






Apache Kafka 使用指南、原理介绍与问题解决方案
Apache Kafka 是一个分布式流处理平台,最初由 LinkedIn 开发,后成为 Apache 开源项目。它结合了消息队列和日志存储的功能,专为高吞吐量、低延迟的实时数据处理而设计。以下内容基于可靠资源(如官方文档和社区实践),我将从原理介绍、使用指南和问题解决方案三个方面,逐步为您解析。回答结构清晰,便于理解。
一、原理介绍
Kafka 的核心原理建立在分布式系统上,确保数据的高可靠性和可扩展性。以下是关键概念和机制:
-
核心组件:
- Broker:Kafka 集群中的服务器节点,负责存储和处理数据。多个 Broker 组成集群,提供容错能力。
- Topic(主题):数据流的逻辑分类,如“订单日志”或“用户行为”。每个 Topic 可划分为多个 Partition(分区),实现并行处理。分区是 Kafka 高吞吐量的基础,通过分区副本(Replica)保证数据冗余。
- Producer(生产者):应用程序将数据推送到 Topic 的组件。生产者根据分区策略(如轮询或键哈希)写入数据,确保负载均衡。
- Consumer(消费者):从 Topic 读取数据的组件。消费者可组成 Consumer Group(消费者组),组内消费者共享分区,实现并行消费。每个消费者维护 Offset(偏移量),记录读取位置,避免重复处理。
- ZooKeeper:早期版本用于管理集群元数据(如 Broker 状态和分区信息),但 Kafka 2.8+ 开始支持 KRaft 模式,逐步摆脱 ZooKeeper 依赖。
-
架构优势:
- 高吞吐量:通过分区和批量写入,Kafka 支持每秒百万级消息处理。例如,生产者使用批量发送减少网络开销。
- 低延迟:消息写入磁盘后立即可用,消费者可实时拉取。
- 持久化:数据存储在磁盘日志中,支持可配置的保留策略(如时间或大小限制)。
- 可扩展性:集群可动态添加 Broker,Topic 可增加分区以应对流量增长。
- 容错性:分区副本机制确保 Broker 故障时数据不丢失。副本通过 Leader-Follower 模型同步,Leader 处理读写,Follower 作为备份。
-
工作流程:
- 生产者发送消息到 Topic 分区 → Broker 存储消息并确认 → 消费者组拉取消息并提交 Offset。
- 例如,在日志收集场景中,多个服务作为生产者写入日志 Topic,消费者组并行处理日志数据。
Kafka 的原理使其广泛应用于实时数据管道,如日志聚合、事件溯源和流处理。
二、使用指南
使用 Kafka 需设置集群、配置生产者和消费者。以下以 Java 和 C# 为例,提供基础指南。假设您已安装 Kafka(可从官网下载)。
1. 基本设置
- 启动 Kafka:
- 启动 ZooKeeper(如果使用):
bin/zookeeper-server-start.sh config/zookeeper.properties - 启动 Kafka Broker:
bin/kafka-server-start.sh config/server.properties - 创建 Topic:
bin/kafka-topics.sh --create --topic test --partitions 3 --replication-factor 1 --bootstrap-server localhost:9092
- 启动 ZooKeeper(如果使用):
- 配置要点:
bootstrap.servers:指定 Broker 地址(如localhost:9092)。- 生产者配置:
acks=all确保所有副本确认写入,提高可靠性。 - 消费者配置:
group.id设置消费者组名,auto.offset.reset=earliest从头开始消费。
2. 生产者示例(Java)
生产者将消息发送到 Topic。以下是一个简单 Java 代码示例(使用 Kafka Java API)。
import org.apache.kafka.clients.producer.*;
public class KafkaProducerExample {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10; i++) {
ProducerRecord<String, String> record = new ProducerRecord<>("test", "key-" + i, "value-" + i);
producer.send(record, (metadata, exception) -> {
if (exception == null) {
System.out.println("Sent to partition " + metadata.partition());
} else {
exception.printStackTrace();
}
});
}
producer.close();
}
}
- 说明:此代码发送10条消息到“test” Topic。使用回调处理发送结果,确保可靠性。
3. 消费者示例(C#)
消费者从 Topic 读取消息。使用 Confluent.Kafka NuGet 包(C# 库)。
using Confluent.Kafka;
using System;
public class KafkaConsumerExample {
public static void Main() {
var config = new ConsumerConfig {
BootstrapServers = "localhost:9092",
GroupId = "test-group",
AutoOffsetReset = AutoOffsetReset.Earliest
};
using (var consumer = new ConsumerBuilder<Ignore, string>(config).Build()) {
consumer.Subscribe("test");
try {
while (true) {
var result = consumer.Consume(TimeSpan.FromSeconds(1));
if (result != null) {
Console.WriteLine($"Received: {result.Message.Value}");
// 手动提交 Offset,确保消息不丢失
consumer.Commit(result);
}
}
} catch (Exception ex) {
Console.WriteLine($"Error: {ex.Message}");
}
}
}
}
- 说明:消费者组“test-group”从“test” Topic 拉取消息。
Commit方法手动提交 Offset,避免重复消费。
4. 集成框架(如 Spring Boot)
在微服务中,Spring Boot 简化 Kafka 集成:
- 添加依赖:
spring-kafka。 - 配置
application.properties:spring.kafka.bootstrap-servers=localhost:9092 spring.kafka.consumer.group-id=my-group - 生产者 Controller:
@RestController public class KafkaController { @Autowired private KafkaTemplate<String, String> kafkaTemplate; @PostMapping("/send") public String sendMessage(@RequestParam String message) { kafkaTemplate.send("test", message); return "Message sent"; } } - 消费者 Service:
@Service public class KafkaConsumer { @KafkaListener(topics = "test", groupId = "my-group") public void listen(String message) { System.out.println("Received: " + message); } } - 测试:通过 REST API 发送消息,消费者自动处理。
使用场景示例
- 日志收集:多个应用作为生产者写入日志 Topic,消费者组聚合到存储系统(如 Elasticsearch)。
- 实时数据处理:Kafka Streams 或 Flink 集成,处理订单流(如过滤异常交易)。
- 消息传递:微服务间解耦,生产者发布事件,消费者订阅处理。
三、问题解决方案
Kafka 使用中常见问题包括性能瓶颈、数据丢失和配置错误。以下是实用解决方案:
-
消息丢失问题:
- 原因:生产者未确认写入、消费者未提交 Offset、Broker 故障。
- 解决方案:
- 生产者端:设置
acks=all,启用重试机制(如retries=3)。 - 消费者端:手动提交 Offset(如 C# 示例中的
Commit),避免自动提交导致消息丢失。 - Broker 端:增加
replication.factor(如 3),确保分区副本足够。
- 生产者端:设置
- 监控:使用 Kafka 工具(如
kafka-consumer-groups.sh)检查 Offset 延迟。
-
性能瓶颈:
- 原因:分区不足、网络延迟、消费者处理慢。
- 解决方案:
- 增加 Topic 分区数(需重启或动态扩展)。
- 优化生产者:批量发送(
batch.size调大),减少网络请求。 - 消费者并行化:扩大消费者组规模,确保分区数与消费者数匹配(避免空闲消费者)。
- 资源调整:监控 Broker CPU/磁盘,升级硬件或优化日志保留策略。
-
重复消费问题:
- 原因:消费者故障后重启,Offset 未提交或提交失败。
- 解决方案:
- 实现幂等消费者:设计处理逻辑,使重复消息不影响结果(如数据库唯一键)。
- 使用事务:生产者启用
enable.idempotence=true,消费者结合事务提交 Offset。 - 监控 Offset:定期检查消费者组的 Offset 状态,及时修复滞后。
-
常见错误处理:
- 连接失败:检查
bootstrap.servers配置、防火墙设置。 - 消费者组不平衡:使用
partition.assignment.strategy=roundrobin优化分配。 - 资源不足:监控集群指标(如磁盘使用率),使用工具(如 Prometheus + Grafana)预警。
- 连接失败:检查
通过这些方案,可提升 Kafka 系统的健壮性。实践中,参考官方文档和社区最佳实践是关键。
总结
Apache Kafka 是一个强大的分布式流处理平台,原理基于分区、副本和消费者组机制,确保高吞吐和可靠性。使用指南覆盖了从基础设置到代码实现,问题解决方案针对常见痛点提供了实用方法。掌握这些内容,您可高效构建实时数据处理系统,如微服务集成或大数据管道。
思维导图
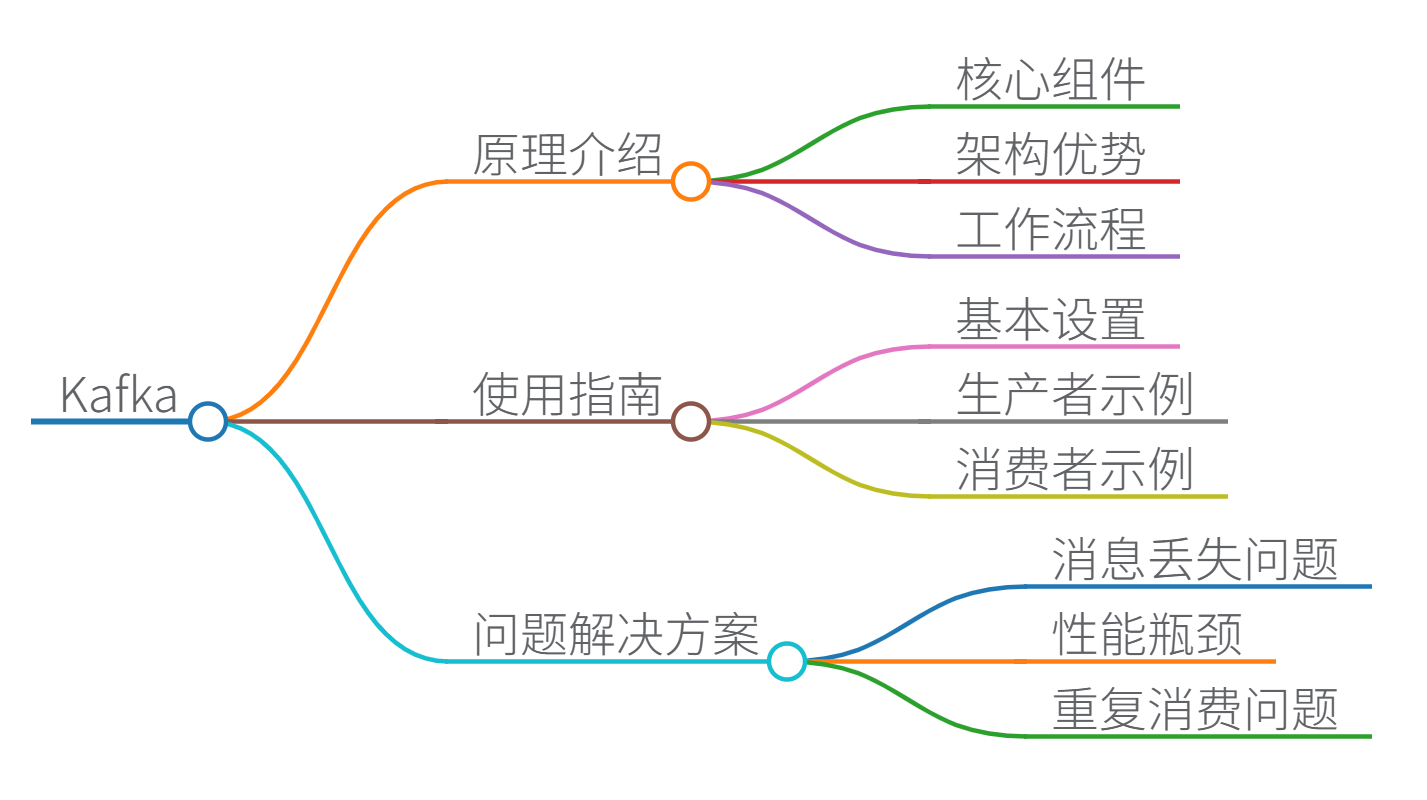
Apache Kafka 全面技术解析
一、技术原理与数据结构
-
分布式日志存储
-
数据结构:
- 分区(Partition):Topic 的物理分片,每个分区是有序不可变的日志序列
- 分段存储(Segment):
.log // 实际消息数据 .index // 稀疏偏移量索引(内存映射加速访问) .timeindex // 时间戳索引(用于时间范围查询) - 索引机制:
- 使用**内存映射文件(MMAP)**实现 O(1)O(1)O(1) 复杂度偏移量定位
- 索引文件仅存储部分偏移量,通过二分查找 + 顺序扫描定位消息
-
写入原理:
Producer→批量压缩Page Cache→异步刷盘磁盘 \text{Producer} \xrightarrow{\text{批量压缩}} \text{Page Cache} \xrightarrow{\text{异步刷盘}} \text{磁盘} Producer批量压缩Page Cache异步刷盘磁盘- 利用顺序磁盘I/O提升性能(追加写入速度 ≈ 内存写入)
-
-
副本同步算法
- ISR(In-Sync Replicas):
- Leader 维护与其数据同步的 Follower 列表
- 同步条件:
replica.lag.time.max.ms内完成最新消息同步
- 水位线机制:
- HW(High Watermark):所有 ISR 已复制的最大偏移量
- LEO(Log End Offset):当前日志最新偏移量
- 消费者只能读取 HW 之前的消息
- ISR(In-Sync Replicas):
-
高性能核心算法
技术 原理说明 性能影响 零拷贝(Zero-Copy) sendfile()系统调用实现 Page Cache → 网卡直接传输减少 60% CPU 开销 批量压缩 生产者端 LZ4/Snappy 压缩,减少网络传输量 吞吐量提升 5x 请求管道化 异步批量发送请求,避免等待单个 ACK 降低网络延迟
二、核心组件功能
| 组件 | 核心功能 | 关键配置参数 |
|---|---|---|
| Producer | 消息分区路由(Key Hash/Round Robin)、批量发送、重试机制 | acks, compression.type |
| Consumer | 消费组负载均衡、Offset 提交、分区再平衡(Rebalance) | group.id, auto.offset.reset |
| Broker | 分区副本管理、请求路由、日志清理(基于时间/大小) | log.retention.hours, num.replicas |
| Controller | 集群元数据管理(KRaft 模式替代 ZooKeeper) | controller.quorum.voters |
三、优缺点分析
| 优势 | 局限性 |
|---|---|
| ▶ 吞吐量可达百万级消息/秒 | ✘ 消息延迟通常 >10ms |
| ▶ 数据持久化(磁盘存储) | ✘ 分区数过多影响 ZooKeeper |
| ▶ 水平扩展性强(动态扩分区) | ✘ 运维复杂度高 |
四、应用场景
- 实时数据管道
- 事件溯源:存储用户行为序列,支持状态重建
- 微服务解耦:服务间通过 Topic 异步通信
五、优化方法
- 生产者优化:
batch.size=1MB(增大批次)linger.ms=50(适当延迟提升吞吐)compression.type=lz4(高效压缩)
- 消费者优化:
max.poll.records=500(单次拉取更多消息)- 分区数 ≥ 消费者线程数
- 手动提交 Offset(避免重复消费)
- Broker 优化:
num.io.threads=16(匹配 CPU 核心数)log.flush.interval.messages=10000(批量刷盘)
六、Java 代码示例
1. 生产者(带异步回调)
import org.apache.kafka.clients.producer.*;
public class AsyncProducer {
public static void main(String[] args) {
// 1. 配置生产者参数
Properties props = new Properties();
props.put("bootstrap.servers", "kafka1:9092"); // Broker地址
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("compression.type", "snappy"); // 启用Snappy压缩
props.put("batch.size", 16384); // 16KB批处理大小
props.put("linger.ms", 10); // 等待10ms组批
// 2. 创建生产者实例
Producer<String, String> producer = new KafkaProducer<>(props);
// 3. 发送消息(带异步回调)
for (int i = 0; i < 100; i++) {
ProducerRecord<String, String> record =
new ProducerRecord<>("orders", "key-" + i, "value-" + i);
producer.send(record, (metadata, ex) -> {
if (ex != null) {
System.err.println("发送失败: " + ex.getMessage());
} else {
System.out.printf(
"消息发送成功! topic=%s, partition=%d, offset=%d\n",
metadata.topic(), metadata.partition(), metadata.offset()
);
}
});
}
// 4. 关闭生产者(会等待未完成请求)
producer.close();
}
}
2. 消费者(手动提交 Offset)
import org.apache.kafka.clients.consumer.*;
import java.time.Duration;
import java.util.Collections;
public class ManualCommitConsumer {
public static void main(String[] args) {
// 1. 配置消费者参数
Properties props = new Properties();
props.put("bootstrap.servers", "kafka1:9092");
props.put("group.id", "order-processor"); // 消费者组ID
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("enable.auto.commit", "false"); // 关闭自动提交
props.put("max.poll.records", "500"); // 单次拉取500条消息
// 2. 创建消费者实例
Consumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Collections.singletonList("orders")); // 订阅Topic
try {
while (true) {
// 3. 拉取消息(超时时间100ms)
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
// 4. 处理消息
for (ConsumerRecord<String, String> record : records) {
System.out.printf(
"收到消息: topic=%s, partition=%d, offset=%d, key=%s, value=%s\n",
record.topic(), record.partition(), record.offset(), record.key(), record.value()
);
processMessage(record.value()); // 业务处理
}
// 5. 手动同步提交Offset(确保消息处理完成)
consumer.commitSync();
}
} finally {
consumer.close();
}
}
private static void processMessage(String message) {
// 实现幂等处理逻辑(如数据库唯一约束)
}
}
七、关键问题解决方案
- 消息顺序保证:
- 生产者设置
max.in.flight.requests.per.connection=1(单分区有序)
- 生产者设置
- 避免重复消费:
- 消费者手动提交 Offset + 业务层幂等处理
- 数据丢失防护:
- 生产者:
acks=all+retries=Integer.MAX_VALUE - Broker:
unclean.leader.election.enable=false(禁止落后副本成为Leader)
- 生产者:
通过以上机制,Kafka 在支付、监控等场景实现 99.999% 可靠性。
思维导图
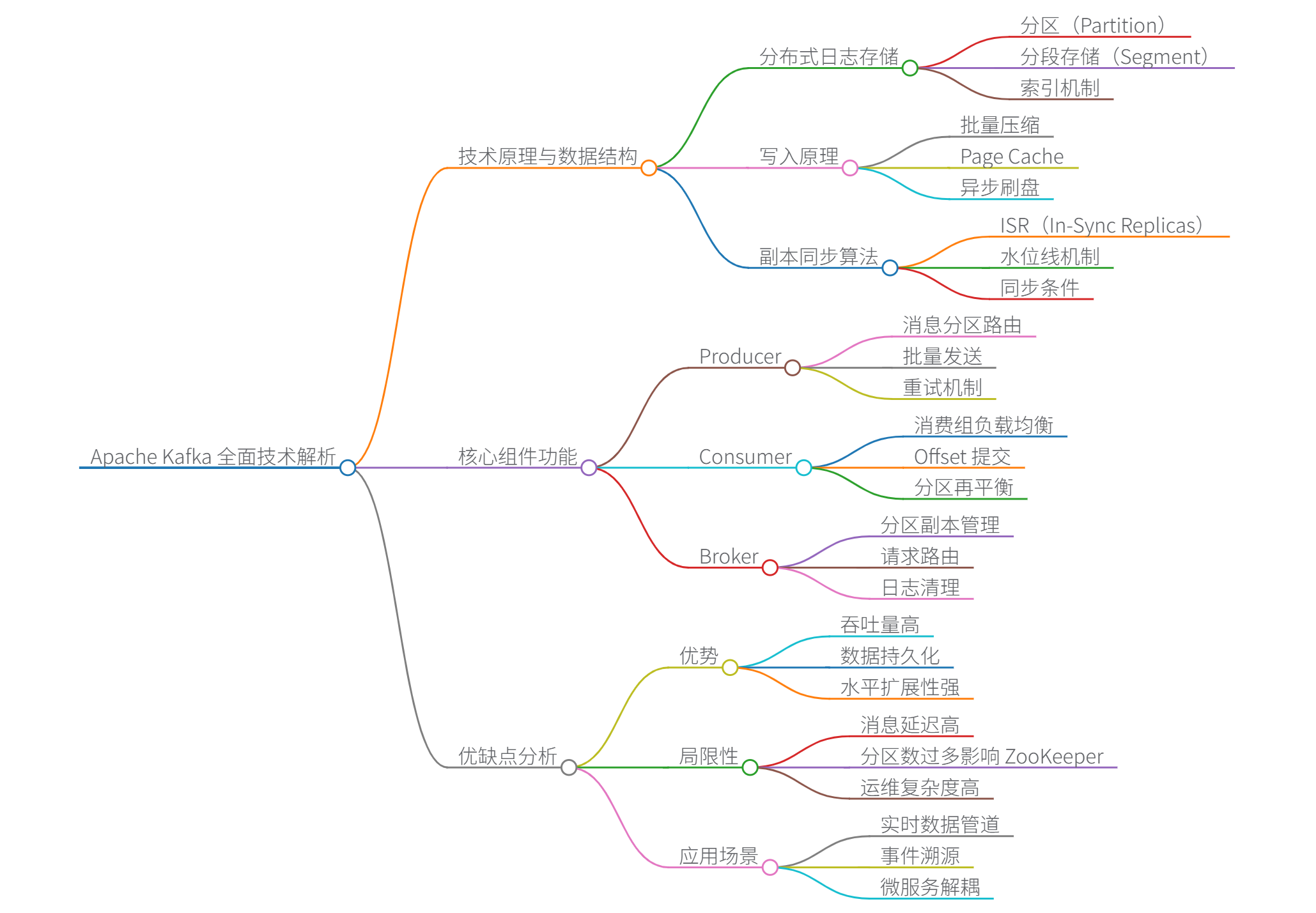
Kafka 内部机制详解
一、高吞吐量与低延迟原理
-
分区并行处理
Kafka 通过**分区(Partition)**实现并行读写。每个分区独立处理消息,生产者可同时向多个分区写入数据,消费者组内成员并行消费不同分区。- 吞吐量公式:$ \text{总吞吐} = \text{分区数} \times \text{单分区吞吐} $
- 分区数设计需平衡:过多会增大元数据开销,过少则限制并行度。
-
顺序磁盘 I/O
消息以**追加写(Append-Only Log)**方式写入磁盘,避免随机寻址。现代磁盘顺序读写速度可达 600MB/s(远超随机读写),利用 PageCache 减少磁盘访问次数。 -
零拷贝(Zero-Copy)技术
通过sendfile系统调用,数据直接从磁盘→网卡(无需经用户空间),减少 CPU 拷贝次数:传统:磁盘 → 内核缓冲区 → 用户缓冲区 → Socket 缓冲区 → 网卡 零拷贝:磁盘 → 内核缓冲区 → 网卡 -
批处理与压缩
- 生产者批量发送消息(
linger.ms控制等待时间) - 支持 Snappy/Gzip 压缩,减少网络传输量(压缩率 3-5 倍)。
- 生产者批量发送消息(
二、消费者组设计
-
拉取(Pull) vs 推送(Push)机制
机制 优势 劣势 Kafka 拉取 消费者按自身能力消费,避免过载 需轮询,可能增加延迟 RabbitMQ 推送 实时性高 消费者可能被压垮 -
消费者组(Consumer Group)
- Rebalance 机制:消费者加入/退出时,通过 Coordinator 重新分配分区(可能导致短暂停顿)。
- 偏移量(Offset)管理:
- 消费者提交 offset 到
__consumer_offsets主题 - 支持手动提交(
enable.auto.commit=false)避免重复消费
- 消费者提交 offset 到
- 快速定位消息:通过二分查找跳转到指定 offset(时间复杂度 O(logn)O(\log n)O(logn))。
三、数据可靠性保障
-
副本同步(ISR)
- ISR(In-Sync Replicas):与 Leader 保持同步的副本集合。
- 写入流程:
- ISR 优化:
min.insync.replicas控制最小同步副本数,保障数据不丢失。
-
ACK 机制
配置 可靠性 吞吐量 acks=0可能丢失 最高 acks=1Leader 落盘 中等 acks=allISR 全部落盘 最低
四、KRaft 模式与 ZooKeeper 替代
-
ZooKeeper 痛点
- 元数据存储在 ZooKeeper,频繁操作成瓶颈
- 控制器(Controller)故障切换慢(依赖 ZooKeeper 选举)
-
KRaft 改进
- Raft 共识算法:Kafka 集群自管理元数据,消除 ZooKeeper 依赖。
- Controller 故障切换:
- 性能提升:元数据操作吞吐量提升 5-10 倍,故障切换时间缩短 50%。
五、Kafka vs RabbitMQ 核心对比
| 维度 | Kafka | RabbitMQ |
|---|---|---|
| 架构 | 分布式日志(分区+副本) | 队列+交换机(AMQP 协议) |
| 吞吐量 | 百万级/秒(分区扩展) | 万级/秒 |
| 延迟 | 毫秒~秒级(批处理影响) | 微秒~毫秒级 |
| 消息回溯 | 支持(按 offset 消费) | 不支持(消费即删除) |
| 适用场景 | 日志流、实时分析、大数据集成 | 任务队列、复杂路由、延时消息 |
| 延迟队列 | 不适用(需外部实现) | 原生支持(死信队列+TTL) |
延迟队列不适用原因:Kafka 设计为顺序追加日志,不支持消息级 TTL(Time-To-Live),需通过外部工具(如 Redis)实现延迟投递。
六、分区设计最佳实践
-
分区数公式:
分区数=max(生产者吞吐量,消费者吞吐量)÷单分区吞吐 \text{分区数} = \max(\text{生产者吞吐量}, \text{消费者吞吐量}) \div \text{单分区吞吐} 分区数=max(生产者吞吐量,消费者吞吐量)÷单分区吞吐- 单分区吞吐参考值:HDD 磁盘 10MB/s,SSD 磁盘 50MB/s。
-
水平扩展步骤:
1. 监控分区负载(如 Lag 堆积) 2. 增加分区数(需重启或工具迁移) 3. 扩容消费者实例(自动 Rebalance)
#@## 性能优化总结
| 组件 | 优化项 | 效果 |
|---|---|---|
| 生产者 | compression.type=snappy | 减少 70% 网络流量 |
batch.size=64KB | 提升批量发送效率 | |
| Broker | num.replica.fetchers=3 | 加速副本同步 |
log.segment.bytes=1GB | 减少分段数量 | |
| 消费者 | fetch.min.bytes=1MB | 减少拉取次数 |
max.poll.records=500 | 单次拉取更多消息 |
图表说明:分区与吞吐量关系呈线性增长,但超过临界点(如单 Broker 100 分区)后因上下文切换导致性能下降,需监控
os::io_wait指标。
思维导图
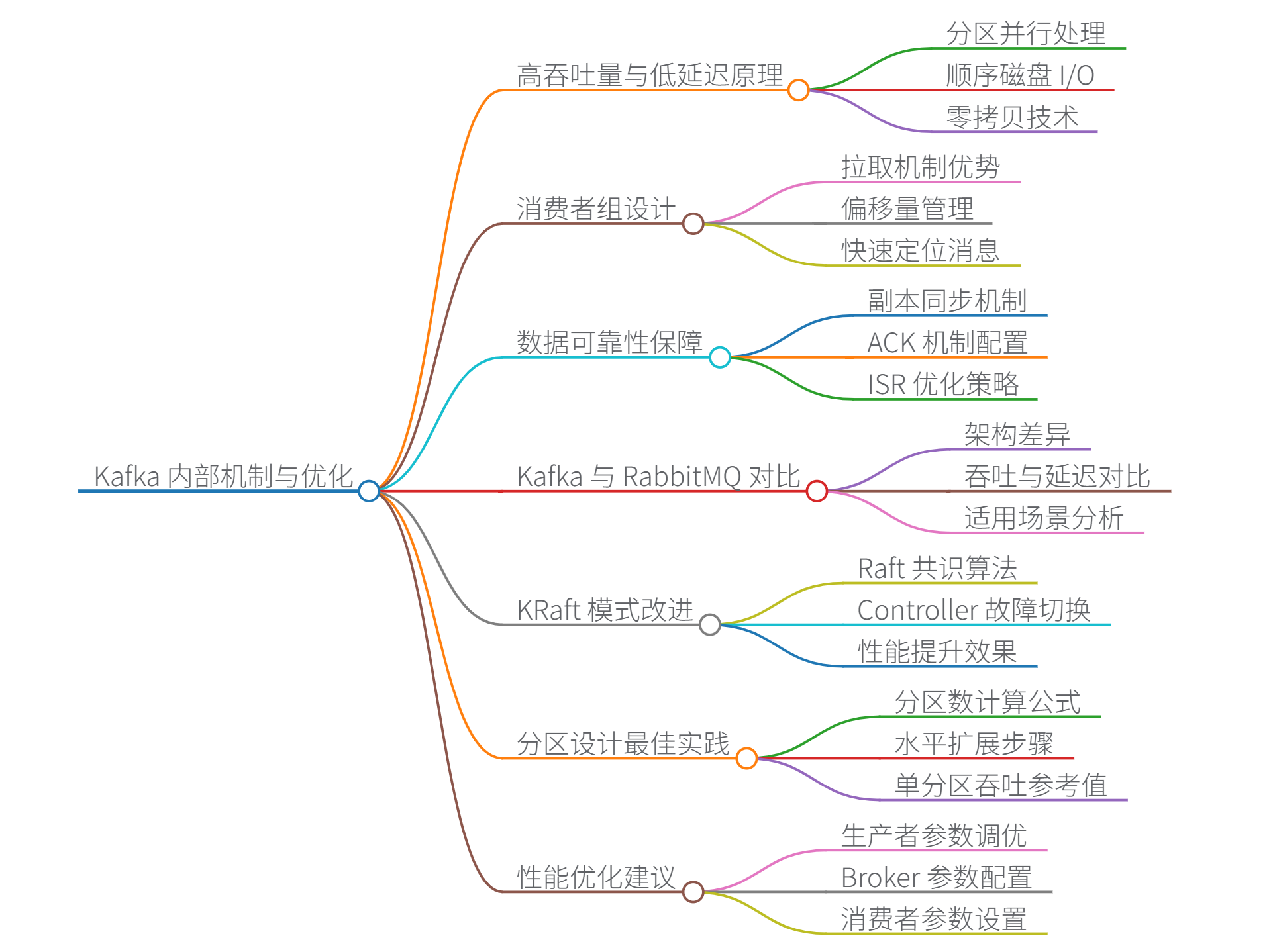

















 2288
2288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









