




 本文介绍了一种名为RECFORMER的新方法,它通过学习语言表征解决序列推荐中的冷启动和跨域问题。RECFORMER使用键值对表示item,结合Longformer编码文本,通过预训练和微调框架,实现了语言理解和推荐的联合,从而实现知识迁移。实验结果显示,RECFORMER在多种数据集上表现优秀,特别是在低资源场景中展现了潜力。
本文介绍了一种名为RECFORMER的新方法,它通过学习语言表征解决序列推荐中的冷启动和跨域问题。RECFORMER使用键值对表示item,结合Longformer编码文本,通过预训练和微调框架,实现了语言理解和推荐的联合,从而实现知识迁移。实验结果显示,RECFORMER在多种数据集上表现优秀,特别是在低资源场景中展现了潜力。
文章目录
今年KDD上一篇paper,通过学习语言表征的方式进行序列推荐,特点之一是摒弃了传统推荐中使用的ID,用key:value格式的item属性,也就是item的内容来表示item。

INTRODUCTION 逻辑
-
任务场景:序列推荐,即按照时间顺序建模用户历史的交互,基于此,推荐用户可能感兴趣的潜在item。
-
传统序列推荐方法面临的challenges:传统的推荐模型将item转为原子ID,然后创建embedding table对item ID进行编码作为item的表示。embedding table会在模型训练中根据user-item的交互数据不断更新。这就是ID-based方法。这种方法面临的问题有:
- 推荐中冷启动问题(新的item因为没有训练过表示从而得不到合适的推荐)
- 跨域推荐或者说不同数据集的迁移问题(每个数据集都定义原子ID,纵使不同领域的item有所关联,比如同名的电影和小说之间的联系,传统的方法也无法将模型进行很好的迁移)。
因此,一个能进行迁移的推荐模型能够适应于冷启动场景和跨域推荐场景。
-
现存可迁移的推荐系统的限制:
- 先前的可迁移推荐系统的工作通常假设共享信息是可用的,比如两个领域之间user-item交互上的重叠、共同的特征等,然后通过学习语义映射或者迁移组件来减少不同领域之间的gap。而这种假设在真实场景下通常很难达成。
- 还有一些方法是以自然语言作为通用接口。一种基本的想法是利用一个预训练的语言模型来获得文本表示,然后学习文本表示到item表示的转换,从而实现不同推荐领域之间的知识迁移。这样的方法目前存在的限制是:
- 预训练模型训练语料(通用语言领域)和item text之间存在gap,导致通过模型获得的item text的文本表示往往是次优的。
- 预训练模型的文本表示无法学习不同项目属性的重要性(这一点没太理解,这难道不是因为输入文本构造的问题吗?)
- 预训练模型的训练目标和推荐模型训练目标的不一致,导致预训练模型的推荐能力没有被充分挖掘。(预训练模型训练目标一般是MLM,而序列推荐是预测下一项item)-> 联合训练。
-
所提方法:一个能为序列推荐有效学习语言表示的框架,RECFORMER。一个将自然语言理解和推荐统一的ID-free序列推荐范式。通过自然语言理解和推荐任务的联合训练,从而利用语言模型的通用性实现推荐中的知识迁移。为了实现这个idea,作者认为有三个challenge需要解决:
- 当item输入到语言模型中时,需要一个统一的输入数据格式,要求这种格式足够灵活能够包含各类item的文本信息。(感觉这个不能算是challenge,,item的文本信息最终想要输入到语言模型中还是需要转成文本句子的形式,论文中的方法也是展平成item ‘sentence’)
- 在一个框架中,如何同时建模语言和item的序列关系?item和item文本如何在模型中对齐?
- ID-free的方法下,如何在没有item embedding table的情况下,根据语言模型对item进行有效排名而产生推荐?(推荐是通过ranking模型产生的)
-
RECFORMER的流程
- (解决第一个challenge)将item用key-value对表示,key是item的属性类型,value是item的属性。
- 使用基于Longformer的双向Transformer来编码item的text,这是一种encoder-only的模型,能够编码比较长的序列。
- 为了进行有效的语言表征学习,为模型设计了训练框架,包括预训练、微调和推理阶段。
-
整体逻辑:序列推荐challenge -> 需要有迁移能力的推荐模型,目前可迁移方法的限制 -> 为了解决上述限制,想到的idea,提出的方法。-> 所提方法的实施过程。
RECFORMER方法
recformer方法的结构图如图所示。
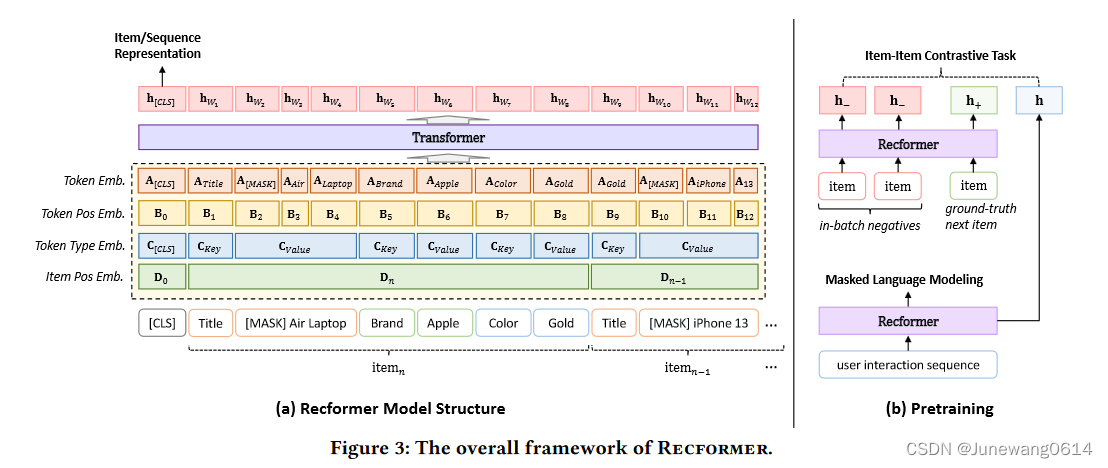
模型结构
模型input
- 对item的表示:每个item根据自己的属性建模为一个dictionary D i { ( k 1 , v 1 ) , ( k 2 , v 2 ) , … , ( k m , v m ) } D_i \left \{ (k_1,v_1),(k_2,v_2),\dots,(k_m,v_m) \right \} Di{ (k1,v1),(k2,v2),…,(km,vm)}。为了能输入到语言模型中,将这个dictionary展平为一个item sentence: T i = { k 1 , v 1 , k 2 , v 2 , … , k m , v m } T_i = \left \{k_1,v_1,k_2,v_2,\dots,k_m,v_m \right \} Ti={ k1,v1,k2,v2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 334
334




 到【灌水乐园】发言
到【灌水乐园】发言







