



链表:
链表是一种物理存储单元上非连续、非顺序的存储结构,其物理结构不能只管的表示数数据元素的逻辑顺序,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列的结点(链表中的每一个元素称为结点)组成,结点可以在运行时动态生成。
链表的分类:
1.单向链表(Singly Linked List):
a·在单向链表中,每个节点包含一个数据域和一个指向下一个节点的引用(指针)。这是最简单的链表形式,只能从头节点遍历到尾节点。
b·优点:实现简单;节省空间(每个节点只需要一个额外的指针)。
c·缺点:不能反向遍历;插入和删除操作需要找到前驱节点。
2.双向链表(Doubly Linked List):
a·双向链表中的每个节点除了包含指向下一个节点的引用外,还有一个指向前一个节点的引用。
b·优点:可以从两个方向遍历链表;插入和删除操作更加方便。
c·缺点:每个节点需要两个额外的指针,因此比单向链表占用更多空间。
3.循环链表(Circular Linked List):
a·循环链表可以是单向的也可以是双向的,其特点是最后一个节点的“下一个”指针不是指向null,而是回指到链表的第一个节点,形成一个闭环。
b·优点:便于实现循环遍历;没有明确的尾节点,处理起来更方便。
c·缺点:如果不小心处理,可能会陷入无限循环。
单向链表:
单向链表是链表的一种,它由多个结点组成,每个结点都由一个数据域和一个指针域组成,数据域用来存储数据,指针域用来指向其后继结点。链表的头结点的数据域不存储数据,指针域指向第一个真正存储数据的结点。
双向链表:
双向链表也叫双向表,是链表的一种,它由多个结点组成,每个结点都由一个数据域和两个指针域组成,数据域用来存储数据,其中一个指针域用来指向其后继结点,另一个指针域用来指向前驱结点。链表的头结点的数据域不存储数据,指向前驱结点的指针域值为null,指向后继结点的指针域指向第一个真正存储数据的结点。
链表的复杂度分析:
get(int i):每一次查询,都需要从链表的头部开始,依次向后查找,随着数据元素N的增多,比较的元素越多,时间复杂度为O(n)
insert(int I, T t):每一次插入,需要先找到i位置的前一个元素,然后完成插入操作,随着数据元素N的增多,查找的元素越多,时间复杂度为0(n);
remove(int i):每一次移除,需要先找到i位置的前一个元素,然后完成插入操作,随着数据元素N的增多,查找的元素越多,时间复杂度为0(n)
链表和顺序表的差异:
相比较顺序表,链表插入和删除的时间复杂度虽然一样,但仍然有很大的优势,因为链表的物理地址是不连续的,它不需要预先指定存储空间大小,或者在存储过程中涉及到扩容等操作,同时它并没有涉及的元素的交换。
相比较顺序表,链表的查询操作性能会比较低。因此,如果我们的程序中查询操作比较多,建议使用顺序表,增删操作比较多,建议使用链表。
接下来做一个测试:
假设你正在开发一个简单的学生管理系统,使用顺序表(SequenceList)来存储学生姓名。请完成以下任务:
1、创建一个可以存储字符串的顺序表,初始容量为10
2、添加以下学生姓名到顺序表中:“张三”, “李四”, “王五”,“赵六”。
3、在“李四”后面插入“李四”(注意:需要先找到“李四”的位置)
4、删除“李四”并从顺序表中移除
5、查找“李四”在顺序表中的位置(索引)
6、打印最终顺序表中的所有学生姓名
7、清空顺序表并验证它确实为空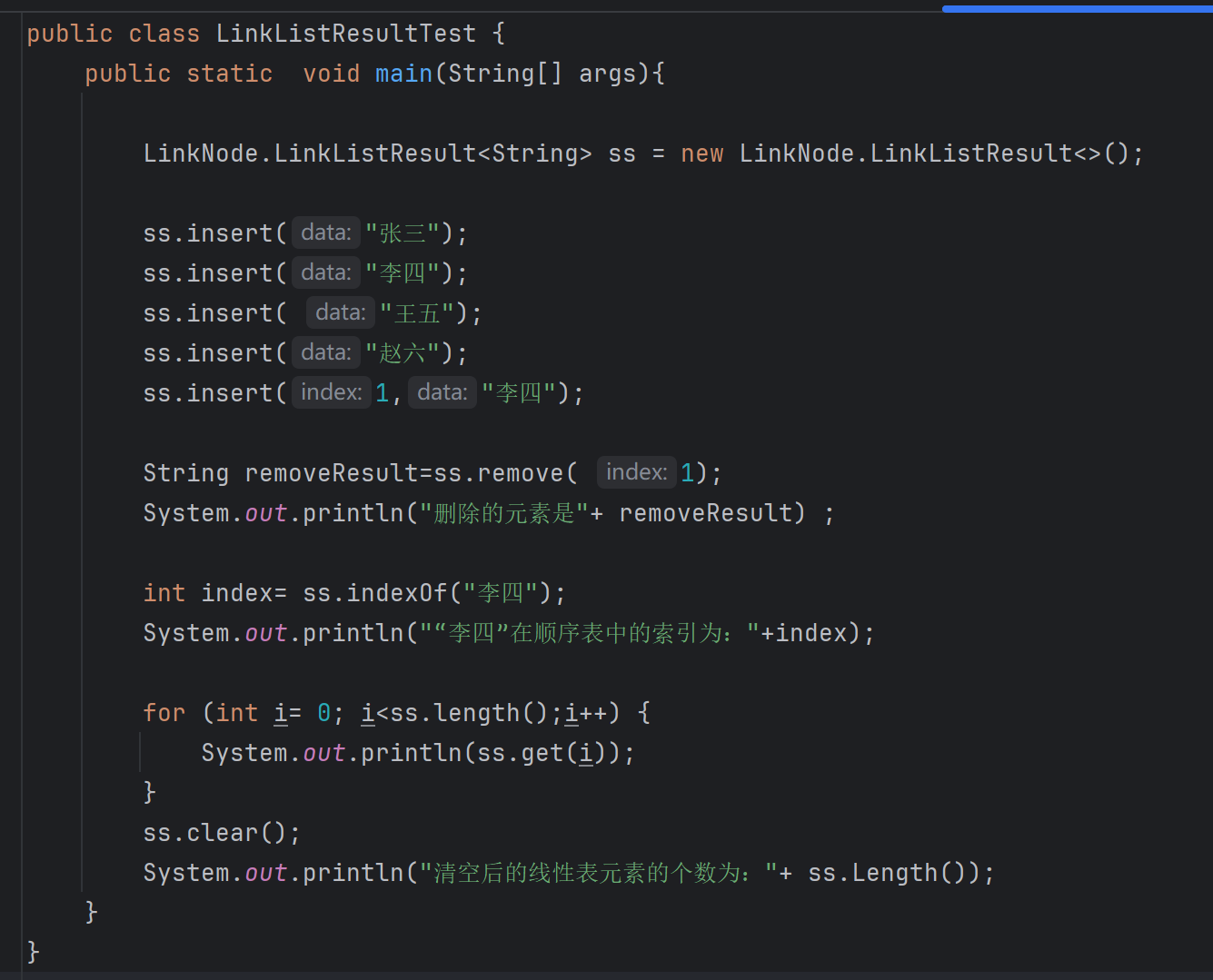

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









