



 本文介绍了Spark任务在FI集群中的运行模式,包括local、yarn-client和yarn-cluster模式,并详细解释了每种模式下的任务架构,如Driver、ApplicationMaster和Executor的角色与职责。此外还探讨了不同模式的应用场景。
本文介绍了Spark任务在FI集群中的运行模式,包括local、yarn-client和yarn-cluster模式,并详细解释了每种模式下的任务架构,如Driver、ApplicationMaster和Executor的角色与职责。此外还探讨了不同模式的应用场景。
saprk任务运行的各种模式及流程
FI 集群中,支持的 Spark 的任务运行模式有 local,yarn-client,yarn-cluster 等,Spark 任务运行是分布式的,由任务的 Driver 驱动任务的运行,由 Executor 来执行具体的任务。大多情况下,Executor 中执行的代码逻辑需要由用户编写。也就是说 Executor 进程运行的命令由用户编写,相当于用户的执行逻辑与Spark自身的逻辑是耦合的,出现问题之后难以定位分界,此章主要介绍 Spark 任务架构,FI 集群中 Spark 各角色实例介绍及相关日志说明,Spark 任务出现问题后的定位手段,常见的 spark 任务异常问题及解决办法。
Spark- - On- -
一个 Spark 任务主要包含 Driver, ApplicationMaster,Executor 等部分,其中 Driver 负责驱
动任务的运行,把相关的函数封装为 Task 并分发到 Executor, ApplicationMaster 主要与 Yarn
交互负责申请资源启动 Executor,汇总 Executor 信息,Executor 主要负责执行具体的 task。
Yarn- -t client 模式
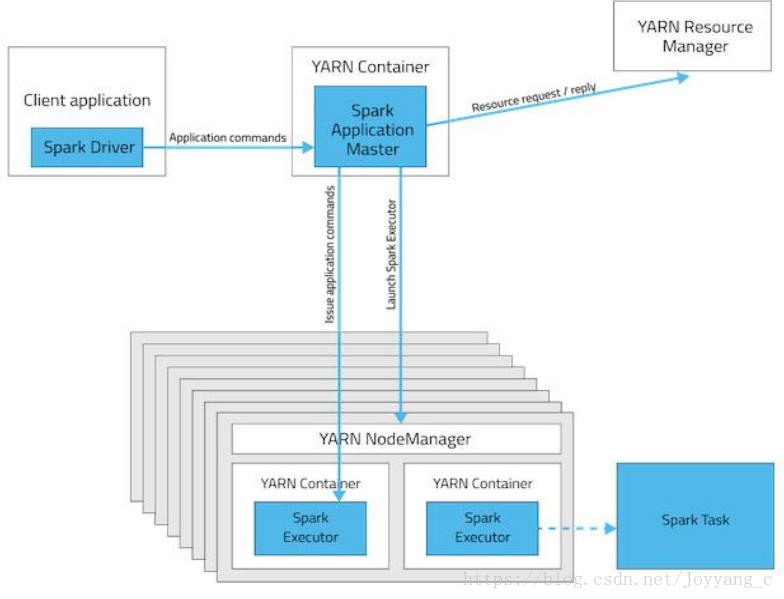
在 yarn-client 模式下,Spark 任务的 driver 作为一个进程运行在提交任务的节点(不是由 yarn 启动,不受 yarn 的管理)。ApplicationMaster 作为一个 container 进程启动在集群中
的某个节点上(具体在哪个节点上启动由 Yarn 决定)。ApplicationMaster 作为集群中与 Yarn 交
互的核心向 Yarn 申请资源以启动 Container(Executor),每个 Executor 都作为一个进程,启动
后等待 driver 发送 task 并执行 task。
Yarn-client 模式架构图:
Yarn- -r cluster 模式
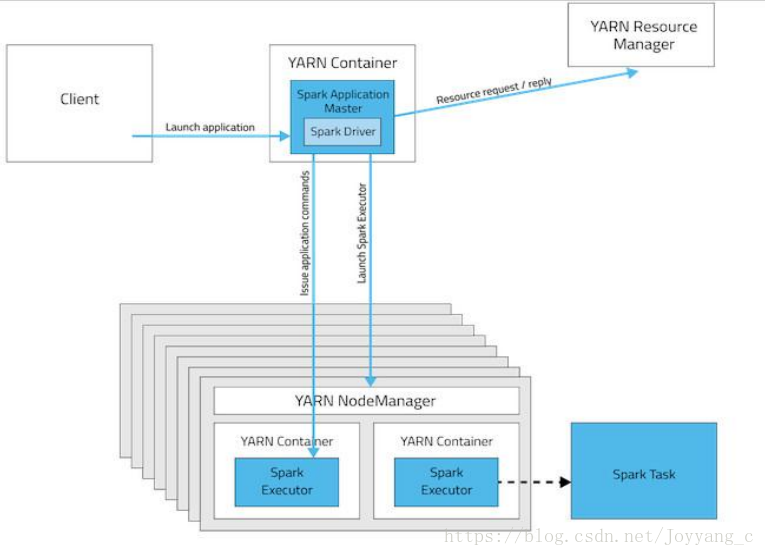
在 yarn-clsuter 模式下,Spark 任务的 driver 和 ApplicationMaster 运行在同一个 container进程中,同时受 yarn 的管理。ApplicationMaster 同样作为一个 container 进程运行在集群中的某个节点上(具体在哪个节点上启动由 Yarn决定),driver作为线程运行在 ApplicationMaster的 container 进程中。ApplicationMaster 作为集群中与 Yarn 交互的核心向 Yarn 申请资源以启动 Container(Executor),每个 Executor 都作为一个进程,启动后等待 driver 发送 task 并执行task。
spark 任务运行在 yarn 集群中,yarn-client 模式适用于开发测试,driver 直接运行在提交任务的节点,不受 yarn 的控制,便于在控制台观察任务运行状态,在 client 端的进程不能关掉。Yarn-cluster 模式下,任务的相关进程均运行在集群中,受 yarn 的管理,提交任务后,
客户端就可以关闭。

















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









