




 本文围绕Leetcode(637)二叉树的层平均值问题展开。先给出题目及示例,随后介绍两种题解。方法一是层序遍历(广度优先遍历),用队列存储节点计算每层平均值;方法二是深度优先遍历,维护两个数组记录每层节点数和节点值之和来计算平均值,还分析了两种方法的复杂度。
本文围绕Leetcode(637)二叉树的层平均值问题展开。先给出题目及示例,随后介绍两种题解。方法一是层序遍历(广度优先遍历),用队列存储节点计算每层平均值;方法二是深度优先遍历,维护两个数组记录每层节点数和节点值之和来计算平均值,还分析了两种方法的复杂度。
Leetcode(637)——二叉树的层平均值
题目
给定一个非空二叉树的根节点 root , 以数组的形式返回每一层节点的平均值。与实际答案相差 10−510^{-5}10−5 以内的答案可以被接受。
示例 1:
输入:root = [3,9,20,null,null,15,7]
输出:[3.00000,14.50000,11.00000]
解释:第 0 层的平均值为 3,第 1 层的平均值为 14.5,第 2 层的平均值为 11 。
因此返回 [3, 14.5, 11] 。
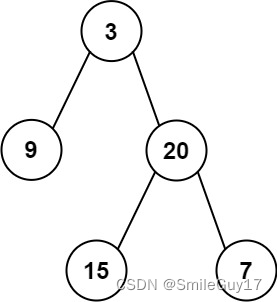
示例 2:
输入:root = [3,9,20,15,7]
输出:[3.00000,14.50000,11.00000]
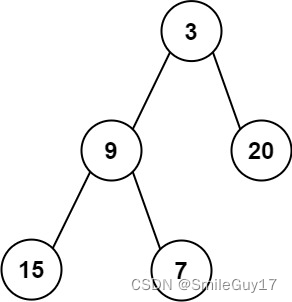
提示:
- 树中节点数量在 [1,104][1, 10^4][1,104] 范围内
- −231-2^{31}−231 <= Node.val <= 231−12^{31 - 1}231−1
题解
方法一:层序遍历(广度优先遍历)
思路
可以使用广度优先搜索计算二叉树的层平均值。从根节点开始搜索,每一轮遍历同一层的全部节点,计算该层的节点数以及该层的节点值之和,然后计算该层的平均值。
如何确保每一轮遍历的是同一层的全部节点呢?我们可以借鉴层次遍历的做法,广度优先搜索使用队列存储待访问节点,只要确保在每一轮遍历时,队列中的节点是同一层的全部节点即可。具体做法如下:
- 初始时,将根节点加入队列;
- 每一轮遍历时,将队列中的节点全部取出,计算这些节点的数量以及它们的节点值之和,并计算这些节点的平均值,然后将这些节点的全部非空子节点加入队列,重复上述操作直到队列为空,遍历结束。
由于初始时队列中只有根节点,满足队列中的节点是同一层的全部节点,每一轮遍历时都会将队列中的当前层节点全部取出,并将下一层的全部节点加入队列,因此可以确保每一轮遍历的是同一层的全部节点。
具体实现方面,可以在每一轮遍历之前获得队列中的节点数量 size\textit{size}size,遍历时只遍历 size\textit{size}size 个节点,即可满足每一轮遍历的是同一层的全部节点。
代码实现
我自己的——初始版本(双队列)
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
queue<TreeNode*> l1, l2; // l1和l2分别指两层的结点,当l1为空,才将l2的转入l1。当l1和l2都为空则遍历完了全部结点
vector<double> ans;
public:
vector<double> averageOfLevels(TreeNode* root) {
l1.push(root);
while(!l1.empty() || !l2.empty()) level();
return ans;
}
void level(){
long sum = 0;
int n = 0;
while(!l1.empty()){
sum += l1.front()->val;
n++;
if(l1.front()->left != nullptr) l2.push(l1.front()->left);
if(l1.front()->right != nullptr) l2.push(l1.front()->right);
l1.pop();
}
ans.push_back(1.0*sum/n);
l1.swap(l2);
}
};
我自己的——优化版本(单队列)
class Solution {
queue<TreeNode*> l; // 优化,使用一个队列,然后使用 nullptr 分隔两层
vector<double> ans;
public:
vector<double> averageOfLevels(TreeNode* root) {
l.push(root);
l.push(nullptr);
while(l.size() != 1) level();
return ans;
}
void level(){
double sum = 0;
int n = 0;
while(l.front() != nullptr){
sum += l.front()->val;
n++;
if(l.front()->left != nullptr) l.push(l.front()->left);
if(l.front()->right != nullptr) l.push(l.front()->right);
l.pop();
}
l.pop(); // 将 nullptr 输出
l.push(nullptr);
ans.push_back(sum/n);
}
};
Leetcode 官方题解:
class Solution {
public:
vector<double> averageOfLevels(TreeNode* root) {
auto averages = vector<double>();
auto q = queue<TreeNode*>();
q.push(root);
while (!q.empty()) {
double sum = 0;
int size = q.size();
for (int i = 0; i < size; i++) {
auto node = q.front();
q.pop();
sum += node->val;
auto left = node->left, right = node->right;
if (left != nullptr) {
q.push(left);
}
if (right != nullptr) {
q.push(right);
}
}
averages.push_back(sum / size);
}
return averages;
}
};
复杂度分析
时间复杂度:O(n)O(n)O(n),其中 nnn 是二叉树中的节点个数。广度优先搜索需要对每个节点访问一次,时间复杂度是 O(n)O(n)O(n)。需要对二叉树的每一层计算平均值,时间复杂度是 O(h)O(h)O(h),其中 hhh 是二叉树的高度,任何情况下都满足 h≤nh \le nh≤n。因此总时间复杂度是 O(n)O(n)O(n)。
空间复杂度:O(n)O(n)O(n),其中 nnn 是二叉树中的节点个数。空间复杂度取决于队列开销,队列中的节点个数不会超过 nnn。
方法二:深度优先遍历
思路
因为使用深度优先搜索计算二叉树的层平均值,需要维护两个数组,counts\textit{counts}counts 用于存储二叉树的每一层的节点数,sums\textit{sums}sums 用于存储二叉树的每一层的节点值之和。搜索过程中需要记录当前节点所在层,如果访问到的节点在第 iii 层,则将 counts[i]\textit{counts}[i]counts[i] 的值加 111,并将该节点的值加到 sums[i]\textit{sums}[i]sums[i]。
遍历结束之后,第 iii 层的平均值即为 sums[i]/counts[i]\textit{sums}[i] / \textit{counts}[i]sums[i]/counts[i]。
代码实现
Leetcode 官方题解
class Solution {
public:
vector<double> averageOfLevels(TreeNode* root) {
auto counts = vector<int>();
auto sums = vector<double>();
dfs(root, 0, counts, sums);
auto averages = vector<double>();
int size = sums.size();
for (int i = 0; i < size; i++) {
averages.push_back(sums[i] / counts[i]);
}
return averages;
}
void dfs(TreeNode* root, int level, vector<int> &counts, vector<double> &sums) {
if (root == nullptr) {
return;
}
if (level < sums.size()) {
sums[level] += root->val;
counts[level] += 1;
} else {
sums.push_back(1.0 * root->val);
counts.push_back(1);
}
dfs(root->left, level + 1, counts, sums);
dfs(root->right, level + 1, counts, sums);
}
};
复杂度分析
时间复杂度:O(n)O(n)O(n),其中 nnn 是二叉树中的节点个数。DFS 需要对每个节点访问一次,对于每个节点,维护两个数组的时间复杂度都是 O(1)O(1)O(1),因此深度优先搜索的时间复杂度是 O(n)O(n)O(n)。遍历结束之后计算每层的平均值的时间复杂度是 O(h)O(h)O(h),其中 hhh 是二叉树的高度,任何情况下都满足 h≤nh \le nh≤n。因此总时间复杂度是 O(n)O(n)O(n)。
空间复杂度:O(n)O(n)O(n),其中 nnn 是二叉树中的节点个数。空间复杂度取决于两个数组的大小和递归调用的层数,两个数组的大小都等于二叉树的高度,递归调用的层数不会超过二叉树的高度,最坏情况下,二叉树的高度等于节点个数。

















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









