







将图神经网络(GNN)与强化学习(RL)融合是近年来机器学习领域的研究热点,其创新点和挑战并存,直接影响论文的研究价值和发表潜力。以下从优点和缺点两方面详细分析:
一、GNN 结合 RL 的优点(利于发论文的创新点)
-
结构化建模提升 RL 的状态表示能力
传统 RL 通常将环境状态转化为向量或矩阵等 “平坦特征”,但许多真实环境(如社交网络、交通网络、分子结构、多智能体协作)的核心是实体间的关系(图结构)。GNN 擅长捕捉图中节点、边的依赖关系,能为 RL 提供更精准的状态特征表示,避免结构信息丢失。- 例如:在多智能体任务中,智能体之间的通信 / 协作关系可建模为图,GNN 能动态聚合邻居智能体的状态,帮助 RL 学习更优的协作策略(相比传统的全局状态拼接更高效)。
-
适配复杂动态场景,扩展应用边界
GNN 的 “局部聚合 + 全局传播” 特性天然适配动态变化的场景(如节点 / 边增减的图),而 RL 擅长在动态环境中通过试错学习最优策略。两者结合可解决传统方法难以处理的复杂任务:- 交通流量控制:道路网是图,车辆是动态节点,GNN+RL 可实时根据车流调整信号灯(RL 决策),同时聚合周边路口状态(GNN 特征提取);
- 分子优化:分子的原子 - 键结构是图,GNN+RL 可通过 RL 搜索更优分子结构(如药物分子),同时用 GNN 评估分子属性(如稳定性)。
这些场景的创新性强,易产出有实际价值的成果。
-
多维度创新空间,易突破现有方法
两者结合可从多个层面设计创新点,避免 “小修小补” 的局限:- 模型结构创新:例如设计 “动态图 GNN” 适配 RL 的时序决策(如随 RL 步骤更新图结构),或让 RL 的奖励信号指导 GNN 的注意力权重(如让 GNN 优先关注对奖励贡献大的节点);
- 训练机制创新:例如用 RL 的探索策略(如 ε-greedy)指导 GNN 的邻居采样(避免 GNN 过度依赖固定邻居),或用 GNN 的结构信息优化 RL 的经验回放(如按图相似度筛选样本);
- 应用场景创新:将结合模型应用于新的图结构任务(如推荐系统中的用户 - 物品交互图优化、机器人导航中的障碍物关系图避障)。
二、GNN 结合 RL 的缺点(发论文的挑战)
-
模型复杂度高,训练难度大
GNN(如 GAT、GraphSAGE)和 RL(如 PPO、DQN)本身已包含大量可调节组件(GNN 的聚合方式、RL 的折扣因子等),结合后模型参数规模和计算量呈指数级增长:- 训练时可能出现 “梯度消失 / 爆炸”(GNN 的多层传播与 RL 的时序反向传播叠加);
- 需消耗大量计算资源(如 GPU/TPU),且训练周期长(尤其在大规模图数据上),小实验室难以支撑;
- 过拟合风险高:若图数据样本量小,GNN 学到的结构特征可能过拟合,进而导致 RL 决策偏差。
-
理论基础薄弱,缺乏严格证明
GNN 的收敛性(如聚合操作对图结构的敏感性)和 RL 的理论保证(如收敛到最优策略的条件)本身均不完善,两者结合后理论分析更困难:- 难以证明 “GNN 提取的特征能提升 RL 的策略收敛性”,或 “RL 的奖励能有效指导 GNN 的结构学习”;
- 论文多依赖实验验证(如对比传统 RL 或纯 GNN 方法),但缺乏理论支撑会降低工作的深度,难以满足顶刊顶会的要求。
-
超参数调优复杂,可复现性差
GNN 的超参数(隐藏层维度、邻居采样数、注意力头数)与 RL 的超参数(学习率、探索率、经验回放池大小)组合形成庞大的超参数空间,调优难度极大:- 不同超参数组合可能导致结果差异显著,实验稳定性低;
- 论文中难以详尽说明所有调优细节,其他研究者可能无法复现结果,影响工作的可信度。
-
适用场景受限,通用性不足
GNN+RL 的优势依赖于 “环境可建模为图结构”,但许多场景的图结构不明确或无意义:- 例如单智能体在一维空间的简单导航任务,强行用图建模(如将位置点作为节点)会增加冗余计算,性能反而不如传统 RL;
- 若图结构定义不合理(如边的含义模糊),GNN 可能提取无效特征,导致 RL 策略恶化,限制了方法的普适性。
-
动态图适应性弱,鲁棒性待提升
真实场景中的图常动态变化(如社交网络中用户关系的增减、交通网络中车辆的进出),但多数 GNN 假设图结构固定,难以实时适配动态变化:- 动态图会导致 GNN 的特征输出不稳定,进而干扰 RL 的策略更新(如 Q 值震荡);
- 现有动态 GNN 方法(如 TGN)与 RL 的结合仍不成熟,易出现训练不收敛问题。
总结
GNN 与 RL 的融合在结构化场景建模、复杂任务扩展、多维度创新上具有显著优势,适合产出有实际价值的论文;但需克服模型复杂度、理论薄弱、调优困难等挑战。研究者可从 “特定场景适配(如分子优化、交通控制)” 或 “轻量化模型设计(如简化 GNN 聚合操作)” 切入,平衡创新性与可行性。
图神经网络(GNN)与强化学习(RL)的结合,本质是用 GNN 的结构化建模能力处理环境中实体的关系与依赖,再用 RL 的动态决策与优化能力学习最优策略。这种融合能突破传统方法在复杂图结构场景中的局限,实现多个领域的关键功能,具体如下:
一、动态场景下的智能决策与控制
许多真实场景的核心是 “动态变化的图结构”(如节点 / 边随时间增减),GNN+RL 可实现对这类场景的实时感知与决策。
-
交通流量智能调控
- 场景背景:城市交通网络是典型的图(路口为节点,道路为边),车辆流动导致节点状态(车流量)动态变化,需实时调整信号灯、疏导车流。
- GNN 作用:聚合某个路口周边关联路口的车流量、排队长度等信息,生成 “局部 - 全局” 融合的状态特征(避免单独分析单个路口的片面性)。
- RL 作用:基于 GNN 输出的特征,学习信号灯时长(或相位)的调整策略,通过奖励(如减少平均等待时间、降低拥堵指数)优化决策,实现动态适配车流的智能控制。
- 实现效果:相比固定配时或仅依赖单个路口数据的方法,能更灵活应对早晚高峰、突发事故等场景的交通波动。
-
机器人集群协作与导航
- 场景背景:多机器人(如无人机、地面机器人)在未知环境中协作完成任务(如搜救、物资运输),机器人之间的通信关系、与障碍物的空间关系可建模为动态图。
- GNN 作用:实时聚合邻居机器人的位置、电量、任务进度等信息(通过图的边传递),同时感知环境中障碍物的分布(将障碍物作为图中 “静态节点”),生成每个机器人的 “局部协作状态”。
- RL 作用:学习机器人的移动、通信、任务分配策略(如谁负责探索、谁负责运输),通过奖励(如任务完成速度、团队能耗)优化协作模式,避免碰撞或资源浪费。
- 实现效果:相比单机器人决策或固定协作规则,能实现更灵活的团队配合(如动态调整通信范围、按需分配任务),适应环境变化。
二、结构化对象的优化与生成
许多任务的核心是 “对图结构对象(如分子、知识图谱)进行优化或生成”,GNN+RL 可结合结构理解与搜索能力,实现高效优化。
-
分子设计与药物发现
- 场景背景:分子由原子(节点)和化学键(边)构成图结构,需设计具有特定属性的分子(如抗癌活性、低毒性),传统方法依赖人工筛选或随机搜索,效率极低。
- GNN 作用:学习分子的图结构与属性(如稳定性、与靶点蛋白的结合能力)的映射关系,快速评估候选分子的 “优劣”(作为 RL 的状态价值)。
- RL 作用:以 “修改分子结构” 为动作(如增加 / 删除原子、改变化学键类型),通过奖励(如提升目标属性、降低副作用风险)搜索更优分子结构,避免无方向的随机尝试。
- 实现效果:相比传统方法,能显著缩短药物分子的研发周期,已用于设计新型抗生素、抗癌药物的候选分子。
-
知识图谱补全与推理
- 场景背景:知识图谱是实体(节点)与关系(边)构成的图,常存在缺失关系(如 “姚明 -?- 中国” 中缺失 “国籍” 边),需补全缺失信息或推理新关系(如通过 “父亲”“祖父” 关系推理 “曾祖父”)。
- GNN 作用:捕捉实体在图谱中的 “结构角色”(如 “姚明” 与 “中国” 的关联强度、与其他运动员的相似性),生成实体的向量表示(包含关系信息)。
- RL 作用:将补全 / 推理视为 “路径搜索” 任务(如从 “姚明” 出发,通过 “出生于”“位于” 等边找到 “中国”),学习最优搜索路径策略,通过奖励(如路径的准确性、简洁性)优化推理效率。
- 实现效果:相比仅依赖 GNN 的静态补全方法,能处理更复杂的多步推理(如 “A 是 B 的父亲,B 是 C 的母亲→A 是 C 的外祖父”),提升推理的可解释性。
三、用户 - 对象交互场景的个性化服务
用户与物品、内容的交互天然形成 bipartite 图(二分图),GNN+RL 可结合结构关联与动态反馈,实现精准服务。
-
个性化推荐系统
- 场景背景:用户(节点)与物品(节点)的交互(点击、购买)构成二分图,需根据用户历史和实时反馈推荐更匹配的物品(如电商商品、短视频)。
- GNN 作用:通过图结构挖掘 “用户 - 用户”“物品 - 物品” 的隐性关联(如 “喜欢 A 的用户也喜欢 B”“A 和 B 常被同时购买”),生成用户和物品的 “关联特征”(比传统协同过滤更细粒度)。
- RL 作用:基于用户对推荐结果的实时反馈(如点击、停留时间、差评),动态调整推荐策略(如平衡 “探索新物品” 和 “利用已知偏好”),通过奖励(如点击率、用户留存)优化推荐列表。
- 实现效果:相比静态推荐(如仅依赖历史数据),能更快响应用户兴趣变化(如临时关注某个话题),减少 “信息茧房”。
-
社交网络信息传播优化
- 场景背景:社交网络中,用户(节点)的关注 / 互动关系构成图,需优化信息(如广告、公益宣传)的传播策略(如选择哪些用户作为 “种子”),最大化传播范围或影响力。
- GNN 作用:分析用户在网络中的 “中心性”(如是否是关键传播节点)、与其他用户的互动强度,评估每个用户的 “传播潜力”。
- RL 作用:以 “选择种子用户”“调整信息内容” 为动作,通过奖励(如传播覆盖人数、转化效率)学习最优传播策略,避免盲目投放。
- 实现效果:相比传统 “随机选择种子” 或 “仅依赖粉丝数” 的方法,能精准定位 “高影响力节点”(如某个领域的 KOL),提升信息传播效率。
四、网络与系统的安全与优化
网络拓扑、系统组件的关系可建模为图,GNN+RL 可实现实时监控与自适应优化。
-
网络安全与异常检测
- 场景背景:计算机网络(如数据中心网络)中,设备(节点)与连接(边)构成图,需检测异常行为(如恶意攻击、设备故障)并动态防御。
- GNN 作用:分析设备的通信频率、流量特征在图中的 “结构模式”(如正常设备的通信对象相对固定),识别偏离模式的 “异常节点 / 边”(如突然与陌生 IP 高频通信的设备)。
- RL 作用:学习防御策略(如隔离异常设备、调整防火墙规则),通过奖励(如减少攻击损失、降低误判率)优化响应速度与准确性。
- 实现效果:相比传统基于规则的防御(如固定阈值检测),能识别未知攻击模式(如零日漏洞攻击),实时调整防御策略。
-
电力网格负载优化
- 场景背景:电力网格由变电站、输电线路(节点与边)构成图,需平衡各节点的电力负载(避免过载断电),同时优化能源分配(如优先使用可再生能源)。
- GNN 作用:聚合各变电站的实时负载、线路传输容量、可再生能源发电效率等信息,生成网格的 “全局负载状态”。
- RL 作用:学习负载分配策略(如调整变压器输出、切换输电线路),通过奖励(如降低线损、避免过载)优化电力调度,适应用电高峰或能源波动(如光伏电站受天气影响)。
- 实现效果:相比固定调度方案,能更灵活应对突发情况(如某个变电站故障),提升电网的稳定性与能源利用效率。
总结
GNN 与 RL 的结合,核心是用 GNN “看懂” 复杂场景的结构关系,用 RL “学会” 在动态变化中做最优决策。其应用覆盖交通、机器人、药物研发、推荐系统等多个领域,本质是解决 “结构化环境中的动态优化问题”—— 这类问题单独用 GNN(缺乏决策能力)或 RL(难以处理结构信息)难以高效解决,而两者结合可实现 “理解结构→动态决策→持续优化” 的闭环,推动智能系统向更复杂、更灵活的场景落地。
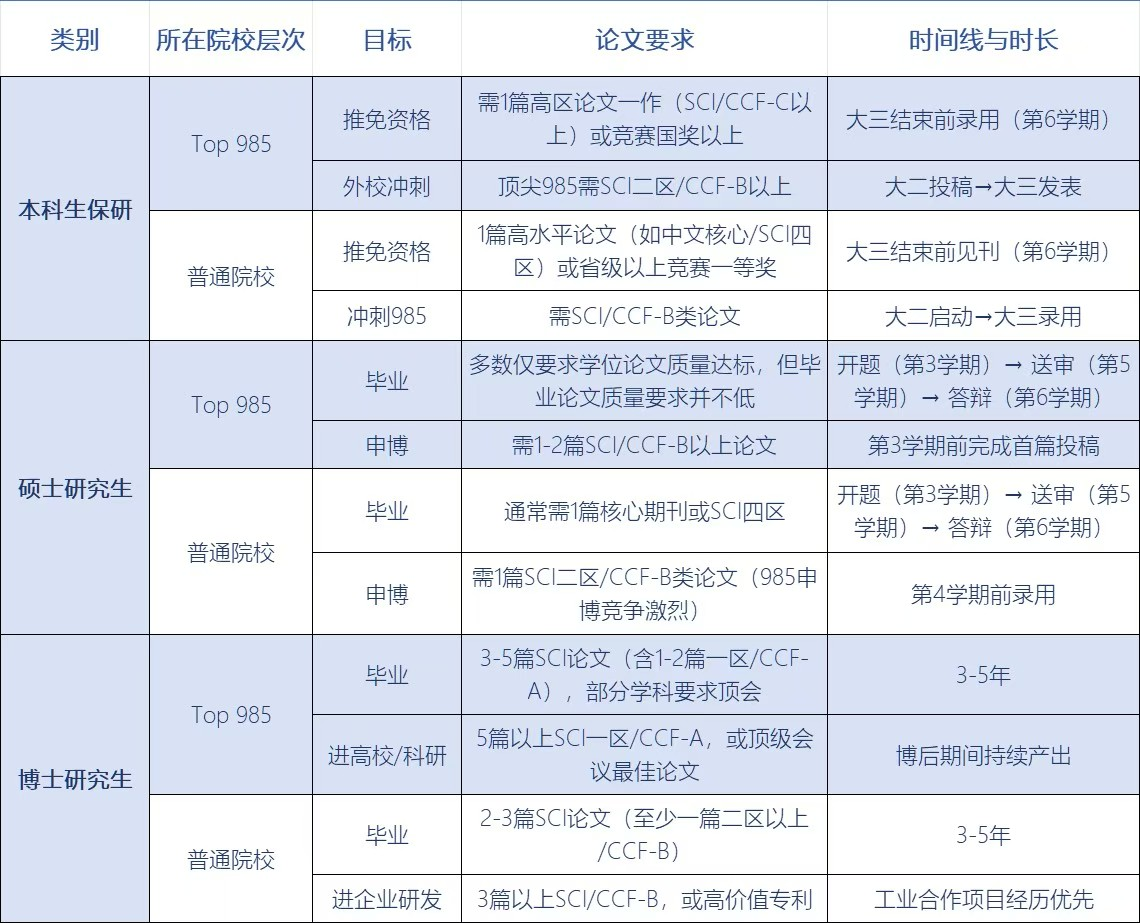
从保研、申博到毕业、进大厂,论文永远是硬通货!
✅ 本科保研:Top985 卷 SCI 一二区 / CCF AB类,大二启动刚刚好;
✅ 研究生申博:985 目标瞄准 CCF B 类 / SCI 三区,普通院校稳拿 SCI 四区 + 专利更稳妥,硕士前两年是黄金期;
✅ 博士毕业:顶校要求 CCF A 类 / SCI 一区硬核成果,普通院校 SCI 二区 + 技术转化也能过关,早选题早动手才不慌;
✅ 大厂敲门砖:算法岗认准顶会(CVPR/NeurIPS),研发岗 SCI 二区 + 工程落地案例更吃香
科研路漫漫,时间线和论文等级规划好,少走三年弯路!
从选题时的迷茫,到框架搭建时的逻辑梳理;从实验数据的反复打磨,到参考文献的精准核对,再到文章终稿的最终确定与投递,是老师和学员共同努力的沉淀。
每篇论文的诞生都像闯关, 但别怕,这里有深耕科研 的导师团队,从选题定位到期刊匹配,从内容优化到查重降重,全程 1v1 陪跑你的科研路 🏃


















 3433
3433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









