



基于视觉引导的点云补全
摘要
本文提出了一种用于点云补全任务的基于视觉引导的解决方案。不同于大多数现有方法所使用的直接利用形状推断缺失点,本研究通过引入ViPC(view-guided point cloud completion,视觉引导点云补全)来完成此任务,该方法从额外的单视图图像中获取缺失的关键全局结构信息。借助一个依次执行有效跨模态和跨层级融合的框架,我们的方法在为视图引导点云补全任务所收集的新大规模数据集上,取得了显著优于典型现有解决方案的结果。
关键词:点云补全,视觉引导
1 引言
由于点云于不同领域(如自动驾驶、机器人学、地理学、表型组学和考古学)内拥有广泛的应用前景,对于它的研究热情目前空前高涨。在实际应用中,深度扫描设备直接获取的点云数据质量会受到物体间遮挡、设备扫描精度低等诸多因素的影响,从而导致扫描得到的点云质量较差,具体表现为点云不完整、点稀疏、点云中存在噪声等情况。
现有的研究方法,主要包括点云的补全、去噪和超分辨率(上采样),已经提出了点云增强的任务。早期方法通过主要使用形状先验信息或根据几何对称关系手绘来生成增强点云。近年来,基于数据驱动生成增强点云的方法为解决此问题贡献颇大,尤其是像PointNet和DGCNN这样的深度学习技术。与传统的方法相比,这些深度学习的方法在处理不规则结构和几何外形的对象方面表现出了显著的优势。
本篇论文聚焦于以下条件的点补全任务:输入点云虽然是不完整的,但是其中的噪声有限,而使用本文提出的的方法将输出一个完整的点云。研究这个问题解决了一个在现实世界进行3D数据采集时常见的问题,即:使用RGB相机的3D扫描仪被环境中的其他物体遮挡时会产生数据缺失。当前最新的解决方法是利用一个编码器-解码器的架构进行基于数据驱动的点云补全。这种方法的原理可以解释为,一个编码器将不完整的输入点云传输到特征空间,然后通过一个解码器将特征传递回欧几里得空间来重新构造一个完整的点云。这整个网络可以看作一个参数模型,这个参数模型用于推测两个潜在空间,即不完整点云和完整的点云之间的映射。在输入点云存在较大程度不完整的情况下,由于以下因素,仅使用单模态点云数据学习这种映射是具有挑战性的:第一,由于输入的点云不完整,其能够提供的信息量有限,因此在推断缺失点时存在很大的不确定性,第二,点云是一种非结构化数据,而且由于其所固有的稀疏性,很难判断点云中空白的3D空间是由于其固有的稀疏性还是因为点云确实不完整。

图 1 .ViPC是一种点云补全的新方法,它主要通过利用额外的单视角图像的补充信息来进行点云补充。
本文旨在探索一种更具应用性的解决方法以完成点云补全的任务。具体来说,本方法借助图像模态来处理该任务,并由此提出了一个基于视图引导的点补全框架ViPC,如图1所示。随着硬件成本的降低,这种传感器融合的设置越来越普遍,如英特尔Real Sense D55和微软Kinect设备。解决这一问题的关键挑战是如何有效地融合由部分点云提供的姿态和局部细节信息以及由单视图图像提供的全局结构信息。这并非易事,因为它涉及二维挑战:“跨模态”(信息来自图像和点云模态)和“跨层次”(局部细节和全局结构是来自不同层次的信息)。我们通过一个三阶段框架来解决这一问题,首先解决跨模态挑战,然后解决跨层次挑战。具体来说,跨模态挑战通过从单视图图像重建一个粗略点云并将所有补全所需的信息转移到相同的点云域中来解决。跨层次挑战通过一种由网络(称为“动态偏移预测器”)驱动的微分细化策略来解决,该网络可以对粗略点云中的点进行微分细化:对低质量点进行轻度细化,而对高质量点进行重度细化。为了更好地研究这一问题,我们在现有的ShapeNet数据集上构建了一个大规模数据集,称为ShapeNet-ViPC。我们的数据集包含来自13 个类别的38328个对象。每个对象有24组真值数据,包括在两种典型的数据采集场景下生成的两个不完整点云、一个视图对齐的图像和一个完整的真值点云。在ShapeNet-ViPC上的广泛评估表明,本文提出的方法较之现有的最先进方法能够取得显著更优的结果。总结来说,本文提出方法的主要贡献有三点:
1. 提出了一种新的点云补全解决方案,其中额外的单视图图像明确地为补全提供了关键的全局结构先验信息。
2. 设计了一个新的通用深度网络,用于点云的微分细化。
3. 构建了一个大规模的点云补全任务数据集,该数据集模拟了由各种遮挡引起的点云缺陷。它可以作为未来点云补全研究的基准。
2.相关工作
现有的点云补全方法可以大致分为三类:基于几何的方法、基于对齐的方法和基于学习的方法。
基于几何的方法。基于几何的方法通过先验几何假设直接从已观测的形状部分预测不可见的形状部分。具体来说,一些方法通过生成平滑插值来局部填充表面孔洞,例如拉普拉斯平滑和泊松曲面重建。其他方法通过检测模型结构中的规律性,并基于识别出的对称轴重复这些规律性来预测缺失数据。这些方法直接从已观测区域推断缺失数据,并取得了很好的结果。然而,它们需要为特定类型的模型预定义手工设计的几何规律,并且仅适用于具有较小程度不完整的模型。
基于对齐的方法。基于对齐的方法通过检索形状数据库中与目标对象相似的模型,然后将输入与模板模型对齐并完成缺失区域。一些方法直接检索三维形状,例如整个模型或部分模型。其他方法使用经过变形的合成模型或非三维几何原语(如平面和二次曲面)代替数据库中的三维形状。这些方法适用于多种不同类型的模型,并且可以应用于不同程度的不完整性,但它们在推理优化和数据库构建方面需要较高的成本,且对噪声敏感。
基于学习的方法。基于学习的方法通过构建参数化模型来学习不完整点云和完整点云特征空间之间的映射。其中大多数是基于编码器-解码器的神经网络。在形状表示方面,大多数现有模型使用体素来表示形状,因为它们直观且便于进行三维卷积运算。为了在完成的点云中保留更多的几何信息(即局部几何细节),一些模型直接在点集上进行操作。由于点或体素都是单模态输入,因此很难在具有较大不完整的输入点云和完整点云之间推断出准确的映射。因此,这些方法可能仅在特定类别的对象或具有较小不完整的形状上表现良好。目前,利用辅助数据补充输入点云缺失信息以增强点云的研究还很少。
3. 方法
3.1. 概述
问题定义。本文提出的视图引导的补全解决方案基于一个假设:输入图像包含缺失形状部分的必要结构信息。我们的目标是恢复一个三维形状![]() ,它由两部分组成,即
,它由两部分组成,即![]() ,其中
,其中![]() 是接近输入部分形状
是接近输入部分形状![]() 的形状部分(即
的形状部分(即![]() 与
与![]() 之间的差异有限),而
之间的差异有限),而![]() 是未知的缺失形状部分。形式上,我们用
是未知的缺失形状部分。形式上,我们用![]() 表示形状
表示形状![]() 在模态
在模态![]() 中的表示,即
中的表示,即![]() 表示点云,
表示点云,![]() 表示图像。任务的输入可以表示为:
表示图像。任务的输入可以表示为:
-
部分点云
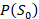 。
。 -
单视图图像
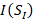 ,其中
,其中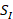 表示从图像视角观测到的形状。
表示从图像视角观测到的形状。
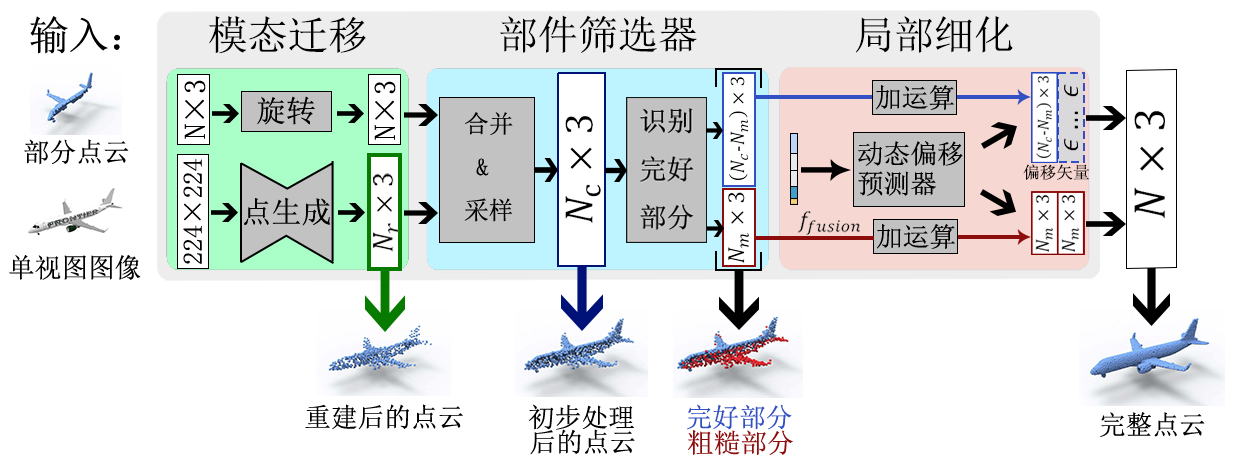
图 2. 本文提出的ViPC的体系结构;详见正文的“流程”部分。
流程。本文提出的三阶段框架如图2所示。第一阶段用于解决跨模态融合问题,将图像![]() 映射到点云
映射到点云![]() 中的粗略表示。第二阶段生成粗略点云,第三阶段对其进行增强以生成高质量的完整点云。这两个阶段共同完成跨层次融合。具体来说,第一阶段称为模态转换,将
中的粗略表示。第二阶段生成粗略点云,第三阶段对其进行增强以生成高质量的完整点云。这两个阶段共同完成跨层次融合。具体来说,第一阶段称为模态转换,将![]() 映射到点云
映射到点云![]() 中的粗略表示,然后在三维空间中将重建的点云与输入部分形状
中的粗略表示,然后在三维空间中将重建的点云与输入部分形状![]() 对齐。第二阶段称为部件过滤,从对齐后的点云中生成粗略点云。此外,这一阶段还会区分主要来自输入部分点云的点和其他主要从输入图像
对齐。第二阶段称为部件过滤,从对齐后的点云中生成粗略点云。此外,这一阶段还会区分主要来自输入部分点云的点和其他主要从输入图像![]() 重建的点。我们将前者称为精细部分,后者称为粗糙部分。一般来说,精细部分的形状质量远高于粗糙部分,只需要轻度细化。最后,第三阶段称为部件细化,它以粗糙部分和精细部分为输入,生成高质量的完整点云。在这一阶段,主要细化粗糙部分的形状,同时将精细部分作为细化的约束条件,从而获得比全局细化(无约束地细化所有点)更好的结果,这一点在实验部分的消融研究中得到了验证。本研究通过一个名为“动态偏移预测器”的新神经网络实现这一目标。接下来,将详细介绍上述三个阶段。
重建的点。我们将前者称为精细部分,后者称为粗糙部分。一般来说,精细部分的形状质量远高于粗糙部分,只需要轻度细化。最后,第三阶段称为部件细化,它以粗糙部分和精细部分为输入,生成高质量的完整点云。在这一阶段,主要细化粗糙部分的形状,同时将精细部分作为细化的约束条件,从而获得比全局细化(无约束地细化所有点)更好的结果,这一点在实验部分的消融研究中得到了验证。本研究通过一个名为“动态偏移预测器”的新神经网络实现这一目标。接下来,将详细介绍上述三个阶段。
3.2. 模态转换
从图像![]() 中直接重建出保留丰富局部细节的高质量点云具有一定的挑战性。因此,转换后的点云有望作为初始化形状,主要用于结构引导。设从图像
中直接重建出保留丰富局部细节的高质量点云具有一定的挑战性。因此,转换后的点云有望作为初始化形状,主要用于结构引导。设从图像![]() 重建的点云为
重建的点云为![]() 。本文采用一个轻量级的点云重建网络,其编码器-解码器架构如图 3 所示。编码器将输入图像映射为隐空间向量,解码器输出一个
。本文采用一个轻量级的点云重建网络,其编码器-解码器架构如图 3 所示。编码器将输入图像映射为隐空间向量,解码器输出一个![]() 的矩阵,它的每一行表示一个点的笛卡尔坐标。在本文的实现中,编码器包含一系列带有ReLU激活的卷积层,并输出
的矩阵,它的每一行表示一个点的笛卡尔坐标。在本文的实现中,编码器包含一系列带有ReLU激活的卷积层,并输出![]() 的特征图作为潜在空间向量。解码器应用一系列反卷积层,并将输出进行拉平,生成
的特征图作为潜在空间向量。解码器应用一系列反卷积层,并将输出进行拉平,生成![]() 个点坐标。编码器每一层的特征图也被保存下来,作为该阶段后续过程的额外指导。从单视图图像重建
个点坐标。编码器每一层的特征图也被保存下来,作为该阶段后续过程的额外指导。从单视图图像重建![]() 后,将其与输入的部分点云对齐。
后,将其与输入的部分点云对齐。

图 3. 模态迁移中单视角图像点云生成的网络结构。
3.3. 部件过滤
重建的![]() 可以粗略地描述从视图观测到的形状
可以粗略地描述从视图观测到的形状![]() ,这被认为包含了缺失形状部分
,这被认为包含了缺失形状部分![]() 的主要信息。在这一阶段,我们首先合并
的主要信息。在这一阶段,我们首先合并![]() 和
和![]() ,并从中提取一个子集(
,并从中提取一个子集(![]() 个点),作为形状
个点),作为形状![]() 的粗略表示。由于
的粗略表示。由于![]() 和重建的
和重建的![]() 的点密度可能不同,直接合并会导致在
的点密度可能不同,直接合并会导致在![]() 和
和![]() 的重叠空间中出现冗余点。我们希望这个包含
的重叠空间中出现冗余点。我们希望这个包含![]() 个点的粗略点云能够均匀密集,并尽可能多地保留形状的全局结构和局部细节。具体来说,团队对
个点的粗略点云能够均匀密集,并尽可能多地保留形状的全局结构和局部细节。具体来说,团队对![]() 使用远点采样(FPS)[22]来实现这一目标。
使用远点采样(FPS)[22]来实现这一目标。
之后,将距离输入部分点云![]() 较近的点识别为不需要重度细化的精细部分,并将剩余的点作为粗糙部分,即将包含
较近的点识别为不需要重度细化的精细部分,并将剩余的点作为粗糙部分,即将包含![]() 个点的粗略点云划分为粗糙部分(
个点的粗略点云划分为粗糙部分(![]() 个点)和精细部分(
个点)和精细部分(![]() 个点)。为了找到
个点)。为了找到![]() 个接近
个接近![]() 中点的点作为精细部分,通过计算
中点的点作为精细部分,通过计算![]() 和
和![]() 之间的点对点的倒角距离[11]来构建它们之间的对应关系。对于
之间的点对点的倒角距离[11]来构建它们之间的对应关系。对于![]() 中的每个点
中的每个点![]() ,计算其到
,计算其到![]() 中最近点的距离,即
中最近点的距离,即![]() 。如果距离
。如果距离![]() 小于一个自适应阈值
小于一个自适应阈值![]() ,就将其选为精细部分的候选点。在实现中,将
,就将其选为精细部分的候选点。在实现中,将![]() 中的点随机划分为两个子集,并计算两个子集中所有点之间的最近距离
中的点随机划分为两个子集,并计算两个子集中所有点之间的最近距离![]() 。然后,将平均距离值作为点云密度的估计,并将其作为阈值
。然后,将平均距离值作为点云密度的估计,并将其作为阈值![]() 。
。
3.4. 部件细化
部件细化阶段进一步细化(上采样)由精细部分和粗糙部分组成的粗略点云,以生成完整的点云。为了实现有效的细化,除了粗略点云本身(由点坐标![]() 表示)外,细化还利用了来自模态转换和部件过滤阶段的四种其他类型的特征,如图4所示。这四种特征可以分为二维或三维引导,与粗略点云的点坐标
表示)外,细化还利用了来自模态转换和部件过滤阶段的四种其他类型的特征,如图4所示。这四种特征可以分为二维或三维引导,与粗略点云的点坐标![]() 一起,被拼接成一个全局特征向量,共享给粗略点云中的每个点。所提出的动态偏移预测器网络将重复
一起,被拼接成一个全局特征向量,共享给粗略点云中的每个点。所提出的动态偏移预测器网络将重复![]() 次的全局特征向量作为输入,并预测
次的全局特征向量作为输入,并预测![]() 输出点的坐标偏移值(
输出点的坐标偏移值(![]() 定义了上采样率)。
定义了上采样率)。
三维引导。在最近的基于学习的补全方法中,已经验证了基于现有形状和先验知识进行补全的可行性。例如,飞机的对称性可以帮助我们完成一侧缺失的机翼。因此,我们通过在部分点云![]() 和重建的
和重建的![]() 上应用常见的点云解码器来提取全局特征。
上应用常见的点云解码器来提取全局特征。
二维引导。单视图图像![]() 为粗糙部分的结构和几何细节的恢复提供了指导。在模态转换阶段,图像
为粗糙部分的结构和几何细节的恢复提供了指导。在模态转换阶段,图像![]() 的特征已经被提取为不同尺寸的特征图,例如
的特征已经被提取为不同尺寸的特征图,例如![]() 、
、![]() 、
、![]() 和
和![]() 。受Pixel2Mesh中感知特征池化的启发,对于粗略点云中的每个点,我们使用坐标和相机参数在图像特征图中搜索对应于每个点的特征。这些特征被堆叠为
。受Pixel2Mesh中感知特征池化的启发,对于粗略点云中的每个点,我们使用坐标和相机参数在图像特征图中搜索对应于每个点的特征。这些特征被堆叠为![]() ,作为一种引导特征。此外,为了增加局部点之间的变化并防止为不同点预测相同的偏移量,受研究[40](Yaoqing Yang, Chen Feng, Yiru Shen, and Dong Tian. Foldingnet: Point cloud auto-encoder via deep grid deformation)提出的FoldingNet的启发,生成一个二维网格并将其重塑为特征向量
,作为一种引导特征。此外,为了增加局部点之间的变化并防止为不同点预测相同的偏移量,受研究[40](Yaoqing Yang, Chen Feng, Yiru Shen, and Dong Tian. Foldingnet: Point cloud auto-encoder via deep grid deformation)提出的FoldingNet的启发,生成一个二维网格并将其重塑为特征向量![]() ,以引入轻微的扰动。
,以引入轻微的扰动。
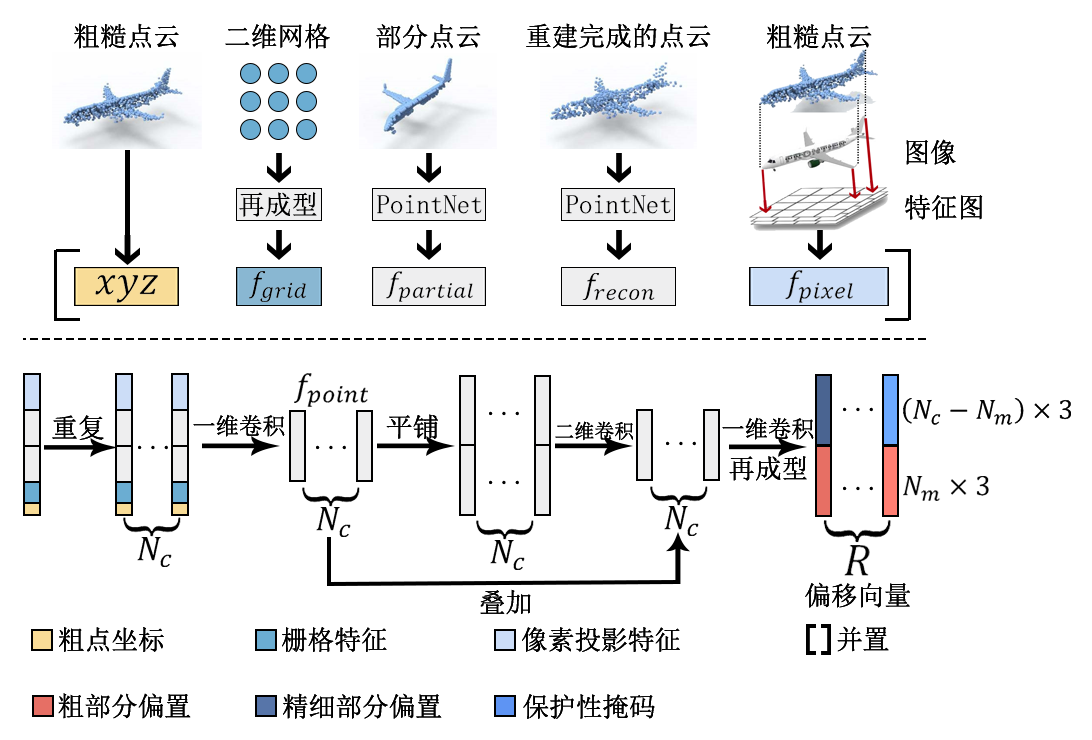
图 4. 将五种类型的特征(顶部行)拼接在一起,作为动态偏移预测器的输入,其架构如底部行所示。
动态偏移预测器。与以往基于折叠或树结构的方法不同,动态偏移预测器预测每个点相对于当前位置的空间偏移量,而不是直接预测坐标,这简化了回归过程。动态偏移预测器的数据流如图4所示:
1.将![]() 重复
重复![]() 次,并输入一系列一维卷积层以输出隐藏嵌入
次,并输入一系列一维卷积层以输出隐藏嵌入![]() 。
。
2.将![]() 铺瓷砖
铺瓷砖![]() 次,用于点的移动和上采样。
次,用于点的移动和上采样。
3.应用核大小为![]() 的二维卷积层,以感知每个点的
的二维卷积层,以感知每个点的![]() 个偏移量的局部信息。
个偏移量的局部信息。
4.通过一维卷积层预测![]() 的偏移向量。
的偏移向量。
5.生成一个![]() 的保护掩码,其偏移值为一个小值
的保护掩码,其偏移值为一个小值![]() ,用于覆盖偏移向量,限制精细部分点的移动。
,用于覆盖偏移向量,限制精细部分点的移动。
6.将![]() 的坐标堆叠
的坐标堆叠![]() 次(
次(![]() ),并加上相应的偏移量,作为完整的点云。
),并加上相应的偏移量,作为完整的点云。
因此,带有动态偏移预测器的部件细化在不改变精细部分细节的情况下,对![]() 进行细化和上采样。
进行细化和上采样。
3.5. 损失函数
损失函数用于衡量密集点云与真值之间的差异。由于点云是无序数据,损失函数必须是排列不变的。在本研究中,考虑了倒角距离(Chamfer Distance, CD)和推土距离(Earth Mover's Distance, EMD)。给定两个子集![]() 和
和![]() ,倒角距离计算
,倒角距离计算![]() 和
和![]() 之间最近点的平均距离。本文使用对称版本的CD,如公式所示,其中第一项迫使输出点云接近真值,第二项确保输出点云覆盖真值点云:
之间最近点的平均距离。本文使用对称版本的CD,如公式所示,其中第一项迫使输出点云接近真值,第二项确保输出点云覆盖真值点云:
![]()
推土距离是一种用于评估两个多维分布之间差异的算法。设ϕ:P→Q![]() 是两个点云之间的双射,它找到两个点集之间的最小平均距离。在实践中,搜索最优ϕ
是两个点云之间的双射,它找到两个点集之间的最小平均距离。在实践中,搜索最优ϕ![]() 在计算上是昂贵的,因此本文使用迭代的
在计算上是昂贵的,因此本文使用迭代的![]() 近似方案:
近似方案:
![]()
将这两种距离结合起来,形成损失函数![]() ,其中
,其中![]() 和
和![]() 是权衡超参数。团队在训练阶段默认使用
是权衡超参数。团队在训练阶段默认使用![]() 和
和![]() 。
。
4. 实验设置
4.1. ShapeNet-ViPC

图 5. 两种典型的点云采集场景示意图。上图:目标形状被环境中的其他物体以及其自身的一部分遮挡(自身遮挡);下图:除了自身遮挡和物体间遮挡外,采集到的点的位置还受到设备噪声的干扰。
为了模拟与视图引导点云补全任务相关的缺陷,并评估所提方法的性能,团队在现有的ShapeNet数据集上构建了一个新的数据集,称为ShapeNet-ViPC。它包含来自13个类别的38328个对象,这些类别包括飞机、长椅、橱柜、汽车、椅子、显示器、灯具、扬声器、枪械、沙发、桌子、手机和船舶。对于每个对象,我们在24个视角下生成两种类型的不完整点云(有噪声和无噪声),如图5所示。这24个视角遵循 ShapeNetRendering中相同的视角设置(该设置也用于3D-R2N2、PointSetGeneration和Pixel2Mesh)。对于每组数据,我们在目标形状的网格表面上均匀采样2048个点,作为对应视角设置下的真值完整点云。具体来说,每个三维形状被归一化到半径为1 的包围球内,并旋转到对应视角的姿态。对于图像数据,使用ShapeNetRendering中相同的24个渲染视角。ShapeNet-ViPC数据集包含![]() 组训练数据,每组数据包含一个真值完整点云、两个不完整的(部分)点云和一个图像视图。在本文中,我们使用8个类别的31650个对象(759600组数据)进行所有实验,其中80%用于训练,20%用于测试。
组训练数据,每组数据包含一个真值完整点云、两个不完整的(部分)点云和一个图像视图。在本文中,我们使用8个类别的31650个对象(759600组数据)进行所有实验,其中80%用于训练,20%用于测试。
4.2. 实现细节和评估指标
在实现中,输入图像的尺寸为![]() ,从该图像中重建包含784个点的点云。部分输入包含2048个点。通过远点采样(FPS)从输入部分点云和重建点云的组合(即
,从该图像中重建包含784个点的点云。部分输入包含2048个点。通过远点采样(FPS)从输入部分点云和重建点云的组合(即![]() )采样1024个点作为粗略点云。输出完整点云包含2048个点(即上采样率
)采样1024个点作为粗略点云。输出完整点云包含2048个点(即上采样率![]() )。模态转换阶段的网络使用64的批量大小和
)。模态转换阶段的网络使用64的批量大小和![]() 的学习率预训练100个周期。部件细化网络使用1的批量大小和
的学习率预训练100个周期。部件细化网络使用1的批量大小和![]() 的学习率训练200个周期。为每个对象类别训练类别特定的参数。为了量化补全性能,我们使用倒角距离(CD)和F-Score作为定量评估指标。较低的CD值和/或较高的F-Score对应于更好的补全质量。
的学习率训练200个周期。为每个对象类别训练类别特定的参数。为了量化补全性能,我们使用倒角距离(CD)和F-Score作为定量评估指标。较低的CD值和/或较高的F-Score对应于更好的补全质量。
5. 实验结果与分析
5.1. 对比实验
我们将在点云补全任务上将我们的方法与几种最先进的方法进行对比,包括 AtlasNet、FoldingNet、点云补全网络(PCN)和TopNet。AtlasNet通过估计一组参数化表面元素来恢复完整的点云。FoldingNet是一种基于2D网格的自编码器,是点云补全的先驱方法。PCN是一种基于编码器-解码器框架的方法,通过典型的粗到细的方案完成部分输入点云。TopNet通过树形结构网络完成不完美的点云。上述所有基线方法仅以部分点云作为输入。
定量结果。对比较方法生成的输出点云进行归一化处理,并在每个形状的2048个点上计算倒角距离和F-Score。表1和表2汇总了每个类别以及平均值的结果。结果表明,本文的方法在所有八个类别上均显著优于其他方法。此外,本文方法在飞机、船舶、灯具和汽车类别上具有更大的优势。
表 1. 使用倒角距离在ShapeNet-ViPC上的定量结果(2048个点)。最佳结果以粗体突出显示。
|
方法 |
每点平均倒角距离 | ||||||||
|
平均 |
飞机 |
橱柜 |
汽车 |
椅子 |
台灯 |
沙发 |
桌子 |
船舶 | |
|
AtlasNet |
6.062 |
5.032 |
6.414 |
4.868 |
8.161 |
7.182 |
6.023 |
6.561 |
4.261 |
|
FoldingNet |
6.271 |
5.242 |
6.958 |
5.307 |
8.823 |
6.504 |
6.368 |
7.080 |
3.882 |
|
PCN |
5.619 |
4.246 |
6.409 |
4.840 |
7.441 |
6.331 |
5.668 |
6.508 |
3.510 |
|
TopNet |
4.976 |
3.710 |
5.629 |
4.530 |
6.391 |
5.547 |
5.281 |
5.381 |
3.350 |
|
本文方法 |
3.308 |
1.760 |
4.558 |
3.138 |
2.476 |
2.867 |
4.481 |
4.990 |
2.197 |
表 2. 使用F-Score在ShapeNet-ViPC上的定量结果(2048个点)。最佳结果以粗体突出显示。
|
方法 |
F-Score@0.001 | ||||||||
|
平均 |
飞机 |
橱柜 |
汽车 |
椅子 |
台灯 |
沙发 |
桌子 |
船舶 | |
|
AtlasNet |
0.410 |
0.509 |
0.304 |
0.379 |
0.326 |
0.426 |
0.318 |
0.469 |
0.551 |
|
FoldingNet |
0.331 |
0.432 |
0.237 |
0.300 |
0.204 |
0.360 |
0.249 |
0.351 |
0.518 |
|
PCN |
0.407 |
0.578 |
0.270 |
0.331 |
0.323 |
0.456 |
0.293 |
0.431 |
0.577 |
|
TopNet |
0.467 |
0.593 |
0.358 |
0.405 |
0.388 |
0.491 |
0.361 |
0.528 |
0.615 |
|
本文方法 |
0.591 |
0.803 |
0.451 |
0.5118 |
0.529 |
0.706 |
0.434 |
0.594 |
0.730 |
定性结果。我们还对比较方法的结果进行了可视化,以进行更全面的评估。图6展示了来自八个类别的代表性示例的结果。可以很容易地观察到,FoldingNet生成的点云较为杂乱,某些形状部分缺乏清晰的结构,例如飞机的机翼、椅子的腿和桌子的腿。与 FoldingNet相比,PCN和AtlasNet在整体上有所改进,但局部小尺度结构细节仍然缺失(例如飞机的燃油箱、椅子的扶手)。基于结构树的TopNet方法在视觉上比PCN和AtlasNet更好,这可以从飞机、灯具、沙发和水上交通工具的结果中看出,这些结果展示了更清晰的部件结构和更整齐的点分布。然而,输入部分点云中的一些部件细节在完成的点云中没有被保留,例如飞机的燃油箱和桌子的支架被移动到了其他部位。本文的方法不存在这个问题,并且在所有八个类别上都比基准方法表现出更好的视觉效果。这是因为与比较方法(推断所有点的位置)不同,本文的方法将形状其他部分的点(即精细部分)用作补全约束,并推断形状一部分的局部点分布(即粗糙部分)。这使得网络能够保留输入部分点云的局部细节,为缺失结构生成更合理的补全(例如重建的桌子左支架),并且收敛速度更快。
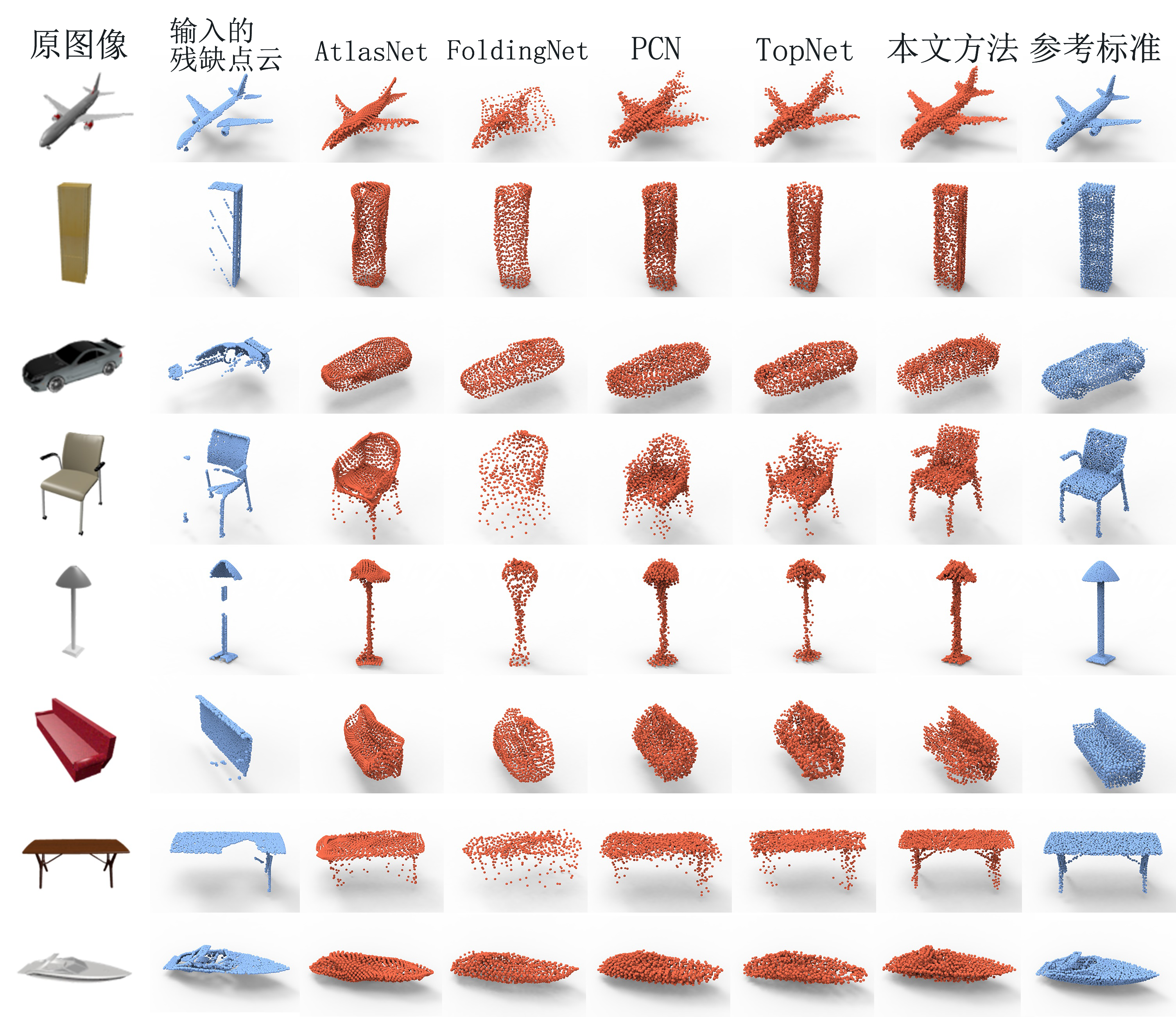
图 6. 在ShapeNet-ViPC上的定性对比。我们的方法显著优于其他基线方法。部分点云、补全点云和真实点云的分辨率均为2048。
5.2. 实验分析
消融研究。进行了消融实验,以研究每个阶段的单独贡献。如表3所示,我们定量比较了模态转换阶段生成的重建点云![]() 、部件过滤阶段生成的粗略点云
、部件过滤阶段生成的粗略点云![]() 和部件细化阶段生成的完成点云
和部件细化阶段生成的完成点云![]() 的点云质量。此外,还研究了区分精细部分和粗糙部分的微分细化策略的贡献。具体来说,团队修改了动态偏移预测器网络,禁用了精细部分的点应在小球内移动的约束,即精细部分和粗糙部分的点被无差别处理。我们将这种架构生成的结果称为
的点云质量。此外,还研究了区分精细部分和粗糙部分的微分细化策略的贡献。具体来说,团队修改了动态偏移预测器网络,禁用了精细部分的点应在小球内移动的约束,即精细部分和粗糙部分的点被无差别处理。我们将这种架构生成的结果称为![]() 。通过比较
。通过比较![]() 和
和![]() ,可以获得微分细化策略的定量作用。
,可以获得微分细化策略的定量作用。
表 3. 消融研究的定量结果,指明了平均倒角距离(单位:![]() )。
)。
|
类别 |
每点平均倒角距离 | |||
|
|
|
|
| |
|
飞机 |
4.479 |
2.360 |
1.993 |
1.760 |
|
橱柜 |
7.381 |
5.531 |
4.807 |
4.558 |
|
汽车 |
4.975 |
3.921 |
3.308 |
3.138 |
|
椅子 |
12.198 |
6.967 |
6.098 |
2.476 |
|
灯 |
4.573 |
3.549 |
3.186 |
2.867 |
|
沙发 |
7.809 |
5.340 |
4.681 |
4.481 |
|
桌子 |
10.967 |
6.719 |
5.891 |
4.990 |
|
船舶 |
5.626 |
3.156 |
2.669 |
2.197 |
|
平均 |
7.241 |
4.693 |
4.079 |
3.308 |
单视图图像的作用。在这组实验中,团队研究了哪种输入视图能更好地改进补全。我们从ShapeNet-ViPC的测试集中随机选取了![]() 个部分点云(每个类别
个部分点云(每个类别![]() 个部分点云)进行评估。对于每个部分点云,我们生成了
个部分点云)进行评估。对于每个部分点云,我们生成了![]() 个完整的点云,每个点云都是以
个完整的点云,每个点云都是以![]() 个渲染视图中的一个图像作为参考生成的。我们用CD指标量化这
个渲染视图中的一个图像作为参考生成的。我们用CD指标量化这![]() 个完成点云的补全质量,并在图7中展示了一些代表性结果。结果表明,不同的图像视图可以提供不同程度的改进。能够为部分点云缺失部分提供更多信息的图像视图会产生更好的结果。
个完成点云的补全质量,并在图7中展示了一些代表性结果。结果表明,不同的图像视图可以提供不同程度的改进。能够为部分点云缺失部分提供更多信息的图像视图会产生更好的结果。

图 7. 单视图图像给输入的残缺点云提供了更多有用的信息,使补全结果呈现更佳效果。输入的残缺点云位于左侧;补全效果的好坏用平均倒角距离(单位为![]() )来衡量,各图倒角距离在图片下方标注。
)来衡量,各图倒角距离在图片下方标注。
与单视图重建方法的对比。在这组实验中,团队研究了所提出的ViPC是否优于基于单视图重建的最先进方法 PSG。我们比较了三种不同的架构:PSG、模态转换阶段中的点生成网络(即表3中的![]() )和整个提出的框架(即表3中的
)和整个提出的框架(即表3中的![]() )。团队在ShapeNet-ViPC的测试集上计算了这三种比较架构生成的结果的平均CD值。我们将定量结果总结在表4中,并在图8中可视化了代表性结果。这些结果表明,整个提出的框架在性能上显著优于PSG。同时团队还发现,PSG生成的结果质量优于
)。团队在ShapeNet-ViPC的测试集上计算了这三种比较架构生成的结果的平均CD值。我们将定量结果总结在表4中,并在图8中可视化了代表性结果。这些结果表明,整个提出的框架在性能上显著优于PSG。同时团队还发现,PSG生成的结果质量优于![]() 。用更有效的网络(如PSG)替换模态转换中的当前网络可能是一个更好的解决方案。
。用更有效的网络(如PSG)替换模态转换中的当前网络可能是一个更好的解决方案。
表 4. 与PSG的定量比较。
|
研究方法 |
PSG |
|
|
|
CD( |
7.092 |
7.241 |
3.308 |

图 8. 与PSG的定性对比。输入视图展示于左侧; ![]() 右上角展示了所需要额外输入的局部点云数据。
右上角展示了所需要额外输入的局部点云数据。
特征消融研究。分别从![]() 中移除
中移除![]() 、
、![]() 、
、![]() 、
、![]() 和
和![]() ,以研究在部件细化阶段这些特征的贡献。完成性能的结果如表 5 所示。它们的作用可以按以下顺序排列:
,以研究在部件细化阶段这些特征的贡献。完成性能的结果如表 5 所示。它们的作用可以按以下顺序排列:![]() 。
。
表 5. 移除不同特征的定量结果及其与融合所有特征时的相对下降百分比。
|
移除 |
|
|
|
|
|
无 |
|
CD( |
3.348 |
3.325 |
3.324 |
3.321 |
3.316 |
3.308 |
|
下降百分比 |
1.22 |
0.52 |
0.49 |
0.39 |
0.24 |
- |
5.3. 局限性
点云配准。为了确保部件过滤和部件细化能够充分发挥作用,输入的部分点云和重建的点云必须准确对齐。由于在标定设备中获取相机参数并不困难,团队在模态转换阶段使用相机参数将输入的部分点云与重建的点云对齐。对于非标定设备,团队尝试了几种经典的无监督点云配准方法,如ICP和ICP-MCC。然而,由于重建点云的稀疏性和部分输入的不完整性,很难实现准确的对齐。用一种有效的基于学习的解决方案替换当前模态转换中的配准方法是未来值得进一步研究的方向。
真实场景中的补全。我们还在真实场景中评估了所提出的方法,其中我们使用手机拍摄单视图图像,并用iPad Pro上的激光雷达设备收集部分点云。由于我们在渲染图像上训练模型,而渲染的纹理无法反映真实环境中的光照,这导致模态转换阶段生成的点云质量较差,从而产生了较差的补全结果。在真实世界数据上进行训练可能会解决这一问题。
6. 结论
本文提出了一个开创性的传感器融合方法,称为ViPC,用于点云补全任务。ViPC通过利用额外的单视图图像提供缺失的全局结构信息来完成部分点云。ViPC的核心技术创新是一个名为“动态偏移预测器”的点云细化网络,它可以对粗略点云中的点进行差异性细化。我们将ViPC与现有的单模态方法进行了比较,这些方法仅基于点云模态或图像模态重建完整的点云。ViPC在我们为点云补全任务收集的新大规模数据集上表现出显著的质量提升。
感谢国家自然科学基金(U1701262, U1801263)和清华大学自主科研计划(No. 20197020003)对本工作的支持。

















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









