






 本文探讨了在Keras中使用TensorFlow的分布式训练策略,包括数据并行和模型并行两种方式。通过创建MirroredStrategy,可以实现数据并行训练,将一个batch的数据分配到多个GPU上独立计算,然后同步模型参数。在每个epoch结束时,不是选择最低损失的参数,而是合并所有设备的参数以保持同步。这种方式有助于加速训练,但可能因多组初始参数导致训练不充分。分布式训练并不直接解决局部最优问题,而是通过增加总体计算资源来提高训练效率。
本文探讨了在Keras中使用TensorFlow的分布式训练策略,包括数据并行和模型并行两种方式。通过创建MirroredStrategy,可以实现数据并行训练,将一个batch的数据分配到多个GPU上独立计算,然后同步模型参数。在每个epoch结束时,不是选择最低损失的参数,而是合并所有设备的参数以保持同步。这种方式有助于加速训练,但可能因多组初始参数导致训练不充分。分布式训练并不直接解决局部最优问题,而是通过增加总体计算资源来提高训练效率。
单机多卡,多机多卡的使用方式
官方教程 :https://keras.io/guides/distributed_training/#singlehost-multidevice-synchronous-training
教程主要内容
- 分布式计算有两种,一种是数据并行,一种是模型并行
- 数据并行只需要修改少量代码
- 模型比较简单的话,并行数据即可
- 数据并行原理和实现
这里讨论数据并行实现原理
- 一个batch_size的数据分配到多个设备上面
- 每个设备独立计算,直到分配的数据计算完毕
- 合并各个设备上的模型参数,同步之后进行下一个epoch
- 用mirrored variable object 实现变量的同步,因此要把模型创建和编译的部分放在该类变量的作用域中
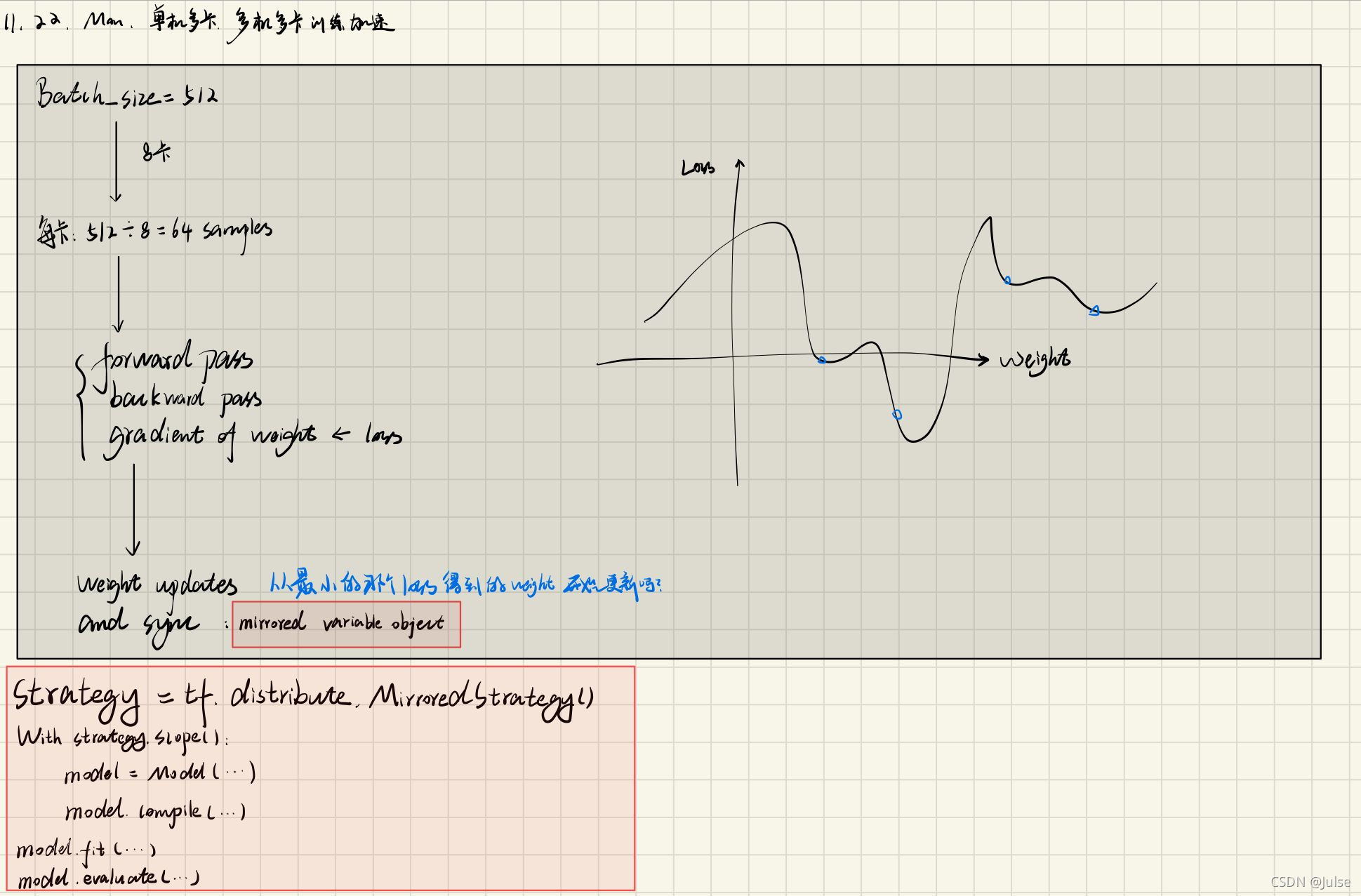
import tensorflow as tf
from tensorflow import keras
# Create a MirroredStrategy.
strategy = tf.distribute.MirroredStrategy()
print('Number of devices: {}'.format(strategy.num_replicas_in_sync))
# Open a strategy scope.
with strategy.scope():
# Everything that creates variables should be under the strategy scope.
# In general this is only model construction & `compile()`.
model = Model(...)
model.compile(...)
# Train the model on all available devices.
model.fit(train_dataset, validation_data=val_dataset, ...)
# Test the model on all available devices.
model.evaluate(test_dataset)
疑问
在局部数据训练完成之后进行的参数合并,是从得到的多个结果中,选择使loss变小的参数作为所有设备上的模型参数,再进入下一次epoch吗?
即是说,不同数据子集,相当于不同的数据分布,模型的初始参数位置不一样,得到的最低点(loss)不一样,选择使loss最小的参数作为这一个batch训练之后模型的参数
有点像mini_batch https://blog.youkuaiyun.com/qq_38343151/article/details/102886304
- 局部最优:如果是这样的话,是不是顺便解决了模型陷入局部最优的问题。
- 训练不充分:因为有多个初始化可能导致训练不充分?

















 1144
1144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









