




 本文介绍了一道关于统计1M文件中频数最高的50个词的题目,采用文件分片、内存限制100KB的策略。通过HashMap统计子文件词频,维护一个50节点的最小堆,实现词频统计。文章讨论了文件切分、内存计算、最小堆实现以及代码实现,最后反思了单机内存限制下的优化问题。
本文介绍了一道关于统计1M文件中频数最高的50个词的题目,采用文件分片、内存限制100KB的策略。通过HashMap统计子文件词频,维护一个50节点的最小堆,实现词频统计。文章讨论了文件切分、内存计算、最小堆实现以及代码实现,最后反思了单机内存限制下的优化问题。
前言
前几天,同学问了我一道笔试题,网上大部分只有思路,良莠不齐。并且没找到java代码来实现的~所以就动手敲了一份,尽可能在思路上做到全面,也欢迎大家指教。代码地址
题目
有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的50个词。
为了本机测试方便,将题目改成:
有一个1M大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是100KB。返回频数最高的50个词。
思路
毕竟是经典题目,大体思路如下:
- 文件分片,使得子文件不超过内存限制大小。
- 通过hashMap统计每个子文件中出现词的频率。
- 维护一个含有50结点的最小堆,将hashMap的值依次与堆顶(最小值)作比较。如果大于堆顶值,则替换堆顶值,并重新调整最小堆。所有子文件遍历完,最小堆中剩下的节点就是频数最高的50个单词。
写代码前,还要多向自己提问,这样才能让思路尽可能全面些:
- Q:怎样切分文件,尽可能平均且方便?
- A:参照HashMap分桶原理(当然redis等的切片也类似),将
word的hash值 & 切分文件数量;这样可以防止hashCode为负的情况,为了切片更均匀,切分文件的数量要为2^n 。
//HashMap分桶源码
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
...}
- Q:怎样确定切分文件的数量?
- A:当然要通过待切分文件的大小,和实际内存大小计算得出。然后再取最接近该结果的2^n,这里也可以参考HashMap获取初始容量的算法。
/**
* HashMap源码:获取初始容量的方法 → 找到最接近设置值的2^n
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1; //-1防止本身cap就是2的指数
n |= n >>> 1; //n=n|(n>>>1)
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
- Q:最小堆一般是基于数组来维护的,怎样同时存放word和count?
- A:通过ArrayList来维护最小堆,里面存放wordCount的实体类。
项目结构
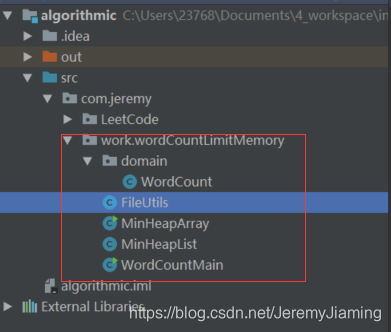
红框内,从上至下:
- domain/WordCount → 实体类;
- FileUtils → File操作类,包含文件分片、生成符合题目要求的文件等方法;
- MinHeapArray → 基于数组维护的最小堆,对本项目无用,作为思路参考;
- MinHeapList → 基于ArrayList维护的最小堆;
- WordCountMain → 主运行文件,入口;
代码
多说无益,上代码:
- 先要生成符合题目要求的文件,用于测试:
/**
* 由一篇英文文章生成
* 生成每一行是一个词的文件,每个文件不超过16个字节
* @param srcFileName
* @param destFileName
* @throws IOException
*/
public static void generateWordTxt(String srcFileName, String destFileName) throws IOException {
BufferedReader br = new BufferedReader(
new InputStreamReader(new FileInputStream(srcFileName)));
StringBuffer stringBuffer = new StringBuffer();
String line;
while ((line = br.readLine()) != null) {
stringBuffer.append(line);
}
String[] words = stringBuffer.toString().split("[^a-zA-Z]+");
PrintWriter pw = new PrintWriter(new FileWriter(destFileName, true));
for (String word : words) {
// ASCII码、UTF-8、GBK 一个英文字母等于一个字节
// Unicode、utf-16be 一个英文字母等于两个字节 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 941
941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









