



 本文详细介绍了在Golang中重构Raft共识算法的过程,包括Leader选举、发送心跳包、日志添加与提交、持久化存储以及日志压缩。在Leader选举中,通过修复随机数生成问题解决了选举冲突。在日志应用方面,通过条件变量和ApplyMsg对象实现了日志的提交和应用。持久化存储确保了服务器重启后的状态恢复,日志压缩则有效减少了存储空间的占用。
本文详细介绍了在Golang中重构Raft共识算法的过程,包括Leader选举、发送心跳包、日志添加与提交、持久化存储以及日志压缩。在Leader选举中,通过修复随机数生成问题解决了选举冲突。在日志应用方面,通过条件变量和ApplyMsg对象实现了日志的提交和应用。持久化存储确保了服务器重启后的状态恢复,日志压缩则有效减少了存储空间的占用。
Lab2 Raft
因为以前的版本很多细节出现问题,导致后面的lab4出现很多bug,所以对raft进行重写。
PartA
本部分需要完成Raft的leader选举和发送心跳包(log为空的AE)。
-
实验流程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nyInNatp-1654832766292)(MIT-6.824.assets/image-20220309154651021.png)]](https://i-blog.csdnimg.cn/blog_migrate/f6740bfaf5c3a39a125d2ecd732fcc7f.png)
-
对象设计
本次实验的主要对象有Raft,ApplyMsg,LogEntry。其中Raft代表了一个Raft对等节点,LogEntry则代表日志。
-
Raft
每次进行leader选举,每个对等节点peer需要从自身的Raft对象中读取自身的term,以及最后一条日志的信息,然后将自己的投票结果存在votedFor中。在不同的阶段,peer将自己的角色存储在role中从而执行不同的任务。每个raft对象中通过存储选举的计时器来实现定时选举。
type Raft struct { mu sync.Mutex // Lock to protect shared access to this peer's state peers []*labrpc.ClientEnd // RPC end points of all peers persister *Persister // Object to hold this peer's persisted state me int // this peer's index into peers[] dead int32 // set by Kill() // Your data here (2A, 2B, 2C). // Look at the paper's Figure 2 for a description of what // state a Raft server must maintain. //持久化变量 currentTerm int //当前任期 votedFor int //记录当前投票的服务器 logs []LogEntry //日志 commitIndex int //提交的日志编号(优化) //易失变量 lastApplied int //已应用的日志下标 nextIndex []int //follower中的同步起点,初始为lastLogIndex+1,server->Index matchIndex []int //follower已同步的索引,初始为0,server->Index //其他 currentState string //当前状态,leader,follower,candidate grantVotes int //获得的票数 //选举计时器 electionTimer *time.Timer electionTimerLock sync.Mutex //心跳计时器 heartbeatTimer *time.Timer heartbeatTimerLock sync.Mutex applyCh chan ApplyMsg //应用层的提交队列 applyCond *sync.Cond //唤醒应用消息的进程发送信息,在commit时唤醒 } -
LogEntry
日志标号可以通过快照(2D)存储的编号加上当前日志数组的下标计算得到。type LogEntry struct { Term int //该日志所处的任期 Command interface{} //该日志包含的命令 }
-
-
流程设计
-
初始化Raft对等节点
Raft节点启动主要需要将初始化term为0,设置为follower,并且为日志分配足够的空间,投票人初始化为未投票状态,以及重启计时器。并且初始化随机种子,用于随机选择选举计时,随机种子在初始化时选择一次就行,不用在每次随机选举时再选。
rf := &Raft{} rf.peers = peers rf.persister = persister rf.me = me // Your initialization code here (2A, 2B, 2C). rf.currentTerm = 0 rf.votedFor = -1 rf.logs = make([]LogEntry, 0) rf.commitIndex = 0 rf.nextIndex = make([]int, len(peers)) rf.matchIndex = make([]int, len(peers)) rf.currentState = FOLLOWER rf.applyCh = applyCh rf.applyCond = sync.NewCond(&rf.mu) rand.Seed(time.Now().Unix()) rf.electionTimerLock.Lock() rf.electionTimer = time.NewTimer(time.Duration(rand.Int())%electionTimeoutInterval + electionTimeOutStart) rf.electionTimerLock.Unlock() rf.heartbeatTimerLock.Lock() rf.heartbeatTimer = time.NewTimer(heartbeatInterval) rf.heartbeatTimerLock.Unlock() // initialize from state persisted before a crash go rf.electionTicker() go rf.appendEntriesTicker() return rf
-
-
随机数补充
之前出现一个bug选举经常出现碰撞导致不能选举出leader,后来发现是因为在重置选举计时器时又重置了随机种子,go语言的随机是伪随机数,如果随机种子相等则第一个数是相同的,而后面再出现的数会不一样,所以在初始化每个peer的第一轮选举超时时间是一样的,但后面的就不一样了,而如果每次重启计时器就重置随机种子,因为第一轮超时时间相同会发生碰撞且在相同的时间发起第二轮,所以这时的重新生成的随机种子又是一样的,导致又是相同的超时时间,也就导致一直碰撞选不出leader。下面是对rand的测试。package main import ( "fmt" "math/rand" "time" ) func main() { for i := 0; i < 5; i++ { go func(x int) { rand.Seed(1) fmt.Println(x, rand.Int()) fmt.Println(x, rand.Int()) }(i) } time.Sleep(3 * time.Second) } //结果如下,可以看到第一轮是相同的,第二个就不一样了。 4 5577006791947779410 4 8674665223082153551 0 5577006791947779410 0 6129484611666145821 3 5577006791947779410 3 4037200794235010051 1 5577006791947779410 1 3916589616287113937 2 5577006791947779410 2 6334824724549167320在当初遇到这个bug我考虑在进入选举goroutine之前打印日志查看,结果2A跑通了,而如果不打印就又会选举不出来,后来猜想是因为多个goroutine调用fmt函数导致每个peer执行选举函数有了先后顺序,先打印先执行选举的可以成为leader,即使超时时间相同,定时器几乎同时返回,但是由于在启动选举之前共同调用fmt会发生冲突,就会强制有一个先后的顺序,在后面的等待前面的fmt打印的时候,可能更前一个的peer已经发来了投票请求。为了验证这个想法,我直接把重置的超时时间设为一个定值,然后在超时调用选举函数前加上一个fmt,然后测试2A还是能够成功。
//将重置选举时间改为定时长度 func (rf *Raft) resetElectionTimer() { rf.electionTimer.Reset(electionTimeOutStart) }//在开始选举前打印一个. func (rf *Raft) electionTicker() { for rf.killed() == false { <-rf.electionTimer.C fmt.Print(".") go rf.startElection() rf.resetElectionTimer() } }2A测试通过
Test (2A): initial election ... ............ ... Passed -- 3.7 3 62 15244 0 Test (2A): election after network failure ... ............................................. ... Passed -- 7.1 3 186 33678 0 Test (2A): multiple elections ... ......................................................................... ... Passed -- 7.1 7 816 145568 0 PASS ok 6.824/raft 18.139s -
leader选举
计时器超时后就会进入选举
func (rf *Raft) electionTicker() { for rf.killed() == false { <-rf.electionTimer.C go rf.startElection() rf.resetElectionTimer() } }如果自身就是leader直接退出选举过程,否则需要进入竞选人candidater。因为需要修改raft的信息所以需要在执行前上锁,防止两个peer在RPC通信时互相持有锁导致死锁。
rf.mu.Lock() //注意RPC调用前要释放锁防止多个拥有锁的peer之间形成死锁 //这里能够使用defer释放是因为这里的rpc都使用的是开辟新的goroutine异步调用,所以主函数可以快速释放 defer rf.mu.Unlock() if rf.currentState != LEADER { //竞选 }开始选举首先需要将投票给自己,并且获得的票数也加一。然后将任期加一作为竞选Leader的新一轮term,然后准备发起新一轮选举的RPC请求,请求包含了新的term,自己的id,以及自己的最后的一个日志下标和term,这两个信息主要是为了确保竞选成功的peer拥有最新的日志(term最大或者term相同但是日志更长)
rf.currentState = CANDIDATE rf.votedFor = rf.me rf.currentTerm++ rf.persist() //DPrintf("[StartElection] Server:%d In term:%d try to elect", rf.me, rf.currentTerm) rf.grantVotes = 1 args := RequestVoteArgs{ Term: rf.currentTerm, CandidateId: rf.me, LastLogIndex: rf.getLastIndex(), LastLogTerm: rf.getLastTerm(), }通过RPC发送RequestVote给各个对等点,这里采用开启多个goroutine异步发送,加快效率和减少阻塞。然后根据接收结果进行下一步的处理。
for server := range rf.peers { if server == rf.me { continue } go func(server int, currentTerm int, args RequestVoteArgs) { reply := RequestVoteReply{} ok := rf.peers[server].Call("Raft.RequestVote", &args, &reply) if ok { rf.handleVoteResult(currentTerm, &reply) } }(server, rf.currentTerm, args) }其他peer接受到RPC请求后,首先检查请求中的term,如果小于自身,则直接返回自己的term以及不投票的回复。
reply.Term = rf.currentTerm reply.VoteGranted = false if args.Term < rf.currentTerm { return }如果请求的term大于自身, 则说明这个节点的term已经落后,所以可以直接更新自己的term,并且设置自己的状态为follower,终止自己的选举过程和投的票。然后修改回复的term为修改的term。
if args.Term > rf.currentTerm { rf.currentTerm = args.Term rf.currentState = FOLLOWER rf.votedFor = -1 reply.Term = rf.currentTerm rf.persist() }
然后检查竞选者是不是比自己的日志要新。只有比自己新才会投票给他。投完票后需要重新启动竞选的计时器。
go if rf.votedFor == -1 || rf.votedFor == args.CandidateId { //检测竞选者是不是比自己的日志要新 if args.LastLogTerm < rf.getLastTerm() || (args.LastLogTerm == rf.getLastTerm() && args.LastLogIndex < rf.getLastIndex()) { return } rf.votedFor = args.CandidateId reply.VoteGranted = true rf.persist() rf.resetElectionTimer() }
发送方接收RPC请求返回的结果reply后,需要检查是不是已经是新的任期。因为发起rpc请求的过程解锁了,所以有可能收到其他peer的请求导致修改了term,那么这时就可以直接停止处理了。此外还可能收到以前的旧的包,同样也是直接返回。
```go
if currentTerm != rf.currentTerm {
return
}
//收到旧时期的包
if reply.Term < rf.currentTerm {
return
}
如果回复中的term大于自身,说明该peer不是拥有最新日志的节点,则更新自己的term信息后停止竞选。
```go
if reply.Term > rf.currentTerm {
rf.currentState = FOLLOWER
rf.currentTerm = reply.Term
rf.votedFor = -1
rf.persist()
rf.resetElectionTimer()
return
}
如果回复给该peer投票并且自己当前状态也是竞选者时则可以更新获得的票数,如果超过一半则成功竞选,修改状态为Leader,并且快速重置n次心跳计时器发送心跳包,因为间隔很短所以期间没有新的日志所以发送的是空的日志也就是心跳包。并且修改nextIndex和matchIndex分别为当前peer的最后一个日志加1和0.
```go
if reply.VoteGranted && rf.currentState == CANDIDATE {
rf.grantVotes++
if rf.grantVotes > len(rf.peers)/2 {
rf.currentState = LEADER
//DPrintf("[NewLeader],Server:%d become leader", rf.me)
//发送心跳包
for i := 0; i < len(rf.peers); i++ {
if i == rf.me {
continue
}
rf.resetHeartbeatTimer(rightnow)
rf.nextIndex[i] = rf.getLastIndex() + 1
rf.matchIndex[i] = 0
}
rf.resetElectionTimer()
}
```
-
发送心跳包
心跳包就是空的日志。当新的Leader竞选后就会快速重置心跳计时器开始广播日志。因为这个间隔很短所以还没有新的日志,所以发送的是空的日志。因为每次发送日志为自己的最后一个日志和下一个发送的日志的前一个之间的日志,而刚刚竞选成功的leader由于刚刚更新的nextIndex就是自己当前的最后的日志的下一个,因此preLog就等于lastIndex,所以这里生成的日志切片长度为0.
preLogIndex := rf.nextIndex[server] - 1 theLogLengthToSend := rf.getLastIndex() - preLogIndex //fmt.Printf("theLogLengthToSend:%d\n", theLogLengthToSend) theLogToSend := make([]LogEntry, theLogLengthToSend)因为心跳包就是空的AE包,所以还需要设置preTerm用于和其他peer同步,而在2A的测试里因为没有测试,所以preLogIndex会一直为0,也就是没法通过logs找到对应日志再求得term,所以需要特殊处理为0.
var preLogTerm int //初始没有日志的情况,直接设置preLogTerm为0 if preLogIndex == 0 { preLogTerm = 0 } else { preLogTerm = rf.getLogTermWithIndex(preLogIndex) }然后将心跳包通过RPC发送给其他peer,因为是空日志,所以只会检查收到的请求中的term,如果小于自身说明这个leader不是最新的,则直接返回自己的term让其不能继续成为leader。大于自身则修改自己的term并且更新为follower,并且重置计时器。if args.Term < rf.currentTerm { reply.Success = false reply.Term = rf.currentTerm return } //大于或等于自身则直接转follower,并且肯定有超过一半的投给它票,直接跟随 if args.Term >= rf.currentTerm { rf.currentTerm = args.Term rf.currentState = FOLLOWER rf.votedFor = args.LeaderId rf.persist() }如果新leader收到的心跳回复的term大于自身,则重新成为follower
if reply.Term > rf.currentTerm { rf.currentTerm = reply.Term rf.currentState = FOLLOWER rf.votedFor = -1 rf.persist() rf.resetElectionTimer() return }因为测试脚本需要知道当前各个节点的状态,看是否选出了leader,所以还需要完成一个方法用于检测当前的状态。
func (rf *Raft) GetState() (int, bool) { var term int var isleader bool // Your code here (2A). rf.mu.Lock() defer rf.mu.Unlock() term = rf.currentTerm isleader = rf.currentState == LEADER return term, isleader }
PartB
本部分需要完成新日志的添加和提交。
- 实验流程
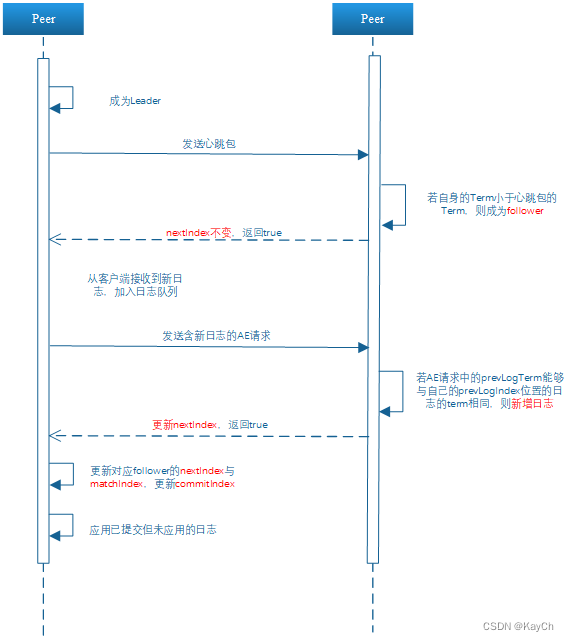
-
对象设计
在2A部分的基础上,需要在Raft对象中新增部分变量,并且增加ApplyMsg对象由于应用已提交日志
-
Raft
新增commitIndex表示已提交的日志下标,以及lastApplied表示已经应用的日志下标,通过对比这两个值来推进日志的应用。并且设置applyCh接收已提交日志来代表日志的应用,并通过设置条件变量唤醒应用日志。(老版本用的循环,会导致很多没有用的执行)
type Raft struct { mu sync.Mutex // Lock to protect shared access to this peer's state peers []*labrpc.ClientEnd // RPC end points of all peers persister *Persister // Object to hold this peer's persisted state me int // this peer's index into peers[] dead int32 // set by Kill() //持久化变量 currentTerm int //当前任期 votedFor int //记录在当前任期投票给谁了 logs []LogEntry commitIndex int //最大已提交索引(论文中可以不持久化,这里持久化进行了优化就不用崩溃后重启再重新计算) //易失变量,crash后丢失 lastApplied int //当前应用到状态机的索引 nextIndex []int //每个follower的log同步起点索引(初始为leader log的最后一项) matchIndex []int //每个follower的log同步进度(初始为0) //自定义的必需变量 voteCounts int //投票计数值 currentState string //当前的状态 //选举定时器 timer *time.Timer timerLock sync.Mutex //心跳定时器 heartbeatTimer *time.Timer heartbeatTimerLock sync.Mutex applyCh chan ApplyMsg //应用层的提交队列 applyCond *sync.Cond //用来唤醒给应用层提交的协程,在commit更新时唤醒 } -
ApplyMsg
设置ApplyMsg用来代表待应用的日志,需要记录这次应用是已经提交的日志,并且记录这次提交的日志命令内容和下标。
type ApplyMsg struct { CommandValid bool Command interface{} CommandIndex int }
-
-
流程设计
在2A实验部分的基础上,主要增加了日志的应用,以及append相关操作的增加和修改。每一次的append都需要prevLogIndex和prevLogTerm匹配才能够发送,并且发送从nextIndex到lastLogIndex之间的所有日志,这就确保在当前term中发送的日志的同时也能确保以前term的日志也能够同步,即使有些follower丢失部分日志,在成功接收新的日志的同时也能够补齐以前丢失的日志。应用日志时需要注意只能提交当前term的日志,而由于在同步日志时也会将以前的日志也同步才行,所以当前任期能够提交的时候肯定前面的日志也能提交了。
-
应用日志
通过条件变量来激活应用协程开始应用日志,激活条件是当peer增加了commitIndex,这个时候再检查commitIndex是否大于已经应用的日志下标。
func (rf *Raft) applyGoRoutine() { for !rf.killed() { rf.mu.Lock() for rf.lastApplied >= rf.commitIndex { rf.applyCond.Wait() } rf.lastApplied++ msg := ApplyMsg{CommandValid: true, Command: rf.getLogWithIndex(rf.lastApplied).Command, CommandIndex: rf.lastApplied, SnapshotValid: false} rf.mu.Unlock() INFO("[%d]---Have committed index %d of logs to UpperFloor", rf.me, rf.lastApplied) rf.applyCh <- msg } } -
新增日志
通过设置定时器定时发出AE请求来同步其他的peer。func (rf *Raft) appendEntriesTicker() { for rf.killed() == false { <-rf.heartbeatTimer.C go rf.boardEntries() rf.resetHeartbeatTimer(heartbeatInterval) } }通过存储的各个peer的nextIndex和自己最新的日志来确认给这个peer发送的日志长度。如果是心跳包这里计算出来的应该为0。然后通过preLog计算出preLog的Term用于同步,然后发起RPC请求给其他的节点。
theLogLengthToSend := rf.getLastIndex() - preLogIndex //fmt.Printf("theLogLengthToSend:%d\n", theLogLengthToSend) theLogToSend := make([]LogEntry, theLogLengthToSend) DPrintf("[BoardEntries],nextIndex:%d,lastsspoint:%d", rf.nextIndex[server], rf.lastSSPointIndex) copy(theLogToSend, rf.logs[rf.getGlobalToRealIndex(rf.nextIndex[server]):]) //处理preLogTerm边界问题 var preLogTerm int //初始没有日志的情况,直接设置preLogTerm为0 if preLogIndex == 0 { preLogTerm = 0 } else { preLogTerm = rf.getLogTermWithIndex(preLogIndex) } args := AppendEntriesArgs{ Term: rf.currentTerm, LeaderId: rf.me, PreLogIndex: preLogIndex, PreLogTerm: preLogTerm, Entries: theLogToSend, LeaderCommit: rf.commitIndex, } go func(server int, args AppendEntriesArgs) { reply := AppendEntriesReply{} ok := rf.peers[server].Call("Raft.AppendEntries", &args, &reply) if ok { //这里args和reply的信息较大,建议传递指针减少开销,并且可以增加准确率 rf.handleAppendResult(server, &args, &reply) } }(server, args) }follower接受到AE请求后,在term验证通过后,会根据请求中的prevLogTerm和prevLogIndex分情况处理:
1.如果不匹配(preLogIndex小于快照下标,preLogIndex大于日志最后的日志下标,或者PreLogTerm不相等(PreLogIndex肯定而不同)),这里进行优化,直接返回当前peer的commitIndex,这样下次传来的日志肯定是能够直接新增在后面,而不需要更多的传递(旧版是如果PreLogIndex大于自身的日志下标,最后则返回自身最后的日志下标,如果小于快照下标则请求传快照,而如果有日志但是不匹配则返回当前出现冲突的日志所在的term的第一个日志,显然这些方法虽然每次传输的数据不多,但是传递次数不止一次的)
2.如果匹配,则直接向后检索到第一个发生冲突的日志然后将日志新增在后面。
3.如果都匹配但是新增日志比当前的长,则直接把新增日志添加在preLogIndex后。上述判断主要遵循raft的以下准则:
1.如果两个不同的日志实体有相同的index和term,则这两个日志实体存储的内容相同。(leader只能增加,不能删除和修改)
2.如果两个不同的日志实体有相同的Index和term,则这两个日志前的所有日志都是相同的。(follower需要prevLogIndex对的上才能新增)
for i, j := args.PreLogIndex-rf.lastSSPointIndex, 0; i < len(rf.logs) && j < len(args.Entries); i, j = i+1, j+1 { //冲突了 if rf.logs[i].Term != args.Entries[j].Term { //只用比对Term,只要相同index的Term不同则不同 DPrintf("[AppendEntries1],preLogIndex:%d,lastsspoint:%d", args.PreLogIndex, rf.lastSSPointIndex) rf.logs = append(rf.logs[:rf.getGlobalToRealIndex(args.PreLogIndex)+1], args.Entries...) rf.persist() } } //没有冲突但比自身的长,则直接添加 if args.PreLogIndex+len(args.Entries) > rf.getLastIndex() { DPrintf("[AppendEntries2],preLogIndex:%d,lastsspoint:%d", args.PreLogIndex, rf.lastSSPointIndex) rf.logs = append(rf.logs[:rf.getGlobalToRealIndex(args.PreLogIndex)+1], args.Entries...) rf.persist() }follower如果成功接收AE的请求后,需要检查参数中带有的leadercommit参数,如果高于自身,则需要和leader进行同步,更新为自己最后一个日志下标和这个commitIndex的下标的最小值。并且通过条件变量去激活日志应用的阻塞协程。
if args.LeaderCommit > rf.commitIndex { preCommitIndex := rf.commitIndex if args.LeaderCommit > rf.getLastIndex() { rf.commitIndex = rf.getLastIndex() } else { rf.commitIndex = args.LeaderCommit } if preCommitIndex != rf.commitIndex { rf.applyCond.Broadcast() } }leader收到follower返回的AE reply后,需要检查返回的term是否高于自身以及自身的状态是否还是leader,如果不满足则直接返回
if reply.Term > rf.term { rf.changeRole(Follower) rf.resetElectionTimer() rf.term = reply.Term rf.mu.Unlock() return } //如果返回后自己已经不是leader则不能继续了 if rf.role != Leader || rf.term != args.Term { rf.mu.Unlock() return }leader收到回复需要先检查term,如果大于自身则说明出现更新的leader了,所以需要更新term并且重新成为follower。如果收到过时的回复直接忽略。如果自己不是leader或者不是发起这个请求时的term了也直接返回。
if reply.Term > rf.currentTerm { rf.currentTerm = reply.Term rf.currentState = FOLLOWER rf.votedFor = -1 rf.persist() rf.resetElectionTimer() return } //收到过时的直接忽略 if reply.Term < rf.currentTerm { return } //已经不是leader或新的term if args.Term != rf.currentTerm || rf.currentState != LEADER { return }
-
如果收到的回复是ok,则说明这个peer成功接收了发送的所有日志,则更新matchIndex和nextIndex,如果matchIndex更改了,则检查是不是有可以新提交的日志。通过对当前所有matchIndex和leader的最后一个日志的下标进行排序,选择中间左边的那个值,这个下标是超过一半的服务器拥有的日志。如果这个下标大于当前leader已提交的下标并且是当前term的则提交。
if reply.Success {
preMatch := rf.matchIndex[server]
rf.matchIndex[server] = Max(rf.matchIndex[server], args.PreLogIndex+len(args.Entries))
rf.nextIndex[server] = rf.matchIndex[server] + 1
//如果匹配的日志修改了,则检查是不是有可以新的提交的日志
if preMatch != rf.matchIndex[server] {
sortMatchIndex := make([]int, 0)
sortMatchIndex = append(sortMatchIndex, rf.getLastIndex())
for s, idx := range rf.matchIndex {
if s == rf.me {
continue
}
sortMatchIndex = append(sortMatchIndex, idx)
}
//对matchIndex从小到大排序
sort.Ints(sortMatchIndex)
//选择中间(偏小)的那一个,因为超过一半的值都大于或等于它,即有超过一半的服务器拥有该日志
newCommitIndex := sortMatchIndex[len(rf.peers)/2]
//只能提交自己任期的日志
if newCommitIndex > rf.commitIndex && rf.getLogTermWithIndex(newCommitIndex) == rf.currentTerm {
rf.commitIndex = newCommitIndex
rf.persist()
rf.applyCond.Broadcast()
}
}
}
如果返回的不是ok,则更新nextIndex为回复里的下标+1
rf.nextIndex[server] = reply.FollowerCommitIndex + 1
PartC
本部分需要完成持久化,主要需要对服务器当前的term,投票人votedFor和log[] (论文要求)进行持久化存储,此外还有快照的Index和term以及提交的日志编号commitIndex
- 实验流程
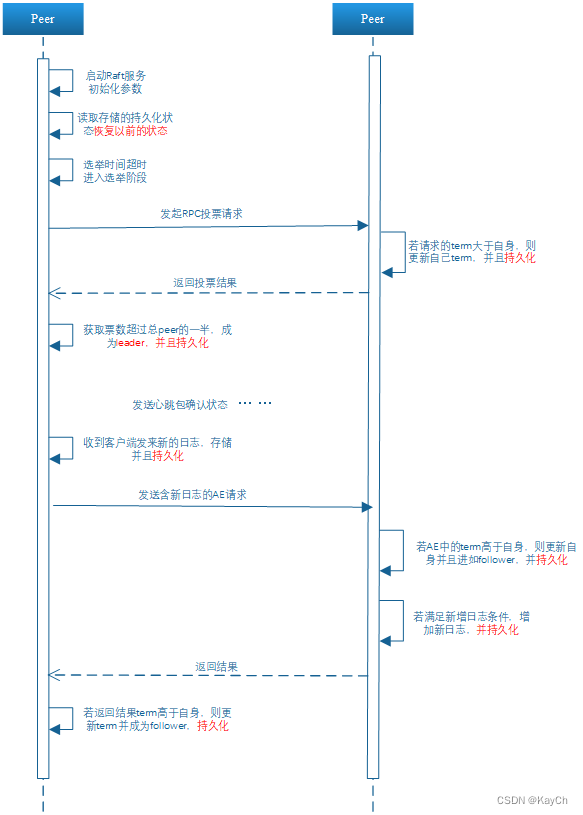
-
对象设计
在前述实验的基础上,增加对象persist,用来存储持久化的状态。
-
Persister
type Persister struct { mu sync.Mutex raftstate []byte snapshot []byte }
-
-
流程设计
-
持久化
将需要持久化存储的状态进行持久化处理
func (rf *Raft) persist() { // Your code here (2C). data := rf.getPersistData() rf.persister.SaveRaftState(data) }func (rf *Raft) getPersistData() []byte { w := new(bytes.Buffer) e := labgob.NewEncoder(w) e.Encode(rf.currentTerm) e.Encode(rf.votedFor) e.Encode(rf.logs) e.Encode(rf.commitIndex) e.Encode(rf.lastSSPointIndex) e.Encode(rf.lastSSPointTerm) data := w.Bytes() return data }
当客户端发来新的日志并添加到日志中时需要持久化。
-
term = rf.currentTerm
newLog := LogEntry{
Term: term,
Command: command,
}
rf.logs = append(rf.logs, newLog)
rf.persist()
index = rf.getLastIndex()
rf.resetHeartbeatTimer(rightnow)
当发起选举并且修改了自身需要持久化的信息,收到选举消息并修改需要持久化的信息或者收到发起选举的回复后修改。
if args.Term > rf.currentTerm {
rf.currentTerm = args.Term
rf.currentState = FOLLOWER
rf.votedFor = -1
reply.Term = rf.currentTerm
rf.persist()
rf.votedFor = args.CandidateId
reply.VoteGranted = true
rf.persist()
rf.resetElectionTimer()
rf.currentState = CANDIDATE
rf.votedFor = rf.me
rf.currentTerm++
rf.persist()
rf.currentState = FOLLOWER
rf.currentTerm = reply.Term
rf.votedFor = -1
rf.persist()
rf.resetElectionTimer()
当收到AE请求修改term和votedfor或者日志时需要持久化,而当收到AE请求的回复如果修改了term需要持久化,如果可以提交新的日志修改了commitIndex也要持久化。
if args.Term >= rf.currentTerm {
rf.currentTerm = args.Term
rf.currentState = FOLLOWER
rf.votedFor = args.LeaderId
rf.persist()
}
if rf.logs[i].Term != args.Entries[j].Term {
//只用比对Term,只要相同index的Term不同则不同
DPrintf("[AppendEntries1],preLogIndex:%d,lastsspoint:%d", args.PreLogIndex, rf.lastSSPointIndex)
rf.logs = append(rf.logs[:rf.getGlobalToRealIndex(args.PreLogIndex)+1], args.Entries...)
rf.persist()
}
if args.PreLogIndex+len(args.Entries) > rf.getLastIndex() {
DPrintf("[AppendEntries2],preLogIndex:%d,lastsspoint:%d", args.PreLogIndex, rf.lastSSPointIndex)
rf.logs = append(rf.logs[:rf.getGlobalToRealIndex(args.PreLogIndex)+1], args.Entries...)
rf.persist()
}
if reply.Term > rf.currentTerm {
rf.currentTerm = reply.Term
rf.currentState = FOLLOWER
rf.votedFor = -1
rf.persist()
rf.resetElectionTimer()
return
}
if newCommitIndex > rf.commitIndex && rf.getLogTermWithIndex(newCommitIndex) == rf.currentTerm {
rf.commitIndex = newCommitIndex
rf.persist()
rf.applyCond.Broadcast()
}
当peer收到InstallSnapshot的请求修改快照信息或者leader收到InstallSnapshot的回复需要修改term时进行持久化。
if ok {
rf.mu.Lock()
if reply.Term > rf.currentTerm {
rf.currentTerm = reply.Term
rf.currentState = FOLLOWER
rf.votedFor = -1
rf.persist()
rf.resetElectionTimer()
rf.mu.Unlock()
return
}
if rf.currentState != FOLLOWER {
rf.currentState = FOLLOWER
rf.votedFor = args.LeaderId
rf.persist()
}
-
读取持久化状态
服务器重启后读取持久化状态进行恢复
func (rf *Raft) readPersist(data []byte) { if data == nil || len(data) < 1 { // bootstrap without any state? return } // Your code here (2C). r := bytes.NewBuffer(data) d := labgob.NewDecoder(r) var currentTerm int var votedFor int var logs []LogEntry var commitIndex int var lastSSPointIndex int var lastSSPointTerm int if d.Decode(¤tTerm) != nil || d.Decode(&votedFor) != nil || d.Decode(&logs) != nil || d.Decode(&commitIndex) != nil || d.Decode(&lastSSPointIndex) != nil || d.Decode(&lastSSPointTerm) != nil { log.Fatal("Read Persistent Err") } else { rf.currentTerm = currentTerm rf.votedFor = votedFor rf.logs = logs rf.commitIndex = commitIndex rf.lastSSPointIndex = lastSSPointIndex rf.lastSSPointTerm = lastSSPointTerm } }服务器在重启后需在初始化需持久化的变量后再读取持久化状态进行恢复,否则读取的持久化状态会被初始化覆盖。
rf.readPersist(persister.ReadRaftState()) if rf.lastSSPointIndex > 0 { rf.lastApplied = rf.lastSSPointIndex }
PartD
本部分需要完成日志压缩。
- 实验流程
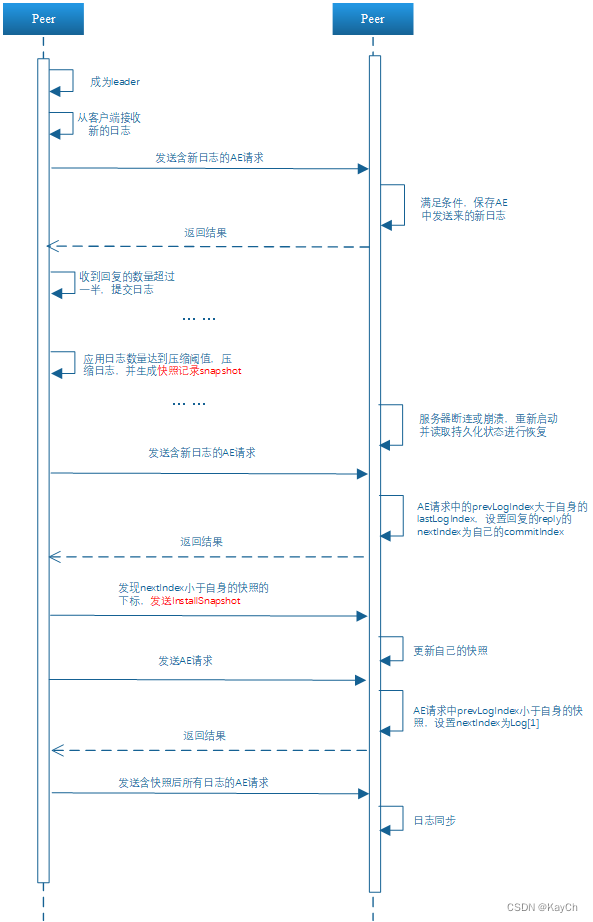
-
对象设计
本实验没有需要新增的对象
-
流程设计
-
日志压缩
当应用的日志达到压缩阈值后,上层应用就会发起请求对日志进行压缩,并且修改快照的下标和任期并且持久化,这里注意的是压缩需要重新生产一个日志而不是直接采用append对原来的切片进行压缩,因为直接使用append对原来的切片压缩底层数组仍然存储了以前的数据,只是访问不到,就会导致内存的浪费。
func (rf *Raft) Snapshot(index int, snapshot []byte) { rf.mu.Lock() defer rf.mu.Unlock() if index > rf.commitIndex || index > rf.lastApplied { log.Fatal("Snapshot Err,index>commitIndex||index>lastApplied") return } //旧的请求 if index <= rf.lastSSPointIndex { return } //压缩日志 tempLog := make([]LogEntry, 0) DPrintf("[Snapshot],index:%d,lastsspoint:%d", index, rf.lastSSPointIndex) for i := index + 1; i <= rf.getLastIndex(); i++ { tempLog = append(tempLog, rf.logs[rf.getGlobalToRealIndex(i)]) } rf.lastSSPointTerm = rf.getLogTermWithIndex(index) rf.lastSSPointIndex = index rf.logs = tempLog rf.persister.SaveStateAndSnapshot(rf.getPersistData(), snapshot) //INFO("[%d]---Current logSize %d all logSize %d", rf.me, len(rf.logs), rf.lastLogIndex()) //DPrintf("[%d]---Change Snapshot until index %d", rf.me, rf.lastSSPointIndex) } -
快照同步
当follower的
nextIndex小于或等于已经leader的快照的最后一条日志的下标后,则需要让follower直接同步自身的快照,然后再补充剩余日志。func (rf *Raft) sendSnapshot(server int) { rf.mu.Lock() args := InstallSnapShotArgs{ Term: rf.currentTerm, LeaderId: rf.me, LastIncludeIndex: rf.lastSSPointIndex, LastIncludeTerm: rf.lastSSPointTerm, Data: rf.persister.ReadSnapshot(), } reply := InstallSnapshotReply{} rf.mu.Unlock() ok := rf.peers[server].Call("Raft.InstallSnapShot", &args, &reply) if ok { rf.mu.Lock() if reply.Term > rf.currentTerm { rf.currentTerm = reply.Term rf.currentState = FOLLOWER rf.votedFor = -1 rf.persist() rf.resetElectionTimer() rf.mu.Unlock() return } ////旧的请求结果 //if reply.Term < rf.currentTerm { // return //} //返回已经不是leader了 if rf.currentTerm != args.Term || rf.currentState != LEADER { rf.mu.Unlock() return } rf.matchIndex[server] = Max(rf.matchIndex[server], args.LastIncludeIndex) rf.nextIndex[server] = rf.matchIndex[server] + 1 //DPrintf("[SendInstall Success,nextIndex]:%d", rf.nextIndex[server]) rf.mu.Unlock() return } }follower接受到同步快照的请求后,先检测
term,快照的下标和term等必要信息,再更新自己的信息。按照给的请求的压缩日志的开始参数对自身的日志进行更新,然后再修改自己的快照日志下标和term。因为快照是要应用在这个peer的,所以还需要检查commitIndex和lastapply,如果修改了commitIndex说明有新的更新,则需要向applychan发送应用消息请求应用。func (rf *Raft) InstallSnapShot(args *InstallSnapShotArgs, reply *InstallSnapshotReply) { rf.mu.Lock() if rf.currentTerm > args.Term { reply.Term = rf.currentTerm rf.mu.Unlock() return } rf.currentTerm = args.Term reply.Term = args.Term if rf.currentState != FOLLOWER { rf.currentState = FOLLOWER rf.votedFor = args.LeaderId rf.persist() } if rf.lastSSPointIndex >= args.LastIncludeIndex { rf.mu.Unlock() return } //日志压缩 index := args.LastIncludeIndex tempLog := make([]LogEntry, 0) DPrintf("[InstallSnapShot],lastIncludIndex:%d,lastsspoint:%d", args.LastIncludeIndex, rf.lastSSPointIndex) for i := index + 1; i <= rf.getLastIndex(); i++ { tempLog = append(tempLog, rf.logs[rf.getGlobalToRealIndex(i)]) } rf.logs = tempLog rf.lastSSPointIndex = args.LastIncludeIndex rf.lastSSPointTerm = args.LastIncludeTerm if rf.commitIndex < index { rf.commitIndex = index } if rf.lastApplied < index { rf.lastApplied = index } rf.persister.SaveStateAndSnapshot(rf.getPersistData(), args.Data) msg := ApplyMsg{ CommandValid: false, SnapshotValid: true, Snapshot: args.Data, SnapshotTerm: rf.lastSSPointTerm, SnapshotIndex: rf.lastSSPointIndex, } rf.mu.Unlock() //只有修改了commitIndex<=Index 才发给上层应用快照 if rf.commitIndex == index { rf.applyCh <- msg } DPrintf("[InstallSnapShot Success],lastSSPointIndex:%d", rf.lastSSPointIndex) return }raft在收到Leader发来的InstallSnapshot RPC时,会发送一个applyMessage交给Service层,Serverice层然后调用Raft的ConInstall检查是否需要快照,即这个通知是不是过期的,如果是则丢弃,如果不是则会修改Service层的应用日志的消息。这里因为在收到InstallSnapshot后就已经判断了这个消息是否过期,并且已经持久化,所以直接让ConInstall返回true
-
func (rf *Raft) CondInstallSnapshot(lastIncludedTerm int, lastIncludedIndex int, snapshot []byte) bool {
return true
}

















 1171
1171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









