







 本文介绍了图像处理中的特征检测和匹配技术,如SIFT、SURF、ORB和FAST算法。FAST算法以其快速性著称,通过比较像素点强度确定特征点,而ORB在FAST基础上增加了方向信息,使用高斯金字塔和灰度质心计算。BRIEF则生成二进制描述符,用于关键点的描述和匹配。文章还提到了ORB使用CUDA实现的可能性。
本文介绍了图像处理中的特征检测和匹配技术,如SIFT、SURF、ORB和FAST算法。FAST算法以其快速性著称,通过比较像素点强度确定特征点,而ORB在FAST基础上增加了方向信息,使用高斯金字塔和灰度质心计算。BRIEF则生成二进制描述符,用于关键点的描述和匹配。文章还提到了ORB使用CUDA实现的可能性。
图像的特征检测和匹配一直是一个非常热门的主题。
最近在有用到特征检测和匹配的技术,所以大致参考一些文章,理清一下思路。
FAST
全称是:Features from accelerated segment test (FAST)
作为一个关键点检测器(keypoint detector),和别的关键点检测器相比,简单来说就是一个字:快。
| 普通 | 加速 |
|---|---|
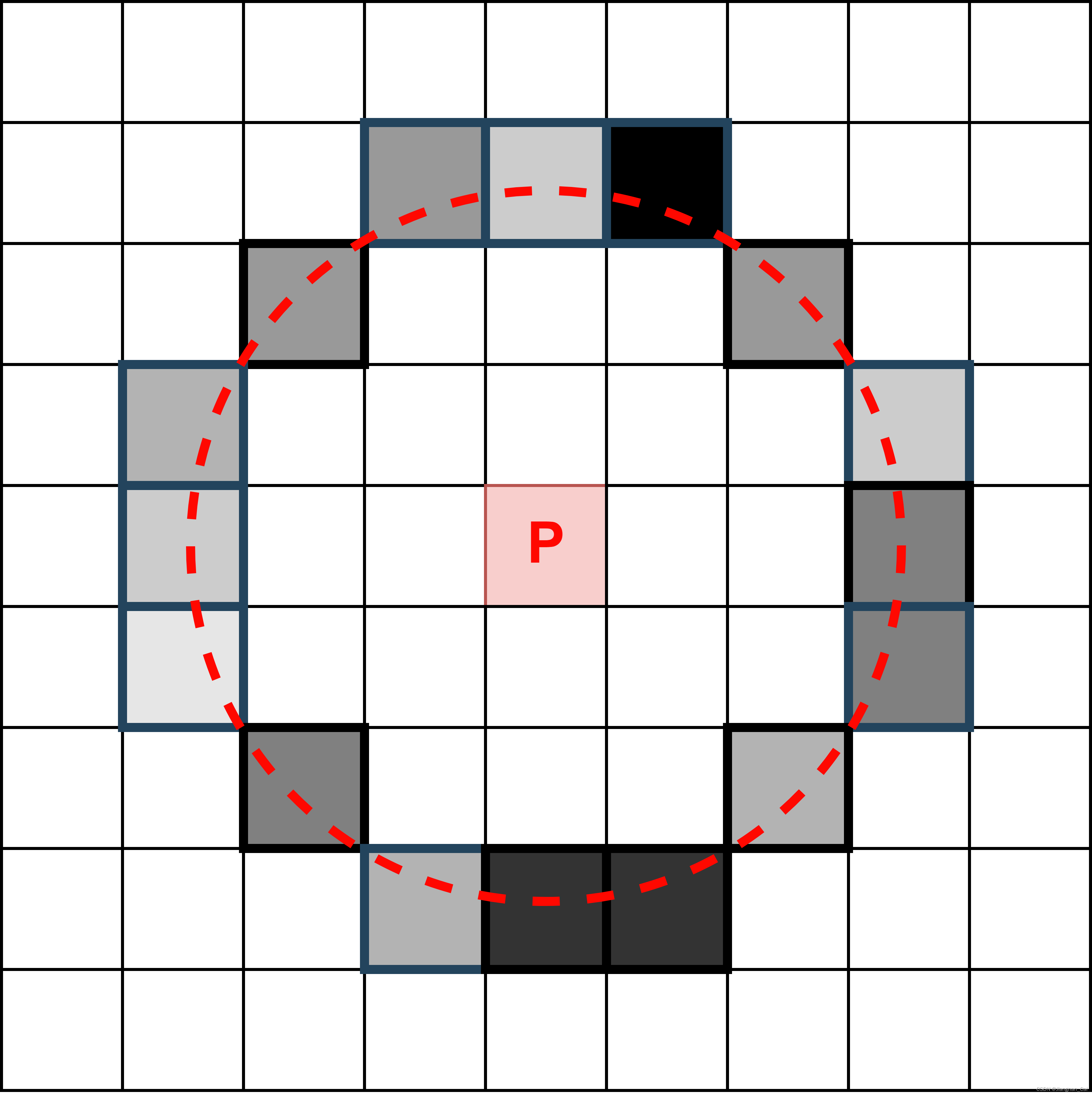 |  |
FAST检测关键的原理可以简单归纳为:中心点 P P P 与一定半径圆上的点的强度(intensity,也就是灰度值)比较,来决定中心点 P P P 是否为关键点 / 特征点 / 角点。
具体怎么确定特征点的呢?我们需要下面几个参数:
- 红色虚线的圆:Bresenham 算法画出来的半径为 3 的圆。确定了 16 个位于环上的像素点。
- 阈值 t t t :用于设置像素点强度的阈值。
- 连续像素点个数 n n n
- P P P 点的强度:表示为 I p I_p Ip, 在圆环上的点,只会被分成 3 类:大于 I p + t I_p + t Ip+t, 小于 I p − t I_p - t Ip−t,还有在 I p − t I_p - t Ip−t 和 I p + t I_p + t Ip+t 之间。
如果圆上存在 n n n 个连续的像素点,其强度值是大于 I p + t I_p + t Ip+t 或者 小于 I p − t I_p - t Ip−t 的。则意味着中心点 P P P 是角点(cornet) / 特征点(feature)。在算法的第一个版本中,作者使用 3 / 4 3/4 3/4 的点,也就是 n = 12 n=12 n=12 作为连续点的设定值。
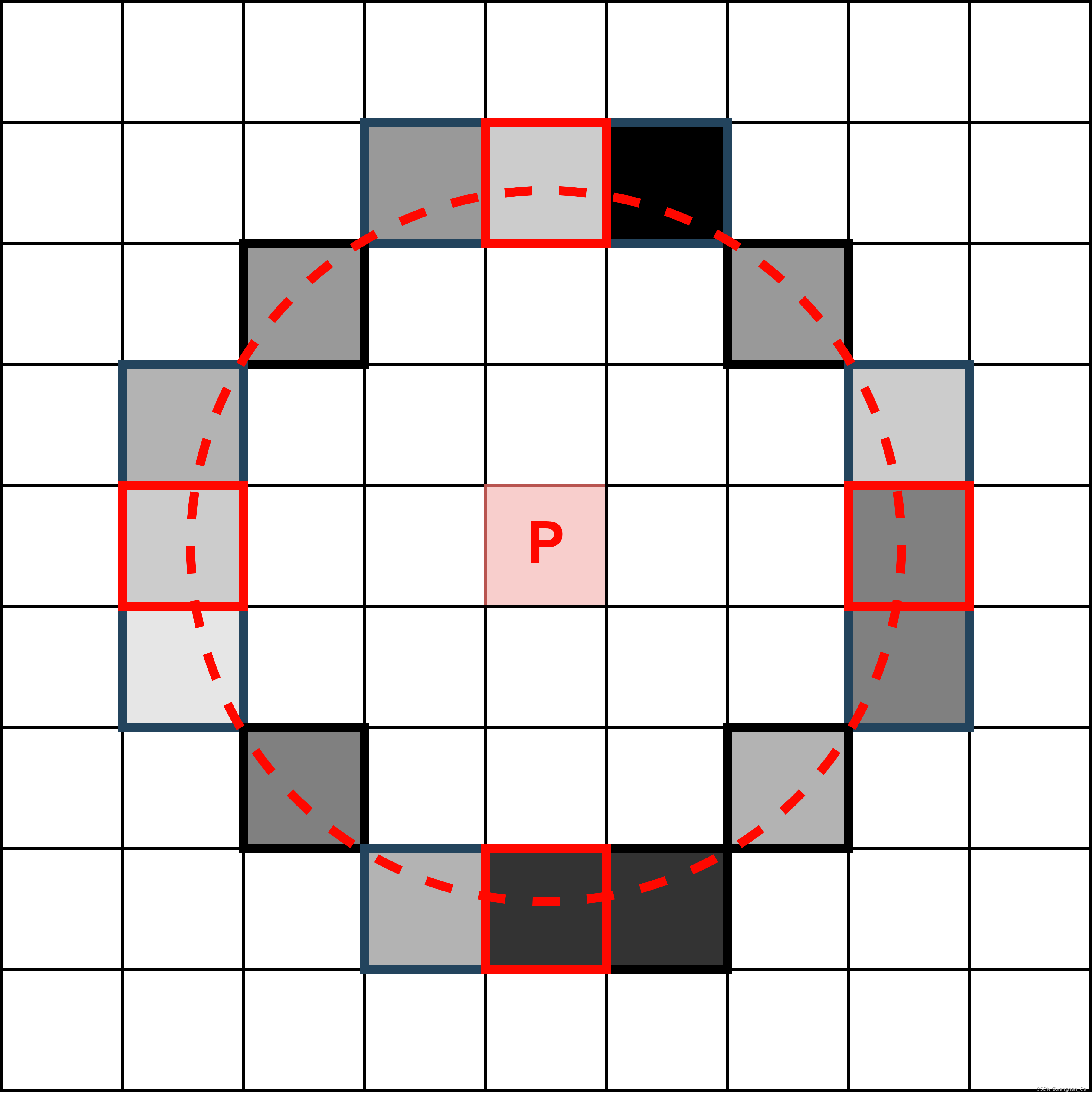
为了让算法跑得更快,加入了一次初筛:
- 第一次判定:先对 I 1 , I 5 , I 9 , I 13 I_1, I_5, I_9, I_{13} I1,I5,I9,I13 也就是图 2 中红色方块内的点进行判断,这 4 个点至少要有 3 个点要大于 I p + t I_p + t Ip+t 或者 小于 I p − t I_p - t Ip−t 的,否则意味着对应的中心点 P P P 不是特征点,可以直接筛掉。
- 第二次判定:再对是否存在 12 个连续像素点满足条件进行判定。
但是这个算法存在 2 个问题:
- 如果 n < 12 n < 12 n<12,检测出来的特征点就会非常多。
- 查询 16 个像素点的顺序,决定了算法的速度。
为了解决上面的问题,引入了机器学习的方法:
就如同上面所说的那样:圆环上的点可以分为 3 类。
S
x
=
{
d
,
I
x
≤
I
p
−
t
(
d
a
r
k
e
r
)
s
,
I
p
−
t
<
I
x
<
I
p
+
t
(
s
i
m
i
l
a
r
)
b
,
I
p
+
t
≤
I
x
(
b
r
i
g
h
t
e
r
)
S_{x} = \begin{cases} d, & I_x \le I_p - t & (darker) \\ s, & I_p - t < I_x < I_p + t & (similar) \\ b, & I_p + t \le I_x & (brighter) \end{cases}
Sx=⎩
⎨
⎧d,s,b,Ix≤Ip−tIp−t<Ix<Ip+tIp+t≤Ix(darker)(similar)(brighter)
- 圆环上的像素点 x x x 的状态表示为 S x S_x Sx, 表示像素点 x x x 在那个某个子集内。
- K p K_p Kp:如果像素点 P P P 是特征点,则有 K p = True K_p = \text{True} Kp=True,否则 K p = False K_p = \text{False} Kp=False。
- 根据圆环像素点的状态,特征向量 P ⃗ \vec{P} P 可以拆分成 3 个子集: P d , P s , P b P_d, P_s, P_b Pd,Ps,Pb。
使用 ID3 算法(决策树分类器)来训练一个决策树,输入就是圆环上的 16 个像素点,输出就是该圆环对应的中心像素点 P P P 的 K p K_p Kp。图像全部的点都过一遍之后。再经过 NMS 筛选一遍之后,就可以得到最终所需的特征点了。
ORB
在 ORB 中也用到了 FAST 算法,但是通过上面,我们知道 FAST 检测出来的特征点是缺少:
- 方向信息(orientation component)
- 多尺度特征(multiscale feature)
但是在 ORB 算法中,我们需要特征点带有方向信息。
就如同在 ORB 论文原文里提到的那样,在几种特征点检测算法中:FAST,SIFT,SURF。除了 FAST,其他两种都是带有方向信息的。
那么,在 ORB 中,他们的解决方案是:
- 缺少多尺度特征,就使用高斯金字塔(pyramid),这使得 ORB 具有了尺度不变性。
- 缺少方向信息,就使用灰度质心(intensity centroid),灰度质心假定特征点的灰度偏离其中心,可以使用该向量来估算特征点的方向。这使得 ORB 具有了旋转不变形。
质心计算
首先,因为图像是二维离散的,包含两个方向,所以图像的矩可以表示为:
m
k
l
=
E
(
X
k
Y
l
)
=
∑
X
∑
Y
x
k
y
l
⋅
I
(
x
,
y
)
m_{kl} =E(X^kY^l)= \sum_X\sum_Y x^k y^l \cdot I(x, y)
mkl=E(XkYl)=X∑Y∑xkyl⋅I(x,y)
- I ( x , y ) I(x, y) I(x,y):像素点 ( x , y ) (x, y) (x,y) 处的灰度值(强度值)。
- k , l k,l k,l:的取值是 0 , 1 0, 1 0,1
这也可以叫做二维 ( k + l ) (k+l) (k+l) 阶原点矩。通常在图像中,是由灰度图或者是二值化图计算得到的。
二维 0 0 0 阶原点矩
在图像中,二维 0 0 0 阶原点矩: m 00 = E ( X 0 Y 0 ) = ∑ X ∑ Y x 0 y 0 I ( x , y ) = ∑ X ∑ Y I ( x , y ) m_{00} = E(X^0Y^0) = \sum_X\sum_Yx^0y^0I(x, y) = \sum_X\sum_YI(x, y) m00=E(X0Y0)=X∑Y∑x0y0I(x,y)=X∑Y∑I(x,y)从这个公式中,我们就可以看出来, m 00 m_{00} m00 相当于对 X Y XY XY 这块面积的灰度强度进行求和。
二维 1 1 1 阶原点矩
也就是 k + l = 1 k+l=1 k+l=1,也就是说存在 k = 0 , l = 1 k=0, l=1 k=0,l=1 和 k = 1 , l = 0 k=1, l=0 k=1,l=0 两种情况: m 01 = E ( X 0 Y 1 ) = ∑ Y y I ( x , y ) m 10 = E ( X 1 Y 0 ) = ∑ X x I ( x , y ) m_{01} = E(X^0Y^1) = \sum_YyI(x, y) \\ m_{10} = E(X^1Y^0) = \sum_XxI(x, y) m01=E(X0Y1)=Y∑yI(x,y)m10=E(X1Y0)=X∑xI(x,y) m 01 m_{01} m01 和 m 10 m_{10} m10 分别表示图像关于 y y y 轴和 x x x 轴的 1 1 1 阶矩。
质心
通过上面的 3 种矩,我们就可以求得质心的坐标为: ( m 10 m 00 , m 01 m 00 ) ( \frac{m_{10}}{m_{00}}, \frac{m_{01}}{m_{00}} ) (m00m10,m00m01)
方向计算
上面我们知道了 X Y XY XY 这一小块图像区域(patch)内的质心的坐标: C = ( m 10 m 00 , m 01 m 00 ) C=\left(\frac{m_{10}}{m_{00}}, \frac{m_{01}}{m_{00}} \right) C=(m00m10,m00m01)而这个区域的中心我们表示为 O O O,则我们可以构造一个 O C → \overrightarrow{OC} OC 向量来表示这一小块图像区域的方向,角度可以通过下面的公式计算: θ = a t a n 2 ( m 01 , m 10 ) \theta = atan2(m_{01}, m_{10}) θ=atan2(m01,m10)
BRIEF
全称是:Binary robust independent elementary feature
大概就是用于生成二进制的描述符(binary descriptor)
但是这个描述符是怎么生成的?
- 取对比较:在关键点周围规定的一小块图像区域(patch)内,随机取两个点 A , B A,B A,B,比较两个点的灰度值,亮的被赋值为 1 1 1,暗的被赋值为 0 0 0。然后根据设定的描述符尺寸取够足够的点对,一般 OpenCV 默认 ORB 算法输出的描述符维度是 32,也就是取 16 对点进行比较,还有 128,256和512等描述符尺寸,可以自己设置。
- 高斯滤波:值得注意的是,在比较上面的像素点强度的时候,为了消除高频噪声,会进行高斯滤波,具体的可以参考文献(BRIEF特征点描述算法详解)里看到详细的讲解。
OpenCV python API
CPU version
orb = cv2.cuda.ORB_create()
img1, img2 = cv2.imread(img1_path, 0), cv2.imread(img2_path, 0) # 以灰度图载入图像
kpt1, desc1 = orb.detectAndCompute(img1, None)
kpt2. desc2 = orb.detectAndCompute(img2, None)
CPU 版本的 ORB 算法:
- 关键点
keypoint:输出的kpt1和kpt2都是 tuple, 而且内部的元素已经是cv.Keypoint对象。所以不需要进行额外的转换。 - 描述符
descriptor:输出的是数组 np.ndarray 类型, ( m , 32 ) (m, 32) (m,32), m m m 表示关键点的数量,等于len(kpt)。
ORB算法的描述符是一个长度为32的向量,它包括了关键点周围的图像信息。具体来说,它包括了该关键点周围的16个像素点的灰度值差异(即光学流),并将其转换为二进制形式。这些二进制值被组合成一个32位的整数,从而得到一个32维的描述符向量。这个向量可以用来比较不同关键点之间的相似性。
就和我们前面提到的 Fast 的原理一样。OpenCV 输出的 ORB 描述符的默认尺寸是32,可以自己设置成 128,256或者512的。
CUDA version
使用 OpenCV 的 CUDA 版本之前,要自己对源码进行编译一次,这里就不展开了。
但是,CUDA 版本的 ORB 算法输出的关键点和描述符都不是符合我们后续匹配操作的格式,所以我么要进行一定的转换。将关键点转换成 cv2.KeyPoint 对象,如果是在 CPU 进行后续的匹配操作,还需要将描述符从 GPU 拷贝回 CPU,不过下面的代码中使用的是 CUDA 版本的 BFMatch 算法,所以不需要将数据转回 CPU。
orb = cv2.cuda.ORB_create()
bf = cv2.cuda.DescriptorMatchter_createBFMatcher(cv2.NORM_HAMMING) # cuda 的 bf match
def feature_detect(img):
img_gpu = cv2.cuda_GpuMat(img)
kpt_gpu, desc_gpu = orb.detectAndComputeAsync(img_gpu, None)
# cv2.KeyPoint的第7个参数是class_id,我这里不太需要,所以构造keypoint的时候没给
kpt_cpu = [cv2.KeyPoint(x=i[0], y=i[1], size=i[2], angle=i[3], response=i[4], octave=int(i[5]))
for i in cv2.cuda.transpose(kpt1_gpu).download().tolist()]
return kpt_cpu, desc_gpu
if __name__ == '__main__':
img1, img2 = cv2.imread(imgpath1, 0), cv2.imread(imgpath2, 0) # ORB 输入必须是灰度图
kptcpu1, descgpu1 = feature_detect(img1)
kptcpu2, descgpu2 = feature_detect(img2)
matches = bf.match(descgpu1, descgpu2) # 得到的matches是DMatch类型组成的list
# 获得两张图中匹配的关键点,位置是一一对应的
kptmatch1 = numpy.float32([kptcpu1[m.queryIdx].pt for m in matches]).reshape(-1, 1, 2)
kptmatch2 = numpy.float32([kptcpu2[m.queryIdx].pt for m in matches]).reshape(-1, 1, 2)
M, _ = cv2.findHomography(src_pts, dst_pts, cv2.RANSAS, 3.0) # 获得转换矩阵
# 进行warp
aligned_img = cv2.warpPerspective(img1, M, (img2.shape[1], img2.shape[0]), borderMode=cv2.BORDER_CONSTANT, borderValue=(255, 255, 255))
img_match = cv2.drawMatches(img1, kptmatch1, img2, kptmatch2, None, flags=2)
cv2.imshow("image", img_match)
cv2.waitKey()
ORB 算法为啥一定要用 Hamming 距离来进行匹配?
- ORB算法得到的描述符是二进制的,而Hamming距离是一种适用于二进制数据比较的距离度量方法。因此,使用Hamming距离来比较ORB算法得到的描述符之间的相似性是非常合适的。而L2距离是一种适用于连续值数据比较的距离度量方法,不适用于二进制数据。因此,使用L2距离来比较ORB算法得到的描述符之间的相似性会报错。
SIFT
我的项目目前使用的就是 SIFT 算法来进行特征点的检测。因为比较了几种特征检测算法之后,发现 SIFT 的描述符可能对方向角度更为敏感,面对各个角度翻转的图像更为敏感。
参考文献:

















 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









