







神经网络是机器学习中用于识别模式和做出决策的大脑启发的计算模型。
神经网络解释
神经网络是一系列算法,旨在通过模拟人脑运作方式的过程来识别数据中的模式和关系。让我们来分析一下:
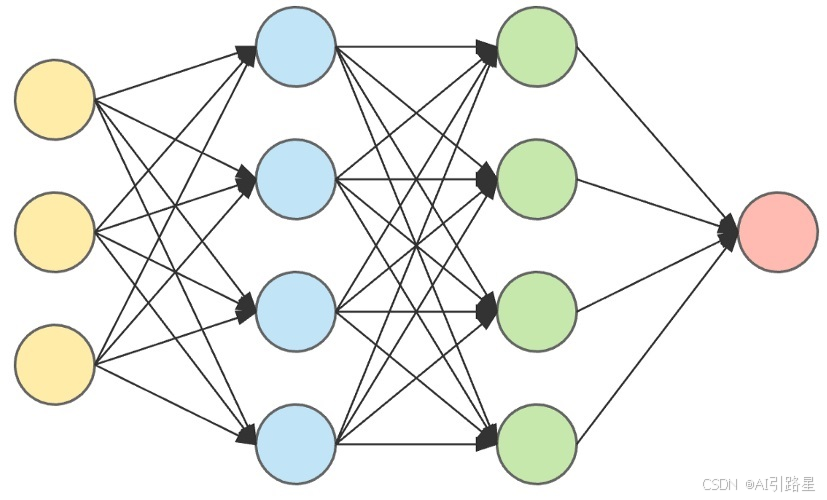
神经网络的核心由神经元组成,神经元是类似于脑细胞的基本单位。这些神经元接收输入,处理它们,并产生输出。它们被组织成不同的层:一个接收数据的输入层、几个处理这些数据的隐藏层,以及一个提供最终决策或预测的输出层。
这些神经元中的可调参数称为权重和偏差。随着网络的学习,这些权重和偏置会进行调整,从而确定输入信号的强度。这个调整过程类似于网络不断发展的知识库。
在训练开始之前,会调整某些设置(称为超参数)。这些决定了学习速度和训练持续时间等因素。它们类似于设置机器以获得最佳性能。
在训练阶段,向网络提供数据,根据其当前知识(权重和偏差)进行预测,然后评估其预测的准确性。此评估是使用损失函数完成的,该函数充当网络的记分器。做出预测后,损失函数会计算预测与实际结果的偏差有多远,训练的主要目标是最大限度地减少这种 “损失” 或错误。
反向传播在这个学习过程中起着关键作用。一旦确定了误差或损失,反向传播就会帮助调整权重和偏置以减少这种误差。它充当一种反馈机制,识别哪些神经元对错误贡献最大,并对其进行改进以获得更好的未来预测。
为了有效地调整权重和偏差,采用了 “gradient descent” 等技术。想象一下,在丘陵地形中穿行,您的目标是找到最低点。您所走的路径,总是朝着较低的点移动,由坡度下降引导。
最后,神经网络的一个重要组成部分是激活函数。此函数根据神经元输入的加权和偏差来决定是否应激活神经元。
为了可视化整个过程,请考虑一个经过训练以识别手写数字的神经网络。输入层接收手写数字的图像,通过其层处理图像,进行预测并完善其知识,直到它可以自信地识别数字。
神经网络是做什么用的?
神经网络具有广泛的应用范围,例如:
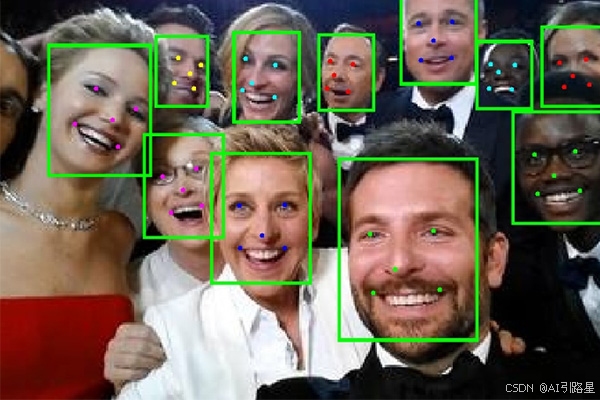
- 图像识别。Facebook 等平台使用神经网络来完成照片标记等任务。通过分析数百万张图像,这些网络可以非常准确地识别和标记照片中的个人。
- 语音识别。Siri 和 Alexa 等虚拟助手利用神经网络来理解和处理语音命令。通过在来自各种语言、口音和方言的大量人类语音数据集上进行训练,他们可以实时理解和响应用户请求。
- 医学诊断。在医疗保健领域,神经网络正在彻底改变诊断。通过分析医学图像,他们可以检测异常、肿瘤或疾病,通常比人类专家更准确。这在早期疾病检测中特别有价值,有可能挽救生命。
- 财务预测。 神经网络分析大量金融数据,从股票价格到全球经济指标,以预测市场走势并帮助投资者做出明智的决策。
虽然神经网络功能强大,但它们并不是一个放之四海而皆准的解决方案。它们的优势在于处理涉及大型数据集且需要模式识别或预测功能的复杂任务。但是,对于数据有限的简单任务或问题,传统算法可能更合适。例如,如果要对一小部分数字进行排序或在短列表中搜索特定项目,则基本算法将比设置神经网络更高效、更快捷。
神经网络的类型
有几种不同类型的神经网络专为特定任务和应用程序而设计,例如:
- 前馈神经网络。最直接的类型,其中信息仅沿一个方向移动。
- 递归神经网络 (RNN)。它们具有允许信息持久性的循环。
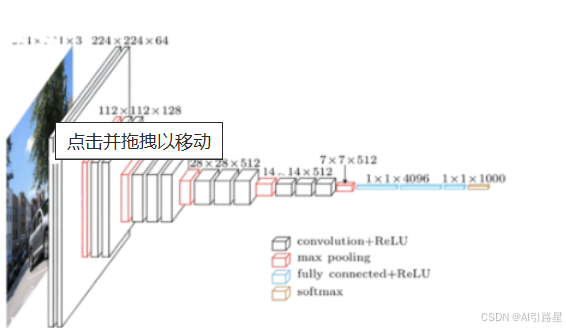
- 卷积神经网络 (CNN)。主要用于图像识别任务。
- 径向基函数神经网络。用于函数逼近问题
神经网络有哪些优势?
- 适应性。他们可以学习并做出独立决定。
- 并行处理。大型网络可以同时处理多个输入。
- 容错。即使网络的一部分出现故障,整个网络仍然可以运行。
神经网络的局限性是什么?
- 数据依赖性。它们需要大量数据才能有效运行。
- 不透明的自然。 通常被称为“黑匣子”,因为很难理解它们如何得出具体决策。
- 过拟合。他们有时可以记住数据,而不是从中学习。
神经网络与深度学习
虽然所有深度学习模型都是神经网络,但并非所有神经网络都是深度学习。深度学习是指具有三层或更多层的神经网络。这些神经网络试图模拟人脑的行为,使其能够从大量数据中“学习”。虽然具有单个层的神经网络可以进行近似预测,但额外的隐藏层可以帮助提高准确性。
构建神经网络项目的初学者指南
几年前,我参加了一门深度学习课程,并第一次体验了神经网络。我学会了如何使用几行代码构建自己的图像分类器,并惊讶地看到这些算法准确地对图像进行分类。
如今,情况已经发生了变化,初学者使用 TensorFlow和 pytorch等深度学习框架构建最先进的深度神经网络模型变得更加容易。您不再需要博士学位来构建强大的 AI。
以下是构建用于对猫和狗照片进行分类的简单卷积神经网络的步骤:
- 从 Kaggle 获取标记的猫和狗图像数据集。
- 使用 Keras作为深度学习框架。我相信它比 PyTorch 更容易让初学者理解。
- 导入 Keras、scikit-learn 和数据可视化库,如 Matplotlib。
- 使用 Keras 实用程序加载和预处理图像。
- 可视化数据 - 图像、标签、分布。
- 通过调整大小、旋转、翻转等来增强数据。
- 在 Keras 中构建卷积神经网络 (CNN) 架构。从简单开始。
- 通过设置要监控的损失函数、优化器和指标来编译模型。
- 训练模型进行多次迭代 (epoch) 以适应数据。
- 在测试集上评估模型准确性。
- 如果需要,请使用 ResNet 等预先训练的模型或添加层以提高准确性。
- 保存并导出经过训练的 Keras 模型。
TorchVision、Transformers 和 TensorFlow 等高级框架使构建图像分类器变得容易,即使对于初学者也是如此。只需一个小型标记数据集和 Google Colab,您就可以开始构建 AI 计算机视觉应用程序。

















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









