




 Transformer模型是序列转换领域的创新,它完全依赖self-attention机制,摒弃了传统的RNN和卷积。模型由encoder-decoder结构组成,其中encoder通过Multi-Head Attention并行处理输入序列,decoder则结合遮罩机制防止未来位置信息泄露,确保自回归性。Self-Attention通过 scaled dot-product attention 实现不同位置间的交互,Multi-Head Attention则允许模型关注不同位置的多种表示子空间。此外,Position-wise Feed-Forward Networks和Positional Encoding则分别提供了额外的特征变换和位置信息。Transformer的设计使得长距离依赖的学习更为高效,适合大规模序列任务。
Transformer模型是序列转换领域的创新,它完全依赖self-attention机制,摒弃了传统的RNN和卷积。模型由encoder-decoder结构组成,其中encoder通过Multi-Head Attention并行处理输入序列,decoder则结合遮罩机制防止未来位置信息泄露,确保自回归性。Self-Attention通过 scaled dot-product attention 实现不同位置间的交互,Multi-Head Attention则允许模型关注不同位置的多种表示子空间。此外,Position-wise Feed-Forward Networks和Positional Encoding则分别提供了额外的特征变换和位置信息。Transformer的设计使得长距离依赖的学习更为高效,适合大规模序列任务。
2 Background
The goal of reducing sequential computation also forms the foundation of the Extended Neural GPU
[16], ByteNet [18] and ConvS2S [9], all of which use convolutional neural networks as basic building
block, computing hidden representations in parallel for all input and output positions. In these models,
the number of operations required to relate signals from two arbitrary input or output positions grows
in the distance between positions, linearly for ConvS2S and logarithmically for ByteNet. This makes
it more difficult to learn dependencies between distant positions [12]. 在Transformer中这个过程被减少为常数级别的操作, albeit at the cost of reduced effective resolution due to averaging attention-weighted positions, an effect we counteract with Multi-Head Attention as described in section 3.2.
Self-attention, 有时也称为intra-attention,是一种将单个序列中不同位置关联起来的attention机制,最终目的是计算得到关于这个序列的一种表示方式。Self-attention已经在许多任务中得到了成功应用,包括reading comprehension, abstractive summarization, textual entailment 以及 learning task-independent sentence representations [4, 27, 28, 22].
End-to-end memory networks are based on a recurrent attention mechanism instead of sequencealigned recurrence and have been shown to perform well on simple-language question answering and
language modeling tasks [34].
据我们所知,Transformer是第一个完全依赖self-attention机制,不使用sequencealigned RNNs or convolution来计算输入输出representation的transduction model。
3 Model Architecture
Most competitive neural sequence transduction models有一个encoder-decoder结构[5, 2, 35]。 这里,encoder将输入序列的符号表示(x1,…,xn)(x_1,\dots,x_n)(x1,…,xn)映射为连续的序列化表达z=(z1,…,zn)z=(z_1,\dots,z_n)z=(z1,…,zn)。给定zzz后,decoder接下来按每步一个的顺序生成输出符号序列y1,…,ym)y_1,\dots,y_m)y1,…,ym)。在每一步模型都是auto-regressive [10]的,consuming the previously generated symbols as additional input when generating the next.
Transformer同样遵循上述结构,对encoder和decoder都使用堆叠的self-attention and point-wise, fully connected layers。如图1左右所示:
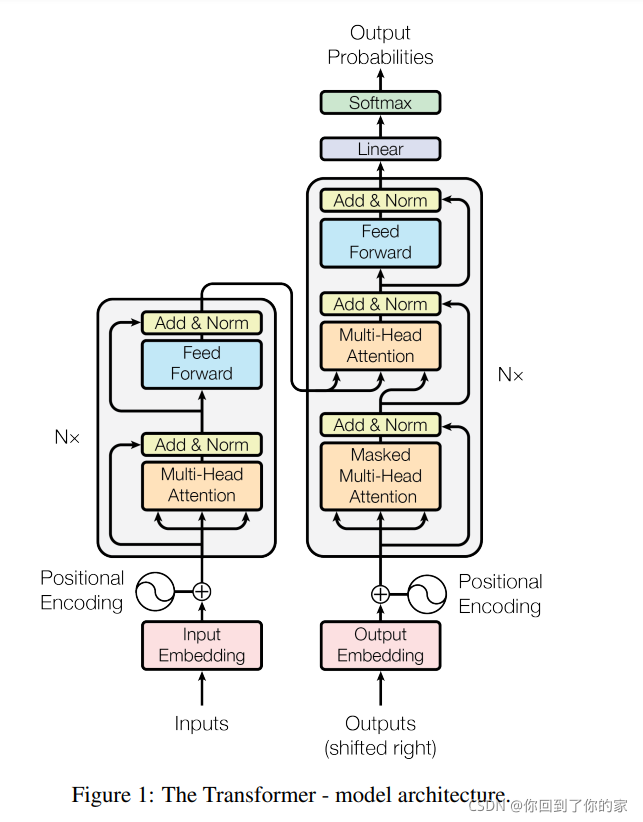
3.1 Encoder and Decoder Stacks
Encoder
上图中左侧为encoder块,右侧为decoder块。橙色部分为Multi-Head Attention,这由多个Self-Attention组成,我们可以看到Encoder块包含一个Multi-Head Attention,而Decoder块包含两个Multi-Head Attention(其中一个用到Masked)。Multi-Head Attention上方还包括一个Add&Norm层,Add表示残差连接用于防止网络退化,Norm表示Layer Normalization,用于对每一层的激活值进行归一化。以一个例子说明,假设我们在encoder input处的输入是机器学习,在decoder input中输入的是,输出是machine。在下一个时刻decoder input的输入是machine,输出是learning,不断重复直到输出是句点(。),代表翻译结束。
接下来看encoder和decoder内部分别做了什么,先看左半部分的encoder:我们输入X∈R(nx,N)X\in R(n_x,N)X∈R(nx,N)通过一个input Embedding的转移矩阵Wx∈R(d,nx)W_x\in R(d,n_x)Wx∈R(d,nx)变成了一个张量,这个张量就是上文的embedding I∈R(d,N)I\in R(d,N)I∈R(d,N),接下来我们加上一个表示位置的positional encoding E∈R(d,N)E\in R(d,N)E∈R(d,N),得到一个张量,接下来进行后面的操作。
张量进入绿色的块后会重复N次。绿色的块中第一层是multi-head attention,一个序列I∈R(d,N)I\in R(d,N)I∈R(d,N)经过multi-head attention后,我们可以得到另外一个序列O∈R(d,N)O\in R(d,N)O∈R(d,N)
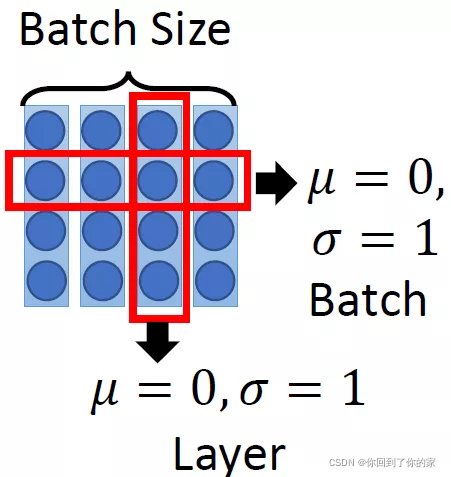
接下来进行Add&Norm,这个意思是,将multi-head attention层的输入I∈R(d,N)I\in R(d,N)I∈R(d,N)和输出O∈R(d,N)O\in R(d,N)O∈R(d,N)进行相加后,再进行Layer Normalization,Layer Normalizaiton和Batch Normalizaiton的区别见如下两个图:
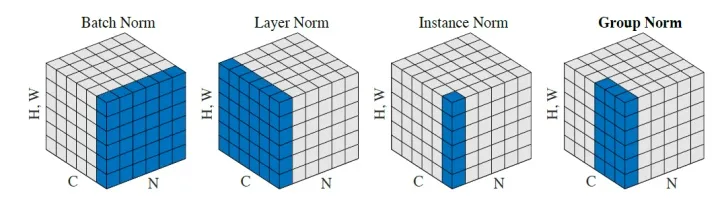
其中,Batch Normalization和Layer Normalization的对比可以概括为上图,Batch Normalization强行让一个batch的数据的某个channel的μ=0,σ=1\mu=0,\sigma=1μ=0,σ=1 ,而Layer Normalization让一个数据的所有channel的μ=0,σ=1\mu=0,\sigma=1μ=0,σ=1 。下图也是说明了ayer Normalizaiton和Batch Normalizaiton的区别:
接下来跟着的是一个Feed Forward的前馈网络和一个Add&Norm层,所以,绿色块中前两个层的操作表示为:
O1=LayerNormalization(I+Multihead Self Attention(I))O_1=Layer Normalization(I+Multihead\ Self\ Attention(I))O1=LayerNormalization(I+Multihead Self Attention(I))
这一绿色块的后两层操作的表达式为:
O2=LayerNormalization(O1+Feed Forward Network(O1))O_2=Layer Normalization(O_1+Feed\ Forward\ Network(O_1))O2=LayerNormalization(O1+Feed Forward Network(O1))
整体可以表示为:
Block(I)=O2Block(I)=O_2Block(I)=O2
所以transformer的encoder整体操作为:
Encoder(I)=Block(...Block(Block(I)))N timesEncoder(I)=Block(...Block(Block(I)))\quad\quad N\ timesEncoder(I)=Block(...Block(Block(I)))N times
在论文中,设定N=6N=6N=6,为了实现残差连接,模型中的所有子层(包括embedding层)的输出都是512维,即dmodel=512d_{model}=512dmodel=512。
Decoder
Decoder的输入包括两部分,下方是前一个time step的输出embedding,即上文所述的I∈R(d,N)I\in R(d,N)I∈R(d,N),再加上一个表示位置的positional embedding E∈R(d,N)E\in R(d,N)E∈R(d,N),得到一个张量,接下来进行后面的操作。即进入绿色块,首先进行Masked Multi-Head Self-Attention,masked的意思是使得attention只会attend on 已经产生的序列,这个很合理,因为还没有产生出来的东西不存在,无法进行attention。
输出是对应iii位置的输出词的概率分布。
输入是:Encoder的输出和对应i−1i-1i−1位置的decoder的输出,所以中间的attention不是self-attention,它的key和value来自encoder,query来自上一位置decoder的输出。
这里要特别注意一下,编码可以并行计算,一次性全部encoding出来,但解码不是一次把所有序列解出来的,而是像RNN一样一个一个解出来的,因为要用上一个位置的输入当作attention的query。

下面详细介绍下Masked Multi-Head Self-attention的具体操作,Masked在Scale操作之后,softmax操作之前。
因为在翻译的过程中是顺序翻译的,即翻译完第i个单词,才可以翻译第i+1i+1i+1个单词。通过maked操作可以防止第i个单词获取到第i+1个单词的信息。下面以 “我有一只猫” 翻译成 “I have a cat” 为例,了解一下 Masked 操作。在 Decoder 的时候,是需要根据之前的翻译,求解当前最有可能的翻译,如下图所示。首先根据输入 “” 预测出第一个单词为 “I”,然后根据输入 " I" 预测下一个单词 “have”。
待补充
decoder同样由 N=6N=6N=6 个相同的层堆叠而成。相比于encoder层中有两个子层,decoder插入了一个新的子层,这个子层对encoder层的输出执行multi-head attention。和encoder类似,decoder中同样使用了残差连接,然后应用了layer normalization。我们同样修改了decoder层中的self-attention子层来prevent positions from attending to subsequent positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
3.2 Attention
假设我们的输入是下图的x1−x4x_1-x_4x1−x4,这是一个序列:
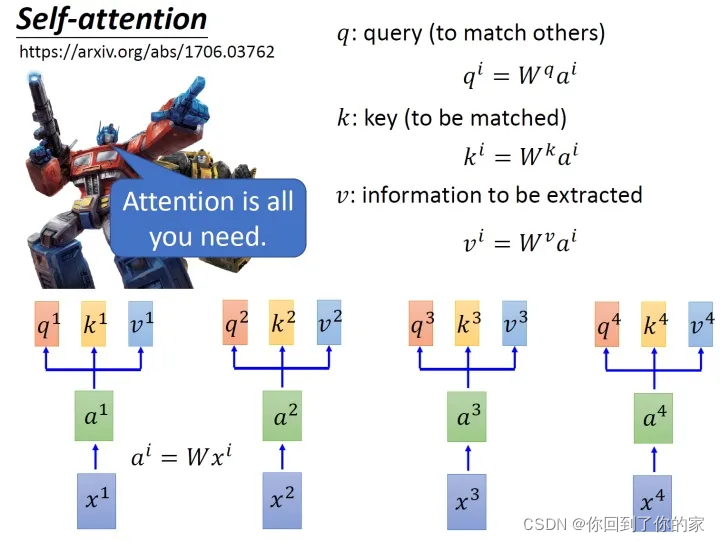
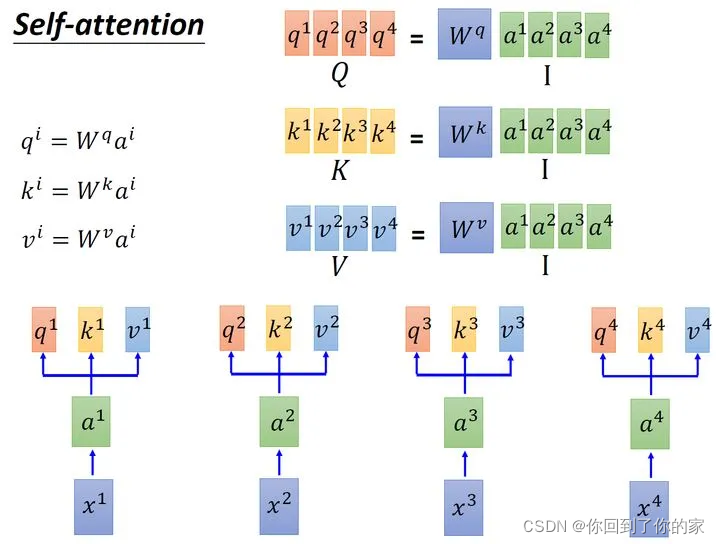
每一个输入向量先乘上一个矩阵WWW得到embedding,即向量a1−a4a_1-a_4a1−a4,接下来这个embedding进入self-attention层,每一个向量a1−a4a_1-a_4a1−a4分别乘上三个不同的转化矩阵Wq,Wk,WvW_q,W_k,W_vWq,Wk,Wv,以向量a1a_1a1为例,这时分别得到三个不同的向量q1,k1,v1q_1,k_1,v_1q1,k1,v1。
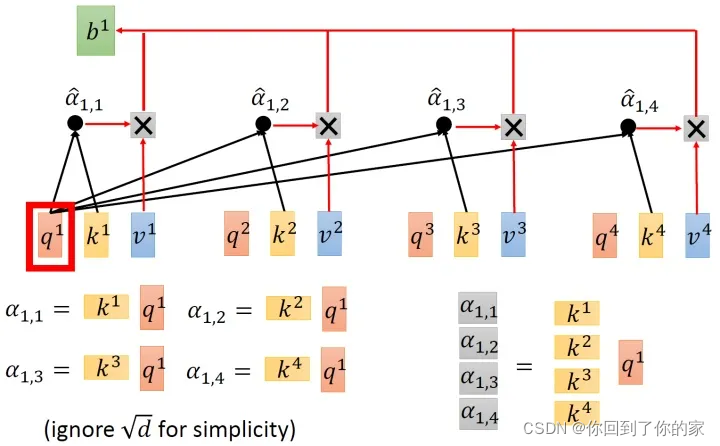
接下来我们使用每个query q去对每个key k做attention,attention本质上就是匹配这两个向量有多接近,例如我们现在对q1q_1q1和k1k_1k1做attention,我们就可以把这两个向量做scaled inner product,得到α1,1\alpha_{1,1}α1,1。接下来用a1a_1a1和k2k_2k2做attention,得到α1,2\alpha_{1,2}α1,2,同理得到α1,3,α1,4\alpha_{1,3},\alpha_{1,4}α1,3,α1,4。上述过程可以用下图表示:
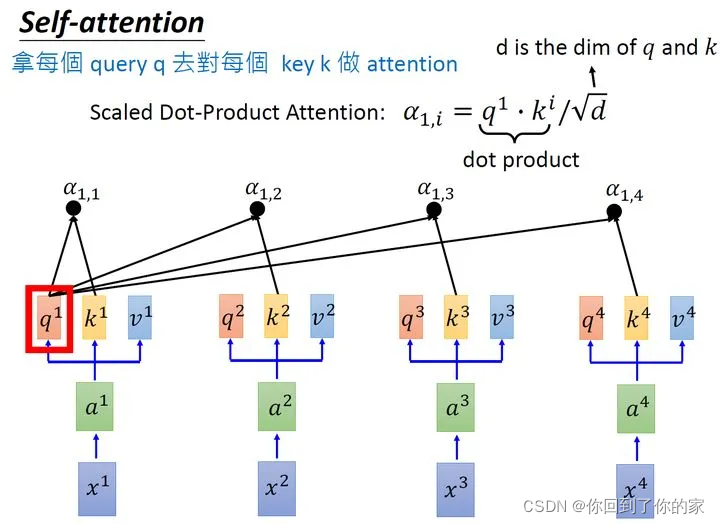
scaled inner product计算方式如下:
α1,i=q1⋅ki/d\alpha_{1,i}=q_1\cdot k_i/\sqrt{d}α1,i=q1⋅ki/d
这里d是q和k的维度。因为q⋅kq\cdot kq⋅k的数值会随着维度的增大而增大,所以要除以dimension\sqrt{dimension}dimension的值,相当于进行了归一化。
接下来的过程如图6所示,将计算得到的所有α1,i\alpha_{1,i}α1,i值取softmax操作:
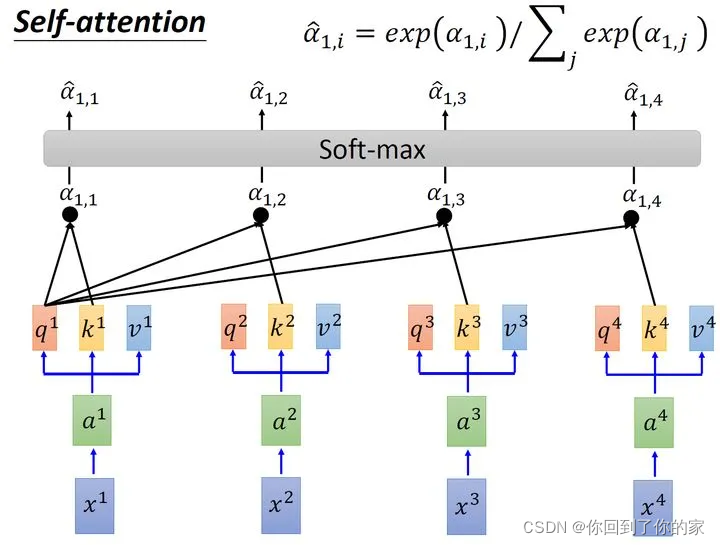
进行softmax操作后我们得到了α^1,i\hat{\alpha}_{1,i}α^1,i,我们将它和所有viv_ivi值相乘。就是用α^1,1\hat{\alpha}_{1,1}α^1,1乘v1v_1v1,后面也类似,将结果进行加和得到b1b_1b1,所以在获取到b1b_1b1的过程中用到了整个序列的信息。如果仅考虑局部信息,那么仅需要学习出对应的α^1,i=0\hat{\alpha}_{1,i}=0α^1,i=0,此时b1b_1b1就不再带有那个对应分支的信息了,如果需要学习全局信息,那么保证α^1,i≠0\hat{\alpha}_{1,i}\ne0α^1,i=0,此时b1b_1b1就带有全部的对应分支的信息了,计算得到b1b_1b1的过程如下图所示:
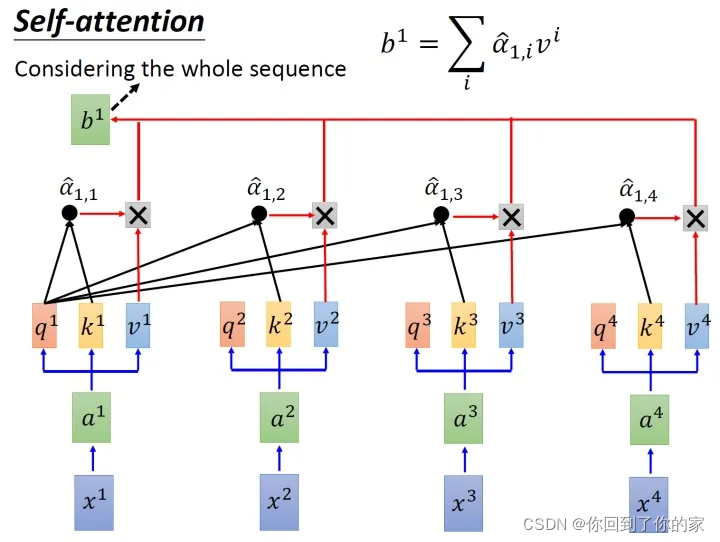
使用类似的方法,我们可以计算出b2b_2b2,如下图所示:
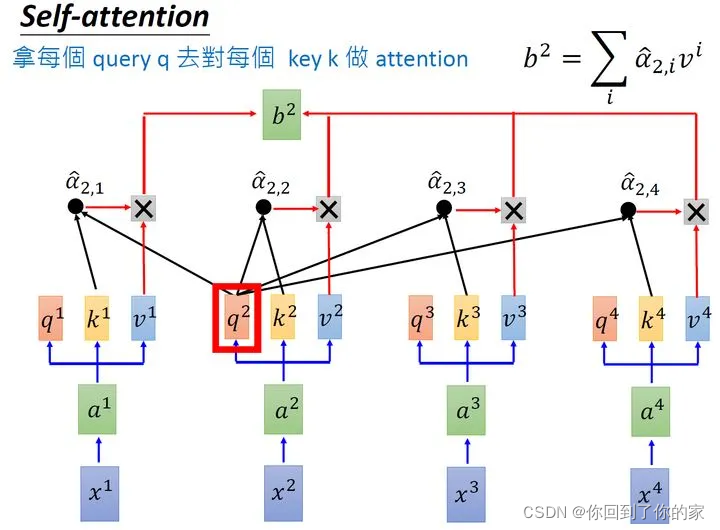
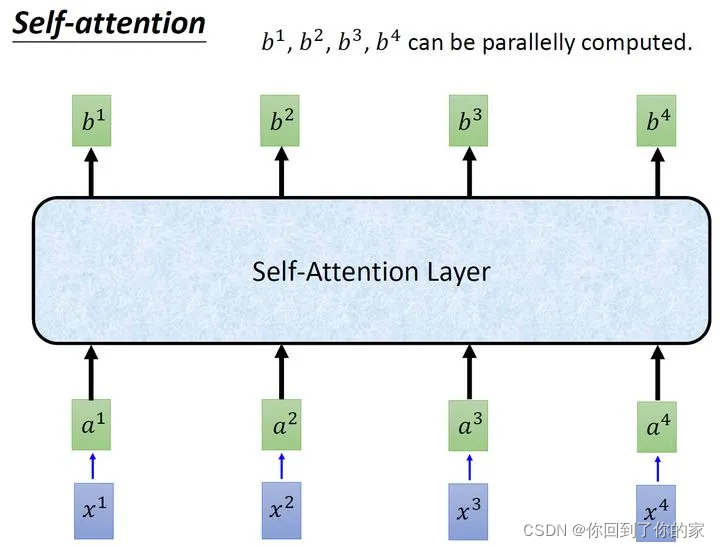
同理我们可以计算得到b3,b4b_3,b_4b3,b4。经过上述一连串计算,self-attention layer层所做的事和RNN其实是一样的,只是它可以并行计算获取结果,如下图所示:
接下来我们使用矩阵表示上述过程,输入的embedding是I=[a1,a2,a3,a4]I=[a_1,a_2,a_3,a_4]I=[a1,a2,a3,a4],我们接下来使用III乘以转化矩阵WqW_qWq得到Q=[q1,q2,q3,q4]Q=[q_1,q_2,q_3,q_4]Q=[q1,q2,q3,q4],每一列都代表一个向量q。同理我们用III乘以转化矩阵WkW_kWk得到K=[k1,K2,K3,K4]K=[k_1,K_2,K_3,K_4]K=[k1,K2,K3,K4],它的每一列都代表一个向量k。同理通过转化矩阵WvW_vWv我们可以得到V=[v1,v2,v3,v4]V=[v_1,v_2,v_3,v_4]V=[v1,v2,v3,v4],它的每一列代表一个向量v。如下图所示:
接下来是k和q的attention过程,我们可以将向量k横过来变成行向量,然后列向量q做内积(省略d\sqrt{d}d)。这样α\alphaα就成了4×44\times44×4的矩阵,它由4个行向量拼成的矩阵和四个列向量拼成的矩阵做内积得到,如下图所示:

这里整个过程可以被表示为如下图所示的过程:
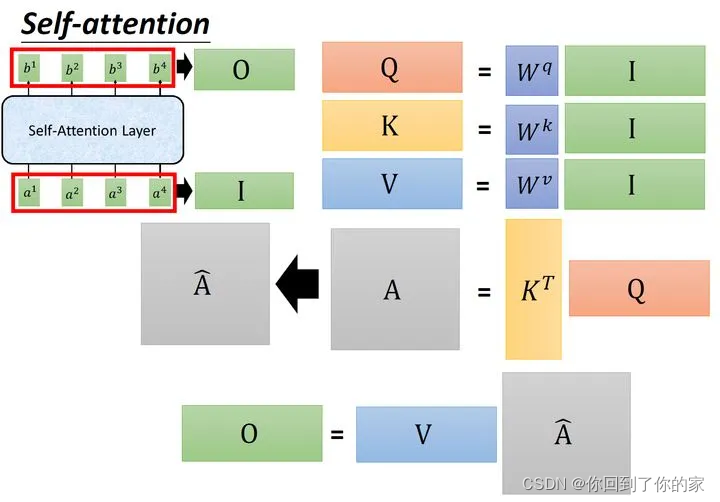
输入矩阵I∈R(d,N)I\in R(d,N)I∈R(d,N)分别乘上三个不同的矩阵Wq,Wk,Wv∈R(d,d)W_q,W_k,W_v\in R(d,d)Wq,Wk,Wv∈R(d,d)得到三个中间矩阵Q,K,V∈R(d,N)Q,K,V\in R(d,N)Q,K,V∈R(d,N)。它们的维度相同,将K转置之后与Q相乘得到Attention矩阵A∈R(N,N)A\in R(N,N)A∈R(N,N),代表每一个位置两两之间的attention。再将它取softmax操作得到A^∈R(N,N)\hat{A}\in R(N,N)A^∈R(N,N),最后将它乘以V矩阵得到输出向量O∈R(d,N)O\in R(d,N)O∈R(d,N)
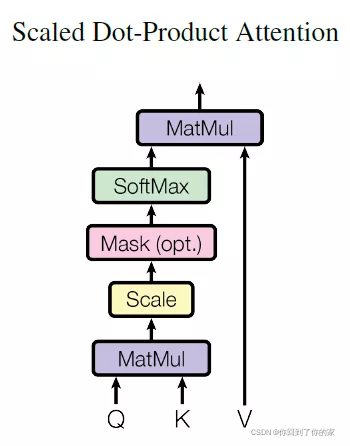
3.2.1 Scaled Dot-Product Attention
我们将我们的特定attention机制称为 “Scaled Dot-Product Attention”,如图2所示:
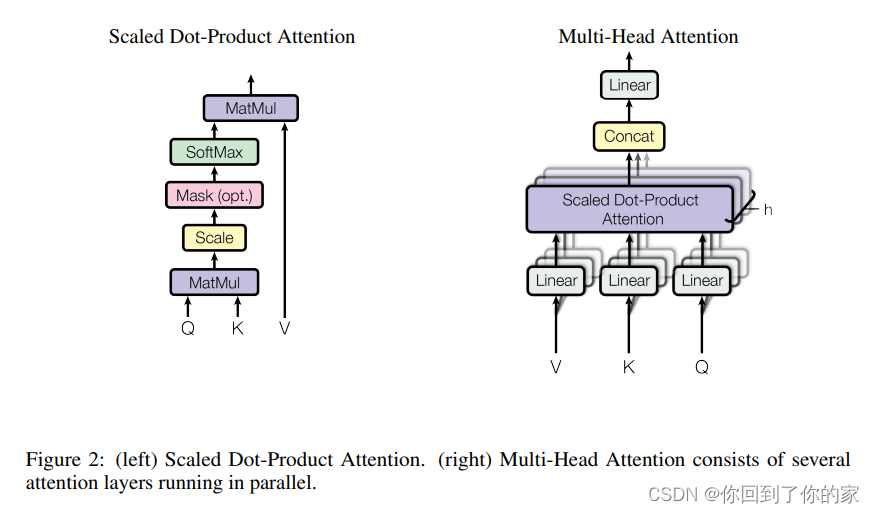
输入包括维度为dkd_kdk的queries、key以及维度为dvd_vdv的values。我们计算the dot products of the query with all keys, divide each by dk\sqrt{d_k}dk, and apply a softmax function to obtain the weights on the values.
实际上,我们对一组queries同时计算attention function,然后打包进一个矩阵QQQ。keys以及values同样打包进了矩阵KKK以及VVV。我们通过如下方式计算输出矩阵:
Attention(Q,K,V)=softmax(QKTdk)V(1)\text{Attention}(Q,K,V)=\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V\quad\quad\quad\quad\quad(1)Attention(Q,K,V)=softmax(dkQKT)V(1)
两个最常使用的attention functions是additive attention [2]以及dot-product (multiplicative) attention. Dot-product attention 和我们的算法相同,除了缩放因子 1dk\frac{1}{\sqrt{d_k}}dk1。Additive attention通过使用一个单隐藏层前馈网络来计算compatibility function。尽管这两种attention的理论计算复杂度类似,但是dot-product attention在实际计算中明显更快并且更高效, 这是因为它可以通过高度优化的矩阵乘法代码进行实现。
尽管对于较小的dkd_kdk来说两种mechanism表现相似,additive attention在dkd_kdk较大且没有scaling时效果好于dot product attention 。我们设想对于较大的dkd_kdk,dot product会在量级上迅速增长,pushing the softmax function into regions where it has extremely small gradients(这里看下脚注)。为了消除这种影响,我们将dot product 缩小了尺度因子1dk\frac{1}{\sqrt{d_k}}dk1。
3.2.2 Multi-Head Attention
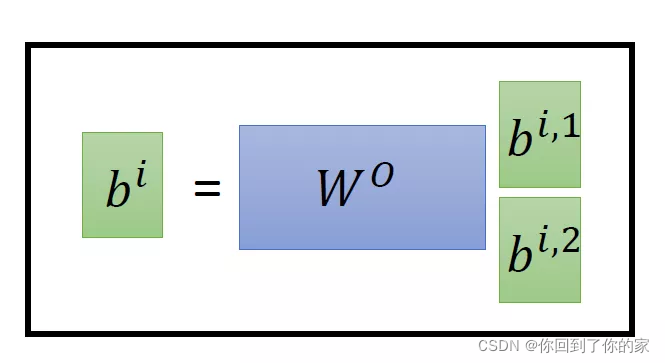
以两个head的情况为例:由aia_iai生成的qiq_iqi进一步乘以两个转移矩阵变为qi,1q_{i,1}qi,1和qi,2q_{i,2}qi,2,同理我们可以得到ki,1k_{i,1}ki,1和ki,2k_{i,2}ki,2,vi,1v_{i,1}vi,1和vi,2v_{i,2}vi,2。接下来qi,1q_{i,1}qi,1再与ki,1k_{i,1}ki,1进行attention,得到weighted sum的权重α\alphaα,再与vi,1v_{i,1}vi,1做weighted sum得到最终的bi,1(i=1,2,...,N)b_{i,1}(i=1,2,...,N)bi,1(i=1,2,...,N)。同理我们可以得到bi,2(i=1,2,...,N)b_{i,2}(i=1,2,...,N)bi,2(i=1,2,...,N)。现在我们已经获取了bi,1(i=1,2,...,N)∈R(d,1)b_{i,1}(i=1,2,...,N)\in R(d,1)bi,1(i=1,2,...,N)∈R(d,1)和bi,2(i=1,2,...,N)∈R(d,1)b_{i,2}(i=1,2,...,N)\in R(d,1)bi,2(i=1,2,...,N)∈R(d,1),我们可以把它们拼接起来,然后通过一个转换矩阵来调整维度,使其与刚才的bi(i=1,2,...,N)∈R(d,1)b_i(i=1,2,...,N)\in R(d,1)bi(i=1,2,...,N)∈R(d,1)维度相同,整个过程如下所示:
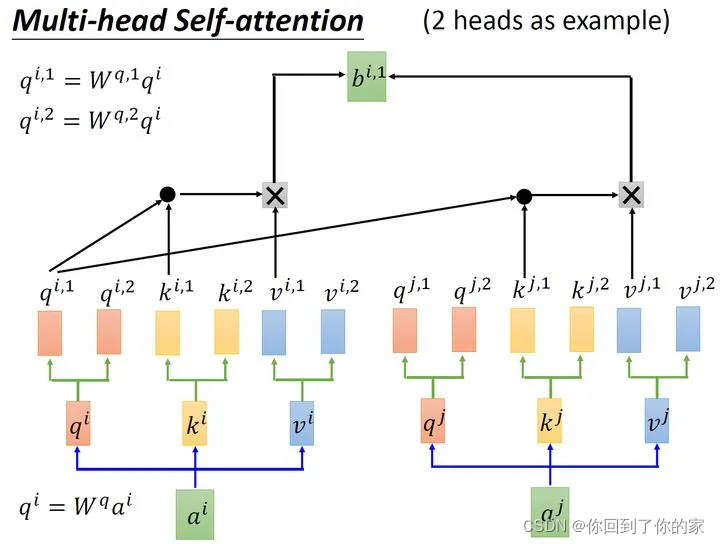
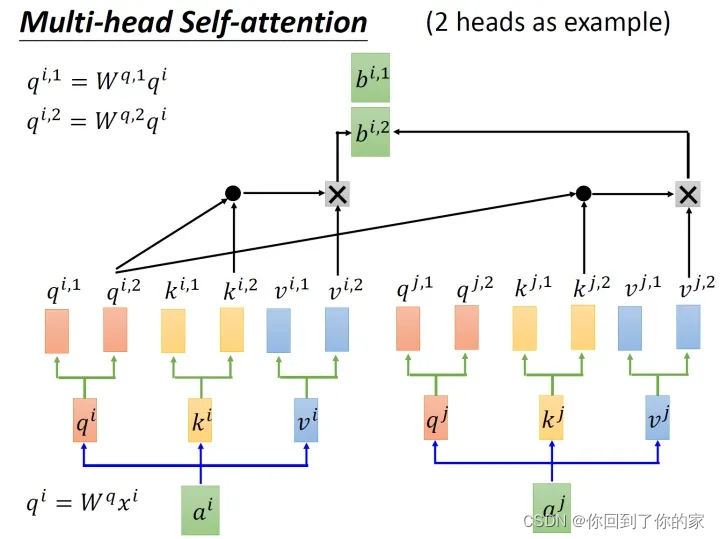
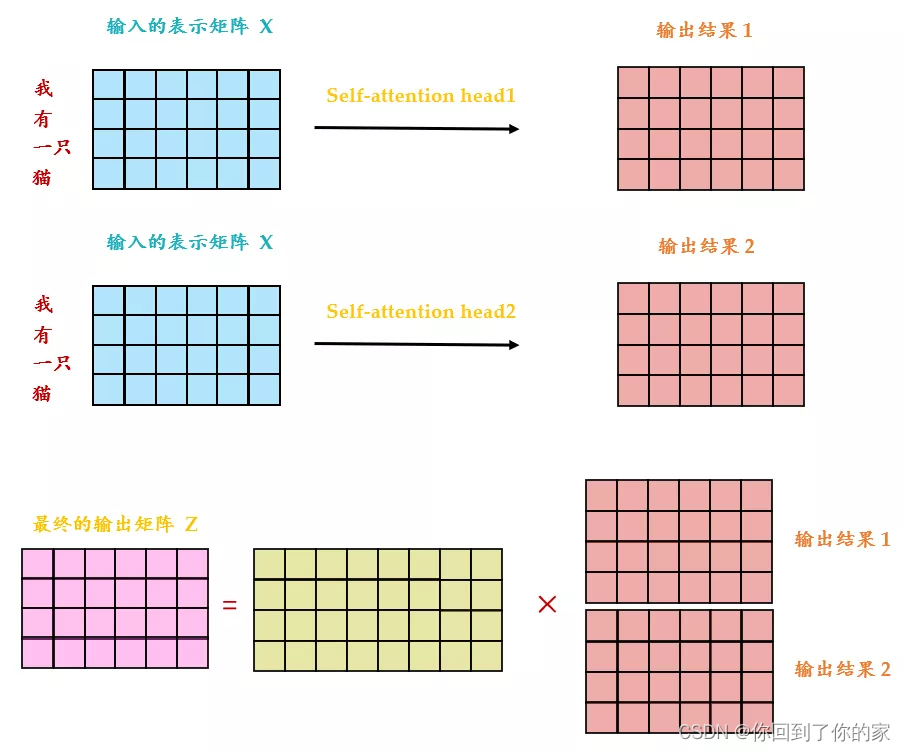
从下图中我们可以看出Multi-Head Attention包含多个Self-Attention层,首先我们将输入XXX分别传递到两个不同的Self-Attention中,计算得到两个输出矩阵,然后将这两个矩阵拼接起来传入一个线性层中,得到Multi-Head Attention的最终输出ZZZ。Multi-Head Attention输出的矩阵ZZZ与其输入的矩阵XXX的维度是一样的:
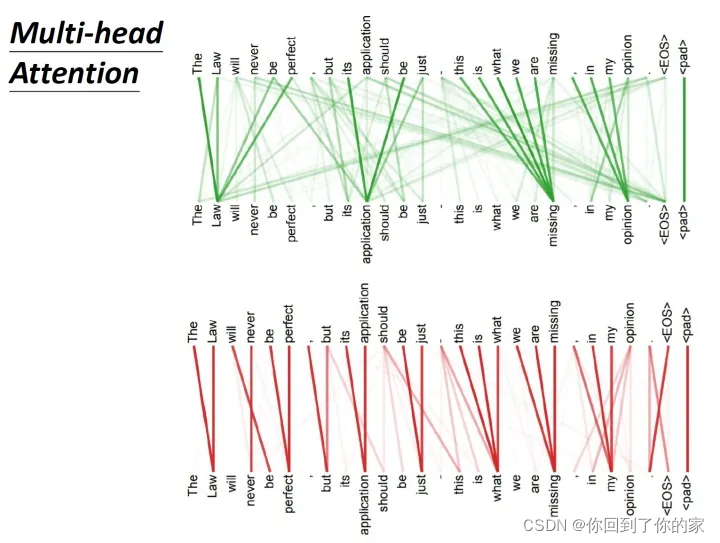
下图展示了一组Multi-Head Attention的结果,其中绿色部分是一组query和key,红色部分是另外一组query和key,我们可以发现绿色部分其实更关注global信息,而红色部分更关注local信息:
我们没有仅仅使用dmodeld_{\text{model}}dmodel维的keys、values以及queries的attention function,而是使用学习到的不同线性映射将queries、keys以及values分别映射 hhh 次到 dk,dkd_k, d_kdk,dk 以及 dvd_vdv 维。对于每个映射后的queries、keys以及values我们并行计算attention function,这会生成 dvd_vdv 维的输出值。然后我们将这些值拼接起来再进行映射,生成最终值,如图2所示。
Multi-head attention允许模型共同关注来自不同位置的不同representation subspaces的信息。当使用单个attention head时,averaging inhibits this。
MultiHead(Q,K,V)=Concat(head1,...,headh)WO\text{MultiHead}(Q,K,V)=\text{Concat}(\text{head}_1,...,\text{head}_h)W^OMultiHead(Q,K,V)=Concat(head1,...,headh)WO
whereheadi=Attention(QWiQ,KWiK,VWiV)\text{where}\quad \text{head}_i=\text{Attention}(QW_i^Q,KW_i^K,VW_i^V)whereheadi=Attention(QWiQ,KWiK,VWiV)
这里映射都为参数矩阵,WiQ∈Rdmodel×dk,WiK∈Rdmodel×dk,WiV∈Rdmodel×dv,WO∈Rhdv×dmodelW_i^Q\in\mathbb{R}^{d_{model}\times d_k},W_i^K\in\mathbb{R}^{d_{model}\times d_k},W_i^V\in\mathbb{R}^{d_{model}\times d_v}, W^O\in\mathbb{R}^{hd_v\times d_{model}}WiQ∈Rdmodel×dk,WiK∈Rdmodel×dk,WiV∈Rdmodel×dv,WO∈Rhdv×dmodel
在本文中,我们采用h=8h=8h=8个并行的attention layer或者head。对于每个head,我们使用dk=dv=dmodel/h=64d_k=d_v=d_{model}/h=64dk=dv=dmodel/h=64。由于每个head的维度都减小了,总计算花销和有全部维度的single-head attention相似。
3.2.3 模型中Attention机制的应用
Transformer中通过三种不同的方式使用了multi-head attention机制:
- 在“encoder-decoder attention”层,queries来自于之前的decoder层,memory keys和values来自于encoder的输出层。这允许decoder中的每个位置都参与输入序列中的所有位置。这模仿了sequence-to-sequence模型中经典的encoder-decoder attention机制。
- encoder包含self-attention层。在一个self-attention层中所有的keys、values以及queries都来自同一个地方,在我们的例子中,这就是encoder之前层的输出。encoder中的每个位置可以参与到encoder先前层的所有位置。
- 类似地,decoder中的self-attention层允许decoder中的每个位置参与到decoder前以及当前层的全部位置。我们需要防止decoder中的leftward information flow来组织auto-regressive。We implement this inside of scaled dot-product attention by masking out (setting to −∞-\infty−∞) all values in the input of the softmax which correspond to illegal connections. 如图2所示。
3.3 Position-wise Feed-Forward Networks
除了attention子层之外,编码器和解码器中的每一层都包含一个全连接前馈网络,该网络分别相同地应用于每个位置。这包括两个线性变换,中间有一个ReLU激活。
FFN(x)=max(0,xW1+b1)W2+b2\text{FFN}(x)=\max(0,xW_1+b_1)W_2+b_2FFN(x)=max(0,xW1+b1)W2+b2
这里线性变化的结构在不同的位置是相同的,但是每层使用不同的参数。另外一种描述这个的方式是核大小为1的两个卷积层。输入核输出的维度都是dmodel=512d_{model}=512dmodel=512,内层的维度为dff=2048d_{ff}=2048dff=2048。
3.4 Embedding 以及 Softmax
与其他序列转换模型类似,我们使用学习到的embeddings将输入tokens和输出tokens转换为维度为dmodeld_{model}dmodel的向量。我们还使用学习到的线性变换和softmax函数将decoder输出转换为预测的下一个token概率。在我们的模型中,我们在两个embedding层和pre-softmax线性变换之间共享相同的权重矩阵,类似于[30]。在embedding层中,我们将这些权重乘以dmodel\sqrt{d_{model}}dmodel。
3.5 Positional Encoding
self-attention有一个问题,那就是不包含位置信息,一个距离较近的单词和距离较远的单词向量效果完全一样。作者为了解决这个问题所作的操作如下图所示:
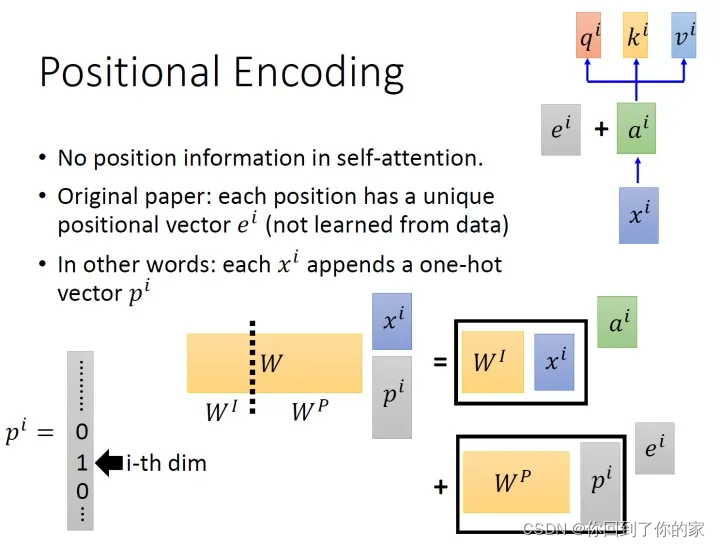
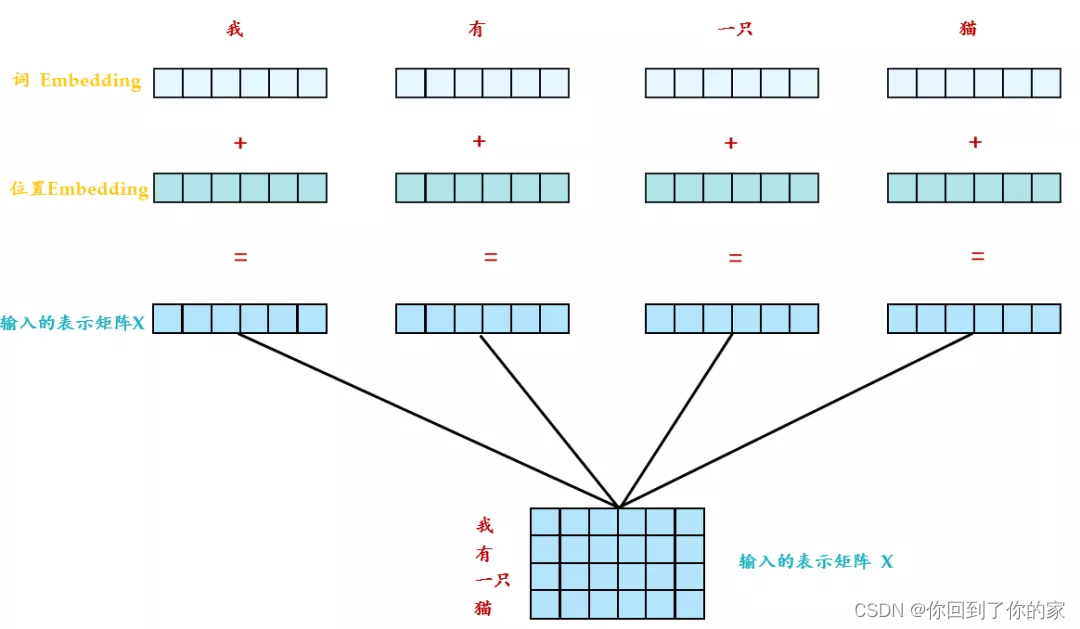
具体的做法是:给每一个位置规定一个表示位置信息的向量eie_iei,让它与aia_iai加在一起之后作为新的aia_iai参与后面的运算过程,但是注意这个eie_iei是人工设定的,不是神经网络学习出来的,因此每一个位置都有一个不同的eie_iei。
到这里有一个问题,为什么是eie_iei与aia_iai相加,而不是拼接?加起来之后,原来表示位置的信息就混杂到aia_iai里面去了,现在不是很难被找到了吗?
这里提供一种解答这个问题的思路:
如上图所示,我们先给每个位置的xi∈R(d,1)x_i\in R(d,1)xi∈R(d,1)append一个one-hot编码的向量pi∈R(N,1)p_i\in R(N,1)pi∈R(N,1),得到一个新的输入向量xpi∈R(d+N,1)x_p^i\in R(d+N,1)xpi∈R(d+N,1),这个向量作为新的输入,乘上一个转化矩阵W=[WI,WP]∈R(d,d+N)W=[W_I,W_P]\in R(d,d+N)W=[WI,WP]∈R(d,d+N),那么:
W⋅xpi=[WI,WP]⋅[xipi]=WI⋅xi+WP⋅pi=ai+eiW\cdot x_p^i=[W_I,W_P]\cdot\begin{bmatrix}x_i\\p_i\end{bmatrix}=W_I\cdot x_i+W_P\cdot p_i=a_i+e_iW⋅xpi=[WI,WP]⋅[xipi]=WI⋅xi+WP⋅pi=ai+ei
所以eie_iei与aia_iai相加就等于把原来的输入xix_ixiconcat一个表示位置的one-hot编码pip_ipi,再进行转化。
这个与位置编码相乘的矩阵WPW_PWP是人工设计的,如下图所示:
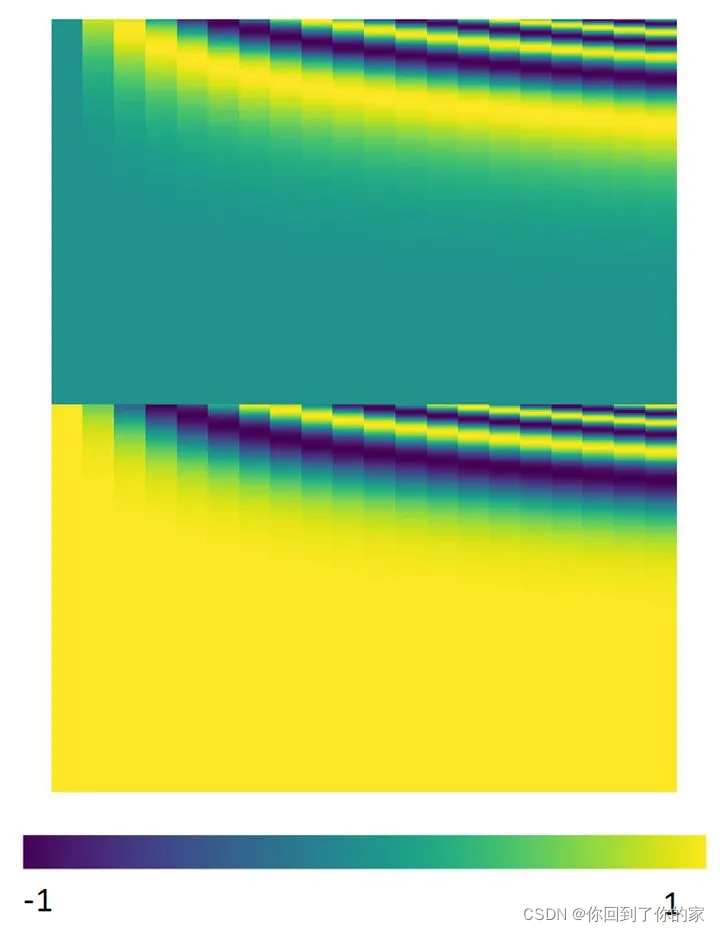
positional encodings用PE表示,它的维度与单词Embeddings相同,PE可以通过训练得到,也可以采用某种公式直接计算得到,在transformer中采用了不同频率的sine以及cosine方程,计算方式如下:
PE(pos,2i)=sin(pos/100002i/dmodel)PE(pos,2i)=sin(pos/10000^{2i/d_{model}})PE(pos,2i)=sin(pos/100002i/dmodel)
PE(pos,2i+1)=cos(pos/100002i/dmodel)PE(pos,2i+1)=cos(pos/10000^{2i/d_{model}})PE(pos,2i+1)=cos(pos/100002i/dmodel)
式中,pospospos表示token在序列中的位置,例如第一个token“我”的pos=0
i,或者准确意义上是2i2i2i和2i+12i+12i+1表示了PE的维度,i的取值范围是[0,..,dmodel/2)[0,..,d_{model}/2)[0,..,dmodel/2)。所以当pos为1时,对应的PE可以写成:
PE(1)=[sin(1/100000/512),cos(1/100000/512),sin(1/100002/512),cos(1/100002/512),...]PE(1)=[sin(1/10000^{0/512}),cos(1/10000^{0/512}),sin(1/10000^{2/512}),cos(1/10000^{2/512}),...]PE(1)=[sin(1/100000/512),cos(1/100000/512),sin(1/100002/512),cos(1/100002/512),...]
式中,dmodel=512d_{model}=512dmodel=512,底数是10000,为什么要使用10000呢,这个就类似于玄学了,原论文中完全没有提啊,这里不得不说说论文的readability的问题,即便是很多高引的文章,最基本的内容都讨论不清楚,所以才出现像上面提问里的讨论,说实话这些论文还远远没有做到easy to follow。这里我给出一个假想:100001/51210000^{1/512}100001/512是一个比较接近1的数(1.018),如果用100000,则是1.023。这里只是猜想一下,其实大家应该完全可以使用另一个底数。
使用上面的式子的好处是:
- 每个位置有一个唯一的PE
- 使得PE能够适应逼训练集里面所有句子更长的句子,假设训练集里面最长的句子有20个单词,突然来了一个长度为21的句子,则使用公式计算的方法可以计算出第21位的embedding。
- 可以让模型容易地计算出相对位置,对于固定长度的间距k,任意位置的PEpos+kPE_{pos+k}PEpos+k都可以被PEposPE_{pos}PEpos的线性函数表示,因为三角函数特性:
cos(α+β)=cos(α)cos(β)−sin(α)sin(β)cos(\alpha+\beta)=cos(\alpha)cos(\beta)-sin(\alpha)sin(\beta)cos(α+β)=cos(α)cos(β)−sin(α)sin(β)
sin(α+β)=sin(α)cos(β)+cos(α)sin(β)sin(\alpha+\beta)=sin(\alpha)cos(\beta)+cos(\alpha)sin(\beta)sin(α+β)=sin(α)cos(β)+cos(α)sin(β)
我们同样测试了使用学习到的positional embeddings[9],发现这两种方案会产生基本相同的结果(见表3 行E)。
4 为什么使用Self-Attention
In this section we compare various aspects of self-attention layers to the recurrent and convolutional layers commonly used for mapping one variable-length sequence of symbol representations
(x1, …, xn) to another sequence of equal length (z1, …, zn), with xi
, zi ∈ R
d
, such as a hidden
layer in a typical sequence transduction encoder or decoder. Motivating our use of self-attention we
consider three desiderata.
One is the total computational complexity per layer. Another is the amount of computation that can
be parallelized, as measured by the minimum number of sequential operations required.
The third is the path length between long-range dependencies in the network. Learning long-range
dependencies is a key challenge in many sequence transduction tasks. One key factor affecting the
ability to learn such dependencies is the length of the paths forward and backward signals have to
traverse in the network. The shorter these paths between any combination of positions in the input
and output sequences, the easier it is to learn long-range dependencies [12]. Hence we also compare
the maximum path length between any two input and output positions in networks composed of the
different layer types.
如表1所示,一个self-attention层在常数级的sequentially executed操作下连接了所有的位置,相比而言recurrent层需要O(n)O(n)O(n)的sequential operations。从计算复杂度的角度看来,当序列长度n小于representation dimensionality d时,self-attention层要比recurrent层快,这是绝大多数情况下会发生的(with sentence representations used by state-of-the-art models in machine translations, such as word-piece [38] and byte-pair [31] representations. )为了提升一些包括非常长序列任务的计算性能,self-attention可以被限定为仅考虑以输出位置为中心的输入序列的某个邻域r。This would increase the maximum path length to O(n/r). We plan to investigate this approach further in future work。
A single convolutional layer with kernel width k < n does not connect all pairs of input and output
positions. Doing so requires a stack of O(n/k) convolutional layers in the case of contiguous kernels,
or O(logk(n)) in the case of dilated convolutions [18], increasing the length of the longest paths
between any two positions in the network. Convolutional layers are generally more expensive than
recurrent layers, by a factor of k. Separable convolutions [6], however, decrease the complexity
considerably, to O(k · n · d + n · d
2
). Even with k = n, however, the complexity of a separable
convolution is equal to the combination of a self-attention layer and a point-wise feed-forward layer,
the approach we take in our model.
As side benefit, self-attention could yield more interpretable models. We inspect attention distributions
from our models and present and discuss examples in the appendix. Not only do individual attention
heads clearly learn to perform different tasks, many appear to exhibit behavior related to the syntactic
and semantic structure of the sentences.


















 3594
3594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









