







在多模态融合领域,结合当前研究热点和未解决的痛点,以下几类模型的结合方向更容易产生创新性论文,核心在于利用模型特性解决模态差异、对齐、效率或泛化性问题,同时结合具体任务或场景落地: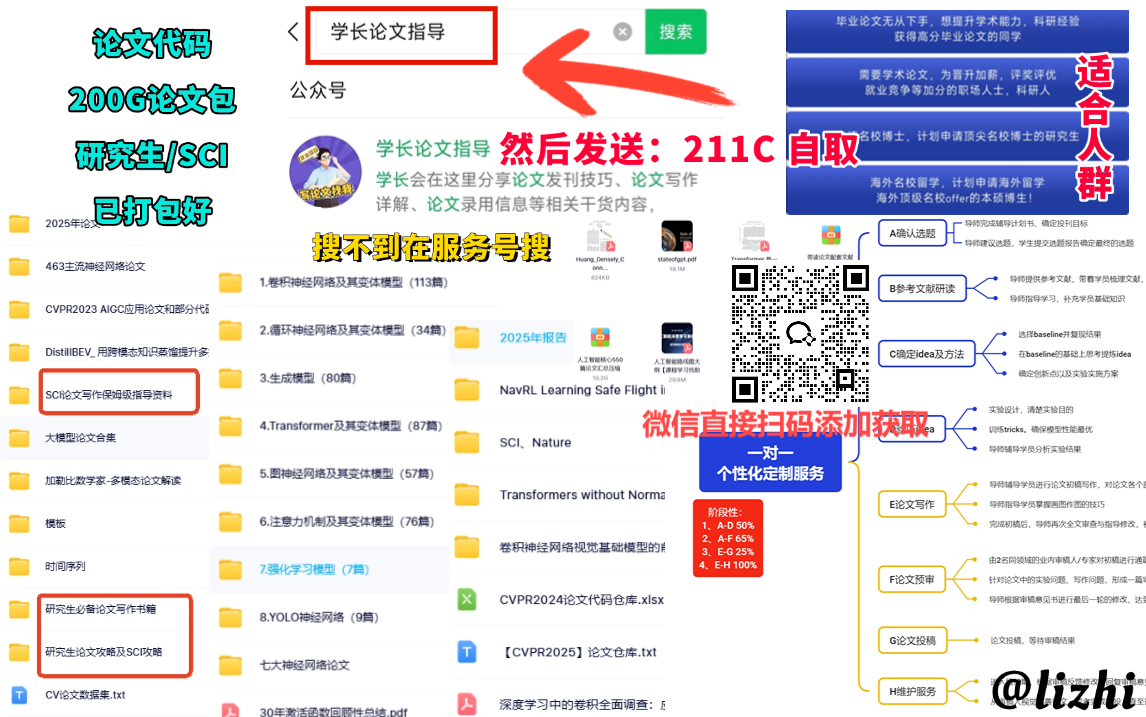
一、大语言模型(LLMs)与视觉 / 音频 / 3D 等模态的融合
LLMs(如 GPT、LLaMA、Gemini)是当前最活跃的研究载体,其强大的文本理解和生成能力,为跨模态融合提供了天然的 “语义桥梁”,但仍有大量待探索的方向:
-
LLMs 与视觉模态的细粒度融合
- 问题:现有视觉 - 语言模型(如 CLIP、BLIP)多依赖固定的视觉编码器(如 ViT),与 LLMs 的交互较浅,难以处理复杂视觉推理(如 “图像中 A 物体和 B 物体的空间关系”)。
- 创新点:设计动态视觉 - 文本交互机制(如让 LLMs 直接 “读取” 视觉特征的时序 / 空间结构),或用 LLMs 的知识蒸馏视觉编码器,提升跨模态推理的逻辑性。
-
LLMs 与多模态序列融合(视频 / 音频)
- 问题:视频(时空特征)、音频(时序特征)与文本的时序对齐难度大,现有模型多采用简单拼接,忽略模态内的动态关联。
- 创新点:结合 LLMs 的时序建模能力(如通过因果注意力),设计跨模态时序对齐模块(如用 LLMs 生成的文本 “锚点” 引导视频 / 音频片段的权重分配),应用于视频字幕生成、多模态对话等任务。
-
小样本 / 零样本多模态融合
- 问题:多模态数据标注成本高,现有模型依赖大规模标注数据。
- 创新点:将 LLMs 的提示学习(Prompt Tuning)、指令微调(Instruction Tuning)扩展到多模态场景,例如用自然语言指令定义跨模态任务(如 “用文字描述图像中异常的区域”),通过少量示例让模型自适应不同模态组合。
二、扩散模型(Diffusion Models)与跨模态生成融合
扩散模型(如 Stable Diffusion)在图像生成上的成功已延伸至多模态领域,其 “逐步去噪” 的生成机制为跨模态语义对齐提供了新思路,且仍有大量未挖掘的空间:
-
多模态条件扩散(文本 + 音频 / 3D 引导图像生成)
- 问题:现有扩散模型多依赖单一文本条件,难以融合多源模态约束(如 “生成一段包含雨声的森林图像” 需要文本 “森林” 和音频 “雨声” 共同引导)。
- 创新点:设计跨模态条件编码器,将音频 / 3D 等模态的特征转化为扩散模型可理解的 “噪声预测约束”,或在扩散过程中动态融合多模态条件(如早期用文本定主题,晚期用音频调细节)。
-
扩散模型的跨模态双向生成
- 问题:现有多模态生成多是 “文本→图像”“图像→文本” 单向,缺乏双向语义一致性(如生成的图像与文本描述存在细节偏差)。
- 创新点:构建 “文本 - 图像” 双向扩散模型,通过对抗训练或循环一致性约束(如用文本生成图像后,再用图像重构文本,确保语义一致),提升生成的准确性。
-
低资源模态的扩散融合(如医学影像 + 报告)
- 问题:医学等领域多模态数据稀缺,扩散模型容易过拟合。
- 创新点:结合领域知识(如医学术语词典)设计模态适配模块,用自监督学习预训练扩散模型的跨模态特征提取器,降低对标注数据的依赖。
三、Transformer 变体与跨模态注意力机制融合
Transformer 的自注意力机制是多模态对齐的核心工具,但标准 Transformer 在处理模态差异(如视觉的高维空间特征 vs 文本的离散符号)和长序列时效率低下,因此改进空间巨大:
-
稀疏 / 动态跨模态注意力
- 问题:全注意力计算复杂度高(O (n²)),且对无关模态特征(如图像中与文本无关的背景)过度关注。
- 创新点:设计模态感知的稀疏注意力(如仅让文本词与图像中高语义区域(如物体)计算注意力),或动态调整注意力权重(如用门控机制过滤低相关模态特征),提升效率和对齐精度。
-
跨模态分层 Transformer
- 问题:不同模态的语义粒度不同(如文本的 “句子 - 词” vs 图像的 “场景 - 物体 - 像素”),单一层次的注意力难以匹配。
- 创新点:构建分层跨模态 Transformer,底层处理细粒度特征(如词与像素),高层处理抽象语义(如句子与场景),通过跨层跳跃连接实现多粒度对齐,适用于多模态检索、细粒度分类等任务。
四、自监督学习模型与多模态预训练融合
自监督学习(如 MAE、MoCo)通过无标注数据学习通用特征,但其在多模态场景的 “跨模态自监督信号” 设计仍不成熟,是创新的富矿:
-
跨模态掩码预测任务
- 问题:现有多模态自监督多采用单模态掩码(如掩码图像块预测),缺乏模态间的关联约束。
- 创新点:设计跨模态掩码任务,例如 “用文本特征预测被掩码的图像块”“用图像特征补全被掩码的句子成分”,强制模型学习模态间的语义映射。
-
多模态对比学习的改进
- 问题:现有对比学习(如 CLIP 的图文对比)依赖 “正负样本对”,但难定义跨模态的 “相似性”(如文本 “红色” 与图像中红色物体的相似性如何量化)。
- 创新点:引入模态间的 “语义桥梁”(如知识图谱中的实体关系),构建更精细的对比损失(如不仅对比整体相似度,还对比局部语义单元的匹配度)。
五、特定场景下的模型融合(落地导向)
结合具体场景的痛点,将上述模型与领域特性结合,更容易产出有实用价值的论文:
- 医疗场景:融合医学影像(CT/MRI)、电子病历(文本)、生理信号(时序),用 Transformer + 自监督学习构建多模态诊断模型,解决 “影像特征与病历描述不一致” 的问题。
- 机器人感知:融合视觉(摄像头)、触觉(传感器)、语音(指令),用 LLMs + 扩散模型实现 “指令 - 动作 - 环境反馈” 的闭环融合,提升机器人的操作精度。
- 自动驾驶:融合激光雷达(3D 点云)、摄像头(图像)、导航文本指令,用动态注意力机制对齐空间特征(3D 障碍物)与文本指令(如 “避开前方车辆”)。
总结
容易出论文的方向需满足:模型特性与多模态痛点的强匹配(如 LLMs 解决语义对齐,扩散模型解决生成质量)+ 创新点的可解释性(如新型注意力机制、跨模态任务设计)。优先选择 “热门模型(如 LLMs、扩散模型)+ 未充分探索的模态组合 / 任务”,或 “经典模型(如 Transformer)+ 跨模态机制的显著改进”,同时结合具体场景落地,更容易体现价值。
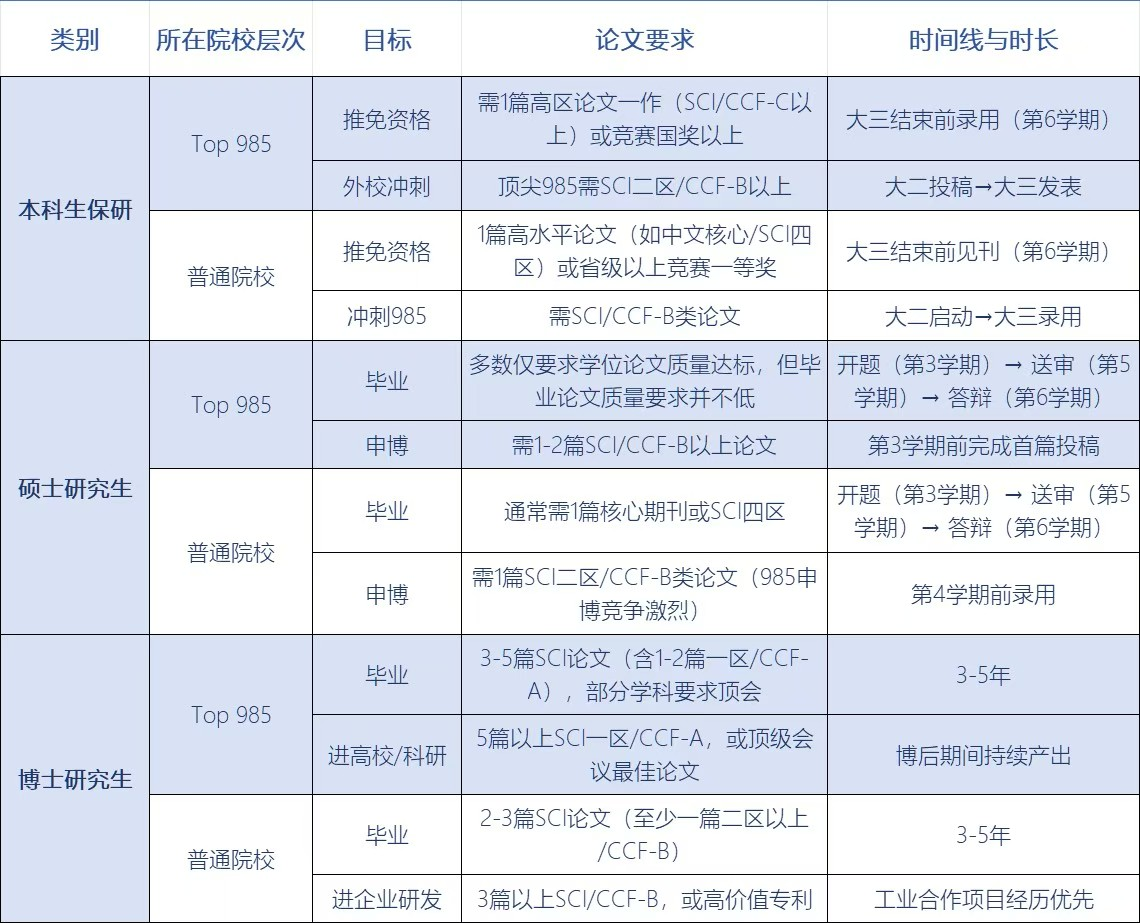
从保研、申博到毕业、进大厂,论文永远是硬通货!
✅ 本科保研:Top985 卷 SCI 一二区 / CCF AB类,大二启动刚刚好;
✅ 研究生申博:985 目标瞄准 CCF B 类 / SCI 三区,普通院校稳拿 SCI 四区 + 专利更稳妥,硕士前两年是黄金期;
✅ 博士毕业:顶校要求 CCF A 类 / SCI 一区硬核成果,普通院校 SCI 二区 + 技术转化也能过关,早选题早动手才不慌;
✅ 大厂敲门砖:算法岗认准顶会(CVPR/NeurIPS),研发岗 SCI 二区 + 工程落地案例更吃香
科研路漫漫,时间线和论文等级规划好,少走三年弯路!
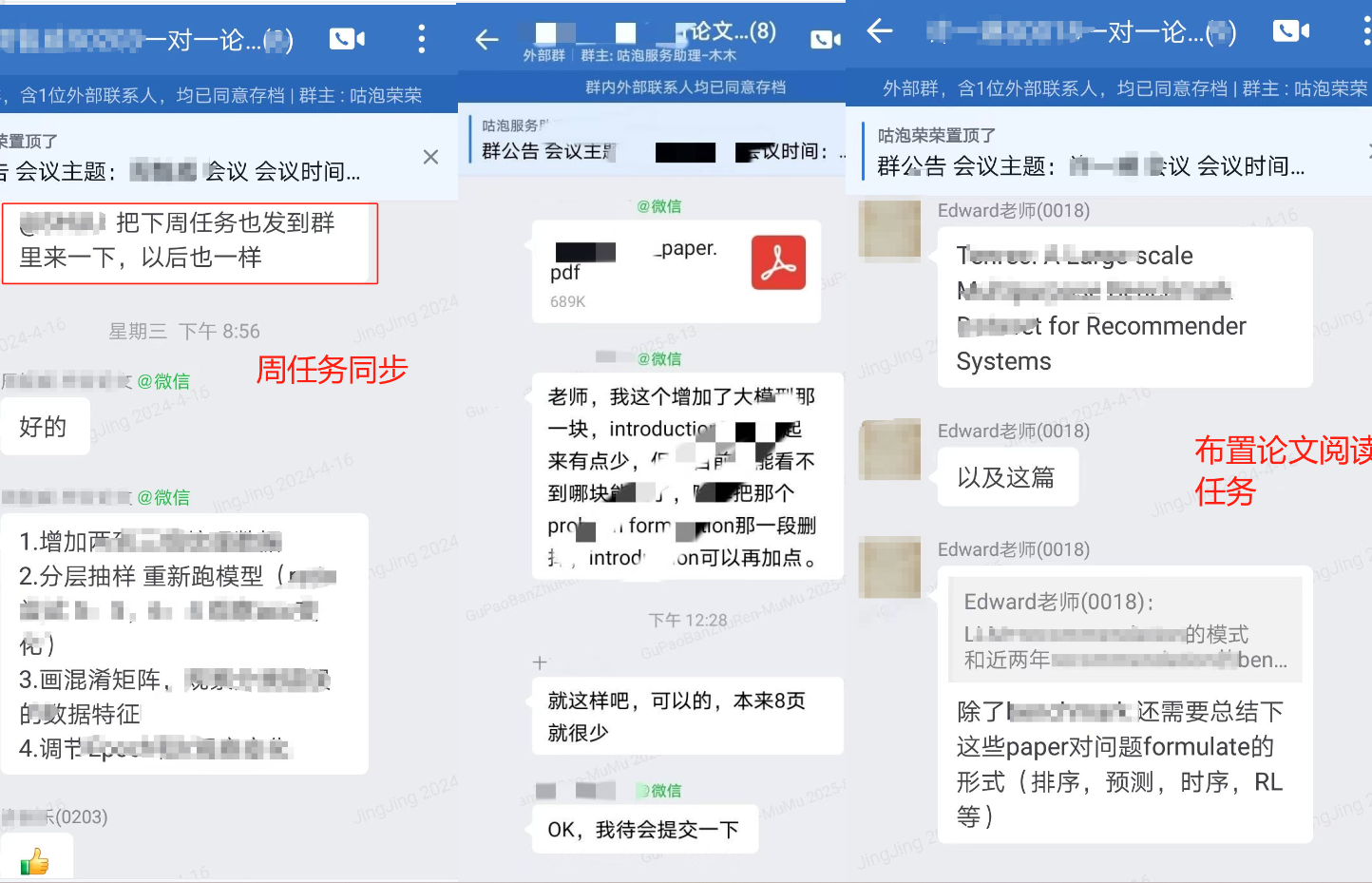
从选题时的迷茫,到框架搭建时的逻辑梳理;从实验数据的反复打磨,到参考文献的精准核对,再到文章终稿的最终确定与投递,是老师和学员共同努力的沉淀。
每篇论文的诞生都像闯关, 但别怕,这里有深耕科研 的导师团队,从选题定位到期刊匹配,从内容优化到查重降重,全程 1v1 陪跑你的科研路 🏃


















 8615
8615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









