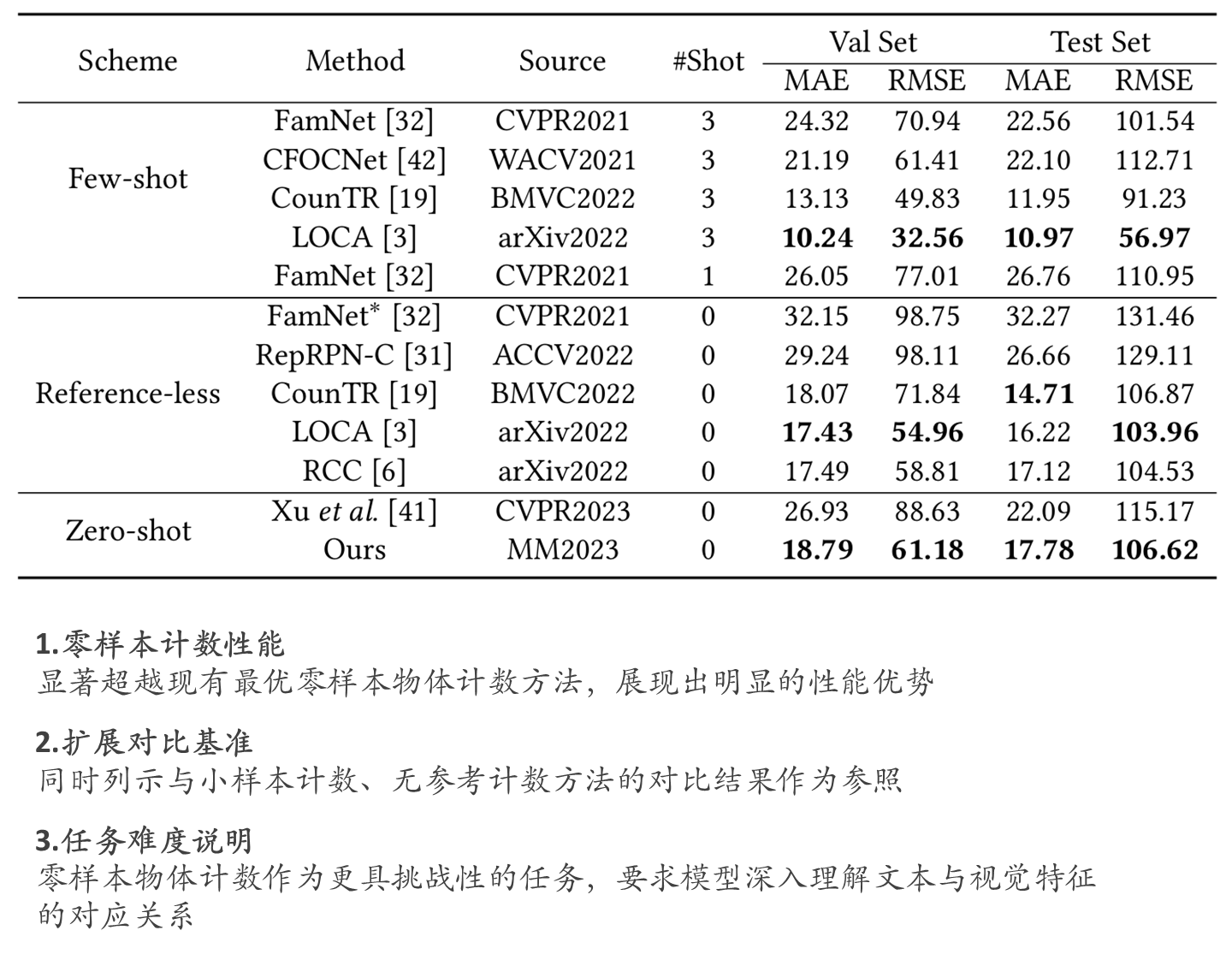
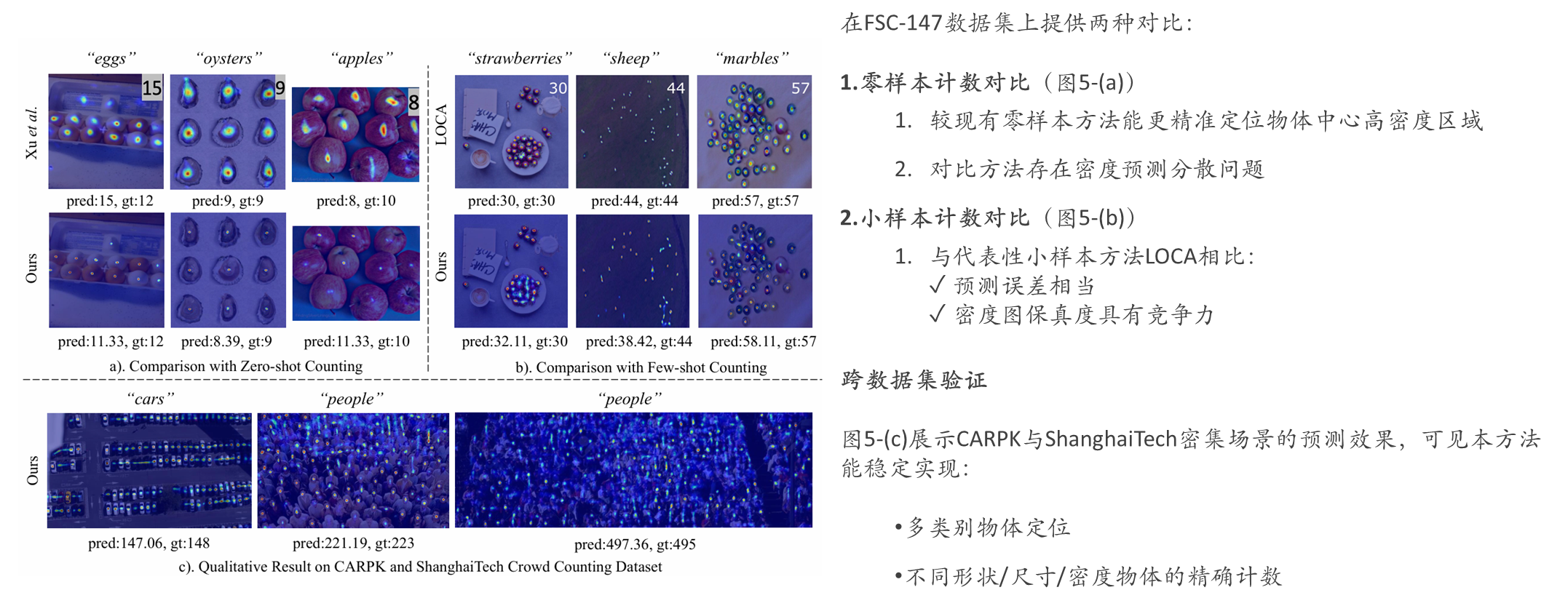
FSC-147实验效果
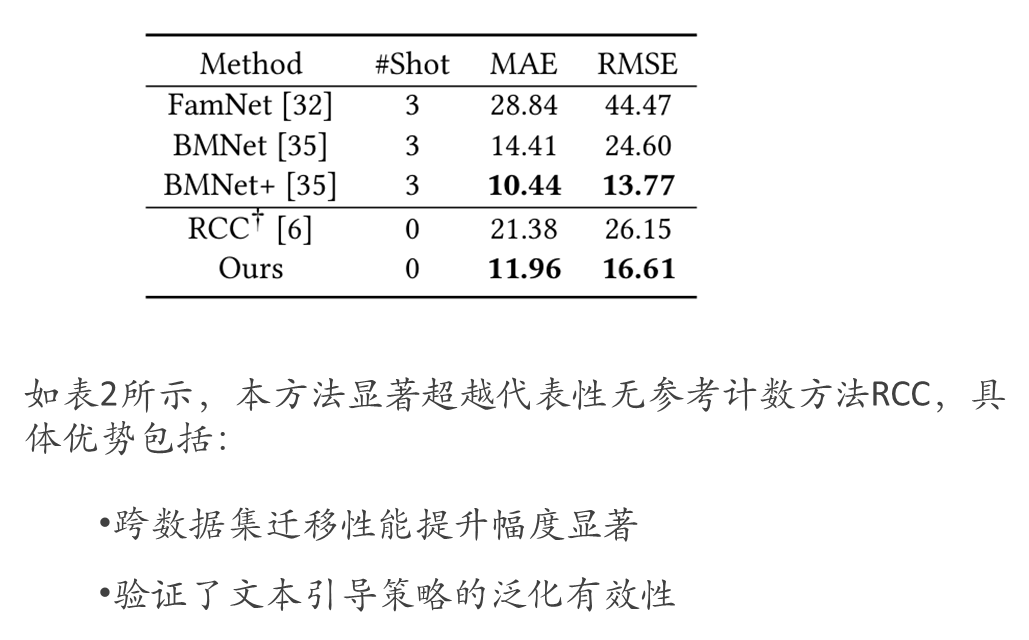
CARPK实验效果
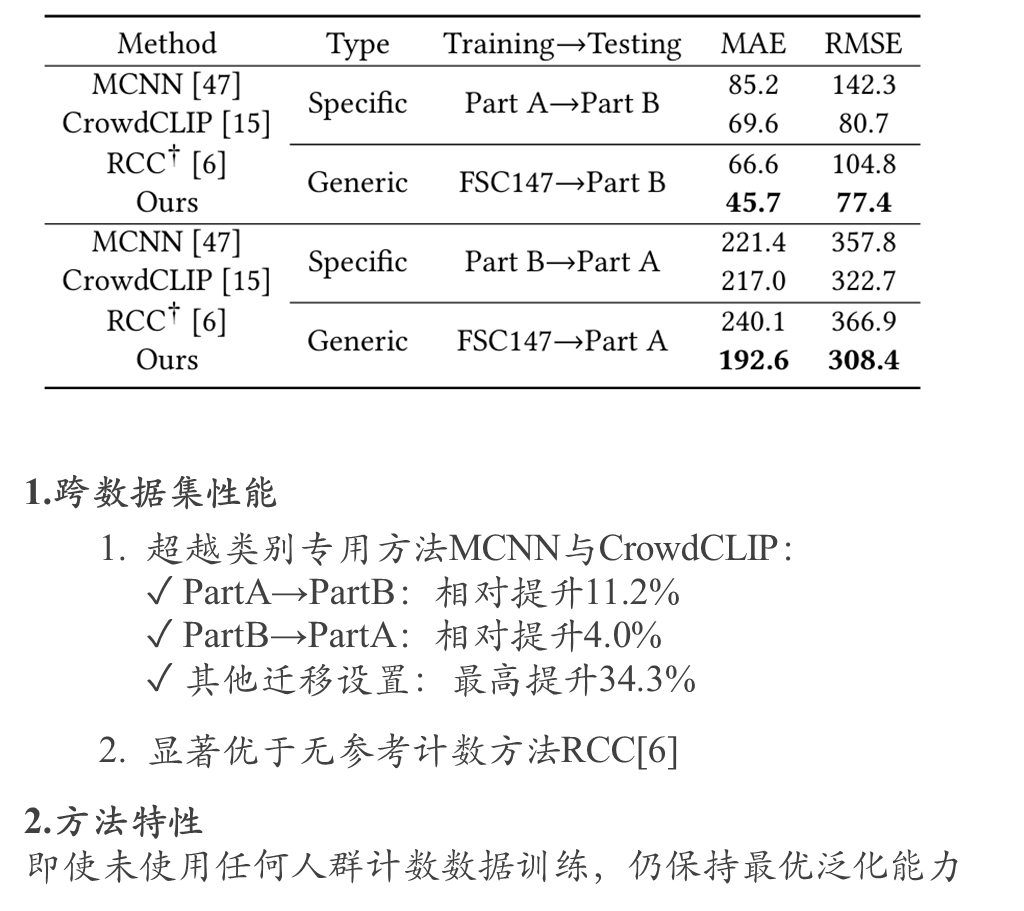
ShanghaiTech crowd counting实验效果
消融实验
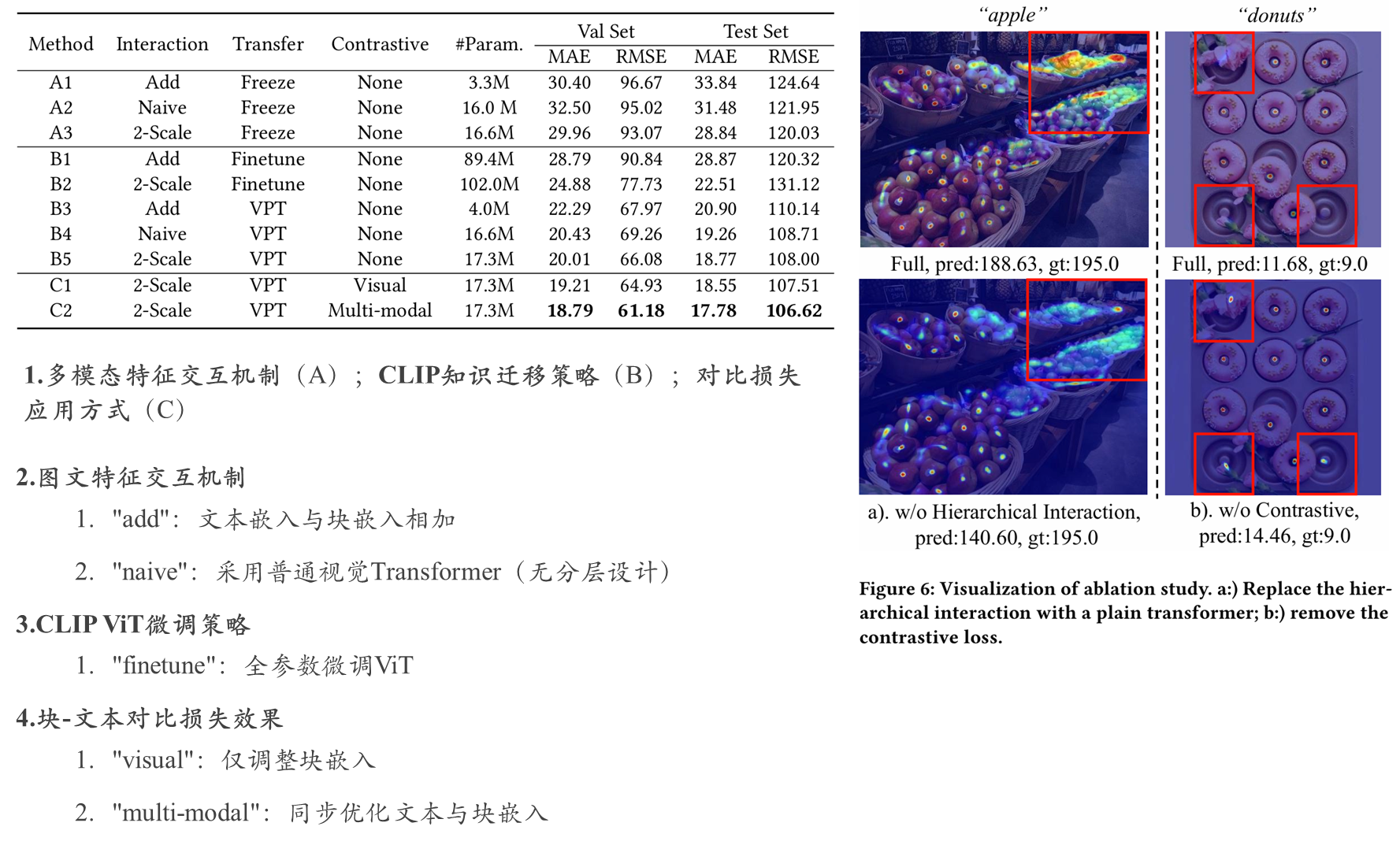
可视化效果对比
CLIP-Count局限性

附件材料大家自己去看一下。



















 1032
1032

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









