







Kaggle 是全球最大的数据科学竞赛平台,也是入门数据科学、提升实战能力的绝佳途径。对于新手来说,入门 Kaggle 需要从「基础准备」到「实战练习」逐步推进,以下是具体步骤和建议:
一、先搞懂:Kaggle 是什么?
Kaggle 核心功能包括:
- 竞赛(Competitions):企业 / 机构发布数据和任务(如预测房价、图像分类),参赛者提交解决方案,按性能排名获奖(奖金 / 荣誉)。
- 数据集(Datasets):海量公开数据,可用于练习或自主研究。
- Notebooks:在线代码环境(类似 Jupyter),可分享代码、学习他人思路。
- 课程(Courses):官方免费入门教程(如 Python、机器学习基础)。
新手核心目标:通过竞赛熟悉「数据处理→建模→优化」全流程,积累经验,而非一开始追求获奖。
二、入门前的基础准备
Kaggle 本质是「实战」,但需要一定基础才能高效上手,避免挫败感。
1. 必备基础知识
- 编程语言:熟练掌握 Python(核心),了解基础语法、数据结构(列表、字典、DataFrame)。
- 数据处理库:Pandas(数据清洗、分析)、NumPy(数值计算)是核心,必学。
- 可视化库:Matplotlib/Seaborn(画图表辅助分析数据),入门阶段能看懂图、画基础图即可。
- 机器学习基础:了解常见算法原理(如线性回归、决策树、随机森林、逻辑回归),不需要推导公式,但要知道适用场景(如分类用逻辑回归,回归用线性回归)。
学习资源:
- 快速入门 Python:菜鸟教程 / Python 官方文档
- 数据处理:Kaggle 官方课程《Python》《Pandas》(免费,带交互练习)
- 机器学习:吴恩达《Machine Learning》(Coursera,经典入门)
2. 工具准备
- 环境:推荐用 Kaggle 在线 Notebook(无需本地配置,直接调用数据),或本地装 Anaconda(含 Jupyter、Pandas 等库)。
- 平台熟悉:注册 Kaggle 账号,逛「Competitions」页面,看比赛规则、数据格式、提交要求(如提交文件是.csv,含 ID 和预测值)。
三、入门实战:从「简单比赛」开始
新手别碰高难度比赛(如复杂深度学习、大奖金赛),先选「入门友好型」比赛练手,目标是:跑通「数据→模型→提交」全流程,理解每个环节。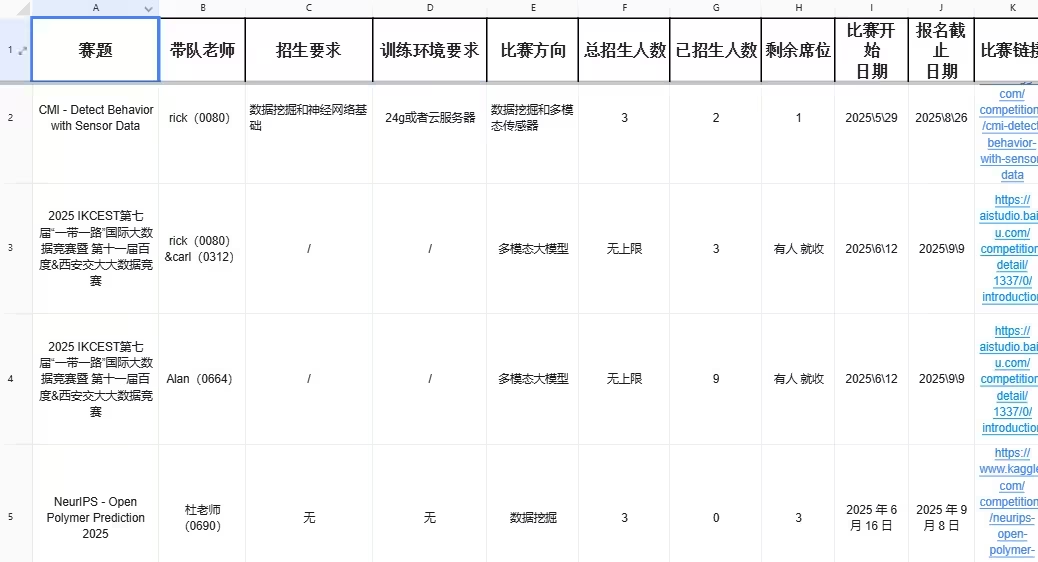
1. 选对比赛:3 类适合新手的竞赛
- Getting Started 比赛:Kaggle 官方入门赛,难度极低,有详细教程,比如:
- Titanic: Machine Learning from Disaster(经典入门,预测乘客是否存活,数据量小,适合练手)
- House Prices: Advanced Regression Techniques(预测房价,适合学回归问题)
- Playground 比赛:模拟真实场景,数据干净、任务明确,无奖金但竞争压力小,比如 Kaggle Playground Series。
- Tutorial 比赛:带官方教程的比赛,比如 Digit Recognizer(手写数字识别,含基础教程,适合入门图像分类)。
2. 核心步骤:以「Titanic」为例
以经典的 Titanic 比赛为例,走一遍完整流程:
(1)理解任务和数据
- 任务:根据乘客信息(如年龄、性别、票价),预测是否存活(分类问题)。
- 数据:比赛页面提供
train.csv(带标签,用于训练模型)和test.csv(无标签,用于预测并提交),还有data_description.txt说明字段含义(如Survived是标签:1 = 存活,0 = 死亡)。
(2)数据探索(EDA:Exploratory Data Analysis)
核心目的:了解数据特征(如哪些字段重要?有没有缺失值?),为后续建模做准备。
- 用 Pandas 加载数据:
import pandas as pd; train = pd.read_csv('../input/titanic/train.csv') - 看数据基本信息:
train.info()(字段类型、缺失值)、train.describe()(数值型字段的均值、标准差等)。 - 分析特征与标签的关系:比如画性别与存活率的柱状图(女性存活率远高于男性),年龄与存活率的箱线图(儿童存活率高)—— 这些发现会指导后续特征工程(如保留「性别」「年龄」作为重要特征)。
工具:用 Seaborn 画图,如 sns.countplot(x='Sex', hue='Survived', data=train)
(3)数据预处理
真实数据往往有「脏数据」,需要处理后才能喂给模型:
- 缺失值:比如年龄有缺失,可用均值 / 中位数填充(
train['Age'].fillna(train['Age'].mean(), inplace=True))。 - 分类变量转数值:模型只认数字,比如性别(男 / 女)转 0/1(
train['Sex'] = train['Sex'].map({'male':0, 'female':1}))。 - 特征选择:删掉无关特征(如乘客名字
Name对预测存活可能没用,可暂时去掉)。
(4)建模:从简单模型开始
新手别追求复杂模型(如深度学习),先用「基础模型」跑通流程:
- 选模型:Titanic 是分类问题,用逻辑回归(
LogisticRegression)或随机森林(RandomForestClassifier)。 - 训练模型:用训练集的特征(
X_train)和标签(y_train)训练:
from sklearn.linear_model import LogisticRegression
# 提取特征和标签(假设已处理好)
X_train = train[['Pclass', 'Sex', 'Age', 'Fare']] # 选几个特征
y_train = train['Survived']
# 训练
model = LogisticRegression()
model.fit(X_train, y_train) 5)预测与提交
- 用训练好的模型预测测试集(
test.csv):
X_test = test[['Pclass', 'Sex', 'Age', 'Fare']] # 测试集特征(格式和训练集一致)
predictions = model.predict(X_test) # 预测结果(0或1) 生成提交文件:按比赛要求的格式(如PassengerId+Survived)保存为.csv:
submission = pd.DataFrame({
'PassengerId': test['PassengerId'],
'Survived': predictions
})
submission.to_csv('submission.csv', index=False) # 保存 - 提交:在比赛页面上传
submission.csv,等待评分(Kaggle 会用测试集的真实标签计算准确率)。
3. 进阶:学习他人思路
第一次提交成绩可能很低,没关系!关键是看「高分 Notebook」学习优化方法:
- 在比赛页面的「Notebooks」栏,筛选「Top」或「Most Votes」的代码,看别人如何:
- 做更深入的 EDA(如发现「头衔(Mr/Mrs)」和存活率相关);
- 更精细的特征工程(如合并特征、处理缺失值的技巧);
- 调参(如用
GridSearchCV优化随机森林的参数); - 集成模型(如多个模型结果加权融合,提升分数)。
模仿→修改→创新:把别人的代码复制到自己的 Notebook,逐行理解,尝试改一个特征或换一个模型,看分数变化。
四、进阶:从「练手」到「竞争」
当熟悉流程后,可尝试:
- 复杂模型:如 XGBoost、LightGBM(结构化数据常用,效果优于基础模型);
- 特征工程:深入挖掘特征(如时间序列数据的滞后特征、文本数据的词向量);
- 参加正式比赛:如「Tabular Playground Series」(定期更新,适合结构化数据练习),或行业相关比赛(如医疗、NLP)。
五、关键心态
- Kaggle 的核心是「学习」,而非获奖。即使排名低,只要搞懂每个步骤的原理,就是进步。
- 别怕复现别人的代码,新手初期「模仿」是最快的成长方式。
- 多逛论坛(比赛页面的「Discussion」),看大家讨论的难点(如数据中的坑、优化思路)。
按这个路径走,1-2 个月就能从「完全不懂」到「独立完成简单比赛」,后续再根据兴趣(如深度学习、NLP)专攻细分领域即可。
需要老师带队的同学扫下方二维码或者
关助我的VX服务号【迪哥谈AI】暗号【8C】了解有哪些AI竞赛
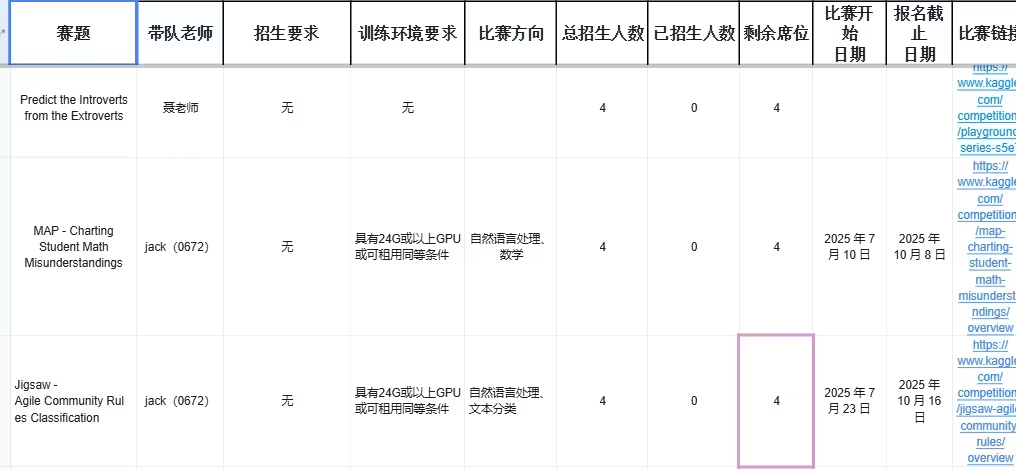
Jigsaw - Agile Community Rules Classification
比赛链接:https://www.kaggle.com/competitions/jigsaw-agile-community-rules/overview
方向:自然语言处理
MAP - Charting Student Math Misunderstandings
链接:https://www.kaggle.com/competitions/map-charting-student-math-misunderstandings/overview
方向:自然语言处理


















 577
577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









