




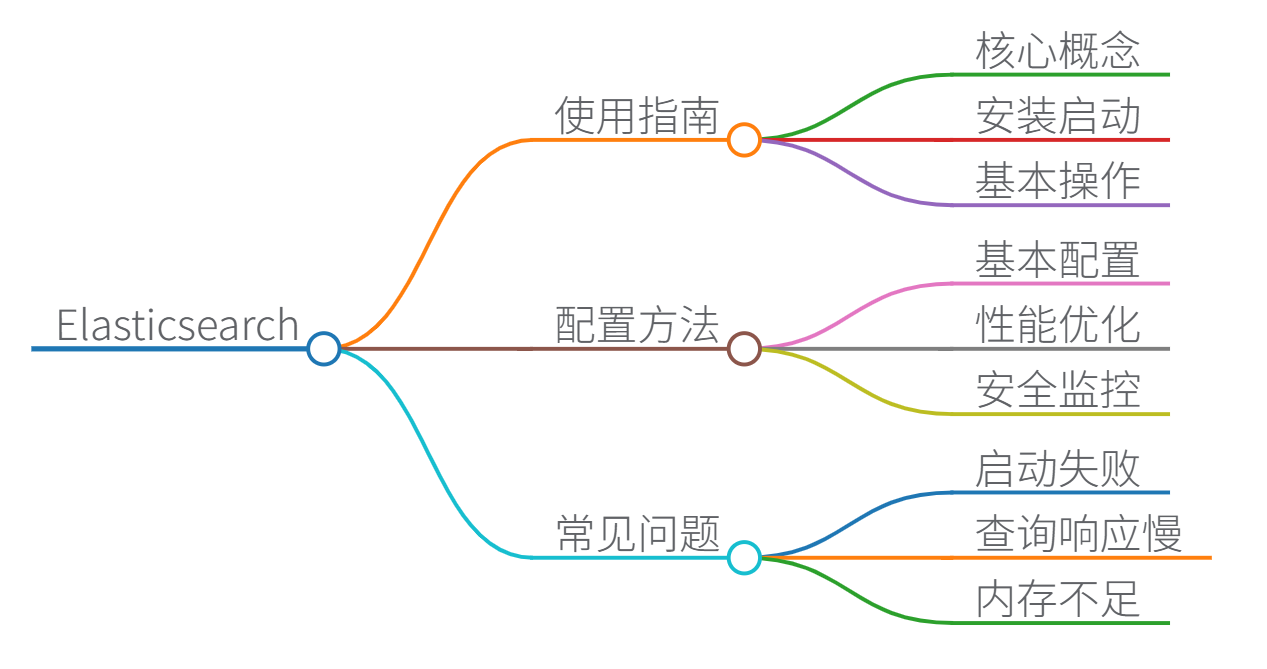
Elasticsearch 使用指南、配置、常见问题及解决方案
Elasticsearch 是一个开源的分布式搜索和分析引擎,基于 Apache Lucene 构建,广泛用于日志分析、全文搜索、实时数据分析等场景。以下内容基于 Elasticsearch 官方文档和社区最佳实践,确保真实可靠。我将分步介绍使用指南、配置方法和常见问题解决方案,帮助您快速上手和解决实际问题。
一、Elasticsearch 使用指南
Elasticsearch 的核心概念包括索引(Index)、文档(Document)、类型(Type,已弃用)、分片(Shard)和副本(Replica)。以下是基本使用步骤:
-
安装与启动:
- 下载 Elasticsearch 二进制包(如从 官网)。
- 解压后运行
bin/elasticsearch(Linux/macOS)或bin\elasticsearch.bat(Windows)。 - 验证安装:访问
http://localhost:9200,应返回 JSON 格式的集群信息。
-
基本操作:
- 创建索引:使用 REST API 创建索引,例如:
PUT /my_index { "settings": { "number_of_shards": 3, "number_of_replicas": 1 } } - 添加文档:插入数据到索引,例如:
POST /my_index/_doc/1 { "title": "Elasticsearch Guide", "content": "A comprehensive guide to Elasticsearch." } - 搜索文档:执行简单查询,例如:
GET /my_index/_search { "query": { "match": { "content": "guide" } } } - 聚合分析:进行数据统计,例如计算平均值:
GET /my_index/_search { "aggs": { "avg_score": { "avg": { "field": "score" } } } }
- 创建索引:使用 REST API 创建索引,例如:
-
高级功能:
- 全文搜索:支持模糊匹配、短语搜索等。
- 数据管道:使用 Kibana 或 Logstash 进行数据可视化。
- 安全配置:启用 X-Pack 插件实现认证和加密。
初学者可参考官方文档的 入门指南,确保从简单用例开始逐步实践。
二、Elasticsearch 配置
Elasticsearch 的核心配置文件是 elasticsearch.yml(位于 config/ 目录)。配置时需关注集群、性能和资源优化:
-
基本配置:
- 集群名称:确保所有节点使用相同集群名,避免节点加入错误集群。
cluster.name: my-elasticsearch-cluster - 节点名称:自定义节点标识,便于监控。
node.name: node-1 - 网络设置:绑定 IP 和端口,例如:
network.host: 0.0.0.0 http.port: 9200
- 集群名称:确保所有节点使用相同集群名,避免节点加入错误集群。
-
性能优化配置:
- 内存管理:调整 JVM 堆大小(建议不超过物理内存的 50%),在
jvm.options文件中设置:-Xms4g -Xmx4g - 分片与副本:根据数据量设置分片数(避免过多分片导致性能下降),例如:
index.number_of_shards: 5 index.number_of_replicas: 1 - 线程池调优:在
elasticsearch.yml中调整线程池大小,防止高并发时阻塞。thread_pool.search.size: 20 thread_pool.search.queue_size: 1000
- 内存管理:调整 JVM 堆大小(建议不超过物理内存的 50%),在
-
安全与监控:
- 启用安全:安装 X-Pack 后,配置 TLS/SSL 和用户角色。
- 监控工具:使用 Elasticsearch 自带的监控 API 或集成 Prometheus,定期检查集群健康:
GET /_cluster/health - 日志配置:在
log4j2.properties中设置日志级别,便于调试。
性能调优需结合具体用例,例如高写入场景需优化刷新间隔(index.refresh_interval)。参考官方 配置文档 进行详细调整。
三、常见问题及解决方案
Elasticsearch 使用中常见问题包括启动失败、查询慢和资源不足。以下是基于社区经验的解决方案:
-
启动失败:
- 问题:节点无法启动,日志显示端口冲突或文件权限错误。
- 解决步骤:
- 检查端口占用:使用
netstat -tuln | grep 9200确认端口空闲。 - 修复文件权限:确保
data/和logs/目录有写入权限(例如chown -R elasticsearch:elasticsearch /path/to/elasticsearch)。 - 验证 JVM 版本:确保使用 Java 11 或更高版本(运行
java -version检查)。 - 参考错误日志:查看
logs/elasticsearch.log定位具体原因。
- 检查端口占用:使用
-
查询响应慢:
- 问题:搜索请求耗时过长,影响用户体验。
- 解决步骤:
- 优化查询:避免复杂聚合,使用
filter代替query减少评分计算。例如,将match查询改为term查询。 - 调整索引设置:增加刷新间隔(
index.refresh_interval: "30s")或使用批量插入(Bulk API)。 - 监控资源:使用
GET /_nodes/stats检查 CPU 和内存使用。如果 JVM 堆内存不足,增加-Xmx值,并监控 GC 行为(如通过jstat -gc <pid>)。 - 分片管理:避免热点分片,通过
_shard_storesAPI 重新分配分片。 - 插件优化:如使用类似 Elastiknn 的插件时,调整算法参数(例如索引时的近似搜索设置)。
- 优化查询:避免复杂聚合,使用
-
内存不足或 OOM 错误:
- 问题:节点频繁崩溃,日志显示
OutOfMemoryError。 - 解决步骤:
- 增加堆内存:在
jvm.options中提升-Xmx(但不超过物理内存的 50%)。 - 减少字段数据缓存:在
elasticsearch.yml设置indices.fielddata.cache.size: 30%。 - 优化映射:禁用不必要的字段索引(
"index": false),并使用keyword类型代替text节省内存。 - 集群扩展:添加更多节点或升级硬件。
- 增加堆内存:在
- 问题:节点频繁崩溃,日志显示
-
其他常见问题:
- 连接超时:检查防火墙设置,确保节点间通信端口(默认为 9300)开放。
- 数据不一致:使用
_cat/indices?v检查副本状态,并通过_cluster/rerouteAPI 手动修复。 - 插件兼容性:更新插件或 Elasticsearch 版本至最新,避免冲突。
实施解决方案时,建议先在测试环境验证,再应用到生产环境。定期备份快照(使用 Snapshot API)是防止数据丢失的最佳实践。更多问题可查阅 Elasticsearch 社区 论坛。
思维导图
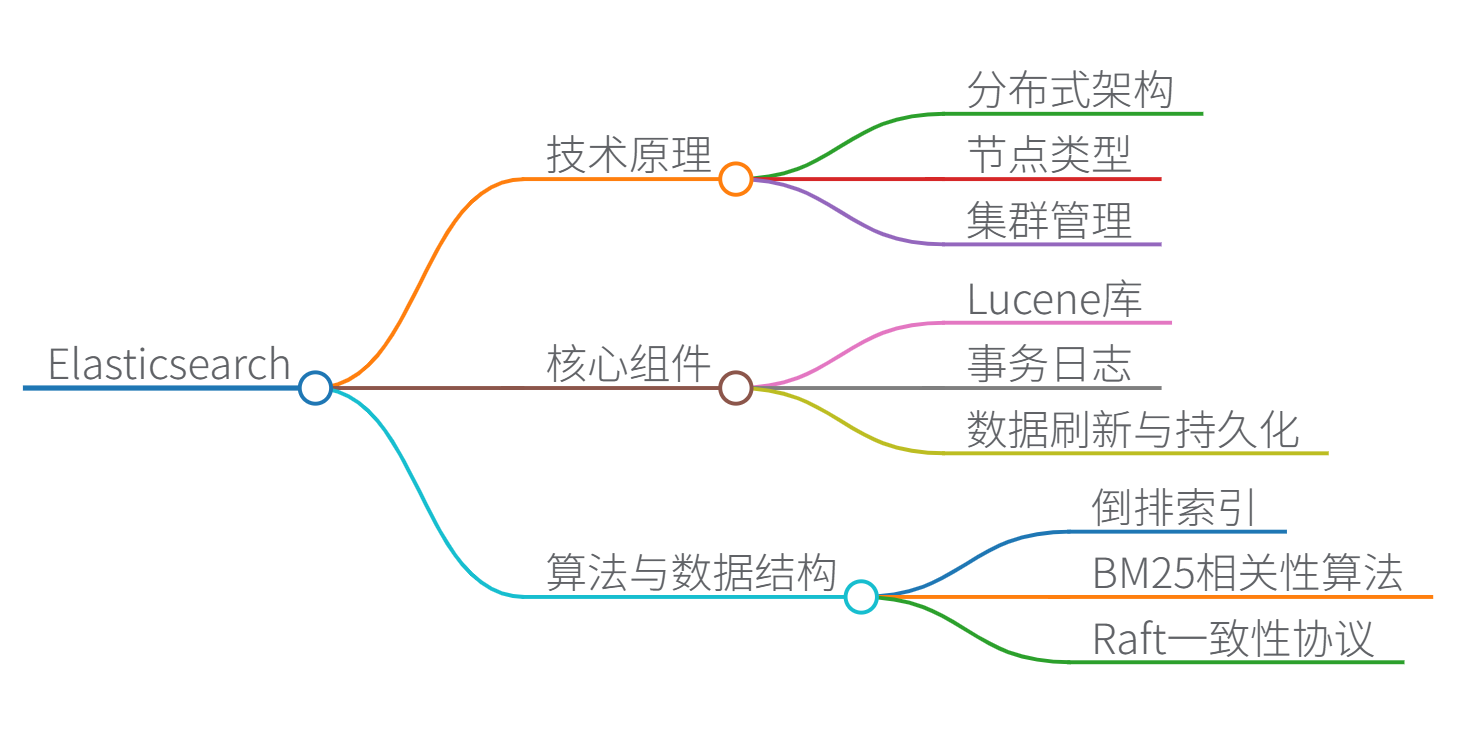
Elasticsearch 技术原理、算法、数据结构与核心组件详解
一、技术原理与核心组件功能
-
分布式架构
Elasticsearch 采用去中心化的分布式架构,包含三种节点类型:- 协调节点:接收请求并路由到数据节点
- 数据节点:存储分片(Shard)和执行读写操作
- 主节点:管理集群状态和分片分配(基于Raft算法实现选举)
-
核心组件功能
组件 功能描述 Lucene 底层搜索引擎库,提供倒排索引、分词等核心功能 Translog 事务日志(Write-Ahead Log),保证写入操作的原子性和持久性 Refresh 将内存缓冲区数据刷入文件系统缓存(默认1秒) Flush 将文件系统缓存持久化到磁盘(默认30分钟) 分片(Shard) 数据水平分割的基本单元(主分片+副本分片) -
数据模型
- 索引(Index):逻辑数据容器(类似数据库)
- 文档(Document):JSON格式的基本数据单元
- 映射(Mapping):定义字段类型和索引规则
{ "properties": { "title": {"type": "text", "analyzer": "ik_max_word"}, "price": {"type": "double", "doc_values": true} // 启用列式存储 } }
二、核心算法与数据结构
-
倒排索引(Inverted Index)
- 数据结构:
词项 -> [文档ID, 位置信息] - 使用FST(有限状态转换器)压缩存储词典
// 伪代码:倒排索引结构 class InvertedIndex { Map<String, PostingList> termToPostings; class PostingList { int docId; // 文档ID int[] positions; // 词项在文档中的位置 int termFrequency; // 词频 } } - 数据结构:
-
相关性评分算法(BM25)
改进的TF-IDF算法,公式:
score ( D , Q ) = ∑ i = 1 n IDF ( q i ) ⋅ f ( q i , D ) ⋅ ( k 1 + 1 ) f ( q i , D ) + k 1 ⋅ ( 1 − b + b ⋅ ∣ D ∣ avgdl ) \text{score}(D,Q) = \sum_{i=1}^{n} \text{IDF}(q_i) \cdot \frac{f(q_i, D) \cdot (k_1 + 1)}{f(q_i, D) + k_1 \cdot (1 - b + b \cdot \frac{|D|}{\text{avgdl}})} score(D,Q)=i=1∑nIDF(qi)⋅f(qi,D)+k1⋅(1−b+b⋅avgdl∣D∣)f(qi,D)⋅(k1+1)
参数默认值: k 1 = 1.2 k_1=1.2 k1=1.2(词频饱和度), b = 0.75 b=0.75 b=0.75(文档长度归一化) -
分布式一致性协议
- 使用 Raft 算法 实现主节点选举
- 写入流程:协调节点 → 主分片 → 副本分片(同步写入)
三、优缺点分析
| 优点 | 缺点 |
|---|---|
| 实时搜索(毫秒级响应) | 写入吞吐量受分片数量限制 |
| 水平扩展性强(支持PB级数据) | 深度分页性能差(from/size) |
| 支持全文/地理/向量搜索 | 强一致性配置影响性能 |
| 完善的生态系统(Kibana等) | 资源消耗较大(JVM堆内存) |
四、Java代码示例(带中文注释)
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.builder.SearchSourceBuilder;
// 1. 创建文档
public void indexDocument(RestHighLevelClient client) throws Exception {
IndexRequest request = new IndexRequest("products"); // 索引名称
String json = "{\"name\":\"智能手机\",\"price\":3999,\"brand\":\"小米\"}";
request.source(json, XContentType.JSON); // JSON数据源
request.id("1"); // 文档ID(可选)
client.index(request, RequestOptions.DEFAULT);
}
// 2. 布尔查询
public void boolQuery(RestHighLevelClient client) throws Exception {
SearchRequest request = new SearchRequest("products");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
// 构建布尔查询:必须包含"手机"且价格在3000-5000之间
sourceBuilder.query(QueryBuilders.boolQuery()
.must(QueryBuilders.matchQuery("name", "手机")) // 全文匹配
.filter(QueryBuilders.rangeQuery("price").gte(3000).lte(5000)) // 范围过滤
);
request.source(sourceBuilder);
client.search(request, RequestOptions.DEFAULT);
}
// 3. 聚合分析:按品牌分组统计平均价格
public void aggregationQuery(RestHighLevelClient client) throws Exception {
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.aggregation(
AggregationBuilders.terms("brands").field("brand") // 按品牌分组
.subAggregation(AggregationBuilders.avg("avg_price").field("price")) // 子聚合
);
// ...(发送请求)
}
五、关键性能优化
-
写入优化:
// 批量写入(Bulk API) BulkRequest request = new BulkRequest(); request.add(new IndexRequest("logs").source(...)); request.add(new IndexRequest("logs").source(...)); client.bulk(request, RequestOptions.DEFAULT);- 调优参数:
refresh_interval = "30s",number_of_replicas = 0(写入期间)
- 调优参数:
-
查询优化:
- 使用
filter代替query避免评分计算 - 深度分页改用
search_after参数 - 冷数据使用
forcemerge合并段文件
- 使用
-
数据结构优化:
- 数值类型启用
doc_values(列式存储) - 避免使用
dynamic: true(动态映射) - 大文本字段设为
index: false
- 数值类型启用
思维导图
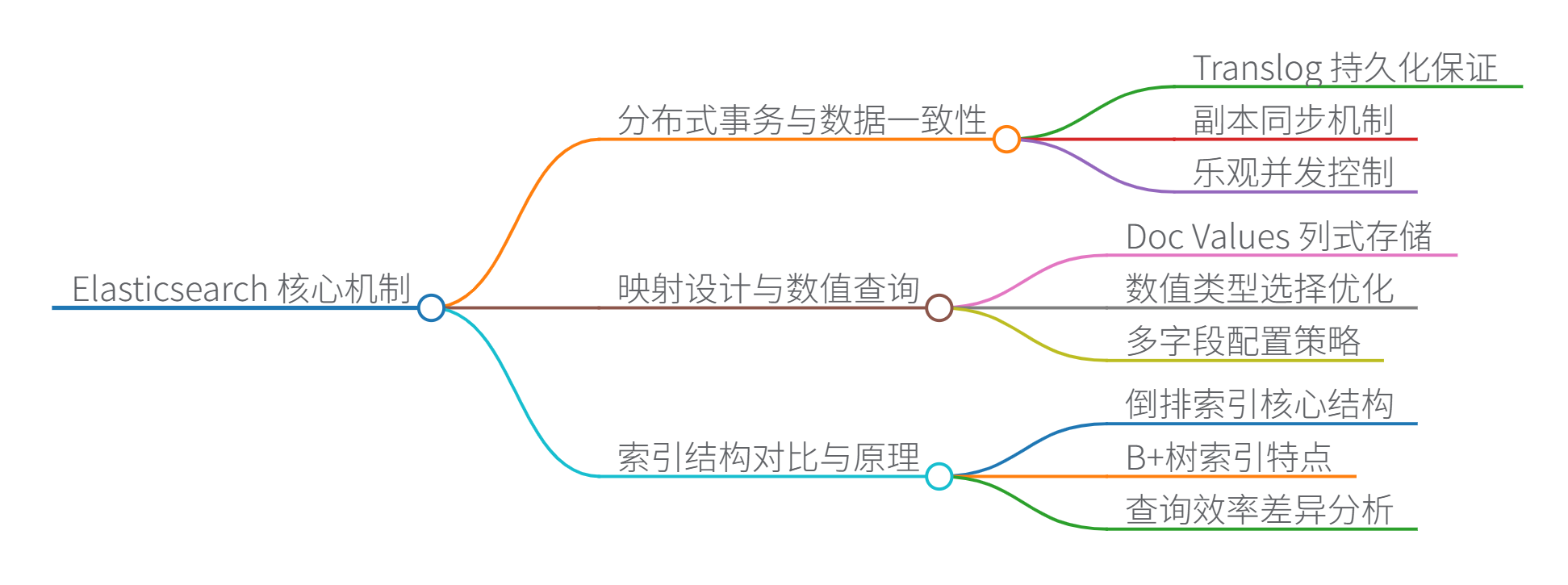
Elasticsearch 的核心机制
好的,我们来逐一解析 Elasticsearch 的核心机制,包括分布式事务、映射设计、索引结构区别、BM25算法、分片副本以及全文检索支持。
1. Elasticsearch 分布式事务如何保证数据一致性?
Elasticsearch 本身不提供传统数据库(如 MySQL)那样的 ACID 强一致性分布式事务。它更侧重于高可用性、可扩展性和最终一致性,这是其分布式、近实时搜索和分析引擎的设计目标所决定的。它通过以下机制来保证数据的可靠性和最终一致性:
- 写入流程与持久化保证:
- Translog (事务日志): 当文档被索引或更新时,首先会被写入内存缓冲区 (
Indexing Buffer) 并同时追加写入到磁盘上的Translog文件中。Translog提供了持久化保证,确保即使节点崩溃,已确认的写入操作也能在重启后恢复。 - Refresh: 内存缓冲区中的数据会定期(默认 1 秒,可配置)通过
refresh操作写入到新的 Lucene 段(Segment)中。此时数据变得可搜索(近实时),但新段还在操作系统的文件缓存中,尚未完全刷盘(fsync)。 - Flush: 当
Translog达到一定大小或时间阈值时,会触发flush操作:- 将内存缓冲区中的所有文档写入新的 Lucene 段。
- 调用
fsync将新段强制持久化到磁盘。 - 清空(截断)旧的
Translog(因为其内容已安全持久化到段文件中)。
- Translog (事务日志): 当文档被索引或更新时,首先会被写入内存缓冲区 (
- 副本同步 (Replication):
- ES 索引通常配置多个分片副本(Replica Shards),分布在不同的节点上。
- 写入操作(索引、更新、删除)首先发送到主分片(Primary Shard)。
- 主分片负责将操作同步到所有可用的副本分片。
- 只有当指定数量的副本分片(由
wait_for_active_shards参数控制,默认是主分片和副本都成功才算quorum)都成功执行了操作后,主分片才会向客户端返回成功确认。这确保了即使部分节点故障,数据也不会丢失(只要满足wait_for_active_shards条件)。 - 副本分片通过拉取主分片的
Translog操作来追赶进度,保持数据同步(最终一致性)。
- 乐观并发控制:
- ES 使用版本号(
_version)实现乐观锁。每次文档更新,其_version都会递增。 - 客户端在更新或删除文档时可以指定预期的
_version(或if_seq_no/if_primary_term)。如果实际版本号不匹配(说明文档已被其他操作修改),操作会失败(返回 409 Conflict),由应用层决定如何处理(重试、放弃等)。这解决了并发写入冲突问题。
- ES 使用版本号(
- 最终一致性:
- 由于
refresh间隔、副本同步延迟等因素,在写入成功后的短暂时间内(通常是毫秒级),不同副本上的数据可能不一致,或者新写入的数据可能还不可见。 - 通过等待
refresh(?refresh=true)或使用GET请求(默认会等待相关分片刷新)可以强制刷新使新文档立即可见。 - 副本同步保证了在无故障和网络稳定的情况下,数据最终会在所有副本上达成一致。
- 由于
总结: ES 通过 Translog 保证单分片写入的持久性,通过同步副本写入和版本控制保证主副本间数据的一致性和冲突解决,实现了高可靠性和最终一致性。它牺牲了强一致性(需要分布式锁、两阶段提交等复杂机制,影响性能)来换取高吞吐、低延迟和水平扩展能力。对于需要强一致性的事务,通常需要在应用层实现补偿机制,或者将 ES 作为查询引擎,由上游的强一致性数据库(如 PostgreSQL)处理事务性写入。
2. 映射 (Mapping) 设计实现高效数值范围查询
数值范围查询(如 price:[100 TO 200])在 ES 中的高效性主要依赖于其底层存储结构和索引方式:
- Doc Values (核心):
- 这是 ES 高效聚合和排序的基石,对范围查询也至关重要。
- 默认情况下,除了
text和annotated_text类型,几乎所有字段类型(包括keyword,numeric-long,integer,short,byte,double,float,half_float,scaled_float,date,boolean,ip,geo_point)都会启用doc_values。 doc_values是一种列式存储结构。它将文档中某个字段的所有值按文档 ID (_doc) 顺序存储在一起。想象一个表格:- 列:字段名(如
price)。 - 行:文档 ID (
_doc)。 - 单元格:该文档在该字段的值。
- 列:字段名(如
- 这种结构使得 ES 可以非常高效地:
- 顺序扫描整列数据(这正是范围查询
price > 100的本质)。 - 进行聚合(如
min,max,avg,sum,histogram)。 - 对字段排序(
sort)。
- 顺序扫描整列数据(这正是范围查询
- 存储在磁盘上,但会被 OS 缓存到内存中加速访问。
- 倒排索引的局限性:
- 倒排索引(Inverted Index)是 ES 全文搜索的核心。它将
Term映射到包含该Term的文档列表 (Postings List)。 - 对于精确匹配(
term,terms查询)和文本搜索极其高效。 - 但对于数值范围查询,倒排索引效率较低:
- 数值被索引为独立的
Term(例如,price:100,price:101, …,price:200)。 - 范围查询
price:[100 TO 200]需要查找这 101 个Term对应的Postings List,然后合并(OR)这些列表。当范围很大时,合并大量Postings List开销显著。
- 数值被索引为独立的
- 倒排索引(Inverted Index)是 ES 全文搜索的核心。它将
- 优化映射设计:
- 使用合适的数值类型: 选择能满足需求的最小类型(如
integer而非long,float而非double)。更小的类型占用更少的磁盘和内存空间(doc_values更紧凑),提升扫描速度。 - 避免将数值索引为
text或keyword: 除非你确实需要对这些数值进行精确匹配(term)或聚合(terms),否则不要将它们映射为text或keyword。将它们映射为数值类型才能利用高效的doc_values进行范围查询和数值聚合。如果同时需要精确匹配和范围查询/聚合,可以使用multi-fields:
- 使用合适的数值类型: 选择能满足需求的最小类型(如
PUT my_index
{
"mappings": {
"properties": {
"product_id": {
"type": "keyword", // 用于精确匹配、聚合
"fields": {
"numeric": {
"type": "integer" // 用于范围查询、数值聚合
}
}
}
}
}
}
// 查询时使用 product_id.numeric 进行范围查询
- 利用
date类型: 对于时间戳,总是使用date类型。它本质上是一个long类型的数值(存储毫秒/微秒/纳秒时间戳),其doc_values对时间范围查询(rangeon@timestamp)极其高效,并且 ES 提供了丰富的日期格式化、计算和聚合功能。 - 考虑
scaled_float: 对于需要高精度的小数(如价格、指标),scaled_float通过指定一个scaling_factor(如 100)将浮点数转换为长整型存储,在保持精度的同时利用整型doc_values的高效性。例如,价格19.99存储为1999(scaling_factor=100)。查询时需要做相应转换(gte: 1000对应10.00)。
总结: ES 高效数值范围查询的核心在于列式存储的 doc_values。通过将数值字段映射为合适的数值类型(而不是 text/keyword),确保 doc_values 被启用,并利用 multi-fields 解决同时需要精确匹配和范围查询的场景,可以显著提升性能。
3. 倒排索引与 B+树索引区别
| 特性 | 倒排索引 (Inverted Index - ES/Lucene) | B+树索引 (B+ Tree - MySQL等关系型数据库) |
|---|---|---|
| 核心结构 | Term -> Sorted List of Document IDs (Postings List) + Term Dictionary (查找Term) + Postings Lists (文档列表) + 可选: Term Frequency, Positions, Offsets | 多叉平衡树 - 叶子节点:包含有序的键值对(键是索引列值,值是主键值或行数据指针) - 非叶节点:索引项(键+指针) |
| 主要目的 | 全文搜索:快速找到包含特定词语/短语的所有文档。 高效处理 OR 条件。 | 精确匹配 & 范围查询:快速定位特定值或有序范围内的行。 高效处理 ORDER BY + LIMIT。 |
| 优势查询 | - term / terms (精确匹配)- match (全文搜索)- match_phrase (短语搜索)- 布尔组合 ( OR 高效)- 相关性评分 (TF-IDF, BM25) | - = (精确匹配)- >/</BETWEEN (范围查询)- ORDER BY ... LIMIT N (排序+分页)- MIN()/MAX() (极值查询) |
| 数据组织 | 按词(Term)组织:索引指向包含该词的文档。 | 按值(Value)组织:索引本身按键值有序存储。 |
| 存储方式 | 通常更紧凑(特别是压缩后),但包含大量元数据(位置等)。 | 结构相对固定,叶子节点链表便于范围扫描。 |
| 写入开销 | 较高: - 文档需分词(文本) - 需更新多个 Term 的 Postings List- 段合并开销 | 相对较低: - 插入/删除需维护树结构平衡 - 页分裂/合并 |
| 更新效率 | 较低效:Lucene 段是不可变的。更新=标记旧文档删除+添加新文档。删除需合并段才能真正回收空间。 | 相对高效:可直接在 B+树中找到记录位置进行原地更新(若长度不变)或删除/插入。 |
| 范围查询 | 效率较低:需要遍历多个 Term 的 Postings List 并合并。数值范围需依赖 doc_values。 | 非常高效:叶子节点链表结构,找到起点后顺序扫描即可。 |
| 典型应用 | 搜索引擎 (Elasticsearch, Solr),全文检索,日志分析,非结构化/半结构化数据。 | 关系型数据库 (MySQL, PostgreSQL, Oracle),OLTP 系统,需要强一致性和事务支持的结构化数据。 |
| 引用关联 | 对应 “Elasticsearch对应机制” 中的各种倒排索引(_id, 字段, 文本)。 | 对应 “MySQL支持” 中的聚簇索引(主键)、二级索引(普通索引)。 |
核心思想差异:
- 倒排索引: “哪些文档包含这个词?” - 解决从词找文档的问题,是全文检索的基石。
- B+树索引: “这个值(或这个范围内的值)在哪几行?” - 解决按值(或有序范围)快速定位数据行的问题,是数据库高效查询和排序的基石。
4. BM25 算法改进 TF-IDF
BM25 (Best Matching 25) 是信息检索领域最先进和广泛使用的相关性评分算法之一,它是在经典的 TF-IDF 基础上发展而来,解决了 TF-IDF 的一些主要缺陷:
-
TF-IDF 基础回顾:
- TF (Term Frequency - 词频):
‘
t
f
(
t
,
d
)
‘
`tf(t, d)`
‘tf(t,d)‘ - 词项
t在文档d中出现的次数。基本思想:一个词在文档中出现次数越多,该文档与该词的相关性可能越高。但简单计数容易导致长文档占优(词出现次数天然多)。 - IDF (Inverse Document Frequency - 逆文档频率):
‘
i
d
f
(
t
)
=
log
N
n
t
+
1
‘
`idf(t) = \log \frac{N}{n_t + 1}`
‘idf(t)=lognt+1N‘ -
N是文档总数,n_t是包含词项t的文档数。基本思想:一个词在所有文档中出现的越少(n_t越小,idf越大),它区分不同文档的能力越强,越重要。 - TF-IDF Score:
‘
s
c
o
r
e
(
t
,
d
)
=
t
f
(
t
,
d
)
∗
i
d
f
(
t
)
‘
`score(t, d) = tf(t, d) * idf(t)`
‘score(t,d)=tf(t,d)∗idf(t)‘ - 文档
d对查询词t的得分。查询包含多个词时,通常是各查询词 TF-IDF 得分之和: ‘ s c o r e ( q , d ) = ∑ t ∈ q t f ( t , d ) ∗ i d f ( t ) ‘ `score(q, d) = \sum_{t \in q} tf(t, d) * idf(t)` ‘score(q,d)=∑t∈qtf(t,d)∗idf(t)‘。
- TF (Term Frequency - 词频):
‘
t
f
(
t
,
d
)
‘
`tf(t, d)`
‘tf(t,d)‘ - 词项
-
TF-IDF 的主要问题:
- 文档长度未归一化: 长文档更容易积累高 TF 值,即使它们可能只是泛泛而谈(包含很多不重要的高频词)。短文档即使高度相关也可能得分偏低。
- TF 增长线性: TF 值线性增长,但词频对相关性的贡献不是线性的。出现 100 次并不比出现 20 次相关 5 倍。存在饱和效应。
- IDF 对常见词惩罚不足: 标准 IDF 对极其常见的词(如 “the”, “and”)的惩罚可能不够彻底。
-
BM25 的改进:
BM25 引入了几项关键改进,形成了更健壮、效果更好的评分公式:-
饱和 TF (Saturation) - 控制词频过度影响:
- 使用一个非线性函数替代原始的
tf。当词频tf很高时,其增长对得分的贡献会逐渐减弱(饱和)。 - 公式核心部分:
‘
(
k
1
+
1
)
∗
t
f
(
t
,
d
)
k
1
∗
(
1
−
b
+
b
∗
∣
d
∣
a
v
g
d
l
)
+
t
f
(
t
,
d
)
‘
`\frac{(k_1 + 1) * tf(t, d)}{k_1 * (1 - b + b * \frac{|d|}{avgdl}) + tf(t, d)}`
‘k1∗(1−b+b∗avgdl∣d∣)+tf(t,d)(k1+1)∗tf(t,d)‘
-
‘
t
f
(
t
,
d
)
‘
`tf(t, d)`
‘tf(t,d)‘: 词
t在文档d中的词频。 -
‘
∣
d
∣
‘
`|d|`
‘∣d∣‘: 文档
d的长度(通常是字段的 token 数)。 - ‘ a v g d l ‘ `avgdl` ‘avgdl‘: 整个索引中所有文档的平均长度。
-
‘
k
1
‘
`k_1`
‘k1‘: 控制词频饱和度的调节参数。
k_1通常在 [1.2, 2.0] 之间。k_1 = 0时完全忽略 TF;k_1越大,TF 影响越大,饱和越慢。 -
‘
b
‘
`b`
‘b‘: 文档长度归一化因子,取值在
[0, 1]之间。b = 0时完全不做长度归一化;b = 1时做完全归一化;通常取0.75。文档d的长度|d|相对于平均长度avgdl越长,分母中的归一化项 ‘ ( 1 − b + b ∗ ∣ d ∣ a v g d l ) ‘ `(1 - b + b * \frac{|d|}{avgdl})` ‘(1−b+b∗avgdl∣d∣)‘ 越大,从而抑制了长文档的得分。
-
‘
t
f
(
t
,
d
)
‘
`tf(t, d)`
‘tf(t,d)‘: 词
- 使用一个非线性函数替代原始的
-
文档长度归一化 (Document Length Normalization):
- 如上面公式所示,BM25 将文档长度
|d|和平均长度avgdl直接融入到了计算中。 - 通过参数
b,可以精细控制文档长度对得分的影响程度。这有效解决了 TF-IDF 中长文档占优的问题,使得短小精悍的相关文档也能获得高分。
- 如上面公式所示,BM25 将文档长度
-
IDF 的鲁棒性增强:
- BM25 通常使用一个更鲁棒的 IDF 变体: ‘ i d f ( t ) = log ( 1 + N − n t + 0.5 n t + 0.5 ) ‘ `idf(t) = \log(1 + \frac{N - n_t + 0.5}{n_t + 0.5})` ‘idf(t)=log(1+nt+0.5N−nt+0.5)‘
- 这个公式对包含词
t的文档数n_t非常小(接近 0)或非常大(接近N)的情况提供了更好的数值稳定性和行为。当n_t = N(每个文档都包含该词),IDF 为负值(通常会被处理为 0),表示该词对区分文档无帮助。
-
BM25 完整公式:
- 结合饱和 TF 和鲁棒 IDF,BM25 对文档
d和查询q的得分通常是: ‘ s c o r e ( q , d ) = ∑ t ∈ q [ i d f ( t ) ∗ ( k 1 + 1 ) ∗ t f ( t , d ) k 1 ∗ ( 1 − b + b ∗ ∣ d ∣ a v g d l ) + t f ( t , d ) ] ‘ `score(q, d) = \sum_{t \in q} [ idf(t) * \frac{(k_1 + 1) * tf(t, d)}{k_1 * (1 - b + b * \frac{|d|}{avgdl}) + tf(t, d)} ]` ‘score(q,d)=∑t∈q[idf(t)∗k1∗(1−b+b∗avgdl∣d∣)+tf(t,d)(k1+1)∗tf(t,d)]‘ - ES 的实现还支持查询词权重(boost)等扩展。
- 结合饱和 TF 和鲁棒 IDF,BM25 对文档
-
总结: BM25 通过引入非线性饱和函数处理 TF 和显式文档长度归一化,显著改进了 TF-IDF,使其相关性评分对文档长度不敏感,更能反映词频的真实贡献(避免过度强调高频词),并且对常见词的处理更鲁棒。参数 k_1 和 b 提供了调优相关性模型以适应不同语料库特性的灵活性。这是现代搜索引擎默认或推荐使用的相关性算法。
5. 分片和副本机制实现高可用性
分片 (Shard) 和副本 (Replica) 是 Elasticsearch 实现水平扩展 (Scalability) 和高可用性 (High Availability, HA) 的核心机制。
-
分片 (Shard):
- 定义: 一个分片是一个底层的 Lucene 索引实例。一个 Elasticsearch 索引 (Index) 在逻辑上是一个大的文档集合,但在物理上被分割成多个分片。
- 目的:
- 水平分割数据: 将海量数据分散存储在多个节点上,突破单机存储和性能限制。
- 分布式查询: 查询可以并行发送到索引的所有相关分片(主分片或副本分片)上执行,大大提升查询吞吐量和速度。
- 主分片 (Primary Shard): 每个文档属于且只属于一个主分片。主分片是文档索引、更新、删除操作的第一入口点。主分片的数量在索引创建时指定,之后不能更改(除非 reindex)。
- 副本分片 (Replica Shard):
- 定义: 每个主分片可以有零个或多个副本分片。副本是主分片的完整拷贝(包含相同的文档数据)。
- 目的:
- 高可用性 (HA): 这是最核心的目的。如果包含主分片的节点发生故障,Elasticsearch 会自动将其中一个健康的副本分片提升 (Promote) 为新的主分片,使索引操作(写入)能够继续进行,服务不会中断。没有副本,主分片丢失就意味着该分片上的数据不可用。
- 提高读取吞吐量: 搜索 (
GET) 和查询请求(search)可以发送到主分片或任何副本分片上执行。通过增加副本数量,可以线性提升系统的读取(查询)吞吐量,分担主分片的查询负载。 - 数据冗余: 副本提供了数据冗余,防止数据丢失。只要不是包含同一个主分片的所有副本(主+副本)的节点同时永久丢失,数据就是安全的。
-
高可用性 (HA) 实现过程:
- 节点故障检测: ES 集群通过节点间的
Zen Discovery协议(或其他发现机制)和心跳检测节点故障。如果主节点(Master Node)判定某个数据节点宕机(默认 30 秒无响应)。 - 主分片重新选举: 对于宕机节点上承载的主分片,集群需要选举一个新的主分片。规则是:从该主分片剩余的同步中 (in-sync) 的副本分片(即数据与故障前主分片一致的副本)中选择一个提升为新的主分片。这个选举由主节点协调。
- 副本重新分配: 集群状态变为
Yellow(因为副本数暂时不足)。主节点会在集群中其他健康的节点上启动新的副本分片创建过程,将数据从新的主分片(或其他同步的副本)复制到新副本,直到满足配置的副本数要求。完成后集群状态恢复Green。 - 写入恢复: 新的主分片可以开始接收写入请求。如果客户端在故障切换期间发送了写入请求(未收到成功响应),它可能会收到失败(如
503)或冲突(409),需要应用层重试。重试的请求会被新的主分片处理。 - 读取恢复: 查询请求可以立即发送到新的主分片和剩余的副本分片上执行,服务恢复。
- 节点故障检测: ES 集群通过节点间的
-
关键点:
- 副本数设置: 为了实现高可用,副本数至少设置为 1。这样每个主分片至少有 1 个副本,允许一个节点故障而不丢失数据或中断写入(前提是主分片和它的副本不在同一个节点上!ES 会自动分配以避免单点故障)。
- 分片分配感知: 可以使用
Shard Allocation Awareness或Forced Awareness确保主分片和其副本分布在不同的物理机架、可用区(AZ)甚至区域(Region),防止机架或数据中心故障导致数据完全丢失。 - 脑裂防护: 通过
discovery.zen.minimum_master_nodes(ES 7.x) 或cluster.initial_master_nodes(ES 7.x+) /cluster.bootstrapping(ES 8.x+) 设置防止网络分区导致的脑裂,确保只有一个主节点被认可。
总结: 分片机制实现数据分片和水平扩展;副本机制是 ES 实现高可用性的基石。它通过提供数据冗余和自动故障转移(副本提升为主分片),确保了在节点故障时,数据仍然可用(读取)且索引操作(写入)能快速恢复。合理设置副本数(至少为 1)和利用分配感知策略是构建高可用 ES 集群的关键。
6. 倒排索引如何支持全文检索?
倒排索引是全文搜索引擎(如 Elasticsearch/Lucene)的核心数据结构,它通过以下关键步骤和特性实现对全文检索的高效支持:
-
文本分析 (Analysis): 这是全文检索的第一步,也是倒排索引构建的基础。
- 分词 (Tokenization): 将原始文本(如句子、段落)分解成一个个独立的词元(Token)。例如,“The quick brown fox” -> [“the”, “quick”, “brown”, “fox”]。
- 规范化 (Normalization): 对分词后的词元进行处理,使其更标准化、更易于匹配:
- 转小写 (Lowercasing): “The” -> “the” (最常见)。
- 去除停用词 (Stop Word Removal): 移除常见但信息量低的词(如 “a”, “an”, “the”, “in”, “on”)。
- 词干还原 (Stemming): 将单词还原为其词根形式(如 “jumping”, “jumped”, “jumps” -> “jump”)。
- 词形归并 (Lemmatization): 更高级的还原,考虑词性和上下文,得到词典原形(如 “better” -> “good”)。
- 同义词处理 (Synonym): 将特定词或短语映射为标准词(如 “TV” -> “television”, “cell phone” -> “mobile phone”)。
- 结果: 原始文本被转换成一个标准化的词元(Token)序列。分析过程由分析器 (Analyzer) 定义,包含一个分词器 (
Tokenizer) 和零或多个词元过滤器 (Token Filter)。
-
构建倒排索引 (Inverted Index Construction): 处理后的词元用于构建倒排索引。
- 核心组件:
- 词项字典 (Term Dictionary): 一个包含所有唯一词项(Term,即规范化后的词元)的有序列表(通常按字典序排序)。这是查找词项的入口。
- 倒排列表 (Postings List): 对于词项字典中的每个词项
t,存储一个倒排列表 (Postings List)。该列表记录了哪些文档包含了词项t,以及在该文档中的一些附加信息:- 文档 ID (
DocID): 包含词项t的文档的唯一标识。 - 词频 (Term Frequency -
tf): 词项t在文档d中出现的次数。用于相关性评分(如 BM25)。 - 位置 (Positions): 词项
t在文档d中每次出现的位置偏移(相对于文档开头或前一个词)。这是支持短语查询 ("quick fox") 和邻近度查询 (quick fox ~5) 的关键。 - 偏移量 (Offsets): 词项
t在原始文本中字符级别的起始和结束位置(用于高亮显示)。
- 文档 ID (
- 结构关系:
Term (t)->Postings List for t=[ (DocID1, tf, [pos1, pos2, ...]), (DocID2, tf, [pos1, ...]), ... ]
- 核心组件:
-
执行全文检索 (Performing Full-Text Search):
当用户提交一个查询(如search for quick fox)时:- 查询分析: 查询字符串也会经过(通常与索引时相同的)文本分析过程,生成一组标准化的查询词项 (Query Terms)。例如
"quick fox"->["quick", "fox"]。 - 查找词项: 在词项字典中查找每个查询词项(
quick,fox)。 - 获取倒排列表: 对于找到的每个查询词项,检索其对应的倒排列表 (
Postings List)。 - 执行布尔逻辑:
- OR 查询 (
should/OR/||):获取所有查询词项的倒排列表,合并 (union) 这些列表中的所有文档 ID。这是最简单的全文匹配(只要包含任意一个词)。 - AND 查询 (
must/AND/&&):获取所有查询词项的倒排列表,求交集 (intersection),找出同时包含所有查询词项的文档 ID。 - 短语查询 (
match_phrase/"..."):- 获取所有查询词项的倒排列表(如
quick,fox)。 - 对于每个文档,检查
fox的位置列表是否恰好包含一个位置,该位置比quick在同一个文档中的某个位置大 1(即fox紧跟在quick后面)。位置信息是实现短语精确匹配的基础。
- 获取所有查询词项的倒排列表(如
- 邻近度查询 (
match_phrasewithslop/"..."~N):类似短语查询,但允许查询词项之间最多有N个其他词项(位置差 <= N+1)。
- OR 查询 (
- 相关性评分 (Scoring): 对于匹配的文档,使用算法(如 BM25)计算其与查询的相关性得分。该算法会利用倒排列表中存储的信息:
- 词频 (
tf):文档中查询词出现的次数。 - 逆文档频率 (
idf):基于词项在整个索引中出现的频率(可从词项字典的全局统计信息或倒排列表的df- Document Frequency 获得)。 - 文档长度 (
fieldLength):用于 BM25 的长度归一化(通常也存储在索引中)。 - 查询词权重 (
boost):可选的提升因子。
- 词频 (
- 结果排序与返回: 根据计算出的相关性得分对匹配文档进行降序排序,返回排名最高的结果给用户。
- 查询分析: 查询字符串也会经过(通常与索引时相同的)文本分析过程,生成一组标准化的查询词项 (Query Terms)。例如
总结
倒排索引通过将文档内容(经过文本分析)映射到关键词(词项)上,并记录每个关键词在哪些文档中出现、出现频率和位置,完美解决了“哪些文档包含这些词?”这个全文检索的核心问题。其结构(词项字典 + 倒排列表)使得基于词项的查找、布尔组合(OR/AND)、短语匹配(利用位置信息)和相关性计算(利用 tf/idf/长度)都能高效执行,成为支持快速、灵活、相关性驱动的全文搜索的基石。
思维导图

















 2268
2268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









