




ICMR 25

文章背景
- 视觉模态与文本模态联合防御
- 文章贡献
- 证明了现有的单模态防御方法在抵抗多模态攻击的时候表现很差
- 提出了多模态联合防御框架JAP,通过双向视觉-文本交互协同消除跨模态扰动,突破了孤立模态防御策略的局限性
- 大量的实验表明JAP能够有效的消除多模态对抗攻击的威胁。
方法
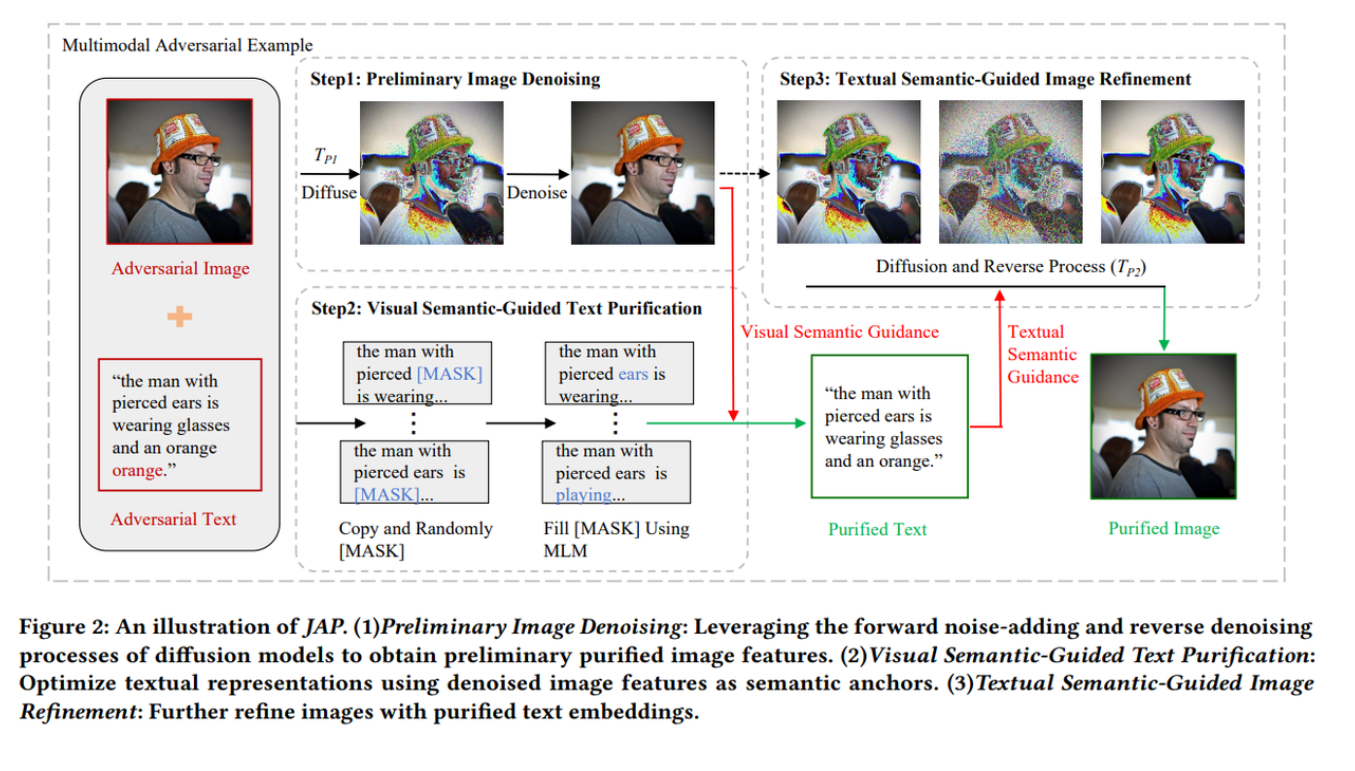
Step1 基于Diffusion做图片净化

Step2 视觉语义引导文本净化

- 将对抗文本l′l'l′复制kkk份:χ={l1′,l2′,...,lk′}\chi=\{l_{1}',l_{2}',...,l_{k}'\}χ={l1′,l2′,...,lk′}
- 对每个副本li′l_{i}'li′,随机用[MASK]掩盖一个token,得到一个新的集合χmask\chi_{mask}χmask
- 预测集合χmask\chi_{mask}χmask的每个副本的[MASK],并用预测词替换[MASK],得到集合χfill\chi_{fill}χfill
- 从集合χfill\chi_{fill}χfill中选取与净化后的图片语义相似度最高的文本
lpur=argminljL(Ev(v0),El(lj)),l^{p u r}=\underset{l_{j}}{\arg \min } \mathcal{L}\left(E_{v}\left(v_{0}\right), E_{l}\left(l_{j}\right)\right),lpur=ljargminL(Ev(v0),El(lj)),
Step3 文本语义引导图像优化
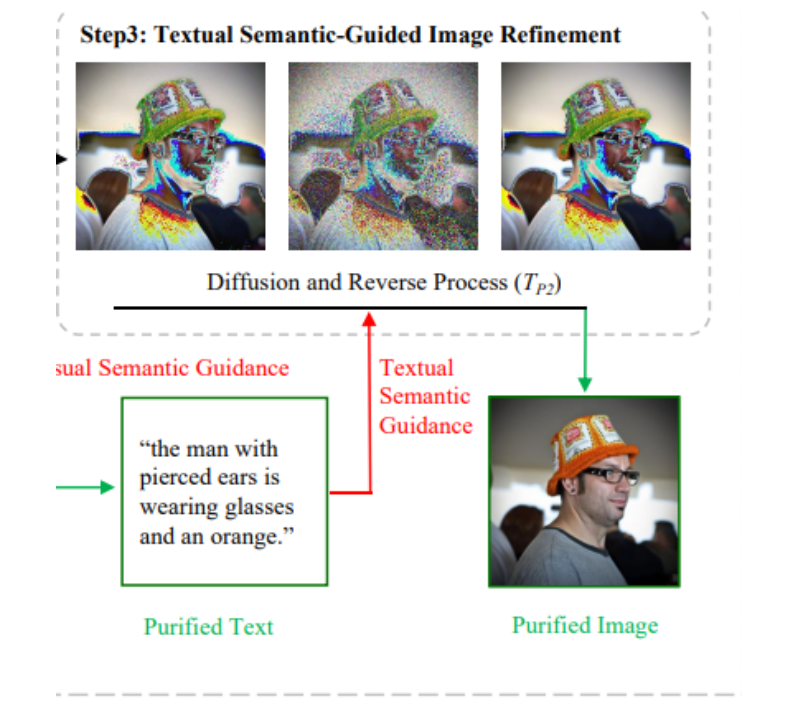
扩散模型反推图像时,用文本语义给结果“拉一把”。
- 基础:扩散模型的反推过程
- 在扩散模型里,反推公式是:
- pθ(xt−1∣xt)=N(μθ(xt,t),σθ2I)pθ(x_{t−1}∣x_t)=\mathcal{N}(μ_θ(x_t,t),σ_θ^2I)pθ(xt−1∣xt)=N(μθ(xt,t),σθ2I)
- 也就是说,模型从带噪声的图像xtx_txt 预测一个更干净的图像 xt−1x_{t-1}xt−1,高斯分布由均值μθ\mu_{\theta}μθ 和方差σθ2\sigma_{\theta}^2σθ2决定。
- 加入文本语义引导
- 现在我们有文本描述 yyy(比如 “一只戴帽子的猫”)。
- 我们希望生成的图像不仅是“合理的图像”,还要和文本语义一致。
- 数学上,把条件分布改成:pθ,ϕ(xt−1∣xt,y)∝pθ(xt−1∣xt)⋅pϕ(y∣xt−1)p_{\theta,\phi}(x_{t-1}\mid x_t,y)\propto p_\theta(x_{t-1}\mid x_t)\cdot p_\phi(y\mid x_{t-1})pθ,ϕ(xt−1∣xt,y)∝pθ(xt−1∣xt)⋅pϕ(y∣xt−1)
- 第二项pϕ(y∣xt−1)p_\phi(y \mid x_{t-1})pϕ(y∣xt−1)就是“这个图像符合文本 y 的概率”。
- 高斯近似 + 梯度引导
- 论文证明这个分布仍可以近似成一个高斯:
- N(μθ+Σg,Σ)\mathcal{N}(\mu_\theta + \Sigma g, \Sigma)N(μθ+Σg,Σ)
- 其中
- μθ\mu_\thetaμθ:原始反推的均值(没加文本时的结果)
- Σ\SigmaΣ:原始方差
- g=∇xt−1logpϕ(y∣xt−1)g = \nabla_{x_{t-1}} \log p_\phi(y\mid x_{t-1})g=∇xt−1logpϕ(y∣xt−1)图像对文本的梯度方向
👉 直观理解:生成时,扩散模型预测出一个图像候选xt−1x_{t-1}xt−1,然后再往“符合文本 y” 的方向拉一点。
- 如何计算文本语义引导
- 用 图文对齐模型(比如 CLIP):
- 输入图像 vtv_tvt,用图像编码器 Ev(⋅)E_v(\cdot)Ev(⋅)得到向量。
- 输入文本lpurl_{pur}lpur,用文本编码器 El(⋅)E_l(\cdot)El(⋅)得到向量。
- 两个向量算余弦相似度:
- F(vt,lpur,t)=Ev(vt)⋅El(lpur)F(v_t, l_{pur}, t) = E_v(v_t) \cdot E_l(l_{pur})F(vt,lpur,t)=Ev(vt)⋅El(lpur)
- 这就是“图像和文本匹配程度”。
实验
实验任务
- 视觉蕴含任务
- 图文检索任务
- 评估指标:
- 视觉蕴含任务:准确率,模型能否正确识别图像内容与对应文本描述之间逻辑关系的比例。
- 图文检索任务:Recall@K (R@K)
对比方法
| 防御方法 | 方法类型 |
|---|---|
| BERT-Defense | 文本防御方法 |
| BitSqueezing | 图像防御方法,丢弃最低有效位来压缩位深 |
| JPEGFilter | 图像防御方法,通过 JPEG 编码和解码操作实现图像对抗防御的方法。 |
| GaussianSmoothing2D (GS) | 空间平滑方法,使用高斯核对图像进行加权模糊处理 |
| MedianSmoothing2D (MS) | 通过将每个像素替换为其邻域内的中值来去除脉冲噪声 |
| DiffPure | 利用扩散模型来净化对抗图像 |
实验结果
与单模态防御方法的比较结果
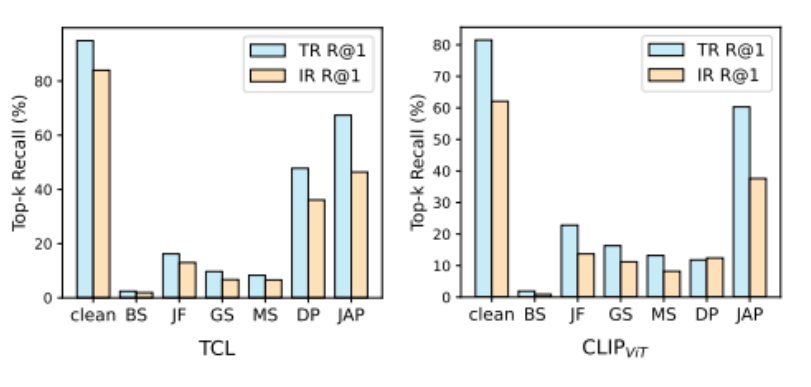
- 单模态防御方法的有效性有限,其中基于文本的防御无法为 VLP 模型提供有意义的保护。
- JAP 方法 在性能上优于所有单模态防御,体现了其在提升 VLP 模型协同防御能力方面的优势
针对白盒攻击的防御
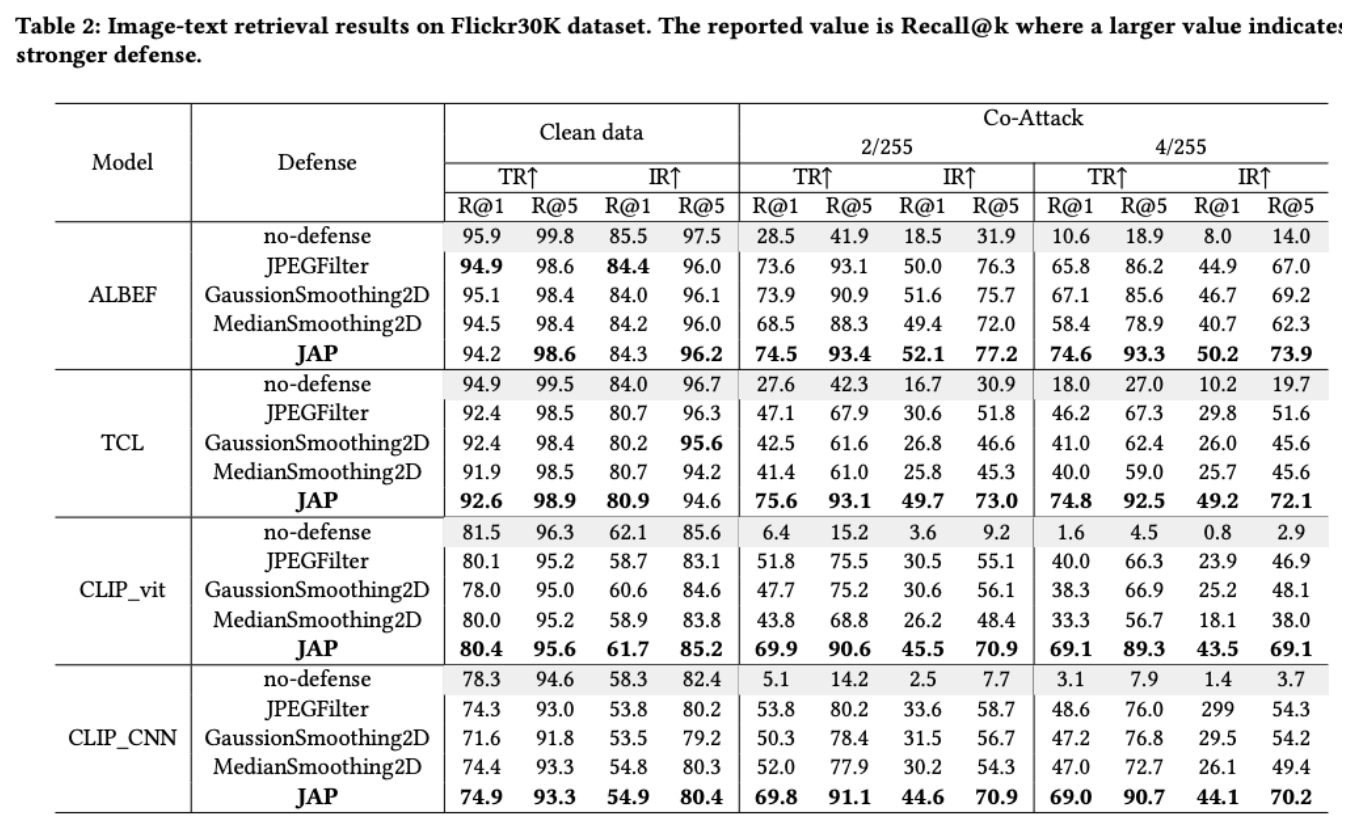
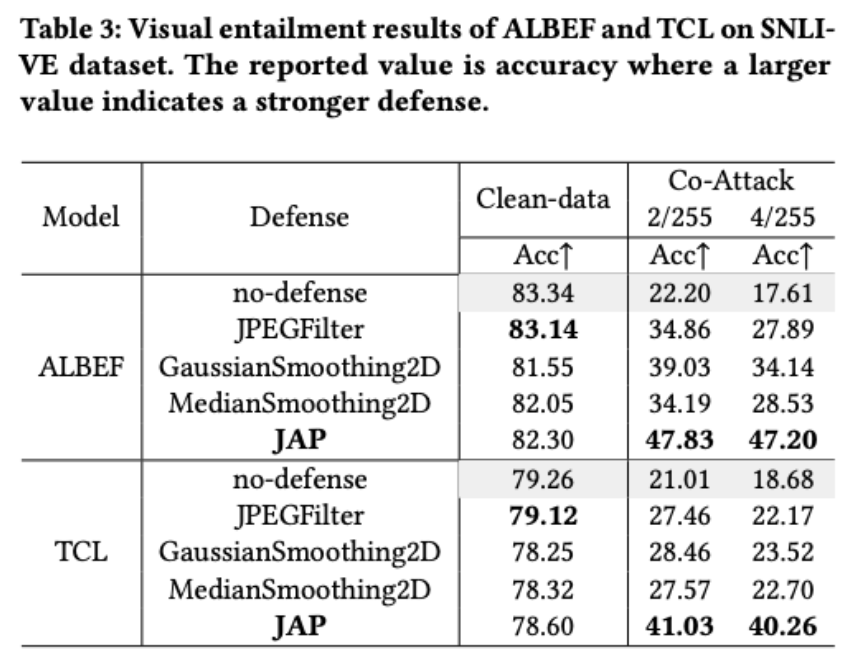
- JAP 方法 在多个数据集和模型架构下对抗 Co-Attack 的效果显著。
- 该方法在不同扰动强度下均能稳定提升性能,说明 JAP 在抵御不同幅度攻击时均有效。
- 尽管在干净数据上的性能有一定下降,但幅度很小,表明该防御不会显著削弱模型的实际效用。
JAP在迁移攻击下的防御效果
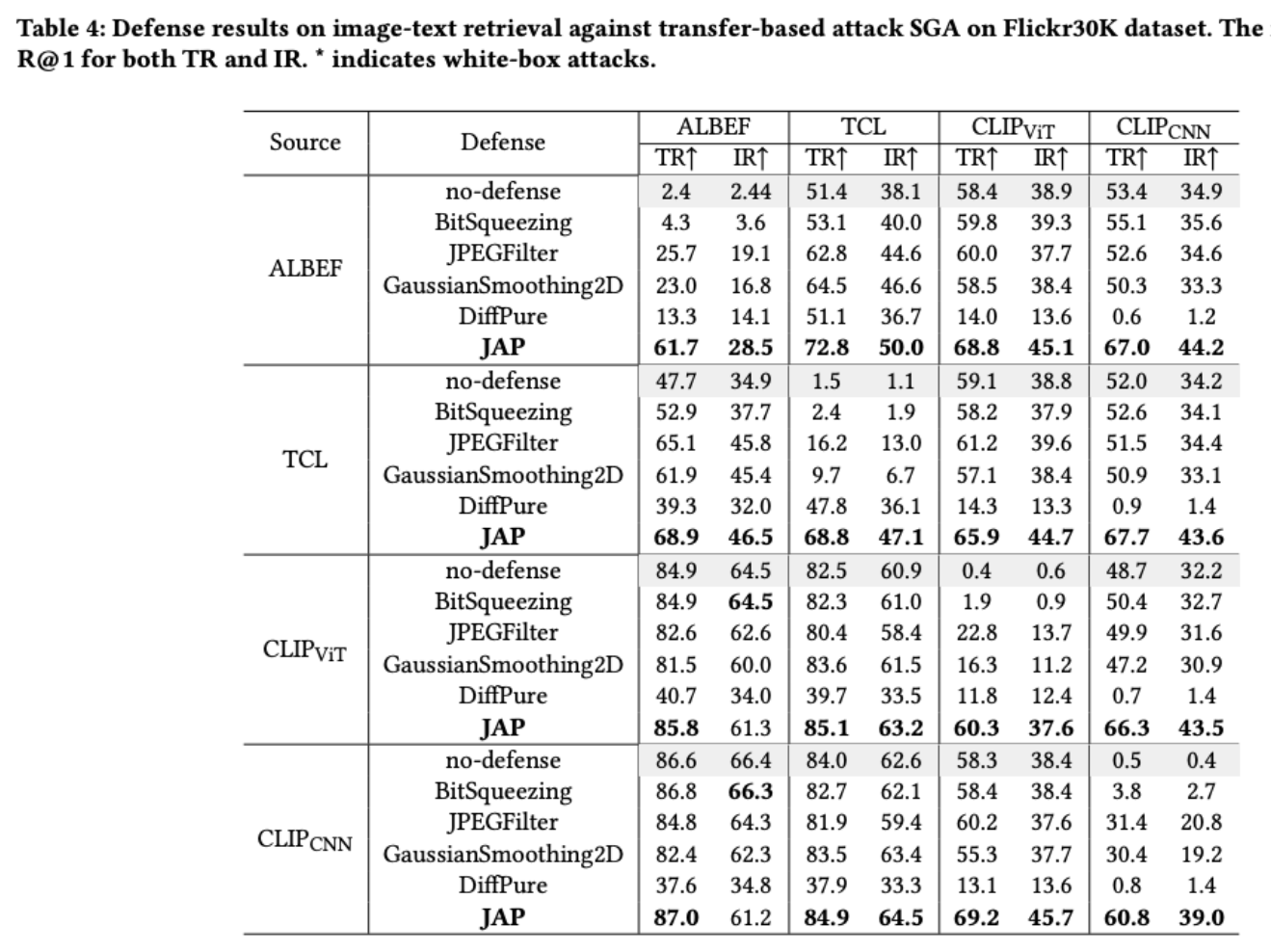
- 在 白盒攻击 下:
- SGA 攻击效果非常强,成功率高
- 但 JAP 能够有效缓解影响,防御性能显著
- 在 迁移攻击 下:
- JAP 防御仍然有效,但效果比白盒场景下稍差
- 原因:迁移攻击的扰动更具有跨模型的泛化性


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









