






 本文介绍了Redis作为高性能Key-Value数据库的基础知识,包括其作为缓存的应用场景,如提高性能和并发处理。详细讨论了缓存穿透、缓存击穿和缓存雪崩的问题及解决方案,强调了使用缓存的重要性以及如何维护数据库与缓存的一致性。
本文介绍了Redis作为高性能Key-Value数据库的基础知识,包括其作为缓存的应用场景,如提高性能和并发处理。详细讨论了缓存穿透、缓存击穿和缓存雪崩的问题及解决方案,强调了使用缓存的重要性以及如何维护数据库与缓存的一致性。
第一章 、初识 Redis
1.1 百度百科解释 :
本词条由“科普中国”科学百科词条编写与应用工作项目 审核 。Redis 百度百科链接
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
1.2 官网简介 : Redis 官网链接 https://redis.io/

第一部分 : 左上角方框内是 Redis 的红色小图标 LOGO;
第二部分 : 左下部分方框内是 Redis 的英文简介,翻译为 : Redis 是一个开源的内存中的数据结构存储系统,它可以用作 : 数据库、缓存和消息中间件。
第三部分 :右下部分方框内是 Redis 的代码操作举例
Redis 是用 C语言 开发的一个开源的高性能键值对 ( key-value )数据库,官方提供的数据是可以达到 100000+ 的QPS(每秒内查询次数)。它存储的 value 类型比较丰富,也被称为结构化的 NoSql 数据库。
tip :
① 官方测试性能数据:读的速度是110000次/s,写的速度是81000次/s ;
② NoSql ( Not only SQL ) , 不仅仅是 SQL,泛指非关系型数据库。NoSQL 数据库并不是要取代 RDBMS ,而是关系型数据库的补充。
③ 常见的关系型数据库和非关系型数据库(NoSql):
关系型数据库 (RDBMS) : MySQL 、Oracle、DB2、SQLServer
非关系型数据库(NoSql): Redis、Mongo db、MemCached
1.3 应用场景
- ⭐缓存⭐ (缓存三兄弟 | 双写一致 | 持久化机制 | 数据过期和淘汰策略)
- 任务队列
- 消息队列
- 分布式锁 (setnx | redisson)
- 计数器
- 保存 token
1.4 常用的数据类型
Redis 存储的是 key-value 键值对结构的数据,其中 key 是字符串类型,value 有5种常用数据类型 :
- 字符串 string
- 哈希 (又叫散列) hash
- 列表 list
- 集合 set
- 有序集合 sorted set

redis常用命令链接 redis.net.cn
拓展几种稍微中高级的数据结构 ; HyperLogLog 、Geo、Pub/Sub、bitmap等等
第二章、Redis 用作缓存场景
2.1 为什么用 Redis 作缓存
2.1.1 高性能方面 :
关键词: 硬盘/内存 数据一致性
假如用户第一次访问数据库的某些数据,因为是从硬盘中读,过程相对比较慢。但是如果用户访问的数据属于高频数据并且不会经常改变,那么就可以将该用户访问的数据存在缓存中。因为可以让下次再访问这些高频热点数据时直接从缓存中获取。操作缓存就是直接操作内存,所以速度相对快。<br /
注意:数据库和缓存中的数据一致性问题,如果数据库中的对应数据改变之后,同步改变缓存的对应数据(延迟双删)。
2.1.2 高并发方面 :
关键词 : QPS(Query Per Second) : 服务器每秒可执行的查询次数
比如MySQL数据库(假设是4核8G配置),它的 QPS 大约在 1w 左右,但是如果用 Redis 缓存之后,很容易到 10W+,甚至 30W+ (针对 redis 单机情况而言,如果是 redis 集群会更高)。
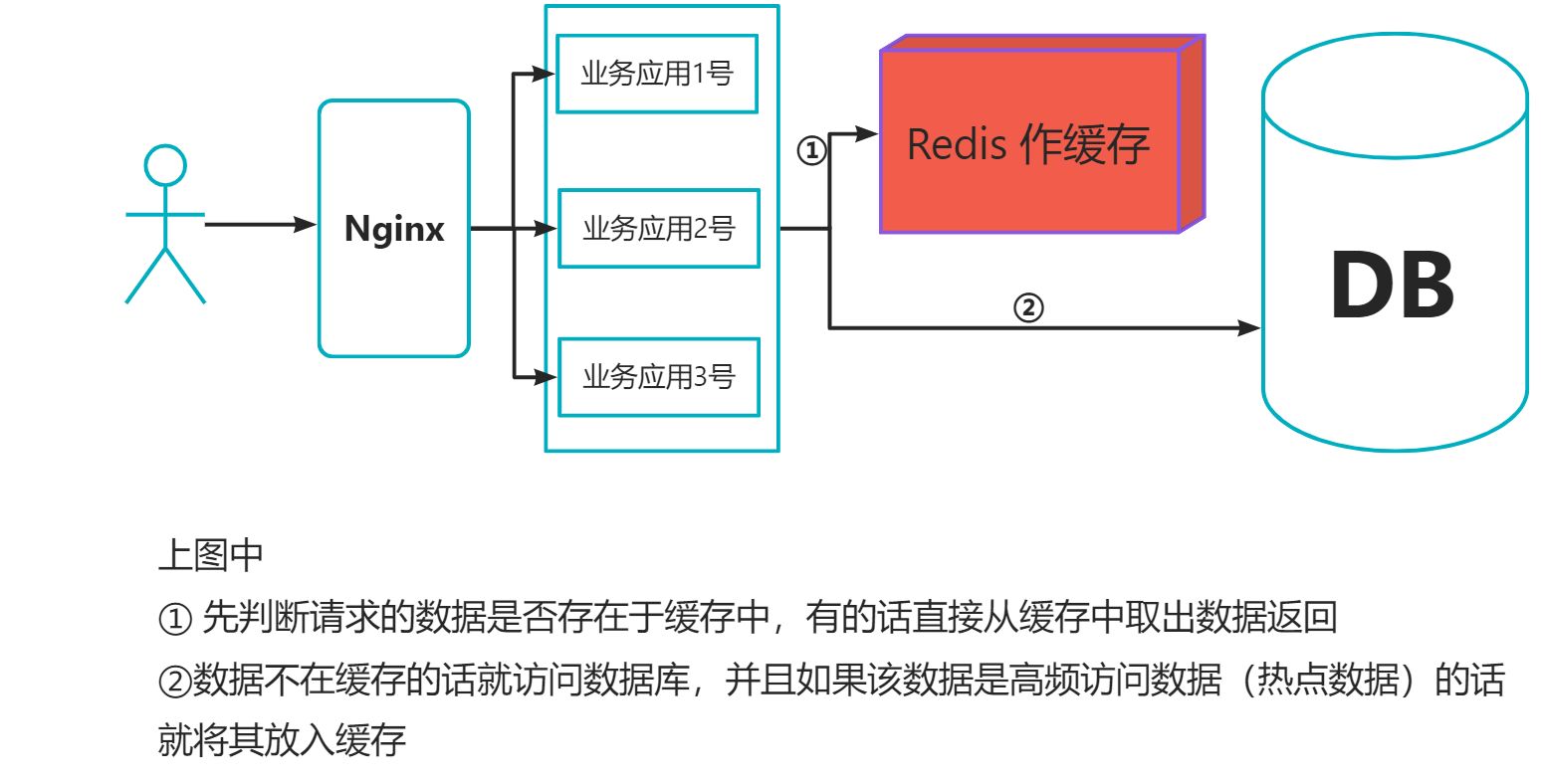
总而言之 : 使用缓存是为了提升用户体验以及应对更多的用户
此外,因为直接操作缓存能承受的数据库请求数量远远大于直接访问数据库,所以可以考虑将数据库的部分数据转移到缓存,这样用户的一部分请求直接到缓存而不用经过数据库。由此也就提升了系统整体并发。
2.2 缓存数据的处理流程
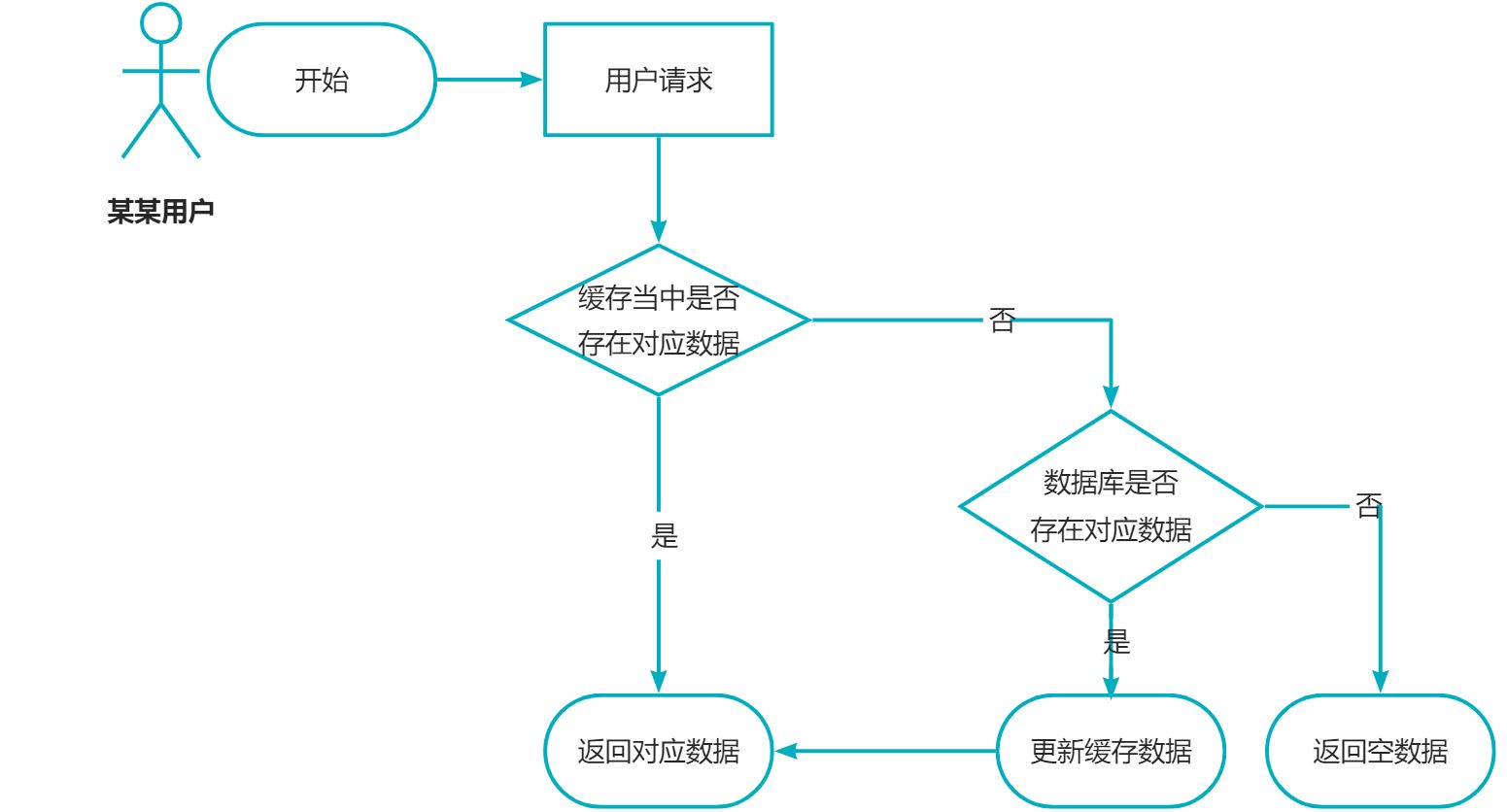
2.2.1 缓存穿透
① 什么是缓存穿透?
缓存穿透 是大量请求的 key 根本不存在于缓存中,导致请求直接到数据库,根本没有经过缓存层,
eg : 黑客故意制造缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。
②流程分析图

③解决方法
- 首先做好参数校验
对于一些不合法参数的请求直接抛异常返回。比如 id 不能小于 0 ;邮箱手机号格式不正确等校验;
- 其次 缓存无效 key
对于缓存和数据库都不存在的 key 的数据写一个到 Redis 缓存中并设置过期时间,具体命令:set key value EX 10086。但这种方式治标不治本,一方面可以解决key变化不频繁的情况,如果恶意攻击,每次构建不同的 key,导致缓存大量无效 key。尽量将过期时间设置短一点,比如一分钟。
缓存空数据 :
好处 : 简单
不足 : 耗内存,可能发生不一致的问题
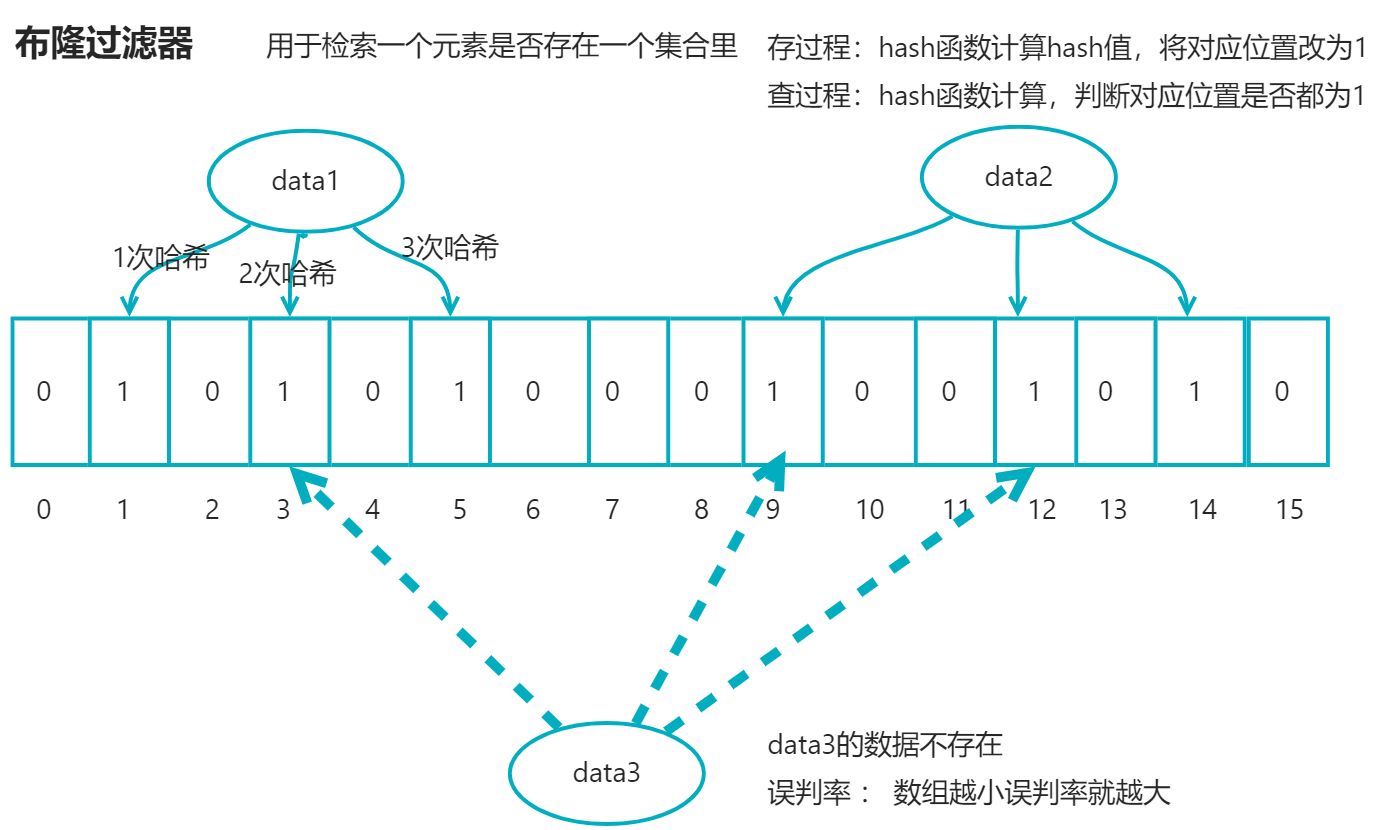
- 布隆过滤器
把所有可能存在的请求的值都存放在布隆过滤器中,当⽤户请求过来,先判断⽤户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会继续走流程。
- 布隆过滤器 底层是一个 bitmap(位图) 以位为单位的数组,数组中每个单元只能存二进制数0或者1;
- 布隆过滤器用于检索一个元素是否存在一个集合中
- 存储数据时: 通过多个hash函数获取hash值,将对应位置改为1;
- 查数据时,使用相同hash函数获取hash值,判断对应位置是都都为1;
- 可以用Redission 或者 Guava实现
- 误判率 : 数组越大误判率越小,但是同时带来了更多的内存消耗。
优点: 内存占用较少, 没有多余key
缺点: 存在误判,实现复杂
2.2.2 缓存击穿
①什么是缓存击穿
给某个key设置了过期时间,当 key 过期时候,恰好这个时间点对这个 key 有大量并发请求过来,这些请求可能会瞬间把DB压垮
②解决方法
解决方式一 :互斥锁 (强一致,性能差)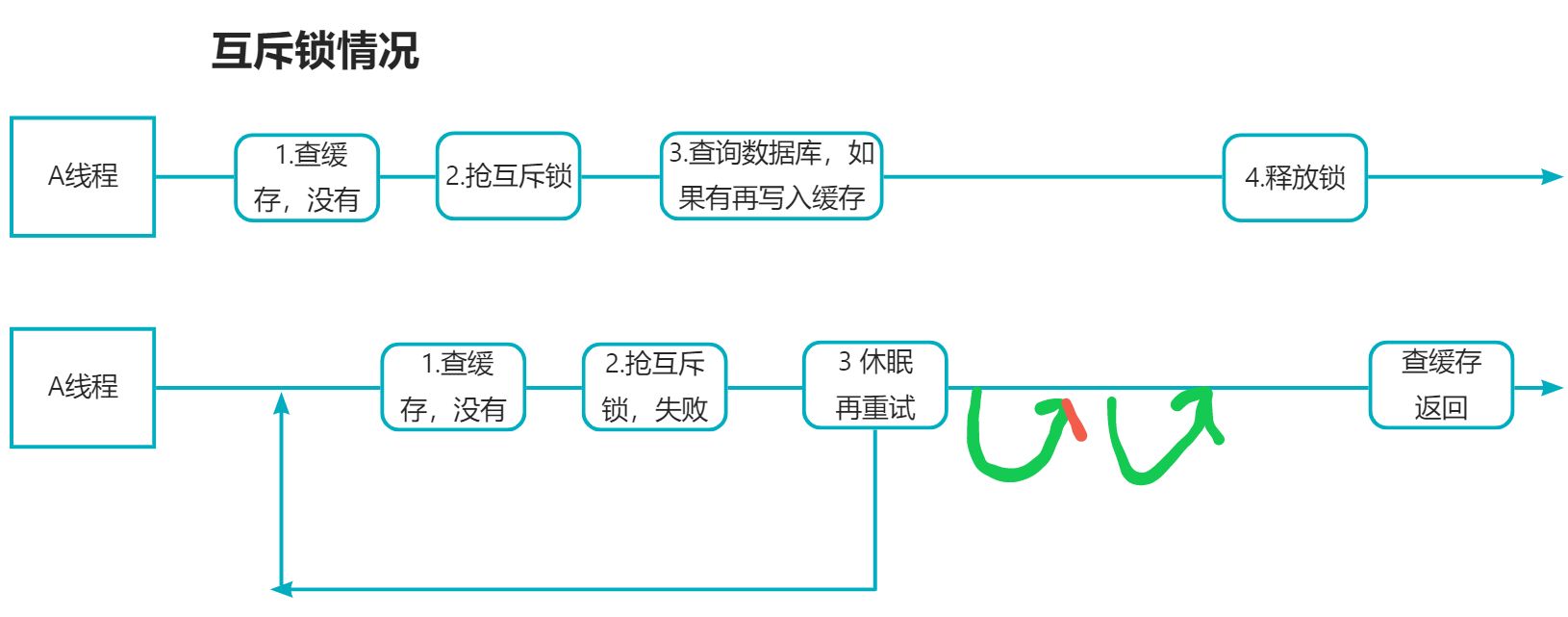
解决方式二 : 逻辑过期 (高可用,性能佳,不保证数据绝对一致)
① 设置key时候,设置一个过期字段一起存到缓存,不给当前key设过期时间
②查询时候,从缓存取数据后判断时间是否过期
③如果过期开通另一个线程进行数据同步,当前线程正常返回数据,这个数据不是最新的
2.2.3 缓存雪崩
①什么是缓存雪崩
缓存key在同⼀时间⼤⾯积的失效,后⾯的请求都直接落到了数据库上,造成数据库短时间内承受⼤量请求。
有⼀些被⼤量访问数据(热点缓存)在某⼀时刻⼤⾯积失效,导致对应的请求直接落到了数据库上。
Redis 服务宕机时,导致大量请求到达数据库,带来巨大压力。
②解决方案:
- 针对热点缓存失效 ; 给不同的 key 过期时间设置随机值 甚至设置缓存永不失效;
- 针对服务不可用情况 :
- 集群模式 或者 哨兵模式 提高服务可用性
- 缓存业务添加降级限流策略 nginx 或者 gateway
给业务添加多级缓存
写在最后 : 愿朋友们码到成功,初心不改 !

















 72
72

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









