







在这篇文章中,将向您展示使用 Kaggle 的真实数据集 FitBit Fitness Tracker Dataset 构建和训练自己的神经网络模型是多么容易。
将使用一些熟悉的日常用户活动作为数据集(如 TotalSteps、TotalDistance 和 VeryActiveMinutes)中的特征来构建和训练神经网络模型。而且,您还可以使用新数据集预测总卡路里消耗量。
假设您具备 Python、PyTorch 的基本知识以及神经网络的一些基本概念。除此之外,我建议您按照这篇文章进行操作,在这篇文章结束时,您将能够构建和训练自己的神经网络,您可以针对其他用例进一步自定义它。
您可以通过以下 6 个简单的步骤轻松实现这一切。
第 1 步:导入所需的库
第一步是导入下面给出的必需的类、函数和模块。有关各个项目的更多详细信息,将在本文后面的相应实施期间提供。在运行下面的导入代码之前,请确保您已安装最新版本的 Python 和 PyTorch。
import torch
import pandas as pd
import numpy as np
import torch.nn as nn
from torch.utils.data import DataLoader, TensorDataset
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
第2步 :加载和准备数据
首先,下载 FitBit Fitness Tracker 数据集。使用 panda 函数将数据集文件dailyActivity_merged.csv加载到 DataFrame 变量中,如下所示,并验证数据是否加载成功。
# You can give your own file path where you've saved the csv file
fitbit_df = pd.read_csv("/content/dailyActivity_merged.csv")
# Displays first 5 row of the csv file
fitbit_df.head()

上述 DataFrame 中的特征数量相当多。出于训练目的,我们将特征的数量减少到 6 个。但是,不建议减少生产应用程序的特征。通过进一步提高准确性,该模型将通过更多特征更好地学习。
features = [ 'TotalSteps', 'TotalDistance','VeryActiveDistance', 'ModeratelyActiveDistance','VeryActiveMinutes', 'FairlyActiveMinutes','Calories']
fitbit_df = fitbit_df[features]
# All the feature value must be numerical. Network doesn't process non-numerical data.
fitbit_df.head()

注意:由于数据来自 Kaggle ,因此已经对其进行了预处理。我不需要在此处执行任何进一步的预处理步骤。但是,如果要使用此模型对其他原始数据进行训练,则必须在进一步处理数据以进行训练之前对数据执行一些预处理操作。数据质量对于任何模型提供高质量结果都非常重要。他们说“垃圾进,垃圾出”。
接下来,我们将fitbit_df字段拆分为输入 X 和输出 y 及其值。此外,将这两个变量转换为 PyTorch 张量。将所有数据转换为 PyTorch 张量将进一步避免潜在的数据类型不匹配问题。
X = torch.tensor(fitbit_df.drop(columns=["Calories"], axis=1).to_numpy(), dtype=torch.float)
y = torch.tensor(fitbit_df["Calories"].to_numpy(), dtype=torch.long)
# Verify X, y value
print("Input tensors: ", X[:5], "\n")
print("Output tensors: ", y[:5], "\n\n")
print("Shape of input tensor: ", X.shape)
print("Shape of ouput tensor: ", y.shape)

现在,为了准备模型的训练、验证和测试数据,我们将这个数据集拆分为 3 个数据集,训练 - 80%、验证 -10% 和测试 10% 的数据。我们将使用sklearn.model_selection模块中的 train_test_split 函数来执行 split 操作。
X_train, X_eval, y_train, y_eval = train_test_split(X, y, test_size=0.2, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_eval, y_eval, test_size=0.5, random_state=42)
# Shape of dataset before split
print("Shape of input tensor: ", X.shape)
print("Shape of ouput tensor: ", y.shape, "\n")
# Shape of train, val, and test dataset after split. The sum total is same as original dataset.
# And each dataset still has 6 features which is the expected result
print("Train input: ", X_train.shape, "Train output: ", y_train.shape)
print("Val input: ", X_val.shape, "Val output: ", y_val.shape)
print("Test input: ", X_test.shape, "Test output: ", y_test.shape)
 功能标准化:如果您注意到功能 TotalSteps 的值在 4 位数字范围内,而 TotalDistance 和 VeryActiveDistance 等功能的值在 1 位数字范围内。这种巨大的范围差距会影响训练过程的不顺利,如果不管理此问题,甚至可能导致发散。因此,我们通过执行数据规范化操作来解决此问题。
功能标准化:如果您注意到功能 TotalSteps 的值在 4 位数字范围内,而 TotalDistance 和 VeryActiveDistance 等功能的值在 1 位数字范围内。这种巨大的范围差距会影响训练过程的不顺利,如果不管理此问题,甚至可能导致发散。因此,我们通过执行数据规范化操作来解决此问题。
归一化特征的一种常见方法是应用平均值 0 和标准差,如下所示。
# Calculate mean
mean_train = X_train.mean(dim=0)
mean_val = X_val.mean(dim=0)
mean_test = X_test.mean(dim=0)
# Calculate standard deviation
std_train = X_train.std(dim=0)
std_val = X_val.std(dim=0)
std_test = X_test.std(dim=0)
# apply mean and std to the input dataset
X_train = (X_train - mean_train)/ std_train
X_val = (X_val - mean_val)/ std_val
X_test = (X_test - mean_test)/ std_test
print("Normalized X_train: ", X_train[:5], "\n")
print("Normalized X_val: ",X_val[:5], "\n")
print("Normalized X_train: ",X_test[:5], "\n")

我们将为训练、验证和测试张量数据的每一对(输入、输出)创建一个 TensorDataset。TensorDataset 是包装张量的 PyTorch 功能,在许多情况下非常有用,例如创建 DataLoader,这是我们接下来要创建的。
train_dataset = TensorDataset(X_train, y_train)
val_dataset = TensorDataset(X_val, y_val)
test_dataset = TensorDataset(X_test, y_test)
# show how train_dataset looks like
print(train_dataset[0])

DataLoader 将数据集和采样器组合在一起,并在给定数据集上提供可迭代对象。如果训练数据非常庞大,则逐个迭代单个训练数据将花费大量时间,同样,由于处理资源限制,一次训练所有数据实际上是不可能的。DataLoader 通过允许定义批量大小来解决这个问题,这可以使模型一次批量训练多个训练数据。我们将为训练、验证和测试数据集分别创建一个数据加载器,对于此模型,batch_size定义为 as10。shuffle=True,帮助对批处理中出现的数据进行随机排序,以更好地进行训练和学习。
# Creating dataloader for each train, val and test dataset
train_loader = DataLoader(train_dataset, batch_size=10, shuffle=True, drop_last=True)
val_loader = DataLoader(val_dataset, batch_size=10, shuffle=False, drop_last=True)
test_loader = DataLoader(test_dataset, batch_size=len(test_dataset.tensors[0]), shuffle=False, drop_last=True)
# showing first batch of train_loader
for X, y in train_loader:
print("Shape of first batch of train_loader input : ", X.shape)
print("Shape of first batch of train_loader output : ", y.shape)
break

第 3 步:定义模型
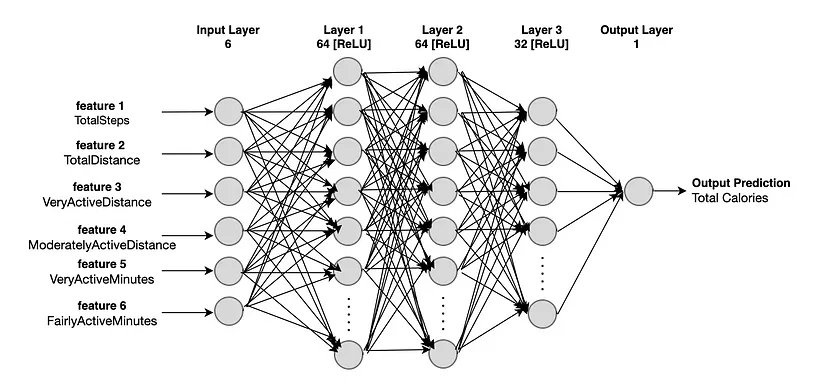
现在,我们将开始从 PyTorch nn.模块。没有特定的规则来规定层数和每层中的节点数。通常,需要多轮反复试验才能找到有效的正确数字。一条经验法则是,网络应该足够小以便快速处理,并且应该足够大以高精度解决预期问题。
我们的模型由 3 层、3 个激活函数和 1 个输出层组成。
1、模型的第一层 layer1 从输入数据中获取in_feature值。它应该是特征或输入向量维度的总数,即 6。在我们的例子中,in_features = X_train.shape[1]。
2、第一层 - layer1 有 64 个节点。layer1 后面是第一个激活函数或激活层(在深度学习文献中可以互换使用)- activation1。我们使用 ReLU 作为激活函数,就其性能而言,这是一个流行的选择,并且还避免了梯度消失问题。ReLU 为前一层的线性输出提供非线性,这对于模型在训练期间更好地学习非常重要。
3、第二层 - layer2 有 64 个节点。另一个激活层 - activation2 是在 layer2 之后添加的。
4、激活 2 之后,是第三层 layer3,它有 32 个节点。在 layer3 之后添加另一个激活层 activation3。
5、输出层有 1 个节点,因为我们在这里处理一个回归任务。
class fitbit_model(nn.Module):
def __init__(self, input_features, output_class):
super(fitbit_model, self).__init__()
self.layer1 = nn.Linear(in_features=input_features, out_features=64)
self.activation1 = nn.ReLU()
self.layer2 = nn.Linear(in_features=64, out_features=64)
self.activation2 = nn.ReLU()
self.layer3 = nn.Linear(in_features=64, out_features=32)
self.activation3 = nn.ReLU()
self.output = nn.Linear(in_features=32, out_features=output_class)
def forward(self, x):
x = self.activation1(self.layer1(x))
x = self.activation2(self.layer2(x))
x = self.activation3(self.layer3(x))
return self.output(x)
6、所有层都已在 fitbit_model 类构造函数中定义。
7、super(fitbit_model, self).__init__()的父类 nn.Module 构造函数,并被调用以引导fitbit_model模型。
8、forward 函数将获取 Importing Tensor 并返回模型的输出 Tensor。
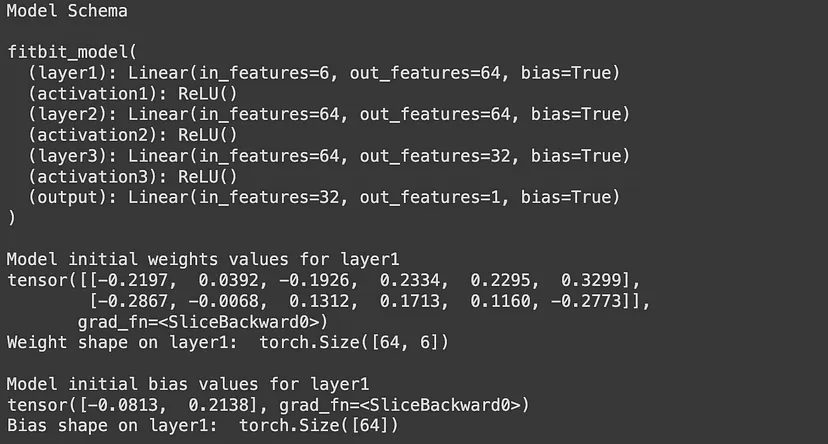
接下来,通过向 fitbit_model 构造函数提供 input features value 和 output class value 来初始化模型。最初,权重和偏置 es 参数由模型本身自动初始化(分配一些随机值)(值如下所示)。这些参数值将在训练期间随后更新。
input_features = X_train.shape[1]
output_class = 1
model = fitbit_model(input_features, output_class)
print("Model Schema\n")
print(model)
print("\nModel initial weights values for layer1")
print(model.layer1.weight[:2])
print("Weight shape on layer1: ", model.layer1.weight.shape)
print("\nModel initial bias values for layer1")
print(model.layer1.bias[:2])
print("Bias shape on layer1: ", model.layer1.bias.shape)
第4步:训练和评估模型
首先,我们将定义损失函数、优化器、纪元总数和其他变量。
# Loss function and optimizer
loss_fn = nn.HuberLoss(delta=0.5)
optimizer = torch.optim.Adam(params=model.parameters(), lr=0.001)
# collecting metrics
train_losses = []
val_losses = []
# Total number of epochs
n_epochs = 100
1、loss_fn = nn.HuberLoss(delta=0.5):Huber Loss 是稳健回归中使用的损失函数。它是 MSE 和 MAE 的组合。delta 是定义 MAE 和 MSE 范围的超参数,该值会根据任务而变化。
2、optimizer = torch.optim.Adam(params=model.parameters(), lr=0.001):Adam 是最常用的优化算法之一,它保持当前状态,并将根据计算的梯度更新参数。它需要 [(model.parameters) — 可学习参数 (W 和 b)] 和学习率来确定模型应该学习多快或多慢才能实现平滑收敛。因此,应仔细选择学习率值。
3、n_epochs = 100:整个训练和验证周期将运行 100 次
最后,让我们开始训练和评估 100 个 epoch 的模型。
# Train and evaluate the model
for epoch in range(n_epochs):
# Train the model
model.train()
train_loss = 0.0
for x_batch, y_batch in train_loader:
# forward pass
y_pred = model(x_batch)
y_pred = torch.squeeze(y_pred)
y_batch = y_batch.float()
loss = loss_fn(y_pred, y_batch)
# backward pass
optimizer.zero_grad()
loss.backward()
# update weights
optimizer.step()
train_loss += loss.item()
train_losses.append(train_loss / len(train_loader))
# Evaluate the model
model.eval()
val_loss = 0.0
with torch.inference_mode():
for x_batch, y_batch in val_loader:
y_pred = model(x_batch)
y_pred = torch.squeeze(y_pred)
y_batch = y_batch.float()
loss = loss_fn(y_pred, y_batch)
val_loss += loss.item()
val_losses.append(val_loss/len(val_loader))
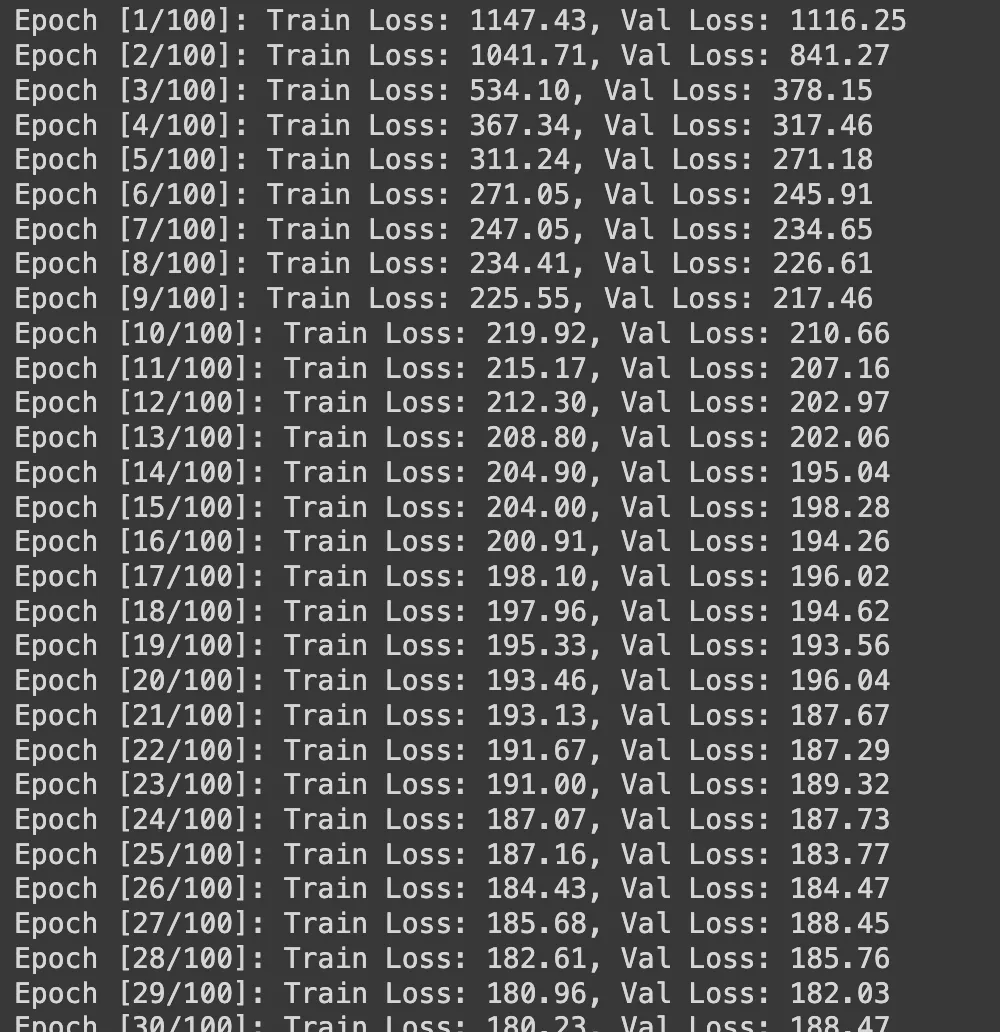
print(f'Epoch [{epoch+1}/{n_epochs}]: Train Loss: {train_losses[-1]:.2f}, Val Loss: {val_losses[-1]:.2f}')
1、model.train():将模型设置为训练模式。在训练模式下,PyTorch 会启用丢弃和批量规范化等功能,这些功能通常在训练期间使用,但在推理期间不使用。
2、在训练期间,训练数据将从 train_loader 中分批获取,并馈送到模型中进行推理。
3、loss = loss_fn(y_pred, y_batch):将计算 loss,即预测输出值与数据集真实值之间的差值。
4、optimizer.zero_grad():在开始执行反向传播之前,将梯度设置为零,因为 PyTorch 会在后续的反向传递中累积梯度。所以必须清除这一点。
5、loss.backward():在此步骤中,它会计算所有可学习参数的损失梯度。
6、optimizer.step() 的计算出梯度后, optimizer.step() 方法会更新所有参数。
7、train_losses.append(train_loss / len(train_loader)): 计算并累积每批后的训练损失。这将在稍后用于图形图中的分析。
8、model.eval():将模型设置为评估模式,并在评估期间。模型,它会禁用 dropout 等操作,因此可以专注于仅执行推理和测试。
9、使用 torch.inference_mode() 时:设置此模式后,autograd 不会跟踪梯度,因为在进行推理时不需要计算梯度。仅在训练期间才需要计算梯度。
10、val_losses.append(val_loss/len(val_loader)):每个批次后的验证损失将被计算并累积到 val_losses 数组中。这将在稍后用于 grap 图的分析
运行上述训练和评估代码部分后,您将看到损失值随着 epoch 数的增加而开始减少。
第5步:分析训练和评估结果
我们使用 matplotlib.pyplot 库函数来绘制结果并相应地进行分析。
plt.figure(figsize=(12,6))
plt.plot(train_losses, label="Train Loss")
plt.plot(val_losses, label="Validation Loss")
plt.ylabel("loss over Epochs")
plt.xlabel("Epoch")
plt.legend()
plt.show()
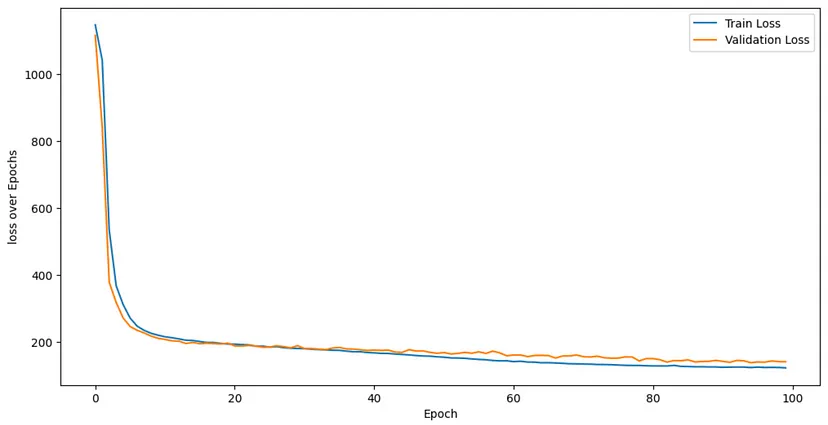
训练损失和验证损失在 20 个 epoch 之后都已显著减少。这个结果被认为是相当令人印象深刻的。为了获得更好的结果,您可以尝试增加训练数据和 epoch 的数量。
第 6 步:对新数据进行预测
最后,现在模型已经成功构建和训练,您一定很想知道我们的模型在新数据集上的表现如何。这是本文的主要目标之一。让我们试一试。
我们将使用一个名为 test_dataset 的新数据集,该数据集之前已经准备好,但直到此时才使用。现在,让我们使用它来进行预测。
# Predicting the test dataset
model.eval()
pred_val = []
target_val = []
with torch.inference_mode():
for x_test, y_test in test_loader:
y_test_pred = model(x_test)
pred_val.append(y_test_pred)
target_val.append(y_test)
让我们使用 matplotlib.pyplot 库函数绘制散点图,以分析新test_dataset的预测结果。
labels = torch.cat(target_val).flatten().tolist()
predictions = torch.cat(pred_val).flatten().tolist()
plt.scatter(labels, predictions)
max_lim = max(max(predictions), max(labels))
max_lim += max_lim * 0.1
plt.xlim(0, max_lim)
plt.ylim(0, max_lim)
plt.plot([0,max_lim], [0,max_lim], "b-")
plt.xlabel("True Values")
plt.ylabel("Predicted Values")
plt.tight_layout()
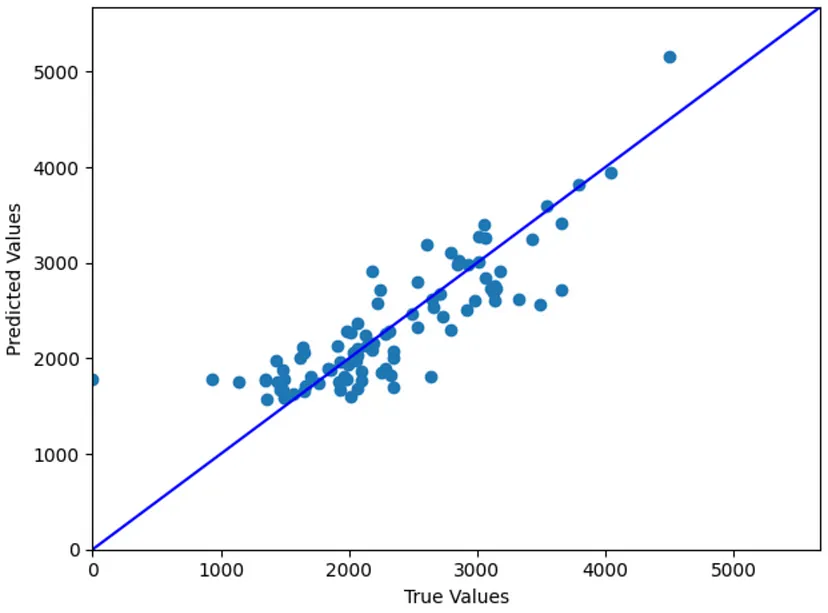
在此散点图中,您可以看到模型的预测值和数据集的真实值非常接近。因此,它证明我们构建和训练的模型在这方面已经相当好地泛化了
new test dataset. new test 数据集。
好了,恭喜你!您已使用 PyTorch 通过 Fitbit 训练数据集成功构建和训练了自己的神经网络。如果您已经编码,我非常有信心您可以轻松地构建模型并针对不同的使用案例使用任何数据进行训练。
Thanks for reading! 感谢阅读!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









