




标题:
Identifying adolescents at risk for depression: Assessment of a global prediction model in the Great Smoky Mountains Study
识别有抑郁风险的青少年:对大烟山研究中全球预测模型的评估
Highlights:
-
Previously, a risk score for adolescent depression (IDEA-RS) was validated in five countries.此前,青少年抑郁症的风险评分(IDEA-RS)在五个国家进行了验证。
-
The IDEA-RS performed above chance in predicting depression in an external sample from the USA. 在来自美国的外部样本中,IDEA-RS预测抑郁症的几率高于chance。
-
Differences on predictive measures and on prevalence rates did not compromise performance. 预测指标和患病率的差异并没有影响表现。
-
Cross-informant prediction had similar performance to common-informant. 交叉信息预测与普通信息预测具有相似的性能。
-
This indicates that IDEA-RS is informative in distinct settings across the globe. 这表明IDEA-RS在全球不同的环境中提供了信息。
Abstract:
青少年早期抑郁风险识别评分(IDEA-RS)已经在四大洲的样本中进行了外部评估,但北美缺乏。我们这里的目的是评估在大烟山研究(GSMS)中,IDEA-RS对美国青少年群体样本中未来严重抑郁症(MDD)发作的预测性能。我们应用巴西开发的原始IDEA-RS模型的截距和权重,为GSMS的每个参与者生成一个15岁时的个人概率(N=1029)。然后,我们使用简单的、病例混合校正和改装的模型,评估了这些预测对19岁时MDD诊断的效果。此外,我们比较了优先考虑父母或青少年提供的信息对性能的影响。当使用未校正的权重时,IDEA-RS预测的C统计量为0.63 (95% CI 0.53-0.74)。病例混合修正模型和改装模型将性能分别提高到0.69和0.67。通过优先考虑青少年或其父母的报告,在性能上没有发现显著差异。IDEA-RS能以超过chance discrimination的性能在GSMS样本中分析出有晚发抑郁症风险的青少年。IDEARS目前在五个大洲都有above-chance的性能。
1. Introduction
青少年抑郁症患病率明显增加(Avenevoli等人,2015),这既是生命早期疾病负担的增加,也是预防的主要机会。因此,区分青少年未来发展为抑郁症的风险高低,可能是为公共卫生和临床决策提供信息的关键一步(Kieling等人,2019)。然而,尽管抑郁症和精神健康障碍的风险因素已经确定,但将多个变量聚合为一个个体水平风险估计的预测模型才刚刚开始出现在文献中(Salazar de Pablo等人,2021)。
为了实现这一目标,我们的小组开发了青少年早期抑郁风险识别评分(IDEA-RS),这是一个预测青少年重度抑郁障碍(MDD)发作的预后模型。该模型最初是使用巴西1993年Pelotas出生群体的数据设计的(Rocha等人,2021),这是一项在中上收入国家进行的具有代表性的前瞻性研究。该算法在临床或流行病学背景下易于收集,只需在简短的评估中收集青少年的信息,即可得出11个社会和人口预测变量。在C统计量上,IDEA-RS实现了0.76-0.79的判别性能,该结果可与医学中广泛使用的预测模型相媲美(china, 2011;Marques等人)。随后,该模型在英国、尼日利亚、新西兰和尼泊尔等一系列具有不同社会文化和经济背景的国家进行了评估,C统计量分别达到0.59、0.62、0.63和0.73 (Brathwaite等人,2020,2021;Rocha等人,2021)。因此,IDEA-RS在四个不同的大洲都取得了超出偶然的成绩,但仍需要对其在北美的表现进行评估。
从这个意义上说,大烟山研究(GSMS)为外部复制提供了一个独特的机会。这是一项具有社区代表性的纵向研究,从9岁起对参与者进行随访,旨在评估儿童时期精神疾病的患病率及其随时间的发展。因此,IDEA-RS中使用的大部分预测因子都是本研究收集的变量,如“童年虐待”、“打架斗殴”、“吸毒”、“社会孤立”、“性别”、“学业失败”、“离家出走”和“肤色”。此外,GSMS的一个明显特点是,敏感话题的信息来源是双重的——从父母和年轻人自己那里获取数据。先前的研究表明,青少年的自我评价信息和父母评价信息之间在估计的一致性方面存在差异(Lewis等人,2012;Piehler等人,2020),目前尚不清楚它们是否可以互换使用,以确定预测工具中是否存在风险因素。
为了弥补这些研究空白,目前的研究试图使用最初在巴西Pelotas 1993出生队列中建立的模型,确定美国大烟山研究(GSMS)中哪些15岁青少年在19岁时患抑郁症的风险较高。作为第二个目标,我们评估了来自青少年及其监护人的风险因素信息的一致性,以及使用一方或另一方报告的信息对模型性能的影响。
2. Method
2.1 Description of study setting and recruitment of study cohort 研究设置和研究群体的选择
我们使用的数据来自GSMS群体,这是一个基于人口的样本,从美国南部阿巴拉契亚山区的11个县招募了1420名儿童。该研究采用加速队列设计,包括3组9岁、11岁和13岁的儿童,在以前的工作中有更详细的描述(Costello等人,1996;Copeland et al, 2014)。杜克大学医学中心机构审查委员会批准了GSMS数据收集协议。家长和成年人签署知情同意书,未成年儿童签署知情同意书。调查是根据2013年版的《赫尔辛基宣言》进行的。
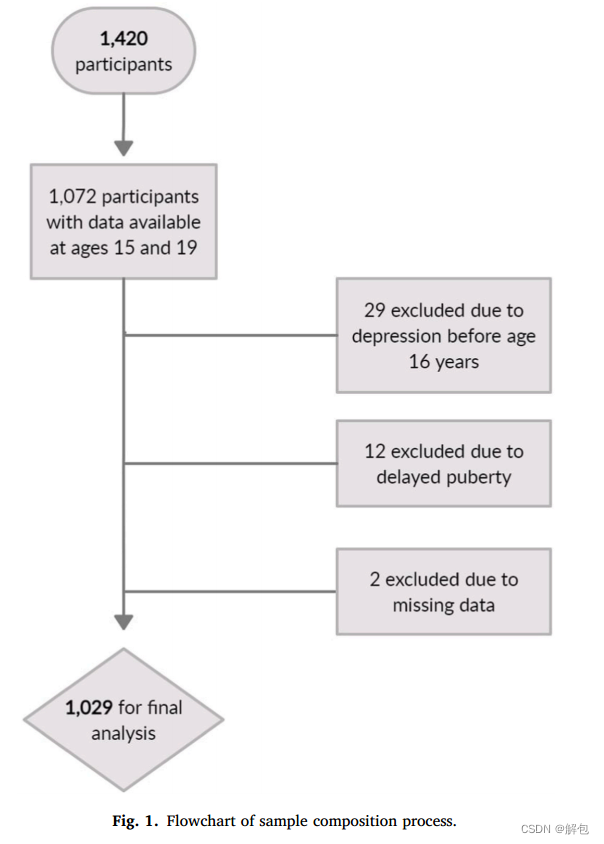
在纳入研究的1420名儿童中,我们选择了1072名同时具有15岁和19岁可用数据的参与者进行当前分析(保留率= 75.5%)。失去随访的参与者更有可能是男性(67.1%对52.5%,卡方独立性检验 p < 0.001),更多在学校失败(32.0%对24.9%,p = 0.014),不太可能吸毒(34.8%对41.5%,p = 0.035),但在其他人口统计学和风险因素变量方面与保留的参与者有相似的情况(见补充表S2)。然后,我们应用了先前在抑郁症风险模型开发中采用的排除标准,目的是捕捉抑郁症的首次发作,并克服潜在的混杂因素(智力残疾、青春期延迟)。因此,29名参与者因在15岁或之前出现抑郁发作而被排除在外,另有12名参与者因被诊断为青春期延迟而被排除(15岁时Tanner分期<2)。没有参与者因智力残疾而被排除在外(智商低于70),因为这已经是GSMS的排除标准。另外两名参与者缺少相关变量的数据,因此被排除在外。当前分析的最终样本量为1029。图1中的流程图概括了选择过程。
2.2 Predictor variables and data harmonization 预测变量和数据协调
最初基于Pelotas群体开发的IDEA-RS包括11个在15岁时评估的变量,用于预测18岁时的抑郁症。我们在GSMS样本中先验定义了15岁时的匹配变量,以构建数据协调矩阵(见表S1)。大多数变量完全或部分对应。“与母亲的关系”、“与父亲的关系”和“父母之间的关系”这三个变量没有发现对应关系,因此没有出现在这里的模型中。正因为如此,我们还通过在Pelotas中生成一个预测模型来更新变量的系数,该模型不包含在GSMS中缺失的三个变量,正如之前的复制工作中所做的那样(Brathwaite等人,2020,2021)。
补充表S1:Pelotas群体中预测因素和抑郁结果测量的描述,以及大烟山研究(GSMS)数据集中的相应的匹配变量
| Pelotas cohort predictors and description |
Categories for questions asked in Pelotas |
Matching variable available in GSMS dataset? |
GSMS cohort matching predictor variable and description |
Categories for questions asked in the GSMS cohort |
| 1. Sex |
Male |
Yes |
Sex |
Male |
| Female |
Female |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1410
1410




 到【灌水乐园】发言
到【灌水乐园】发言







