




 本文介绍了解决Python3.x在读取TXT文件时出现UnicodeDecodeError的方法。主要原因是文件编码与系统默认编码不匹配,文中详细介绍了如何检查和更改文件编码,以及针对不同Python版本提供的解决方案。
本文介绍了解决Python3.x在读取TXT文件时出现UnicodeDecodeError的方法。主要原因是文件编码与系统默认编码不匹配,文中详细介绍了如何检查和更改文件编码,以及针对不同Python版本提供的解决方案。
python3.x 在读取txt文件时出现错误:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xcd in position 0: invalid continuation byte
从网上找了一个代码编译时出现了错误,在网上找了好久终于看到了在一个论坛上找到了解决办法:
出现这种问题绝大部分情况是因为文件不是 UTF8 编码的(例如,可能是 GBK 编码的),而系统默认采用 UTF8 解码。解决方法是改为对应的解码方式。所以赶紧看看txt文件是什么编码的,这才发现时ANSI编码,这就需要把ANSI编码改成UTF-8编码,这样就没有问题了。
如何该记事本的编码格式如下:
-
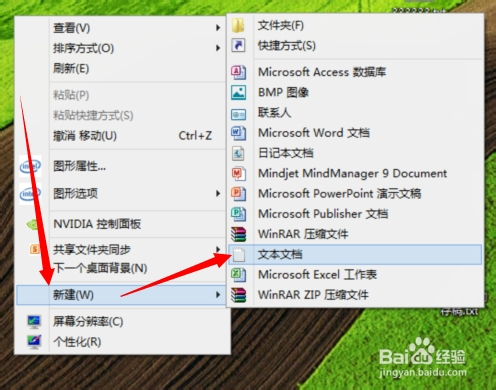
打开电脑,在桌面右键---》新建---》文本文档

-
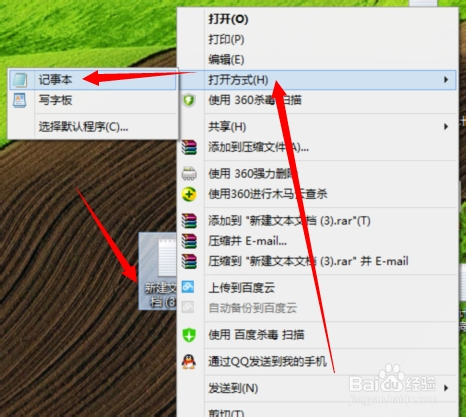
然后右键文件---》打开方式---》记事本
-
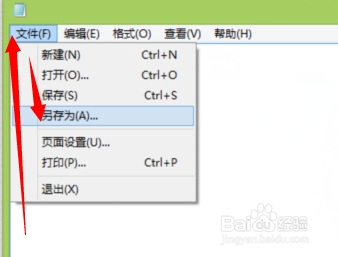
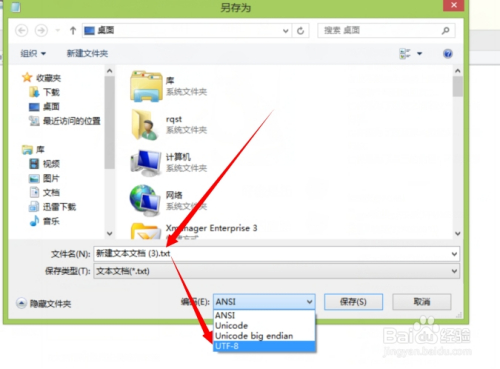
打开记事本之后,我们的目的主要是查看文件的编码格式系统默认的什么,选择头部菜单的“文件--》另存为”
-
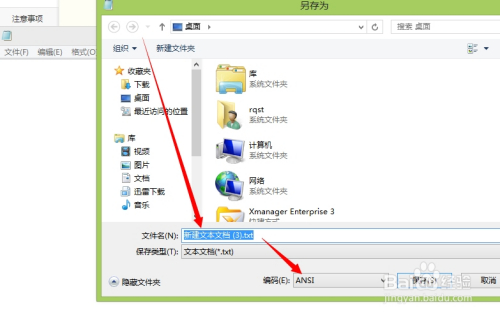
点击之后,有一个另存为的弹窗出现,如下图,我们可以看到默认编码格式为"ANSI"
-
如果要更改编码格式,那么就在编码下拉框中选择你需要的编码格式
(1).对于python2来说
reload(sys)
sys.setdefaultencoding("utf-8"),
但是python3已经变成了
import importlib
importlib.reload(sys)
(2).可以使用Notepad++来修改代码的编码格式


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









