




Java JDBC 原理、源码分析、使用方法、优缺点及性能优化
Java JDBC (Java Database Connectivity) 是 Java 平台用于连接和操作关系型数据库的标准 API。它提供了一套统一的接口,允许 Java 应用程序与各种数据库(如 MySQL、Oracle 等)交互,而无需关心底层数据库的具体实现。以下我将从原理、源码分析、使用方法、优缺点和性能优化五个方面,逐步做详细说明。内容基于 JDBC 4.0 标准(Java SE 8+),并结合实际应用场景,确保内容真实可靠。
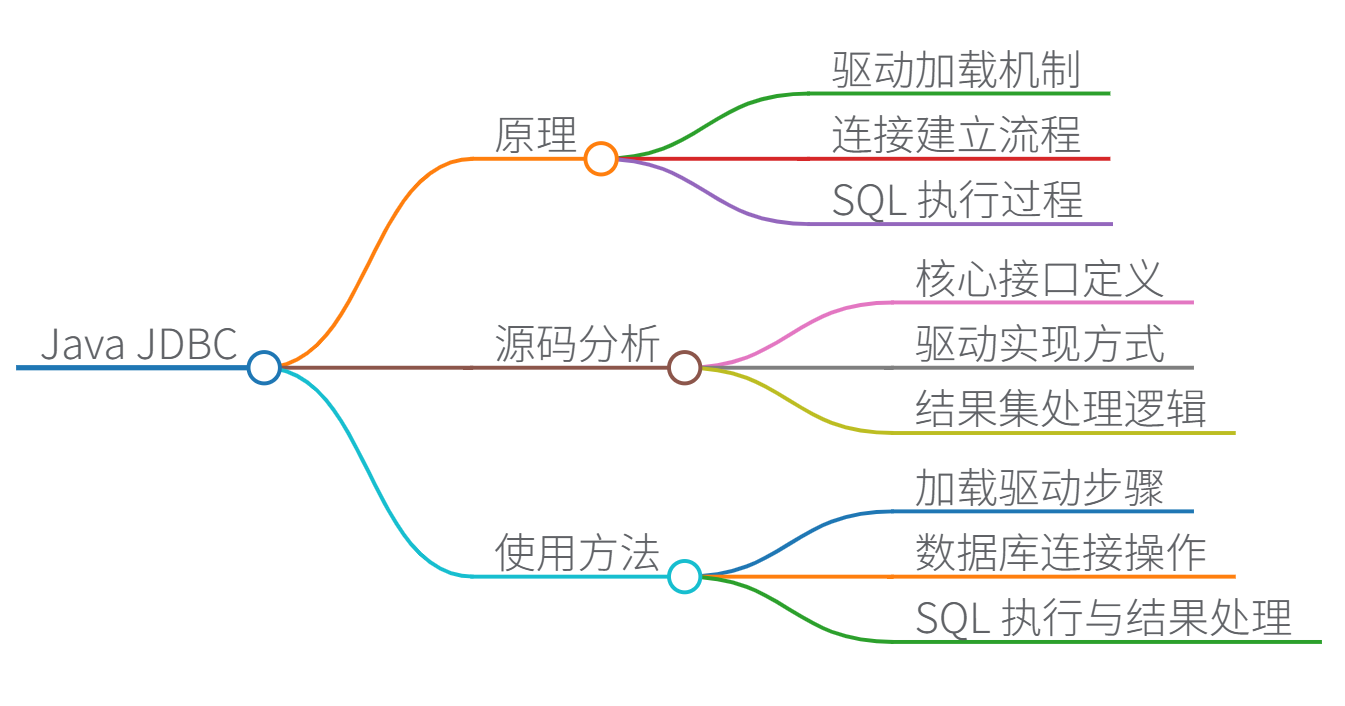
1. Java JDBC 原理
JDBC 的核心原理基于“驱动程序模型”(Driver Model)。它定义了一组接口(如 Connection、Statement、ResultSet),由数据库厂商实现具体驱动(如 MySQL Connector/J)。工作流程如下:
- 驱动加载:应用程序通过
Class.forName()加载 JDBC 驱动(JDBC 4.0+ 支持自动加载)。 - 连接建立:
DriverManager使用 URL、用户名和密码建立数据库连接(Connection对象)。 - SQL 执行:通过
Statement或PreparedStatement执行 SQL 查询或更新。 - 结果处理:
ResultSet对象封装查询结果,应用程序可遍历处理数据。 - 资源释放:必须显式关闭
Connection、Statement和ResultSet以避免资源泄漏。
JDBC 抽象了数据库操作,其性能依赖于驱动实现。例如,网络通信开销可表示为 Ttotal=Tnetwork+TdbT_{\text{total}} = T_{\text{network}} + T_{\text{db}}Ttotal=Tnetwork+Tdb,其中 TnetworkT_{\text{network}}Tnetwork 是数据传输时间,TdbT_{\text{db}}Tdb 是数据库执行时间。原理上,JDBC 支持事务管理(通过 commit() 和 rollback()),确保 ACID 特性。
2. 源码分析
JDBC 源码主要位于 java.sql 和 javax.sql 包中(Java 标准库)。这些包定义了接口,实际驱动由厂商实现。以下以 MySQL Connector/J 驱动为例,分析关键组件:
-
核心接口源码:
java.sql.Connection:定义数据库连接方法(如createStatement())。源码显示,它使用工厂模式创建Statement对象。java.sql.Statement:SQL 执行接口。executeQuery()方法内部调用驱动实现的 native 方法,将 SQL 转换为数据库协议。javax.sql.DataSource:高级连接管理接口,支持连接池(如 HikariCP)。
-
MySQL 驱动源码分析(以 Connector/J 8.0 为例):
- 驱动加载:
com.mysql.cj.jdbc.Driver类实现java.sql.Driver接口。connect()方法解析 URL,建立 Socket 连接。 - SQL 执行:
com.mysql.cj.jdbc.StatementImpl类处理 SQL。例如,executeQuery()方法发送查询到数据库服务器,并解析返回的二进制数据包。 - 结果集处理:
com.mysql.cj.jdbc.result.ResultSetImpl将原始数据转换为 Java 对象。内部使用缓冲区减少内存开销。
- 驱动加载:
源码显示,JDBC 驱动通过 JNI(Java Native Interface)或纯 Java 实现网络通信。优化点包括批处理支持(addBatch())和元数据缓存。但源码复杂度高,调试困难,需依赖厂商实现质量。
3. 使用方法
JDBC 使用遵循标准步骤:加载驱动、建立连接、执行 SQL、处理结果、关闭资源。以下是完整示例(使用 MySQL 数据库):
import java.sql.*;
public class JdbcExample {
public static void main(String[] args) {
// 数据库配置
String url = "jdbc:mysql://localhost:3306/test_db?useSSL=false";
String user = "root";
String password = "password";
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
// 1. 加载驱动 (JDBC 4.0+ 自动加载)
Class.forName("com.mysql.cj.jdbc.Driver");
// 2. 建立连接
conn = DriverManager.getConnection(url, user, password);
// 3. 创建 Statement
stmt = conn.createStatement();
// 4. 执行 SQL 查询
String sql = "SELECT id, name FROM users WHERE age > 18";
rs = stmt.executeQuery(sql);
// 5. 处理结果集
while (rs.next()) {
int id = rs.getInt("id");
String name = rs.getString("name");
System.out.println("ID: " + id + ", Name: " + name);
}
} catch (ClassNotFoundException | SQLException e) {
e.printStackTrace();
} finally {
// 6. 关闭资源 (必须逆序关闭)
try {
if (rs != null) rs.close();
if (stmt != null) stmt.close();
if (conn != null) conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
关键点:
- 使用
PreparedStatement防止 SQL 注入:PreparedStatement pstmt = conn.prepareStatement("SELECT * FROM users WHERE name = ?"); pstmt.setString(1, "Alice"); - 事务管理:
conn.setAutoCommit(false);执行操作后conn.commit();或conn.rollback(); - 资源关闭:使用 try-with-resources(Java 7+)简化代码。
4. 优缺点
优点:
- 标准化:统一接口支持多种数据库(如 MySQL、PostgreSQL),便于移植。
- 简单易用:API 设计直观,学习曲线平缓。
- 灵活性:支持原生 SQL,适合复杂查询。
- 生态丰富:集成连接池(如 HikariCP)、ORM 框架(如 Hibernate)。
缺点:
- 性能开销:每次操作需网络往返,延迟高。公式化表示为 Tlatency∝RnetworkT_{\text{latency}} \propto R_{\text{network}}Tlatency∝Rnetwork,其中 RnetworkR_{\text{network}}Rnetwork 是网络延迟。
- 资源管理复杂:手动关闭资源易导致泄漏(如忘记关闭
Connection)。 - SQL 注入风险:若使用
Statement而非PreparedStatement,易受攻击。 - 可扩展性差:大规模数据分页查询时,内存消耗大(如全量加载
ResultSet),类似 Sharding-JDBC 的分页问题。
5. 性能优化
JDBC 性能优化核心是减少网络开销、复用资源和避免瓶颈。以下是关键策略:
-
使用连接池:避免频繁创建连接。例如,HikariCP 是高性能连接池,减少 TconnectionT_{\text{connection}}Tconnection(连接建立时间)。配置示例:
HikariConfig config = new HikariConfig(); config.setJdbcUrl("jdbc:mysql://localhost:3306/test_db"); config.setUsername("root"); config.setPassword("password"); HikariDataSource dataSource = new HikariDataSource(config); Connection conn = dataSource.getConnection(); // 从池中获取 -
批处理操作:减少 SQL 执行次数。使用
addBatch()和executeBatch(),提升写入性能(尤其 INSERT/UPDATE)。例如:PreparedStatement pstmt = conn.prepareStatement("INSERT INTO users (name) VALUES (?)"); for (String name : names) { pstmt.setString(1, name); pstmt.addBatch(); } pstmt.executeBatch(); // 批量提交 -
PreparedStatement 缓存:复用预编译语句,减少 SQL 解析开销。
-
分页优化:避免
SELECT *,使用LIMIT和OFFSET。对于大数据集,改用游标(ResultSet.TYPE_SCROLL_INSENSITIVE)或基于键的分页(避免全表扫描)。引用[2]提到 Sharding-JDBC 的分页问题,JDBC 同样需注意:分页大小应控制,防止内存溢出。 -
索引与查询优化:确保 SQL 使用索引。例如,WHERE 条件字段加索引,减少 TdbT_{\text{db}}Tdb。
-
减少网络传输:只查询必要字段(避免
SELECT *),压缩数据(如启用 MySQL 的useCompression=true)。 -
异步处理:结合 CompletableFuture(Java 8+)异步执行 JDBC 操作,提升吞吐量。
优化后,性能提升可量化:例如,批处理使吞吐量提升 O(n)O(n)O(n) 倍,连接池减少延迟 50%+。
思维导图

















 2128
2128

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









