




算法导论基础:
1.关于一些概念
- 算法:非形式的说,算法就是任何良定义的计算过程,该过程取某个值或值的集合作为输入并产生某个值或值的集合作为输出。
- 算法就是把输入转换成输出的计算步骤的一个序列。
- 可以把算法看成是用于求解良说明的计算问题的工具。一般来说问题陈述说明了期望的输入输出关系。算法则描述一个特定的计算过程来实现该输入输出体系。
- (1)时间复杂度:执行这个算法需要消耗多少时间。
- (2)空间复杂度:这个算法需要占用多少内存空间。
2.插入排序及对插入排序算法的分析及设计算法
1. 插入排序
输入 n个数的一个序列(a1,a2,….,An)
输出 输入序列的一个排序(A1’,A2’…An’)满足A1’ ≤A2’≤… ≤An’

插入排序的步骤:
A ={5,2,4,6,1,3}
{2,5,4,6,1,3}
{2,4,5,6,1,3}
{2,4,5,6,1,3}
{1,2,4,5,6,3}
{1,2,3 ,4,5,6}
循环不变式:把 524613 分为A[1,j-1] A[j,N] A [1,j-1]是排序好的部分,称为循环不变式子

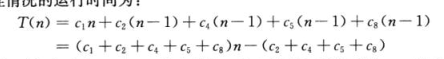
循环不变式的性质:
- 初始化 循环的第一次迭代之前, 它为真 最开始的5是不定式子
- 保持 如果循环的某次迭代之前他为真,他们下一次迭代之前仍为真
第二次的 25 第三次的 245 都是不变式
- 终止 在循环终止前,不变式为我们提供一个有用的性质,该性质有助于证明算法是正确的。
证明插入排序的正确性:

2.分析算法:
分析算法的结果意味着预测算法需要的资源。虽然有时候我们主要关心像内存,通信带宽或计算机硬件这类资源。但是我们通常想度量的是计算时间。
插入排序算法的分析:算法需要的时间与输入的规模同步增长。所以通常把一个程序的运行时间描述成其输入规模的函数。
输入规模:对许多问题,如排序或计算离散傅里叶变换,最自然的量度是输入中的项数,例如,待排序数组的规模N。对其他许多问题,如两个整数相乘,输入规模的最佳量度是用通常的二进制记号表示输入所需的总位数。
运行时间: 一个算法在特定输入上的运行时间是指执行的基本操作数或步数。定义步的概念以便尽量独立于机器是方便的。假定每次执行第i行代码需要常量时间Ci 。

![]()
Java代码实现插入算法:
//(c, n),第一个参数表示该步执行一次的时间,第二个参数表示该步执行的次数。
for (int i = 1; i < a.length; i++) { // (c1, n)
int j = i - 1; //(c2, n-1)
int curr = a[i]; // (c3, n-1)
while (j > -1 && curr < a[j]) { // (c4, t2+t3+...+tn)
a[j + 1] = a[j];// (c5, (t2-1)+(t3-1)+...+(tn-1))
j--;// (c6, (t2-1)+(t3-1)+...+(tn-1))
}
a[j + 1] = curr;// (c7, n-1)
}
最佳情况:若输入数组已经排好序,则出现最佳情况。
那么上述表达式可变为:
最坏情况:如果输入数组是倒序,则出现最坏情况。
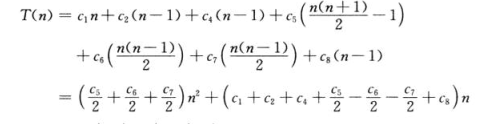
我们可以把最佳情况的函数表达为 Tn=an+b 这是线性函数。
最坏情况的函数表达为 An2+Bn+c 这是二次函数。
平均情况:在某些特定情况下,我们会对一个算法的平均情况运行时间感兴趣,贯穿于本书,我们将看到概率分析技术被用于各种算法,平均情况分析的范围有限,因为对于特定的问题,什么构成一种平均输入并不明显。我们常常假定给定规模的所有输入具有相同的可能性。实际上,该假设可能并不成立,但是,有时可恶意使用随机化算法,他做出一种随机的选择,以允许进行概率分析并产生某个期望的运行时间。
增长量级:
我们使用某些简化的抽象来使得分析插入排序的分析更加容易。
第一:我们通过使用常量Ci表示这些代价忽略每条语句的实际代价。
第二: 我们注意到这些常量也提供了比我们真正需要的要多的细节:把最坏情况运行时间表示为An2+Bn+C 其中a,b,c依赖于语句代价Ci,这样我们不但忽略实际的语句代价,而且也忽略抽象的代价Ci。
从上面可以看出,其实,对于算法分析而言,我们真正感兴趣的是运行时间的增长率或增长量级。所以我们只考虑公式中最重要的项 An2 ,因为当N的值很大时候,低阶项相对来说不太重要。 甚至我们也可以忽略最重要的项的常系数,当N的值很大时候,在确定计算效率时常量因子不如增长率重要。对于插入排序,当我们忽略低阶项和常数系数时,只剩下最重要的项中的因子N2.
我们记插入排序具有最坏情况运行时间 西塔符号θ(N2)-à (西塔 N的平方).
如果一个算法的最坏情况运行时间具有比另一个算法更低的增长量级,那么我们通常认为前者比后者更有效。由于常量因子和低阶项,对于小的输入,运行时间具有较高增长量级的一个算法与运行时间具有较低增长量级的另一个算法相比,其可能需要较少的时间。但是对足够大的输入,一个θ(N2的算法在最坏情况下比另一个θ(N3)的算法运行的更快。
3设计算法
- 分治法: 许多有用的算法在结构上是递归的,为了解决一个给定的问题,算法一次或多次递归地调用其自身以解决紧密相关的若干子问题。这些算法典型的遵循分治法的思想:将原问题分解为几个规模较小,但类似于原问题的子问题,递归地求解这些子问题,然后再合并这些子问题的解来建立原问题的解。
- 分治模式在每层递归时都有三个步骤:
- 分解原问题为若干子问题,这些子问题是原问题的规模较小的实例
- 解决这些子问题,递归的求解各个子问题,然而若干子问题的规模足够小,则直接求解
- 合并这些子问题的解成原问题的解。
归并排序:
归并排序算法完全遵循分治模式
- 分解:分解待排序的N个元素的序列成各具n/2元素的两个子序列
- 解决 使用归并排序递归的排序两个子序列
- 合并,合并两个已排序的子序列产生已排序的答案。


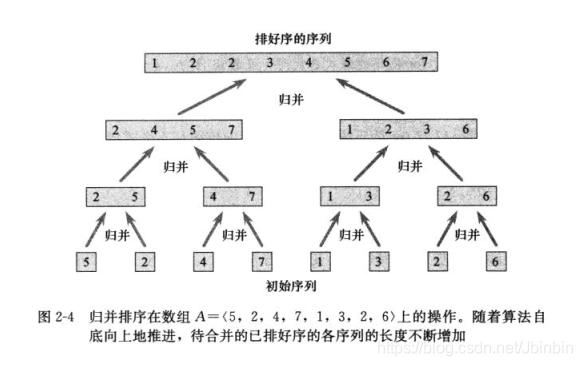
Java代码实现归并排序
public class merge {
public static void main(String[] args) {
int[] arr= {9,5,2,4,6,1,3,7,10,8} ;//new int[5];
merge_sort(arr,0,9);
for(int i=0;i<arr.length;i++) {
System.out.print(arr[i]);
}
}
//假如有一个数组a 1-30 ,我们取他们的子数组 9-16,p=9 q=12 r=16
// p q r 是数组下标 0 4 9
public static void mergeArray(int p,int q,int r,int[] a) {
//分别定义左数组的长度和右数组的长度
int n1=q-p+1;//5
int n2=r-q;//5
//System.out.println( n1 +" " + n2);
int[] left = new int[n1+1];//定义一个左数组 长度为6
int[] right = new int[n2+1];//定义一个右数组 长度为6
System.out.println("分割后两数组长度"+ left.length + right.length);
//给两个数组赋值
for(int i=0;i<n1;i++) {// 01234
left[i]=a[p+i];
System.out.println(left[0]);
}
for(int i=0;i<n2;i++) {//56789
right[i]=a[q+i+1];
System.out.println(right[0]);
}
left[n1]= 9999;// 设置两个最大值 数组比较时候不用判断是否数组为空
right[n2]= 9999;
int i=0;
int j=0;
//分治策略是把一个数组分成两个,然后在两个数组一一比较,假如a<b 则 a排在前面
for(int k=p;k<=r;k++) { //k=0 ,k<=9
if(left[i]<right[j]) { // 9,5,2,4,6 1,3,7,10,8
a[k]=left[i];
i=i+1;
} else {
a[k]=right[j];
j=j+1;
}
}
}
public static void merge_sort(int[] a,int p,int r){
System.out.println( p + "===" + r);
if(p<r) {
int q=(p+r)/2; //3
System.out.println( p + " ||| " + r+ "平均值"+q );
merge_sort(a,p,q);//对左边划分
merge_sort(a,q+1,r);//对右边划分
mergeArray(p,q,r,a);//分治排序
}
}
}
分析分治算法:
当一个算法包含对其自身的递归调用时,我们 往往可以用递归方程或递归式来描述其运行时间,该方程根据在较小输入上的运行时间来描述在规模为N的问题上的总运行时间,然后我们可以使用数学工具来求解该递归式并给出算法性能的界。
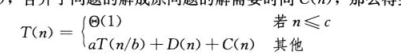
指数和对数
Y=aX X=log2Y
8=2#3 3=log2#8
函数的增长:e 是一个自然对数,极限值。
假定有一种单细胞生物,它每过24小时分裂一次。
那么很显然,这种生物的数量,每天都会翻一倍。今天是1个,明天就是2个,后天就是4个。我们可以写出一个增长数量的公式:
上式中的x就表示天数。这种生物在x天的总数,就是2的x次方。这个式子可以被改成下面这样:
其中,1表示原有数量,100%表示单位时间内的增长率。
4
我们继续假定:每过12个小时,也就是分裂进行到一半的时候,新产生的那半个细胞已经可以再次分裂了。
因此,一天24个小时可以分成两个阶段,每一个阶段都在前一个阶段的基础上增长50%。
当这一天结束的时候,我们一共得到了2.25个细胞。其中,1个是原有的,个是新生的,另外的0.25个是新生细胞分裂到一半的。
如果我们继续修改假设,这种细胞每过8小时就具备独立分裂的能力,也就是将1天分成3个阶段。
那么,最后我们就可以得到大约2.37个细胞。
很自然地,如果我们进一步设想,这种分裂是连续不断进行的,新生细胞每分每秒都具备继续分裂的能力,那么一天最多可以得到多少个细胞呢?
当n趋向无限时,这个式子的极值等于2.718281828...。
因此,当增长率为100%保持不变时,我们在单位时间内最多只能得到2.71828个细胞。数学家把这个数就称为e,它的含义是单位时间内,持续的翻倍增长所能达到的极限值。
这个值是自然增长的极限,因此以e为底的对数,就叫做自然对数。
e是石头里蹦出来的吗?
e是自然对数函数的底数。有时称它为欧拉数(Euler number),以瑞士数学家欧拉命名;也有个较鲜见的名字纳皮尔常数,以纪念苏格兰数学家约翰·纳皮尔引进对数。它就像圆周率π和虚数单位i,e是数学中最重要的常数之一。 它的数值约是:e ≈ 2.71828
第一次提到常数e,是约翰·纳皮尔于1618年出版的对数著作附录中的一张表。但它没有记录这常数,只有由它为底计算出的一张自然对数列表,通常认为是由威廉·奥特雷德(William Oughtred)制作。第一次把e看为常数的是雅各·伯努利(Jacob Bernoulli)。知的第一次用到常数e,是莱布尼茨于1690年和1691年给惠更斯的通信,以b表示。1727年欧拉开始用e来表示这常数;而e第一次在出版物用到,是1736年欧拉的《力学》(Mechanica)。虽然以后也有研究者用字母c表示,但e较常用,终于成为标准。
用e表示的确实原因不明,但可能因为e是“指数”(exponential)一字的首字母。另一看法则称a,b,c和d有其他经常用途,而e是第一个可用字母。不过,欧拉选这个字母的原因,不太可能是因为这是他自己名字Euler的首字母,因为他是个很谦虚的人,总是恰当地肯定他人的工作。
当x趋于正无穷大或负无穷大时,“1加x分之一的x次方”这个函数表达式(1+1/x)^x的极限就等于e,用公式表示,即:
lim(1+1/x)^x=e (x趋于±∞)
实际上e就是欧拉通过这个极限而发现的,它是个无限不循环小数,其值等于2.71828……。以e为底的对数叫做自然对数,用符号“ln”表示。
至于欧拉选择e的理由,较为多数人所接受的说法有二:一为在a,b,c,d等四个常被使用的字母后面,第一个尚未被经常使用的字母就是e,所以,他很自然地选了这个符号,代表自然对数的底数;另一说法为e是“指数”一词英文的第一个字母,虽然你或许会怀疑瑞士人欧拉的母语不是英文,可事实上法文、德文的“指数”都是它。究竟e的来历是什么?至今仍然是个谜。

















 295
295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









