



WTAGRAPH: Web Tracking and Advertising Detection using Graph Neural NetworksTOC](这里写自定义目录标题)
2022 IEEE Symposium on Security and Privacy (SP)
#课程作业,也是一个简单的对于网络安全监管方面的学习
摘要
如今,网络跟踪和广告 (WTA) 在网络上无处不在,不断损害用户的隐私。现有的防御解决方案,例如广泛部署的基于过滤器列表的阻止工具和先前研究中提出的基于替代机器学习的解决方案,在准确性和有效性方面存在局限性。在这项工作中,我们提出了 WTAGRAPH,一种基于图神经网络 (GNN) 的网络跟踪和广告检测框架。我们首先构造一个表示 HTTP 网络流量的属性同质多图 (AHMG),并将网络跟踪和广告检测制定为 AHMG 中基于 GNN 的边缘表示学习和分类的任务。然后,我们在 WTAGRAPH 中设计了四个组件,使其可以
(1)收集 HTTP 网络流量、DOM 和 JavaScript 数据
(2)构建 AHMG 并提取相应的边和节点特征
(3)构建用于边表示学习的 GNN 模型以及转导学习设置中的 WTA 检测
(4) 在归纳学习设置中使用预训练的 GNN 模型进行 WTA 检测。
我们在从 Alexa Top 10K 网站收集的数据集上评估 WTAGRAPH,并表明 WTAGRAPH 可以在转导和归纳学习设置中有效地检测 WTA 请求。人工验证结果表明,WTAGRAPH 可以检测到被过滤列表遗漏的新 WTA 请求,并识别被过滤列表错误标记的非 WTA 请求。我们的消融分析、规避评估和实时评估表明,WTAGRAPH 在实践中具有具有竞争力的性能和灵活的部署选项。索引词——网络跟踪和广告、隐私、图形神经网络
1 介绍
网络跟踪和广告 (WTA) 无处不在,由跟踪器执行以收集网络用户的浏览活动,用于各种目的,例如个性化广告和行为分析 [1]-[5],在此期间用户隐私经常受到损害。为了保护用户,一个基本的方法是在 WTA 即将发生时检测并采取行动。目前,广泛部署的解决方案是使用 AdBlock Plus [6] 和 uBlock Origin [7] 等阻止工具。这些工具可以根据过滤器列表(例如 EasyList [8] 和 EasyPrivacy [9])检测和阻止 WTA 请求,过滤器列表定义了一组规则,用于确定 HTTP(或 HTTPS)请求是否与 WTA 相关(即与跟踪相关)或广告,或两者兼而有之)。然而,维护这些手动整理的过滤器列表通常需要大量的人力,并且先前的研究也表明过滤器列表存在一些缺点,例如会产生假阳性和假阴性错误 [10]、[11]。因此,研究人员提出了基于机器学习的解决方案,以更好地检测 WTA 请求,尤其是减少漏报。通过从 HTTP 流量和请求 URL [12]、[13] 中提取特征,已经开发了各种机器学习分类器来检测与 WTA 相关的请求。同样,通过使用 JavaScript 代码 [14]-[16] 的句法和语义特征,研究人员展示了不同机器学习分类器在检测与 WTA 相关的 JavaScript 请求方面的有效性。最近,伊克巴尔等人。 [17] 介绍了 AdGraph,这是一种最先进的 WTA 检测方法。然而,尽管这些先前的每一项努力都做出了重要贡献,但研究人员仍有机会进一步提高基于机器学习的 WTA 检测方法的性能。
在本文中,我们提出了 WTAGRAPH,一种基于图神经网络 (GNN) 的网络跟踪和广告检测框架。近年来,在应用 GNN 解决图结构数据问题方面取得了巨大成功 [18]-[21]。典型的 GNN 采用邻域聚合策略(即消息传递),其中每个节点的表示是通过结合其特征向量和从其邻居聚合的特征向量来迭代学习的。在实践中,许多 GNN 变体已经实现了最先进的性能,因为 GNN 可以利用节点的显式特征和从图中学习的隐式特征来学习更好的节点表示。从本质上讲,包含 WTA 请求的 HTTP 网络流量可以构造为图形,其中边表示特定的 HTTP 请求,节点表示发出 HTTP 请求的源域或 HTTP 请求的目标域被发送到。受 HTTP 网络流量可以用图表示并且 GNN 在图学习任务中取得成功这一事实的启发,我们构建了一个属性同质多图(AHMG)来表示 HTTP 网络流量,并将 WTA 检测制定为 GNN 的任务。 AHMG 中基于边缘表示的学习和分类。为了有效地执行此任务,我们提出了 WTAGRAPH 并解决了一些技术挑战,包括 AHMG 构造、属性分配、边缘表示公式和消息传递。
我们在 WTAGRAPH 中设计并实现了四个组件,使其可以(1)收集 HTTP 网络流量、DOM 和 JavaScript 数据,(2)构建 AHMG 并提取相应的边和节点特征,(3)构建用于边表示学习的 GNN 模型和在转导学习设置中的 WTA 检测,以及 (4) 在归纳学习设置中使用预训练的 GNN 模型进行 WTA 检测。
我们在从 Alexa Top 10K 网站收集的数据集上评估了 WTAGRAPH,并表明 WTAGRAPH 可以在转导和归纳学习设置中有效地检测 WTA 请求。例如,它在转导学习设置中以 97.90% 的准确率、98.38% 的准确率、96.25% 的召回率和 97.30% 的 F1 分数检测 WTA 请求;它在归纳学习设置中以 97.82% 的准确率、98.00% 的准确率、96.38% 的召回率和 97.18% 的 F1 分数检测 WTA 请求。人工验证结果表明,WTAGRAPH 可以检测到被过滤列表遗漏的新 WTA 请求,并识别被过滤列表错误标记的非 WTA 请求。我们的消融分析、规避评估和实时评估表明,WTAGRAPH 在实践中具有具有竞争力的性能和灵活的部署选项。
总的来说,我们的论文做出了以下主要贡献:
(1)我们提出了一种新的基于 GNN 的 WTA 检测方法,
(2)我们开发了一种直接在 AHMG 中学习边缘表示的 GNN,
(3)我们设计并实现了一种边缘表示GNN 中的聚合策略,
(4) 我们实施了 WTAGRAPH,将数据收集、图构建、GNN 训练和 WTA 检测集成到一个框架中,(5) 我们进行了大规模评估,表明 WTAGRAPH 在这两个方面都是有效和有用的转导式和归纳式学习设置。
本文的其余部分结构如下。第二节回顾了 WTA 检测和图神经网络的相关工作。第三节给出了我们的 AHMG 的正式定义,并制定了我们的 WTA 检测任务。第四节描述了 WTAGRAPH 的设计和实现。第五节描述了我们的数据收集过程和数据集。第 VI 节和第 VII 节分别介绍了 WTAGRAPH 在转导和归纳设置中的评估结果。第八节讨论了 WTAGRAPH 的使用、限制和未来的工作。第九节总结了这项工作。
2 相关工作
我们的工作与 WTA 检测和 GNN 密切相关。 WTA检测。网络跟踪和广告通过将用户的身份与他们在不同网站上的浏览活动相关联来损害用户的隐私。基于定义一组规则的手动筛选列表,阻止工具已被广泛部署以检测 WTA 请求。然而,先前的研究表明该解决方案在维护工作、假阳性错误和假阴性错误方面存在缺点 [10]、[11]。
因此,研究人员提出了基于机器学习的解决方案,以更好地检测 WTA 请求。古格尔曼等人。 [12] 介绍了一种基于机器学习的 WTA 请求分类方法。基于一组 HTTP 流量特征,作者训练了一个分类器,可以识别 WTA 请求,准确率和召回率在 84% 左右。同样,Shuba 等人。 [13] 提出了用于移动环境广告拦截的 NoMoAds 框架。它从 HTTP 流量中提取特征并训练决策树模型来检测 WTA 请求。 Bhagavatula 等人。 [22] 开发了一个 k 最近邻分类器,可以使用 91 个 URL 特征检测 WTA 请求。通过使用 JavaScript 代码的句法和语义特征,Ikram 等人。 [14] 提出了一种单类分类器,可以检测与 WTA 相关的 JavaScript 程序。吴等。 [15] 和凯泽等人。 [16] 引入了类似的分类器,使用代码行为(例如,API 和 cookie 访问)检测与 WTA 相关的 JavaScript 请求。我们的方法与这些解决方案有很大不同,因为我们构建了一个 GNN 模型,通过利用从 AHMG 学习的显式和隐式特征来更好地识别 WTA 请求。
最近,伊克巴尔等人。 [17] 提出了一个基于图的框架,名为 AdGraph,用于 WTA 检测。通过检测 Chromium 浏览器,AdGraph 首先记录在网页访问期间由责任方(例如一些 JavaScript 代码和 HTTP 请求)引起的 DOM 更改。使用记录的 DOM 更改,它然后构建一个图形来捕获 HTTP 请求的上下文(例如,DOM 操作和 JavaScript 行为)。最后,它从 HTTP 请求的上下文图中提取 64 个特征,并训练随机森林模型以 95.33% 的准确率、89.1% 的准确率和 86.6% 的召回率 [17] 对 WTA 请求进行分类。请注意,在 AdGraph 的基础上,Brave 浏览器的 PageGraph [23] 组件正在开发中。通过更全面地归因 DOM 事件,PageGraph 可以执行各种任务,例如过滤器列表生成和 Web 兼容性分析 [23]。
我们的方法在两个方面也与这项工作有很大不同。首先,我们构造属性同质多图 (AHMG) 来表示一组请求的 HTTP 网络流量,而 AdGraph 构建一个图来表示单个网页访问的 HTTP 请求的上下文。其次,我们开发了一个 GNN 模型来学习边缘表示和检测 WTA 请求,而 AdGraph 基于显式提取的特征训练传统的随机森林模型来检测 WTA 请求。我们在第 VII-B 节中提供了 AdGraph 和我们的工作之间的详细实验比较。图神经网络。图被广泛用于表示社交网络、知识图谱、交通网络和分子结构等各个领域中的现实世界对象和关系。 GNN 是一种神经网络,可以直接对图进行操作以执行不同的学习任务。近年来成功的 GNN 类别是卷积 GNN [18]-[20]、[24]、[25]。受卷积神经网络 (CNN) [26] 成功的启发,这些 GNN 通过采用邻域聚合策略(即消息传递)实现图卷积运算,其中每个节点的表示通过结合其特征向量和特征来迭代学习从其邻居聚合的向量。在实践中,许多 GNN 变体已经在不同领域的任务中实现了最先进的性能,例如计算机视觉中的点云分类和动作识别 [27]-[29]、社交网络中的推荐和垃圾邮件检测 [30] –[32],以及化学中的分子指纹和药物发现 [24]、[33]、[34]。
受 HTTP 网络流量可以用图表示并且 GNN 在图学习任务中取得成功这一事实的启发,我们在这项工作中将 WTA 检测制定为 HTTP 网络流量图中的边分类任务。特别是,我们设计了一个特定的 GNN 模型,可以直接学习边缘表示来执行此任务。
3 问题定义
我们 WTA 检测的任务是检测网站发出的某些 HTTP 请求是否用于跟踪和/或广告目的。直观上,可以构建一个图来表示一个或多个网站的 HTTP 网络流量,其中边表示特定的 HTTP 请求,节点表示发出 HTTP 请求的源域或发送 HTTP 请求的目的域到。因此,我们可以将 WTA 检测的任务视为预测图中边的标签(即 WTA 与非 WTA)。在本节中,我们首先介绍我们旨在在这项工作中探索的属性同质多图的定义。然后,我们将 WTA 检测正式定义为此类图上的边缘分类任务。
3.1 属性同质多图
属性同构多图 (AHMG) 被定义为有向图 G = (V, E, X, Xe),其中每个节点 v ∈ V 具有特征向量 xv ∈ X,每条边 e(u,v, i) ∈ E 有一个特征向量 xe (u,v,i) ∈ Xe。由于在 G 中允许从节点 u 指向节点 v 的多条边,我们使用索引 i 来指示这些多条边中的第 i 条边。此外,在 G 中也允许自环(即从节点指向节点本身的边)。
AHMG 是 Web 上 HTTP 网络流量的自然表示。图 1 提供了一个示例。每个节点代表一个完全限定的域名 (FQDN) [35],而一条边代表从源 FQDN 向目标 FQDN 发出的特定 HTTP 请求。与 Web 上 HTTP 网络流量的特点一致,两个 FQDN(如 e.com 和 tk.b.net)之间存在多条边,它们代表不同的 HTTP 请求,同时自环(如 http://tv .d.org/show) 也普遍存在于 AHMG 中。此外,FQDN 和 HTTP 请求的属性可以自然地分别视为节点和边的属性。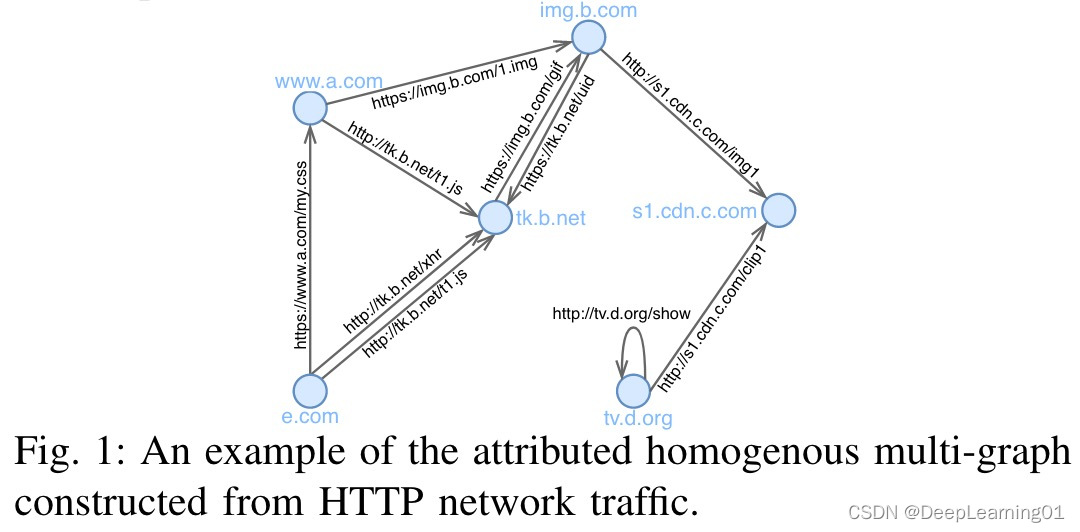
3.2 AHMG 边缘表示学习和分类
通过上面的定义,我们可以正式地将 WTA 检测任务定义为 AHMG 边缘表示学习和分类问题。给定一个 AHMG G = (V, E, X, Xe),目标是设计一个模型 fω : xe → Rd (d |xe|) 来学习每个边 e(u,v,i) 的 d 维表示) 在 G 中。学习到的边缘表示可以用于不同的任务,例如边缘聚类和边缘分类。具体来说,我们在这项工作中的任务是在 AHMG 中使用学习到的边表示将边分类为 WTA 或非 WTA,该 AHMG 从 HTTP 网络流量构建。
4设计
在本节中,我们首先介绍我们的 WTA 检测框架 WTAGRAPH 的高级架构。然后,我们详细阐述了其四个组成部分的设计原理和实现。
4.1 WTAGRAPH 的高层架构
在我们将问题表述为 AHMG 中的边缘表示学习和分类任务后,我们确定了任务中的以下三个挑战。
- 如何提取和分配AHMG 中节点和边的代表性属性?如图 1 中所述,域名和 URL 自然是节点和边的属性。为了获得更好的学习和分类性能,将它们有效地转换为特征向量并识别其他代表性特征至关重要。
- 如何设计和构建直接学习AHMG 中边表示的GNN 模型?据我们所知,不存在用于 AHGM 中直接边缘表示学习的现有 GNN。因此有必要设计一个新的 GNN 模型来学习我们图中的边表示。
- 如何在该 GNN 中有效地聚合和传播边表示? GNN 在其他应用中的成功表明,有效的聚合和传播策略对于我们的 GNN 至关重要。
因此,我们提出 WTAGRAPH 来应对这些挑战并执行我们的 WTA 检测任务。具体来说,WTAGRAPH 专为两种使用设置而设计:转导学习设置和归纳学习设置。在转导学习设置中,WTAGRAPH 有望检测所有观察数据的测试部分中的 WTA 请求。也就是说,给定 AHMG 中的边被分成训练和测试数据集;对 WTAGRAPH 进行训练,在此期间观察训练数据集中边的标签和 AHMG 的整体结构,以推断测试数据集中的边标签。在此设置中,我们的 GNN 通过正向传播和反向传播进行模型训练以及推断测试数据集中未标记的边。在实践中,这种使用设置对应于多个网站或网页的一批 HTTP 请求加入预测(即其标签未知或不确定)的应用场景;它们属于测试数据集,并被添加到现有的 AHMG(带有标记边)中,以形成一个新的 AHMG,用于整个转换训练/再训练和推理过程。例如,可以在转导学习设置中利用 WTAGRAPH 的预测来帮助改进过滤器列表。
在归纳学习设置中,WTAGRAPH 有望检测到在训练过程中从未见过的 WTA 请求。也就是说,WTAGRAPH 在预构建的 AHMG 上进行了预训练(在上面的转导学习设置中)将用于通过简单地通过前向传递来预测新的或看不见的边缘。在实践中,这种使用设置对应于使用预训练模型立即预测新的 HTTP 请求的应用场景。更具体地说,每次网页访问遇到的请求都会立即形成一个新的测试AHMG,如果它们共享一些节点,则会连接(即扩展)到上述预建AHMG的一跳;这个扩展但仍然小得多的测试 AHMG 将是预训练的 WtaGraph 的输入,并且将简单地通过前向传递进行边缘表示学习和实时推理。
如图 2 所示,我们在 WTAGRAPH 中设计了四个组件,用于在转导和归纳学习设置中进行 WTA 检测。**数据收集器组件使用 Google Chrome 浏览器扩展来收集每次网页访问的 HTTP 网络流量、文档对象模型 (DOM) 和 JavaScript API 访问。**图构建器组件从收集到的 HTTP 网络流量构建 AHMG,并提取相应的节点和边缘特征来解决第一个挑战。 WTA-GNN 组件是一种新颖的 GNN 模型,用于在转导学习环境中进行边缘表示学习和 WTA 检测。它捕获局部图结构、邻居节点的特征和邻居边缘的特征,以学习每个边缘表示。在我们的 WTA-GNN 设计中,我们解决了最后两个挑战。边缘分类器组件使用预训练的 WTA-GNN 在归纳学习设置中进行 WTA 检测。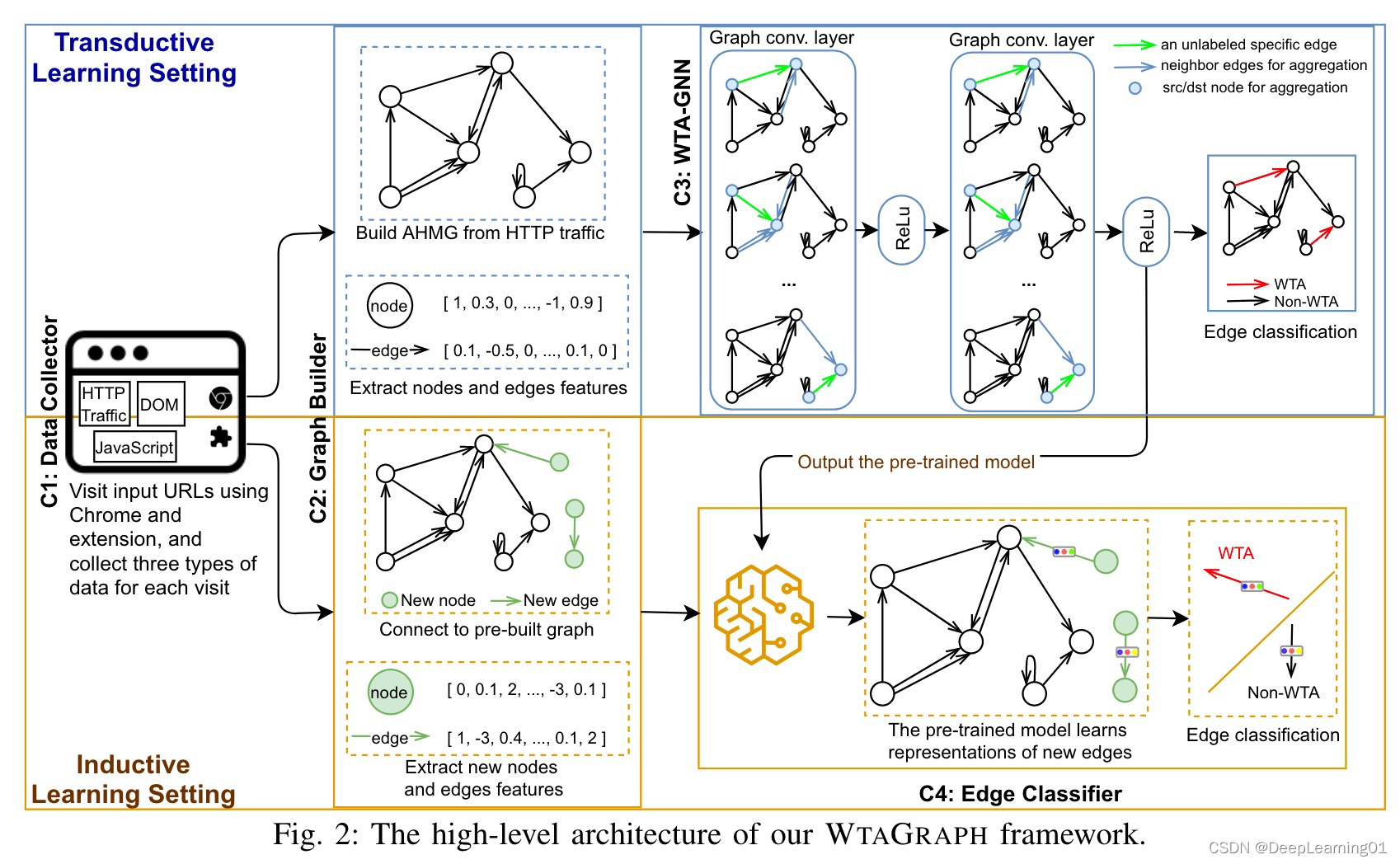
4.2 Data Collector
数据收集器组件旨在记录每次网页访问的 HTTP 流量(包括 [17]、[36]-[38] 中的所有重定向请求)、DOM 和 JavaScript API 访问。然后可以利用收集到的数据来构建 AHMG 并提取其节点和边的特征。我们在 Google Chrome 浏览器扩展中实现了这个数据收集器的核心功能。在数据收集过程中,此扩展程序可以安装在由 Selenium [39] 自动抓取网站列表的 Google Chrome 中。更详细地说,我们使用以下功能实现了浏览器扩展。
首先,它可以使用 Google Chrome 的 webRequest API 拦截并记录网页访问期间的所有 HTTP 流量。其次,它可以自动向下滚动网页以加载动态内容(如果有)。第三,它可以在访问结束时保存页面源,以便提取与 DOM 相关的特征。第四,它可以通过检测可用于跟踪和/或广告的流行 API 来监控 JavaScript API 访问。最后,它可以将所有爬取的数据保存到服务器上的 NoSQL 数据库中,以供以后分析。
4.3 图形生成器
Graph builder 组件旨在根据数据收集器爬取的数据构建 AHMG,并提取 AHMG 的节点和边缘特征。
4.3.1 图构建
在转导学习设置中,图形构建器通过将所有拦截的 HTTP 请求转换为边并将这些请求的相应源和目标 FQDN 转换为节点来构建 AHMG,如图 1 所示。这个 AHMG 通常很大,包含从许多(例如,在我们的实验中有数千个)网站收集的请求。在归纳学习设置中,图形构建器将新收集的单个网页访问的 HTTP 流量转换为新的测试 AHMG,如第 IV-A 节所述。根据新测试 AHMG 和预建 AHMG 之间共享节点的存在,三种可能类型的边被添加到新测试 AHMG。
首先,在源和目标 FQDN 作为节点存在于预建 AHMG 中的情况下,我们在两个节点之间添加一条新边来表示新的 HTTP 请求。
其次,在预构建的 AHMG 中只有两个 FQDN 中的一个作为节点存在的情况下,我们添加一个节点来表示丢失的 FQDN 和两个节点之间的新边。
第三,在预构建的 AHMG 中不存在源和目标 FQDN 的情况下,我们添加两个节点来表示两个缺失的 FQDN 和它们之间的新边。可以想象,孤立的子图可以存在于 AHMG 中。例如,x.com 可能只向 y.com 发送请求,它们与其他 FQDN 之间没有请求,因此创建了一个孤立的子图,表示这两个 FQDN 之间的唯一流量。请注意,孤立的子图并不是我们 WTA-GNN 的设计和实现的障碍,因为典型的 GNN 可以处理这种情况(第 IV-D 节)。
4.3.2 特征提取
在任一学习设置中构建 AHMG 后,图构建器分别为节点和边提取两类和三类特征。
第一个节点特征类别是字符嵌入。如第 III 节所述,FQDN 字符串可以自然地视为节点的属性。因此,将 FQDN 表示为 WTA-GNN 的输入的一种直接方法是使用单热编码。 FQDN 字符串中的每个字符将由位向量表示(例如,如果我们只对小写字母进行编码,则为 26 位),其中 1 位表示存在特定字符。
因此,FQDN 的表示可以是串联的单热向量的大向量,尤其是当 FQDN 包含数十个字符并且需要对更多字符(例如,大写字符和特殊字符)进行编码时。因此,我们决定使用字符 CNN 嵌入模型 [40] 产生的字符嵌入。在训练了超过 10 亿个单词后 [41],字符 CNN 模型为词汇表中的 256 个字符中的每一个生成一个嵌入。每个字符的嵌入大小为 16。例如,字符“a”由以下 16 个实数向量表示:
[1.1014, -0.6760, 0.6962, …, 1.0212]
更详细地说,我们首先将 FQDN 的长度设置为 30 个字符。长于 30 个字符的 FQDN 将从第 31 个字符截断,短于 30 个字符的 FQDN 将用 标记填充到长度 30。然后我们按照 FQDN 中的字符顺序连接所有字符嵌入向量。请注意,对于 标记,我们用 16 个零填充其嵌入向量。使用此方法,FQDN 字符串由大小为 480 的特征向量表示。
第二个节点特征类别是 DOM。节点的 DOM 特征是一个位向量,代表 DOM 中 HTML 标签的存在。此功能可以帮助识别 WTA 请求,因为许多与 WTA 相关的域可能没有 DOM 数据(例如,没有 DOM 可用于仅接受 POST 请求的端点域)。请注意,对于那些没有收集 DOM 信息的 FQDN,我们用全零填充特征向量。
第一个边缘特征类别也是字符嵌入。我们将请求 URL 截断或填充为 200 个字符,并按照请求 URL 中的字符顺序连接每个字符嵌入向量。这为每条边带来了一个大小为 3,200 的特征向量,代表 URL 中的字符。请注意,虽然 FQDN 字符串与节点更相关,但请求 URL 更特定于我们的 AHMG 中的边缘。因此,我们将请求 URL 的相应字符嵌入视为边缘特征。
第二个边缘特性类别是 JavaScript API 访问。边缘的 JavaScript 特征是一个位向量,表示从 JavaScript 文件请求接收到的脚本对检测 API 的访问。此类别中的功能有助于区分函数式和 WTA 相关的 JavaScript,因为 WTA 相关的 JavaScript 以访问某些 API 来执行跟踪和/或广告 [1]、[42] 而闻名。此外,我们将 JavaScript 文件请求的脚本 HTML 标记中存在的 async 和 defer 属性视为两个二进制特征。作者在 [17] 中评估并确认了这两个特征的高信息增益。对于非 JavaScript 请求,我们用全零填充它们的 JavaScript 特征向量。
第三个边缘特征类别是请求统计。对于请求,我们提取以下信息属性:源帧、顺序、时间、类型、方法、HTTP cookie 和 URL 长度。这些属性还可以帮助描述 WTA 请求的特征。例如,WTA 请求通常在其 URL 中携带数据(例如,在查询部分),这使得其 URL 长度通常比非 WTA 请求长。这些属性可以从保存的 HTTP 流量中提取。具体来说,通过在我们的数据收集器扩展中使用 chrome.webRequest API [43],我们可以提取每个 HTTP 请求的详细信息。例如,给定一个 HTTP 请求,源帧特征是一个指示请求是否发生在主框架中的位,可以从 frameId 属性中提取; order 特征是一个整数,通过检查当前请求在按 timeStamp 属性排序的请求序列中的索引得出。这最终得到了一个边的大小为 34 的特征向量。
4.4 WTA-GNN
给定构造的 AHMG 及其节点和边缘特征,我们的任务是预测边缘(代表特定 HTTP 请求)是否与 WTA 相关。
4.4.1 设计选择、决策和论证
要执行此任务,至少有四种可能的解决方案。首先,可以训练传统的机器学习分类器(例如随机森林分类器)来预测边的标签。其次,可以构建传统的神经网络,例如多层感知器 (MLP),通过学习边缘的表示来对边缘进行分类。第三,按照典型的链接预测(即预测两个节点之间可能存在的边)方法 [44]、[45],可以构建 GNN 模型来学习节点表示,并使用派生的边表示(例如,通过连接或平均相应的源和目标节点表示)。第四,可以构建一个端到端的 GNN 模型,直接学习边缘表示并预测它们的标签。
但是,前三种解决方案都存在一些不足。在第一种或第二种解决方案中,主要使用边缘特征进行预测。任何一种解决方案都会错失利用邻居节点特征和潜在图结构特征的机会,这些特征可以直观地有助于更好的分类性能。第三种解决方案也不适合解决我们的问题,即使它利用 GNN 来探索节点和图结构特征。典型的链接预测 GNN 是为处理简单图而构建的,而我们的图是多图。因此,如果我们简单地从节点表示中导出它们的表示,我们图中同一对节点之间的多条边将具有相同的边表示。这将导致不准确的分类结果。我们在第 VI-A 节中评估和比较这三种解决方案。
因此,我们着手探索第四种解决方案来执行我们的任务。我们构建了一个特定的 GNN 模型,该模型通过结合边特征、节点特征和潜在图结构特征来直接学习边表示。我们的模型称为 WTA-GNN,可用于转导和归纳学习环境。
4.4.2 WTA-GNN设计
典型的 GNN(例如 GCN [18]、GAT [20] 和 GraphSage [19])通过结合邻居节点特征和图结构特征来学习同质简单图中的节点表示,用于节点分类、节点聚类和链接等任务预言。据我们所知,还没有专门针对 AHMG 上的边缘表示学习进行过研究。因此,受典型 GNN 设计的启发,我们设计了 WTA-GNN 用于 AHMG 上的边缘表示学习。
典型 GNN 的节点表示学习过程可以归结为以下两个步骤。首先,它聚合了每个节点的邻居节点的表示。其次,它通过合并每个节点的表示和聚合表示来传播每个节点的表示。各种 GNN 研究表明,这种聚合和传播过程可以在与图相关的任务上产生更好的性能。我们假设类似的聚合和传播过程可以直接应用于边缘表示学习,以帮助我们在 AHMG 中的 WTA 检测任务中取得良好的性能。
因此,我们在 WTA-GNN 中设计边缘表示学习过程如下。首先,它聚合了每条边的相邻边的表示。具体来说,我们将同一目标节点的传入边视为给定边的邻居以进行聚合。这种设计背后的直觉是,发送到相同 FQDN 的 HTTP 请求可能具有相同的目的,尤其是从 WTA 与非 WTA 的角度来看。因此,这样的聚合可以帮助传播和学习边缘表示以进行准确分类。其次,它结合了每条边的两个节点的表示。这种设计背后的直觉是节点表示可以进一步编码图形结构信息并帮助对边进行分类。第三,类似于节点表示学习,它通过多层计算合并其表示和聚合的边和节点表示来传播每个边表示。
算法 1 详细说明了 WTA-GNN 中的边缘表示学习过程。它以 AHMG G = (V, E, X, Xe) 和可学习的权重矩阵 WV 和 WE 作为输入,并输出每个边的 d 维边表示 ze(u,v,i)。更详细地说,L 定义了神经网络中的层数,外层循环中的 l 表示特定层。请注意,基本情况 l = 0 定义了初始输入层,其中图形构建器组件提取的特征提供给 WTA-GNN(第 1 和第 2 行)。在每一层 l 中,WTA-GNN 首先在第一个内循环中学习节点表示(第 4 到 7 行),然后在第二个内循环中学习边表示(第 8 到 12 行)。在第一个内循环中,每个节点表示 slv 是通过将激活函数应用于邻居节点表示的加权和(在第 5 行中聚合)和它自己来自第 l-1 层的表示而产生的。在第二个内循环中,WTA- GNN 首先将相邻边的表示聚合为单个向量 hl N (e(u,v,i))(第 9 行),然后通过平均 slu 和 slv 将边的两个节点的表示组合为向量 tl(第 10 行) ,最后通过将激活函数应用于加权级联表示向量(第 11 行)来生成边表示 hle(u,v,i)。具体来说,WTA-GNN 连接组合向量 tl(表示仅从两个节点继承的部分边表示)和边表示 hl−1 e(u,v,i) 和聚合的相邻边的表示 hl N (e(u,v,i))。
如图 2 所示,WTA-GNN 在转导学习设置中进行训练,其中输入 AHMG 中的边被分成训练集和测试集。在训练过程中,我们将交叉熵损失函数应用于训练集中边缘的输出表示 ze(u,v,i),并通过随机梯度下降调整权重矩阵 WV 和 WE。交叉熵损失在 GNN(例如 [18]、[20])中广泛用于分类任务。在我们的例子中,它测量原始(即没有归一化)边缘分类逻辑和地面真实标签之间的距离。训练过程最小化所有训练边的平均交叉熵损失。经过训练的 WTA-GNN 可以输出测试集中边的表示并预测它们的标签。此外,经过训练的 WTA-GNN 可用于归纳学习设置,以立即预测为每次网页访问构建的测试 AHMG 中新边的标签。
4.4.3 WTA-GNN 实现
我们使用 DGL [46] 中的 GNN 框架将 WTA-GNN 实现为具有两层(即 L=2)。此外,我们将聚合函数 Agg 实现为均值聚合器,它采用 {sl−1 u , ∀u ∈ N (v)} 和 {hl−1 j , ∀j ∈ N (e(u ,v,i))} 分别在第 5 行和第 9 行。我们实现邻域函数 N 来选择节点或边的完整邻居集。事实上,可以在算法 1 中选择不同的聚合和邻域函数。例如,可以实现邻域函数 N 以仅选择 [19] 中的邻居子集。请注意,对于没有邻居的边或节点(例如,在只有一条边甚至一个节点的孤立子图中),不会发生邻居选择和聚合;因此,相应的边或节点表示完全是从其自身的初始特征中学习的。
4.5 边分类器
WTAGRAPH 的最后一个组成部分是边缘分类器。它加载在转导学习设置中预训练的 WTA-GNN 模型,以预测测试 AHMG 中新边的标签。具体来说,它根据 WTA-GNN 输出 ze(u,v,i) 将新边分类为 WTA 或非 WTA。算法 1 中的向量 ze(u,v,i) 在我们的设计中大小为 2,对应于边的两个可能类别(即 WTA 和非 WTA)。边分类器将logit值较大的类作为边的分类结果。
5 数据收集和数据集
5.1 数据采集
如第 IV-B 节所述,我们将 WTAGRAPH 的数据收集器组件实现为 Google Chrome 浏览器扩展。在我们的数据收集中,我们在 AdGraph [17] 的 Chromium 浏览器 [47] 中安装了数据收集器。这样,可以在同一个网页访问中进行两个独立的数据采集操作,互不干扰。我们从 2020 年 6 月 8 日的 Alexa 百万榜单中选取了前 10K 个网站进行数据收集。对于每个网站,我们从 2020 年 7 月 23 日到 2020 年 8 月 6 日使用安装了 WTAGRAPH 数据收集器的检测 Chromium 浏览器自动访问其主页。在每次网页访问中,我们等待主页完成加载和滚动(由 WTAGRAPH 的数据触发)收集器)或最多 120 秒。检测后的 Chromium 浏览器收集网页执行上下文数据,而 WTAGRAPH 的数据收集器保存 HTTP 流量、DOM 和 JavaScript API 访问信息。
5.2 Ground Truth
为了训练和评估 WTAGRAPH,我们通过利用与 AdGraph [17] 中使用的相同的七个过滤器列表1,创建了所有收集到的 HTTP 请求的真实标签。具体来说,它们是 EasyList [8]、EasyPrivacy [9]、AntiAdblock Killer [48]、Warning Removal List [49]、Blockzilla [50]、Peter Lowes List [51] 和 Fanboy Annoyances List [52]。我们没有涵盖 [17] 中使用的 Squid 黑名单,因为那时它不再可用。请注意,过滤器列表可能有误报和漏报,如 [10]、[11] 中研究的那样,但使用它们的输出作为模型训练和定量评估的基本事实标签仍然是合理和可行的,特别是对于 Top 10K 网站,如 [ 17]。我们对一组样本分类结果进行了人工验证,详见第 VI-B 节和附录 A。对于每个收集到的 HTTP 请求,我们根据它是否会被这七个过滤器中的任何一个阻止,将其标记为 WTA 或非 WTA列出。
5.3 数据集统计
表一总结了 WTAGRAPH 的数据收集器和 AdGraph 的 Chromium 浏览器 [47] 在相同访问中从 Alexa Top 10K 网站收集的 HTTP 请求的统计数据。 WTAGRAPH 和 AdGraph 分别收集了超过 155 万和 834K 的请求;使用相同的七个过滤器列表,WTAGRAPH 和 AdGraph 收集的这些请求中分别有 39% 和 15% 被标记为 WTA 请求。从 WTAGRAPH 的角度来看,它错过了 AdGraph 收集的大约 15% 的请求。从 AdGraph 的角度来看,它错过了 WTAGRAPH 收集的超过 952K(61%)的请求,而这些错过的请求中超过一半是 WTA 请求。我们调查了这种数据差异,发现 WTAGRAPH 正确地收集了数据,而 AdGraph 在实践中错误地收集了一些不是 HTTP 请求的 URL,并且由于其 Chromium 检测的潜在不完整性而错过了某些类型的 HTTP 请求。有关此差异分析的更多详细信息,请参见附录 B。
我们将 WTAGRAPH 的数据收集器收集的数据集(在表 I 的第一列中)称为我们的 Top-10K 数据集。该数据集将在第 VI 节和第 VII 节中使用。我们的 Top-10K 数据集与 AdGraph 在同一网页访问期间收集的数据集之间的重叠数据(在表 I 的第三列中)将在第 VII-B 节中用于比较 WTAGRAPH 与 AdGraph。
6 传导环境中的评估
在本节中,我们介绍了 WTAGRAPH 在转导学习设置中检测 WTA 请求的性能。
我们描述了它的整体性能,执行手动验证,并提供了 WTAGRAPH 变体的消融研究结果。回想一下,转导学习设置对应于第 IV-A 节中描述的添加多个网站或网页的一批 HTTP 请求以进行预测的应用场景。

6.1 整体表现
6.1.1 基线模型
第 IV-D 节介绍了除了 WTAGRAPH 之外的其他三种可能的解决方案来解决我们的 WTA 检测问题。我们实现了其中两个,一个典型的链接预测 GNN 模型和一个传统的多层感知器 (MLP),作为与 WTAGRAPH 进行比较的基线模型。请注意,我们在第 VII-B 节中展示了传统机器学习分类器(即 AdGraph [17] 中使用的随机森林模型)和 WTAGRAPH 之间的比较。
对于链路预测 GNN 模型,我们实现了一个双层 GCN [18] 模型,该模型学习节点表示并通过平均每条边的两个节点的学习节点表示来生成边表示。对于 MLP,我们用一个隐藏层实现它;它以原始请求特征(即 WTAGRAPH 提取的节点和边缘特征)作为输入,并为每个请求输出大小为 2 的学习特征向量。此外,我们提出并实现了一个高级链接预测 GNN 作为基线模型。它类似于 WTA-GNN,但在学习过程中不会聚合相邻边的表示。我们在附录 C 中详细介绍了实验设置。我们通过分层 10 折交叉验证在我们的 Top-10K 数据集上评估了这三个基线模型和 WTAGRAPH。
6.1.2 Overall Results
表二总结了这四种模型在我们的 Top-10K 数据集上的表现,包括分类准确度、精确度、召回率和 F1 分数。总体而言,WTAGRAPH 在每个评估指标上都优于所有三个基线模型。例如,WTAGRAPH 的检测准确率、准确率、召回率和 F1 分数分别为 97.90%、98.38%、96.25% 和 97.30%。这四个模型的 ROC 和 AUC 分析在附录 D 中。

这些结果有两个主要含义。一方面,我们提出的 WTAGRAPH 和高级链接预测模型优于其余两个基线模型。这意味着受益于邻居聚合和隐式图特征,有目的设计的 GNN 模型在检测 WTA 请求方面可以优于典型模型。另一方面,通过比较 WTAGRAPH 中的聚合策略(即从节点和边聚合)与我们的高级链路预测 GNN 中的聚合策略(即仅从节点聚合),我们发现前者具有更好的检测性能.
6.1.3 详细性能
表 III 总结了 WTAGRAPH 在我们的 Top-10K 数据集中对 12 种类型的 HTTP 请求的详细检测性能。 WTAGRAPH 收集的 HTTP 请求涵盖了 Google Chrome [53] 记录的所有 12 种请求类型。如表 III 左侧所示,WTAGRAPH 检测到的 WTA 请求数与每个请求类型的过滤器列表非常接近。总体而言,WTAGRAPH 和过滤器列表分别将所有请求中的 38.52% 和 39.37% 检测为 WTA。这个结果意味着 WTAGRAPH 可以替代过滤器列表,因为它对 WTA 请求的检测率接近。同时,WTAGRAPH 在大多数请求类型上都有出色的表现。例如,WTAGRAPH 对前四种请求类型(即图像、脚本、xmlhttprequest 和其他占数据集中所有请求的 86.34%)的准确率、精确率、召回率和 F1 分数均达到 95% 以上。 WTAGRAPH 在检测 main_frame、样式表和字体请求方面的性能相对较差。例如,这三类请求的漏报率分别为 69.50%、16.20% 和 10.41%。
6.2 人工验证
为了验证 WTAGRAPH 的预测,我们对抽样请求进行了一组手动验证。具体来说,从12种请求类型的所有预测中,我们随机抽取了846个假阳性、941个假阴性、1,040个真阳性和1,139个真阴性;我们手动为每个标签分配了 WTA、非 WTA、混合(仅用于 [17] 中的脚本资源)或验证后不可判定的标签。由于篇幅限制,我们在附录 A 中详细介绍了完整的验证程序、标准和结果。
总体而言,从 846 个误报样本中,我们发现 WTAGRAPH 能够识别过滤器列表遗漏的 WTA 请求,尤其是图像、脚本、xmlhttprequest、sub_frame、ping 和媒体类型。具体来说,846 个请求中有 320 个被验证为 WTA 请求,这意味着 WTAGRAPH 的分类是正确的。例如,虽然过滤器列表丢失,但 WTAGRAPH 成功检测到以下跟踪像素 https://ss0.baidu.com/6ONWsjip0QIZ8tyhnq/ps_default.gif。从 941 个漏报样本中,我们验证了 WTAGRAPH 的分类(即非 WTA 预测)在 90% 的时间里对于样式表、main_frame、其他和字体请求确实是正确的。也就是说,过滤器列表错误地将这些请求标记为 WTA。例如,Peter Lowes 的列表 [51] 积极阻止对 criteo.com 的任何请求;因此,当一个人访问作为第一方网站的 criteo.com 时,所有对 criteo.com 的请求,包括 main_frame 请求,都会被这个过滤器列表阻止。
从 1,040 个真阳性样本和 1,139 个真阴性样本中,我们观察到 WTAGRAPH 和过滤器列表之间的大部分 (89.67%) 协议是正确的,而它们在大约 5% 的请求(不包括不可判定的请求)上可能是不正确的,这可能是由于过滤器列表的不完善和不完整。例如,WTAGRAPH 和过滤器列表都没有检测到以下跟踪像素 https://c.evidon.com/a/4.gif。
6.3 消融分析
为了弄清楚不同类别的特征和邻居聚合策略如何影响 WTAGRAPH 的性能,我们对四种 WTAGRAPH 变体进行了消融研究:(1)没有节点聚合的变体,(2)没有边缘 URL 嵌入特征的变体,(3)没有边缘的变体JavaScript 功能,以及 (4) 没有边缘 URL 统计功能的变体。请注意,没有邻居边缘聚合的 WTAGRAPH 变体(即高级链路预测 GNN)已在表 II 中进行了评估和报告。
图 3 展示了这四种变体和原始 WTAGRAPH 的性能。总的来说,四个 WTAGRAPH 变体的性能比原始 WTAGRAPH 略差。具体来说,在没有节点聚合的情况下,WTAGRAPH 的分类准确率、准确率、召回率和 F1 分数分别下降了 0.72%、0.95%、0.89% 和 0.91%;在没有边缘 URL 嵌入特征的情况下,其准确率、精确率、召回率和 F1 分数分别下降 0.59%、0.71%、0.81% 和 0.76%;在没有边缘 URL 统计或 JavaScript 功能的情况下,WTAGRAPH 的分类性能略有下降,约为 0.10%。
这些结果表明:(1)WTAGRAPH 的性能是由所有特征和聚合策略贡献的,而不是某些主导因素; (2) WTAGRAPH 在实践中的部署选项是灵活的,例如,如果存在特征可用性或计算资源的限制,可以删除某些特征,并期望 WTAGRAPH 仍然具有竞争力的性能; (3) WTAGRAPH 可以抵抗一些 WTA 检测规避,例如 DGA 域 [54] 和 JavaScript 混淆 [55],因为它不严重依赖某些特定功能。
7 诱导环境中的评估
在本节中,我们在不同的归纳学习设置中评估 WTAGRAPH。我们首先介绍它的整体性能。然后,我们对 WTAGRAPH 和 AdGraph [17] 进行了详细比较。第三,我们进行逃避研究以评估 WTAGRAPH 的稳健性。最后,我们评估了 WTAGRAPH 的实时性能。回想一下,归纳学习设置对应于应用场景,其中预训练模型用于立即预测新的 HTTP 请求(在每次网页访问中遇到),这些请求形成新的测试 AHMG,如第 IV-A 节所述。
7.1 整体表现
上一节中的所有评估都是在转导学习设置中的完整图表上执行的。为了评估 WTAGRAPH 在归纳学习环境中的表现,我们首先在从随机选择的网站构建的不同图表上转导训练了四个 WTAGRAPH 模型。具体来说,我们从 Top-10K 数据集中随机选择 1K、3K、5K 和 7K 网站进行转导训练,并使用其余(未见过的)9K、7K、5K 和 3K 网站在其主页上进行归纳测试。我们构建了四个图,分别称为 Random-1K、Random3K、Random-5K 和 Random-7K2 图,并分别在这些图上预训练了四个 WTAGRAPH 模型。然后,我们在相应的剩余网站上测试了这四个预训练的 WTAGRAPH 模型。更详细地说,我们为每个单独的测试网页构建了一个测试 AHMG,并且在相应的预建 AHMG(第 IV-A 节)中,用其节点和边缘的一跳邻居扩展它。我们使用相应的预训练模型来预测每个测试 AHMG 中的 WTA 请求。
值得强调的是,我们测试的 AHMG 构造方法既合理又有效。在归纳学习设置中,用于预测或测试的预训练模型的输入必须是 AHMG。尽管可以构建一个测试 AHMG,它只包含一个边代表网页访问中的单个请求,但 WTAGRAPH 的性能会很差(正如我们最初观察到的那样),因为这样的 AHMG 不能很好地利用隐式图特征和邻居信息。为每个网页访问的多个请求构建一个测试 AHMG 将能够从内容和上下文的角度提取丰富的特征;同时,通过采用这种方法,无需或依赖于访问更多的网页或网站。换句话说,这就是我们在 WTA 检测任务中解决 GNN 归纳学习中常见的所谓冷启动问题或挑战(即可行且正确地构建测试图)的方式 [56]、[57] .请注意,虽然 AdGraph 构造了一个完全不同的图,但它的图构造和特征提取也是基于网页访问的多个请求;因此,相同的输入单元(即从每次网页访问收集的信息)将提供给 WTAGRAPH 和 AdGraph 以进行公平比较。
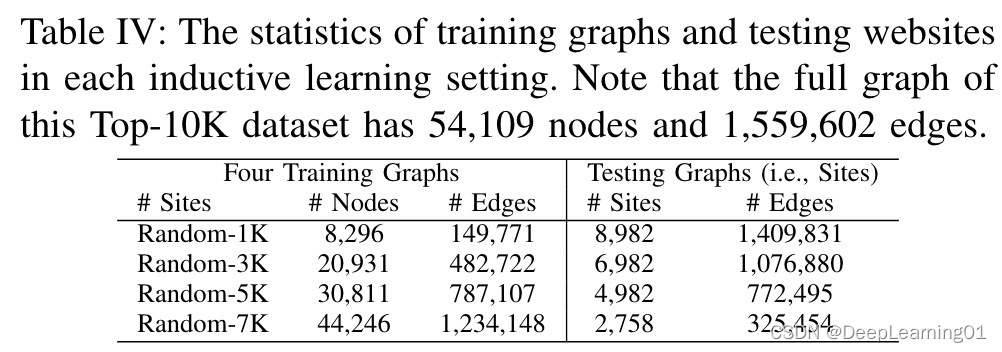
表 IV 总结了我们的数据集在每个归纳设置中的统计数据。以Random-1K图为例,它只包含Top-10K数据集中出现的9.60%的边和15.33%的节点。在此归纳学习设置中,将使用在 Random-1K 图上训练的 WTAGRAPH 模型来推断训练过程中从未见过的 8,982 个网站的超过 140 万个请求的标签。请注意,将为这 8,982 个网站中的每一个创建一个测试 AHMG,并将对其进行独立测试以推断其边缘的标签。平均而言,每个测试 AHMG 有 27 个节点和 129 个边。
图 4 展示了 WTAGRAPH 模型在四种归纳学习设置中的表现。为比较目的绘制的蓝色条表示 WTAGRAPH 在转换学习设置中的性能,如表 II 所示。我们观察到,除了在 Random-1K 图上训练的 WTAGRAPH 模型外,与 WTAGRAPH 在转导学习设置中的性能相比,其余 WTAGRAPH 模型可以在归纳学习设置中实现竞争性能。例如,WTAGRAPH模型在Random-7K图上可以预测2758个测试网站的325454次请求,准确率为97.82%,
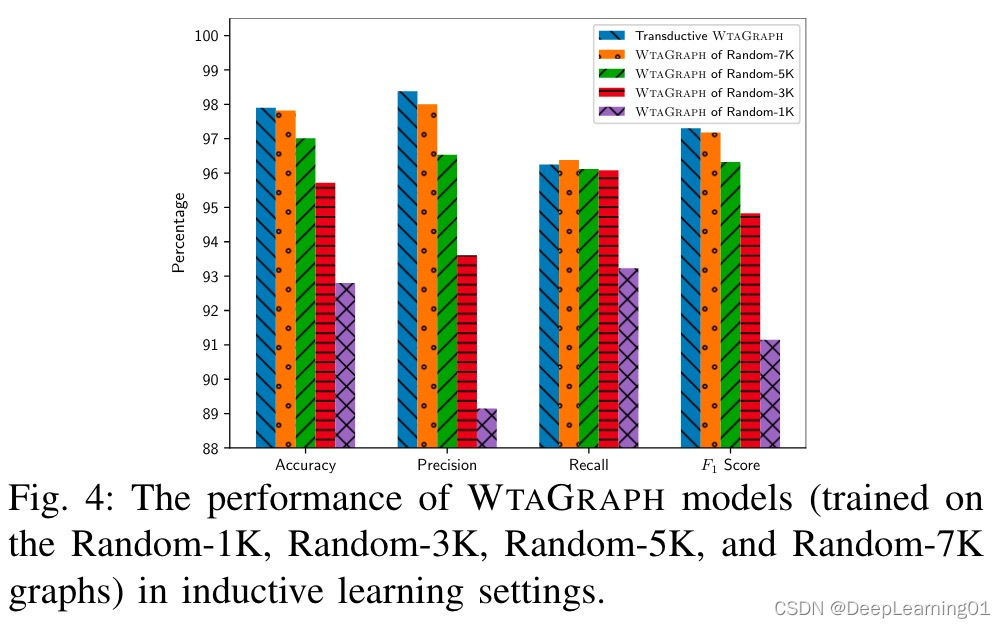
精确率 98.00%,召回率 96.38%,F1 分数 97.18%。此外,我们发现训练图越大,归纳学习设置中的性能越好。这是预期的,因为更大的图可能会捕获更多的 HTTP 流量模式并包括用于聚合的代表性边。这些结果表明,当训练数据集不太小时,WTAGRAPH 能够在归纳学习设置中表现良好。本小节和下一小节中模型的 ROC 和 AUC 分析在附录 D 中。
7.2 与 AdGraph 的比较
AdGraph [17] 仅收集了我们 Top-10K 数据集中 38.93%(即 607,124)的请求(总结在表 I 中),并且不直接处理我们的 Top-10K 数据集,因为 AdGraph 遗漏的请求的上下文信息是无法使用。为了切实可行地将我们的 WTAGRAPH 与 AdGraph 进行比较,我们评估了它们在 Top-10K 数据集中的这 607,124 个重叠请求上的性能。
如表 V 顶部所示,我们随机选择了 80% 的网站(即 9,032 个重叠网站中的 7,224 个)进行训练,20% 的网站进行测试。我们还将 1,808 个测试网站分为两类:连接网站和孤立网站。如果一个网站在其 AHMG 中存在至少一个节点也出现在训练图中,则该网站被视为已连接;否则,它被认为是孤立的。换句话说,连接网站的 AHMG 至少有一条边连接到训练图。共有 1,714 个连接网站和 94 个孤立网站。请注意,在我们的 Top10K 数据集中几乎不存在孤立的网站(总共三个孤立的网站),因为 WTAGRAPH 收集了访问过的网站的完整请求,并且网站更有可能根据共同的请求相互连接。
我们使用相同的训练数据在 AdGraph 中训练了 WTAGRAPH 模型和随机森林模型,并在表 V 中报告了它们在相同测试数据上的分类性能。一方面,我们发现 WTAGRAPH 在分类准确度、精确度方面优于 AdGraph在预测 1,808 次测试的请求时,召回率和 F1 得分分别提高了 1.46%、4.05%、3.99% 和 4.02%网站。值得一提的是,我们使用相同 7,224 个网站的完整数据(而不是重叠数据)训练了一个 WTAGRAPH 模型,报告其准确率 97.82%、精确率 98.00%、召回率 96.38% 和 F1 得分 97.18% VII-A。我们可以看到它在重叠数据集上的性能在不同的评估指标上下降了 2.14% 到 9.38%。这种性能差异有两个可能的原因。首先,倾斜数据(即重叠数据集)用于训练 WTAGRAPH。例如,在 Top-10K 数据集中只有 19% 的重叠请求被过滤器列表标记为 WTA,而所有请求中有 39% 被标记为 WTA(见表 I)。其次,由不完整的请求构建的训练图不能完全代表野外的网络流量,因此训练后的模型无法达到与上一小节相同的性能。
另一方面,我们发现 AdGraph 缺少对大量 WTA 请求的收集和相应分类。例如,如表 I 所示,在我们的 Top-10K 数据集中被过滤器列表标记为 WTA 的超过 614K 请求中,AdGraph 错过了超过 496K (81%) WTA 请求并且仅收集了大约 19% 的 WTA 请求。
我们进一步随机抽样并手动验证 AdGraph 和 WTAGRAPH 之间的 200 个分歧,遵循与附录 A 中描述的相同的验证方法和标准。更详细地说,我们首先抽样了 100 个 WTAGRAPH 分类为 WTA 但 AdGraph 分类为非 WTA 的请求。我们发现 WTAGRAPH 对 62 个请求的分类与过滤器列表中的标签一致,而 AdGraph 的这个数字是 38。人工验证这100个请求后,我们发现在91个可以确定标签的请求中,WTAGRAPH正确分类了57个,AdGraph正确分类了34个。我们进一步抽取了 WTAGRAPH 分类为非 WTA 但 AdGraph 分类为 WTA 的 100 个请求。我们发现 WTAGRAPH 对 55 个请求的分类与过滤器列表中的标签一致,而 AdGraph 的这个数字是 45。同样,在人工验证这100个请求后,我们发现在84个可以确定标签的请求中,WTAGRAPH正确分类了51个,AdGraph正确分类了33个。
此外,我们随机抽取并手动验证了 AdGraph 和 WTAGRAPH 之间的 200 个协议。具体来说,在他们分类为WTA的100个请求中,都被过滤器列表标记为WTA;经核实,其中96个确实是WTA请求,4个请求无法确定。在被他们归类为nonWTA的100个请求中,只有一个被过滤器列表标记为WTA;我们验证了这100个请求中有91个确实是非WTA,而8个请求无法确定。此外,被过滤列表标记为WTA的确实是WTA请求。
总之,我们发现 WTAGRAPH 从三个方面优于 AdGraph。首先,WTAGRAPH 对重叠请求的分类比 AdGraph 更准确。其次,WTAGRAPH 对 AdGraph 和 WTAGRAPH 之间那些抽样分歧的分类至少在 60% 的情况下是正确的。第三,AdGraph 错过了收集和分类大量 WTA 请求的机会。 WTAGRAPH 优于 AdGraph 有两个可能的原因。首先,我们的 WTAGRAPH 模型可以利用请求的显式特征和从图中学习的隐式特征来检测 WTA 请求,而 AdGraph 中的传统随机森林模型仅使用请求的显式特征。其次,WTAGRAPH 构建的用于表示 HTTP 网络流量和节点之间关系的 AHMG 可能比 AdGraph 构建的用于表示单个网页上下文的图表在表征 WTA 请求方面提供更多信息和帮助。请注意,WTAGRAPH 和 AdGraph 在 94 个独立的测试网站上都表现不佳,这可能与数据严重偏斜有关,因为 2,793 个请求中只有 2.15% 是 WTA 请求。对于 WTAGRAPH,另一个原因是孤立子图中的边或节点表示完全是从其自身的初始特征中学习的。
7.3 规避分析
回想一下我们在第 VI-C 节中的消融分析结果,这表明 WTAGRAPH 可以很好地抵抗规避,因为它不严重依赖某些特定特征。我们现在在归纳学习设置中评估其在不同 URL 相关规避技术下的稳健性。
我们考虑四种规避技术进行评估:更改二级域名、更改较低级别(即第 3 级、第 4 级等)域、扩展 URL 长度和替换敏感关键字。在更改二级域时,我们将二级域替换为随机生成的相同长度的字符串。在更改较低级别的域时,我们用随机生成的相同长度的字符串替换它们中的每一个(如果有的话)。因为有动机的跟踪器有可能改变二级或低级域来逃避检测,所以我们评估了这两种逃避技术。在扩展 URL 长度时,我们在其末尾的 URL 路径部分填充一个随机生成的字符串,以便 URL 路径部分从开始到结束的长度为 200 个字符。因为 WTAGRAPH 截断长度为 200 的 URL 以进行特征提取,此填充将强制 WTAGRAPH 截断剩余字符(例如,在查询字符串中),从而允许我们评估截断的信息是否会帮助攻击者逃避我们的 WTAGRAPH。请注意,填充 URL 的开头(即域名)类似于规避更改较低级别的域。在替换敏感关键字时,我们将 URL 中的关键字“ad”1 和“track”替换为随机生成的相同长度的字符串。我们选择“ad”和“track”作为关键字是因为它们包含在 EasyList [8] 的 43.36% 规则中。
我们使用在 Random-7K 图(在第 VII-A 节中描述)上训练的 WTAGRAPH 模型进行规避评估。对于测试网页的每个标记的WTA URL,我们首先分别采用上述规避技术对URL进行修改,并为修改后的URL提取新的特征。然后我们测试了 WTAGRAPH 以预测每个测试网页中的 WTA URL。按照相同的规避程序,我们还测试了 AdGraph 和过滤器列表以进行比较。
表 VI 总结了四种针对 WTAGRAPH、AdGraph [17] 和过滤器列表的规避技术的成功率。总的来说,WTAGRAPH 对所有这四种规避技术都很稳健。例如,只有 0.22% 和 2.61% 的 WTA URL 分别通过替换敏感关键字和扩展 URL 长度成功逃避了 WTAGRAPH 的检测。相比之下,21.84% 的 WTA URL 通过扩展 URL 长度来逃避 AdGraph 的检测。 AdGraph 上如此高的逃避成功率是意料之中的,因为 URL 长度在 AdGraph 中被报告为“提供最高信息增益”[17] 的两个内容特征之一。此外,通过替换关键字,6.74% 的 WTA URL 逃过了 AdGraph 的检测。这主要是因为 AdGraph 将 WTA 相关关键字的出现作为一个特征,而我们的 WTAGRAPH 并未明确提取该特征。然而,我们还发现 WTAGRAPH 在应对更改二级和低级域的规避方面不如 AdGraph 稳健。这可能是因为改变域会导致图结构发生变化(例如,添加或删除节点和边),从而影响 WTAGRAPH 的检测。
我们还发现过滤列表是最易受攻击的解决方案。具体而言,57.78% 的 WTA URL 通过更改二级域名成功规避了过滤列表。这是因为很大一部分规则是通过匹配二级域名来检测 WTA 请求的。例如,超过三分之一的 EasyList [8] 规则匹配二级域以进行 WTA 检测。通过更改二级域名,可以轻松规避“||ad1data.com”、“||adserved.net$third-party”等规则。此外,过滤器列表也比 WTAGRAPH 和 AdGraph 更容易受到更改低级域和替换关键字的攻击。
7.4 实时性能
为了实时评估 WTAGRAPH 的性能,我们通过利用 Google Chrome [58] 的本机消息传递 API 实现了基于扩展的 WTA 检测解决方案,该解决方案支持我们的浏览器扩展程序与本机 WTAGRAPH 应用程序之间的通信。更详细地说,我们首先将 WTAGRAPH 及其所有依赖项捆绑到一个独立的可执行文件中,谷歌浏览器可以在单独的进程中将其作为本机消息传递主机启动。然后,我们将一个消息传递组件添加到我们的数据收集扩展(在图 2 中介绍),以便它可以使用本机消息传递 API 向 WTAGRAPH 可执行文件发送消息和从 WTAGRAPH 可执行文件接收消息。总的来说,对给定网页的实时 WTA 检测是通过以下四个步骤执行的。首先,我们的扩展程序在访问我们在第 IV-B 节中介绍的网页时收集 HTTP 流量、DOM 和 JavaScript API 访问。其次,它使用本机消息传递 API 将收集的数据发送到在本地计算机上运行(由 Google Chrome 启动)的 WTAGRAPH 可执行文件。第三,WTAGRAPH 提取特征,从收集到的数据中构建一个测试 AHMG,并预测每个收集到的请求的标签。最后,WTAGRAPH 使用本机消息传递 API 将其预测返回给扩展。
基于这个实现,我们测量了 WTAGRAPH 在 Alexa Top 1K 网站上的实时性能。我们选择了在 Random-5K 图(在第 VII-A 节中描述)上训练的 WTAGRAPH 模型进行实时评估。该模型确保在 Top 1K 网站中,有一半在 Random-5K 训练图中出现过(即转导学习设置),而另一半在训练中从未出现过,可以在归纳学习环境。具体来说,我们测量了:(1) 与普通的 Google Chrome 浏览器相比,WTAGRAPH 引入了多少开销? (2) WTAGRAPH 需要多长时间才能完成对一个网页的预测? (3) WTAGRAPH 对请求的预测有多好?
从 2021 年 2 月 23 日到 2 月 28 日,我们分别使用集成了 WTAGRAPH 的 Google Chrome 浏览器和普通 Google Chrome 浏览器访问了 Top 1K 网站的主页 10 次,以测量开销。附录 C 详细说明了本小节中实验的硬件和软件配置。对于主页的每次访问,我们通过测量每个浏览器中 DOM 的 navigationStart 和 loadEventEnd 事件之间的时间差来记录页面加载时间,并通过测量发送第一条消息之间的时间差来记录扩展中 WTAGRAPH 的整体执行时间(即发送收集的数据)并接收预测结果作为最后一条消息。我们还保存了预测结果以供分析。
从开销的角度来看,我们发现普通谷歌浏览器的页面加载时间平均为 5,903 毫秒,而集成 WTAGRAPH 的谷歌浏览器平均为 6,419 毫秒。换句话说,我们的实现平均引入了 516 毫秒的页面加载开销。这种开销主要是由我们扩展中的 JavaScript API 检测和数据收集(例如,轮询 JavaScript 调用堆栈以跟踪 API 访问)引起的,并且可以通过改进实现来减少。
从整体执行时间来看,我们发现 WTAGRAPH 平均每个网页只需要 266 毫秒就可以完成对 1 个网页请求的预测。 WTAGRAPH 和扩展程序之间的消息交换平均每个网页需要 100 毫秒,WTAGRAPH 用剩下的 166 毫秒来提取特征、构建图形并预测网页上所有请求的标签。
从预测性能的角度来看,我们从 Top 1K 主页的所有 10 次爬取中总共收集了 2,002,026 个请求,并在附录 E 的表 VIII 中总结了 WTAGRAPH 的预测性能。总体而言,我们发现 WTAGRAPH 可以准确地预测所有收集到的请求92.80%,准确率 94.29%,召回率 91.29%,F1 分数 92.77%。与第 VI-A 和 VII-A 节相比,我们观察到性能下降。这主要是因为用于实时预测的 WTAGRAPH 模型是根据七个月前收集的数据进行训练的。然而,这个问题可以通过定期重新训练 WTAGRAPH 来解决。 WTAGRAPH 在归纳学习设置中可以实现的真实预测性能是我们在第 VII-A 节中介绍的,即再训练模型可以实时实现的预测性能。
总之,WTAGRAPH 可以与浏览器很好地集成,以很小的开销实现实时竞争性能。如果进一步改进集成实现,将会有更少的开销。
8 DISCUSSION
8.1 更好地使用 WTAGRAPH 的建议
如第 VI-B 节所示,WTAGRAPH 能够识别被过滤器列表遗漏的新 WTA 请求和被过滤器列表错误阻止的非 WTA 请求。因此,WTAGRAPH 可用于(例如,在网络隐私爬虫中)通过增加新规则来检测新的 WTA 请求并改进现有规则以减少错误来改进现有的过滤器列表。除了基于扩展的部署(正如我们在第 VII-D 节中评估的那样),WTAGRAPH 还可以潜在地部署为浏览器组件以支持浏览器的内置 WTA 检测,这类似于 Brave 中的 PageGraph [23]浏览器。但是,由于需要针对每次网页访问的多个请求构建测试AHMG才能达到良好的检测性能,因此立即屏蔽当前网页访问的请求是不明智的。相反,检测结果可用于阻止后续网页访问中的相同请求。总的来说,最好在爬虫中使用 WTAGRAPH 来精炼过滤器列表。
8.2 局限性和潜在的未来工作
虽然第 VI 节和第 VII 节的评估结果表明 WTAGRAPH 在 WTA 检测中是有效的,但我们承认它有一些局限性。例如,它在 Top-10K 数据集上的假阴性率和假阳性率分别为 3.75% 和 1.03%;它在检测发送到 CDN 服务器的 WTA 请求方面的准确性相对较低(附录 A)。此外,与 AdGraph [17] 中的类似,我们在训练过程中使用过滤器列表的输出作为真实标签,但过滤器列表本身会产生错误的结果,如我们的分析和 [17] 中所示;更好的真实标签(例如,由隐私研究人员或工程师验证)可能有助于 WTAGRAPH、AdGraph 和相关工作。
为了解决 WTAGRAPH 的局限性并进一步提高其性能,我们确定了以下潜在的未来工作。首先,节点和边的新特征可能有助于减少 WTAGRAPH 的错误分类。例如,某些 DOM 特性(例如,标签属性和 JavaScript 存在)可以帮助 WTAGRAPH 正确检测更多子帧 WTA 请求。可以设计更多特定于每种类型请求的特征,以更好地表征 WTA 请求。其次,细粒度的聚合策略可以帮助提高 WTAGRAPH 在检测发送到 CDN 服务器的 WTA 请求方面的性能。例如,通过仅聚合具有相同请求类型的邻居边缘,WTAGRAPH 可能能够从邻居那里学习更多相关特征。第三,微调我们的 WTA-GNN 模型可以帮助提高其性能。例如,可以在训练过程中应用子采样和负采样技术,以潜在地减少误报和漏报。第四,可以探索来自高级或替代 GNN 模型的一些技术(例如,来自 GAT [20] 的注意力机制和来自 GraphSage [19] 的局部邻域采样方法)来帮助提高 WTAGRAPH 的性能。同时,虽然现有的基于知识图 (KG) 的公式和学习算法(例如 [59]-[61])由于多图定义和边缘表示差异而不易应用于我们的 WTA 检测问题,但一些基于 KG 的技术可能对以后的探索有帮助。
此外,手动筛选的过滤器列表在检测非英语网站 [62] 上的 WTA 请求方面表现不佳,因为它们通常针对英语网站。因此,在非英语网站上对 WTAGRAPH 的评估可能会提供有关 WTAGRAPH 是否有助于解决此问题的信息。
9 总结
在本文中,我们提出了 WTAGRAPH,一种基于图神经网络的网络跟踪和广告检测框架。我们首先将 WTA 检测制定为 AHMG 中边缘表示学习和分类的任务。然后我们在 WTAGRAPH 中设计并实现了四个组件(代码可在 [63] 获得),以便它可以执行边缘表示学习和 WTA 检测。评估结果表明,WTAGRAPH 可以在转导和归纳学习环境中有效地检测 WTA 请求。例如,它以 97.90% 的准确率、98.38% 的准确率、96.25% 的召回率和 97.30% 的 F1 分数检测 Top-10K 网站中的转导学习设置的 WTA 请求;它在归纳学习设置中以 97.82% 的准确率、98.00% 的准确率、96.38% 的召回率和 97.18% 的 F1 分数检测 WTA 请求。人工验证结果表明,WTAGRAPH 可以检测到被过滤列表遗漏的新 WTA 请求,并识别被过滤列表错误标记的非 WTA 请求。我们的消融分析、规避评估和实时评估表明,WTAGRAPH 在实践中具有具有竞争力的性能和灵活的部署选项。

















 2605
2605




 到【灌水乐园】发言
到【灌水乐园】发言







