







我的学习计划
了解工程文件结构
- cfg/ : 目录下面有很多.cfg文件,类似caffe的prototxt文件,包含网络结构,学习参数等
- data/ : 存放训练数据和标注文件,.name文件存放类别名。labels/下有ASCII码32-127的8种尺寸的图片,显示标签用。
- examples/ : 例程代码
- include/ : darknet.h
- obj/ : 编译中间文件
- python/ : karknet.py , darknet.pyc , proverbot.py
- scipts/ : 有关训练集索引文件的脚本
- src/ : 源码
- backup/ : 目录下保存训练产生的权重文件,初始为空文件夹
重新下载编译,并上传至github
cd darknet
git reset
rm -rf .git* # 删除已有的git规则
git init
git add *
git status
gedit .gitignore
git add .gitignore # 我的.gitingore似乎没用了
git commit -m "first commit"
git remote add origin https://github.com/Z-Jeff/darknet.git
git push -u origin master
# 在另一设备上,拷贝下项目:
git clone https://github.com/Z-Jeff/darknet.git
修改Makefile:
# Makefile 修改如下:
GPU=1
CUDNN=1
OPENCV=1
...
NVCC=/usr/local/cuda-10.0/bin/nvcc # 可由 which nvcc查询
编译:
make 下载权重文件并测试运行:
wget https://pjreddie.com/media/files/yolov3.weights
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg // 测试单张图片
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights // 摄像头实时检测
遇到问题:
CUDA Error: out of memory
darknet: ./src/cuda.c:36: check_error: Assertion ‘0’ failed.
解决:更改cfg目录下的yolov3.cfg,把subdivisions=16
改为subdivisions=64
解析Makefile
GPU,CUDNN,OPENCV,OPENMP,DEBUG,ARCH,SLIB,ALIB,EXEC,OBJDIR,OPTS,COMMON等都是自动变量
ARCH:
- 在ARCH中-gencode保证用户GPU可以动态选择最适合的GPU框架,
-arch=compute_30,-code=sm_30表示计算能力3.0及以上的GPU都可以运行编译的程序。 - NVIDIA GPU算力可由此查看https://developer.nvidia.com/cuda-gpus
- 我的显卡为GTX1050,算力是6.1,于是我将其改为
ARCH= -gencode arch=compute_61,code=compute_61- 我尝试了下改成 ARCH= -gencode arch=compute_62,code=compute_62 ,发现编译没出错,运行时出错:CUDA Error: no kernel image is available for execution on the device,以后如果报这种错误,说明你ARCH设定的算力比机器真实算力高。
SLIB指明动态链接库文件,ALIB指明静态链接库文件,EXEC指明可行文件名称,OBJDIR指明中间文件存放目录
OPTS指明编译选项,OPTS=-Ofast中-Ofast 表示忽视严格的标准,使用所有-O3优化。-Ofast详见此 http://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
VPATH,CC,CCP,NVCC,AR,LDFLAGS,CFLAGS等是内置变量
VPATH指定依赖文件的搜索路径,当有多个路径时用分号 : 隔开
AR命令可以用来创建、修改库,也可以从库中提出单个模块,参考博客:https://www.cnblogs.com/LiuYanYGZ/p/5535982.html
ARFLAGS是库文件维护程序的选项
LDFLAGS是GCC链接选项参数,LDFLAGS= -lm -pthread,-lm代表链接数学函数库,-pthread代表链接多线程编译库
CFLAGS是C编译选项
addprefix函数是添加前缀
wildcard是扩展通配符,$(wildcard src/*.h)代表src/下的头文件
这是Makefile的执行主题,分号前面是“目标”,分号后面是“依赖”,下一行是“命令”

Makefile有三个非常有用的变量。分别是$@,$^,$<代表的意义分别是:
$@--目标文件,$^--所有的依赖文件,$<--第一个依赖文件。
$(OBJDIR)%.o 代表文件夹下所有的.o文件
mkdir的-p选项允许你一次性创建多层次的目录
当Makefile文件所在目录有文件名为clean的文件,命令行“.PHONY: clean”又没添加的话,执行make clean是无效的
所以“.PHONY: clean”就是保证即使目录下有文件名为clean的文件,也能正常执行make clean
-DGPU相当于添加了GPU宏定义,用来条件编译和预处理。
源码分析
在examples/darknet.c中有main()函数
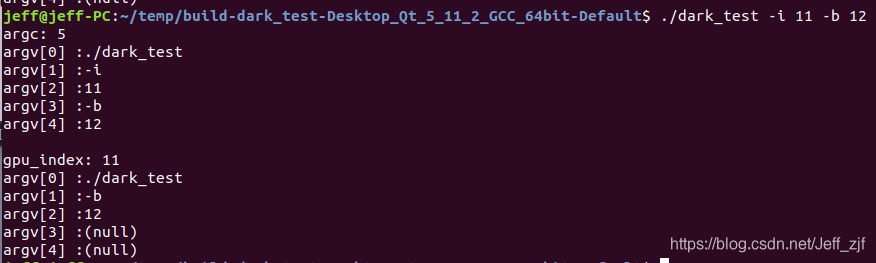
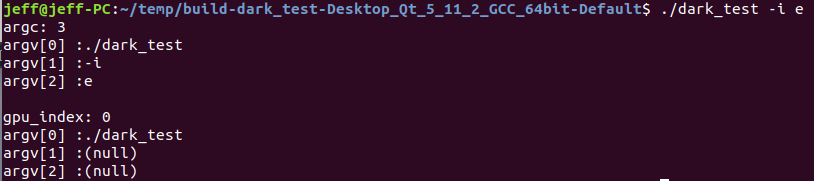
- find_int_arg(),作者自己写的函数,gpu_index = find_int_arg(argc, argv, "-i", 0)的目的是找到-i后的数字参数并赋予gpu_index, 并把-i 和其后的一个参数从argv[]中删除,这说明了-i后面接GPU参数。gpu_index仅仅在cuda_set_device(gpu_index)用到,说明gpu_index应该是有多张显卡的情况下,指明选择哪张显卡
- average(),看名字,猜是计算数据集平均值用的,用法是./daeknet average [cfgfile] [outfile] [weightfile],遇到了一个跟网络配置有关的函数parse_network_cfg()
- parse_network_cfg()
- 其中的 list 是作者自己定义的双向链表结构体,在darknet.h中查到其定义,链表的相关操作在list.c,有创建链表make_list(),取出链表中的一个节点list_pop(), 插入节点到链表list_insert(),释放链表中指针free_list(),释放链表内容free_list_contents(),链表转数组list_to_array()等操作
- read_cfg(),顾名思义,是用来读.cfg文件用的,其中有section结构体,就是加了个type字符标志的链表,声明了section结构体变量options;再下面有个fgetl(),也是作者自己写的,用来读取文件的一行;strip(line)把每一行的空格,制表符和回车符号去掉;然后判断每一行的首字符,如果是 [ ,则将那一行保存到current -> type中去,如果是 \0 # ; 则跳过,其他情况下,将一行保存到 current -> options 中。
有些复杂,我用下图便于理解。每一个红色框是一个section,也是链表options的一个节点,每个section由type和options组成。list *sections = read_cfg(filename)的作用一目了然。section可以看做是一个“层”的表示。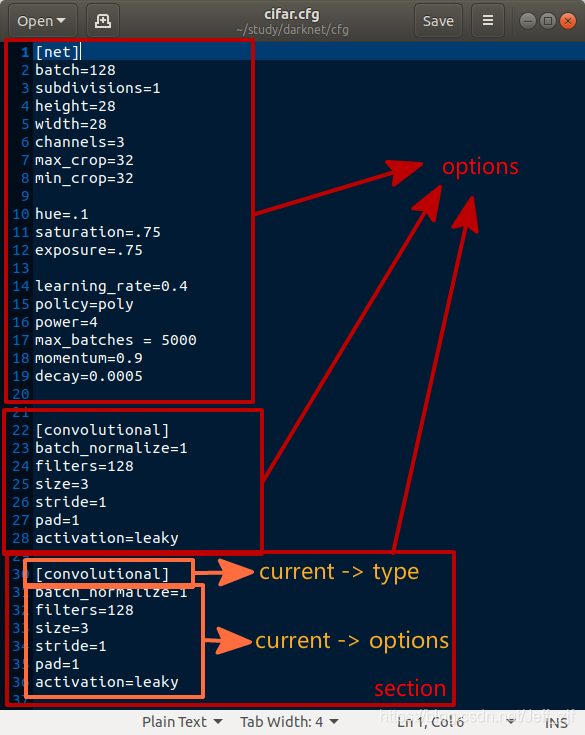
- make_network(),初始化网络,首先要了解network结构体,其包含了网络的参数,意义如下:
network结构体:n batch *seen *t epoch subdivisions *layers *output policy 含义 层数
int
批大小
int
计数用途。
比如用30批大小迭代一次,seen为30。
运行时加参数-clear可使seen为0.
size_t
int
迭代次数
float
batch分割次数
为解决内存不足
int
结构体
见下表
输出结果
float
学习策略
enum
learning_rate momentum decay gamma scale power time_steps step max_batches *scales *steps num_steps burn_in layers结构体:
type activation cost_type (*forward)
(*backward)
(*updata) 含义 层的类型。
枚举变量,有卷积,反卷积,连接,池化等类型。
激活函数。
枚举变量,有LOGISTIC,RELU,RELIE等。
损失类型。
枚举变量。有
SSE,MASKED,L1SEG等
前向,后向操作。
函数指针。
形参是layers和network
更新操作。
函数指针。
形参是layers和update_args。
update_args详见darknet.h第97行
onlyforward stopbackward dontload dontsave dontloadscales numload 是否载入该层权重。
int
载入的卷积个数 - parse_net_options(),作用将.cfg文件中读到的信息保存到network结构体变量net中,其源码大部分是赋值语句,特别注意下batch变量,batch先除于subdivisions,再乘上time_steps,这个结果才是正真的batch,我很好奇作者这样做的意图,难道batch大小要随时间变化?
- load_weights(),作用是载入权重,它的主体是函数load_weights_upto()。load_weights_upto()有四个形参:network结构体变量,权重文件名,开始的层数,截止的层数。
定位到它的源码,fread(&major, sizeof(int), 1, fp)代表读一个int变量到major中,权重文件开头是三个int变量:major,minor,revision。major和minor组成的数字控制network->seen的内容,这里我有点疑惑。
接下来的循环体,以层为单位进行遍历,新建了layer结构体变量l并赋值,首先判断 l.dontload 是否加载权重,然后根据 l.type 做不同操作。虽然type有很多种类型,比如CONVOLUTIONAL,CONNECTED,BATCHNORM,RNN等,但其载入权重的方式只有三种:load_convolutional_weights(),load_connected_weights(),load_batchnorm_weights()- load_convolutional_weights():
先载入l.n个float类型的偏置,说明layer.n是卷积层中卷积的个数。如果有BN操作并且l.dontloadscales不为1时,读BN算法相关的参数:scales,rolling_mean,rolling_variance(这里均值和方差是滚动的)。每个卷积核都有独立的BN算法参数,所以要载入n组参数。
有关BN算法参考博客:https://blog.youkuaiyun.com/yujianmin1990/article/details/78764597
如果scales对应γ,似乎少了个β参数,我又疑惑了。
然后载入卷积的权重参数到l.weights,参数个数计算方法为int num = l.c/l.groups*l.n*l.size*l.size; ( 通道数/分组数×卷积个数×卷积尺寸×卷积尺寸 ),l.flipped控制权重参数是否转置。 - load_connected_weights():
跟load_convolutional_weights()类似,就是biases和weights数量不一样。 - load_batchnorm_weights():只载入scales,rolling_mean,rolling_variance这三组参数。
- load_convolutional_weights():
- 整个average()看下来,其作用就是计算每层biases,weights,scales,rolling_mean,rolling_variance的平均值。
- parse_network_cfg()
- test_detector():这是运行./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg时调用的函数,可以看到有七个参数:datacfg,cfgfile,weightfile,filename,thresh,hier_thresh,outfile,fullscreen。
- datacfg:有关数据集信息的文件。以cfg/coco.data为例
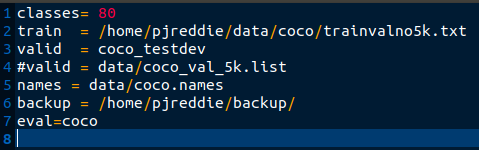
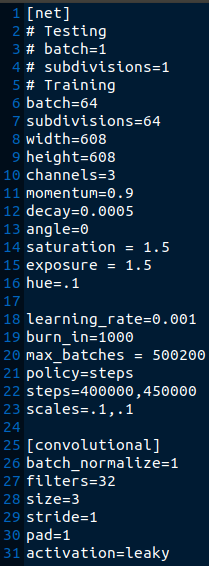
如果只是推理,只会用到classes(类别个数),names(类别名称) - cfgfile:网络配置文件。以cfg/yolov3.cfg为例,它包含yolov3网络配置的参数,比如学习率,批大小。以及每层的卷积核大小,pad,stride等信息
- weightfile:权重文件。以yolov3.weights为例,它包含yolov3网络各层的权重。
- filename:测试的图片文件名。
- thresh:用于目标检测的阈值。
- hier_thresh:
- outfile:输出图片文件名。输出图片为检测的结果
- fullscreen:
- datacfg:有关数据集信息的文件。以cfg/coco.data为例
test_detector()的输入参数作用了解后,开始读此函数的源码:
list *options = read_data_cfg(datacfg); 读datacfg文件
char *name_list = option_find_str(options, "names", "data/names.list"); 然后找datacfg中“name”的那一项,就是标签名称文件。如果没找到,就默认为data/names.list。
char **names = get_labels(name_list); 获取标签的名称
image **alphabet = load_alphabet(); 从data/labels/下加载ASCII码32-127的8种尺寸的图片,后边显示标签用。
network *net = load_network(cfgfile, weightfile, 0); 用cfgfile载入网络配置,用weightfile载入网络权重,第三个参数控制set->seen
set_batch_network(net, 1); 配置网络批大小为1
srand(2222222); 随机数发生器的初始化函数
image im = load_image_color(input,0,0); 载入图片。如果编译时选定了opencv,会用opencv的函数载入图片,否则用stb_image.h中的函数载入图片。后两个的参数是w,h(宽,高),如果这两个参数不为0时,会resize成对应的尺寸,如果为0时,则按原尺寸载入
image sized = letterbox_image(im, net->w, net->h); 将图片缩放适合输入网络的尺寸,其具体操作见下图:
layer l = net->layers[net->n-1]; 这是网络最后一层
network_predict(net, X); 推理预测,函数内部调用forward_network(),
detection *dets = get_network_boxes(net, im.w, im.h, thresh, hier_thresh, 0, 1, &nboxes); 获取网络目标检测输出的box,这里面有关目标检测的细节有点多,暂时跳过。
if (nms) do_nms_sort(dets, nboxes, l.classes, nms); 对检测结果做非极大值抑制(NMS)
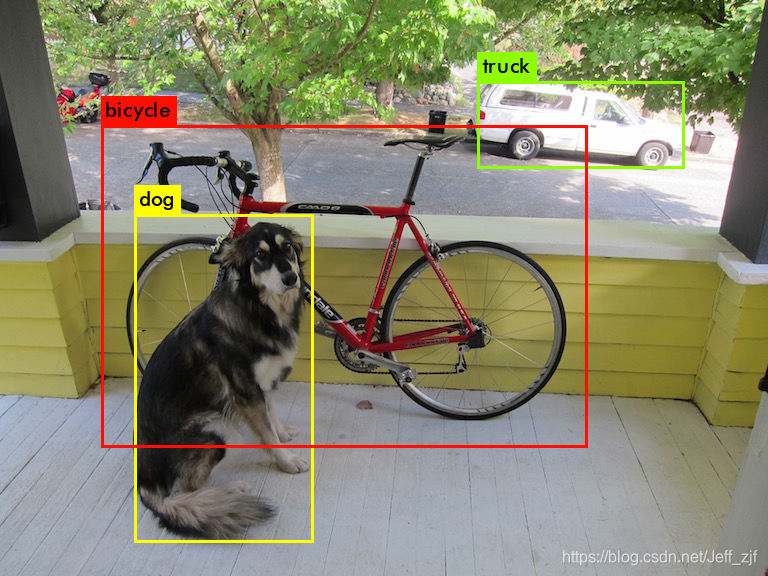
draw_detections(im, dets, nboxes, thresh, names, alphabet, l.classes); 画出检测结果
看了average(),和test_detector()两个函数,下一步,想要了解darknet是如何训练的。

















 1254
1254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









