




在B站,UP主每天都会发布海量的视频、动态、专栏等内容,随之而来的是弹幕和评论区的各种讨论。
播放器中直接滚动播放的弹幕,如同调味剂,重在提升视频观看体验;
而点进评论区,相对而言评论文本更长,内容的观点、形式都更丰富,更像是饭后甜点。
随着业务不断发展,B站的评论系统逐渐组件化、平台化;
通过持续演进架构设计,管理不断上升的系统复杂度,从而更好地满足各类用户的需求。
评论的基础功能模块是相对稳定的。
- 发布评论:支持无限盖楼回复。
- 读取评论:按照时间、热度排序;显示评论数、楼中楼等。
- 删除评论:用户删除、UP主删除等。
- 评论互动:点赞、点踩、举报等。
- 管理评论:置顶、精选、后台运营管理(搜索、删除、审核等)。
结合B站以及其他互联网平台的评论产品特点,评论一般还包括一些更高阶的基础功能:
- 评论富文本展示:例如表情、@、分享链接、广告等。
- 评论标签:例如UP主点赞、UP主回复、好友点赞等。
- 评论装扮:一般用于凸显发评人的身份等。
- 热评管理:结合AI和人工,为用户营造更好的评论区氛围。
由于篇幅限制,只能给大家展示小部分内容,
全套面试笔记及答案【点击此处】即可免费获取
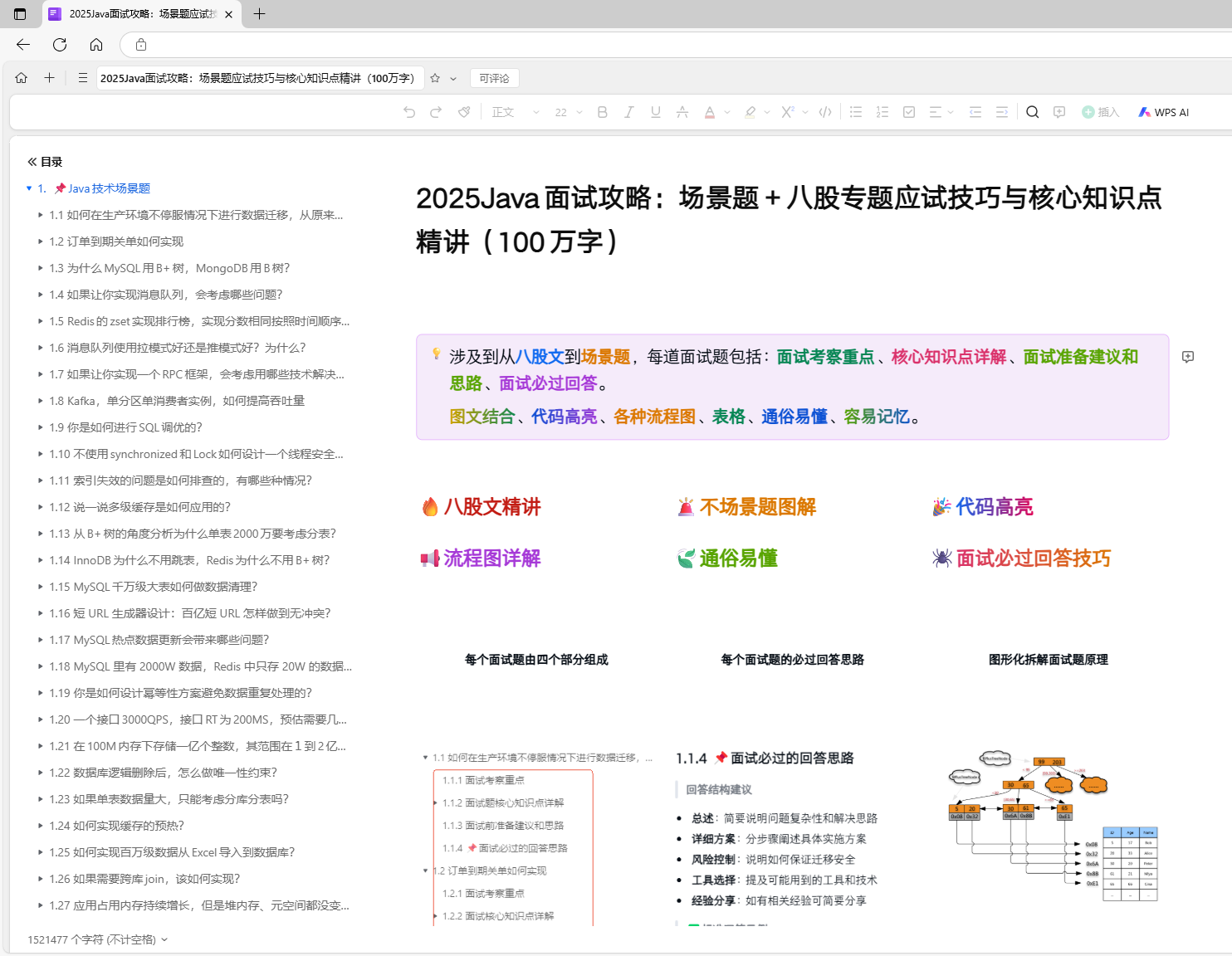
7.1 总体的架构设计
评论系统 中台,从总体的架构上来区分,分为:
(1)接入层
(2)服务层
(3)异步任务层
(4)cache层
(5)DB层
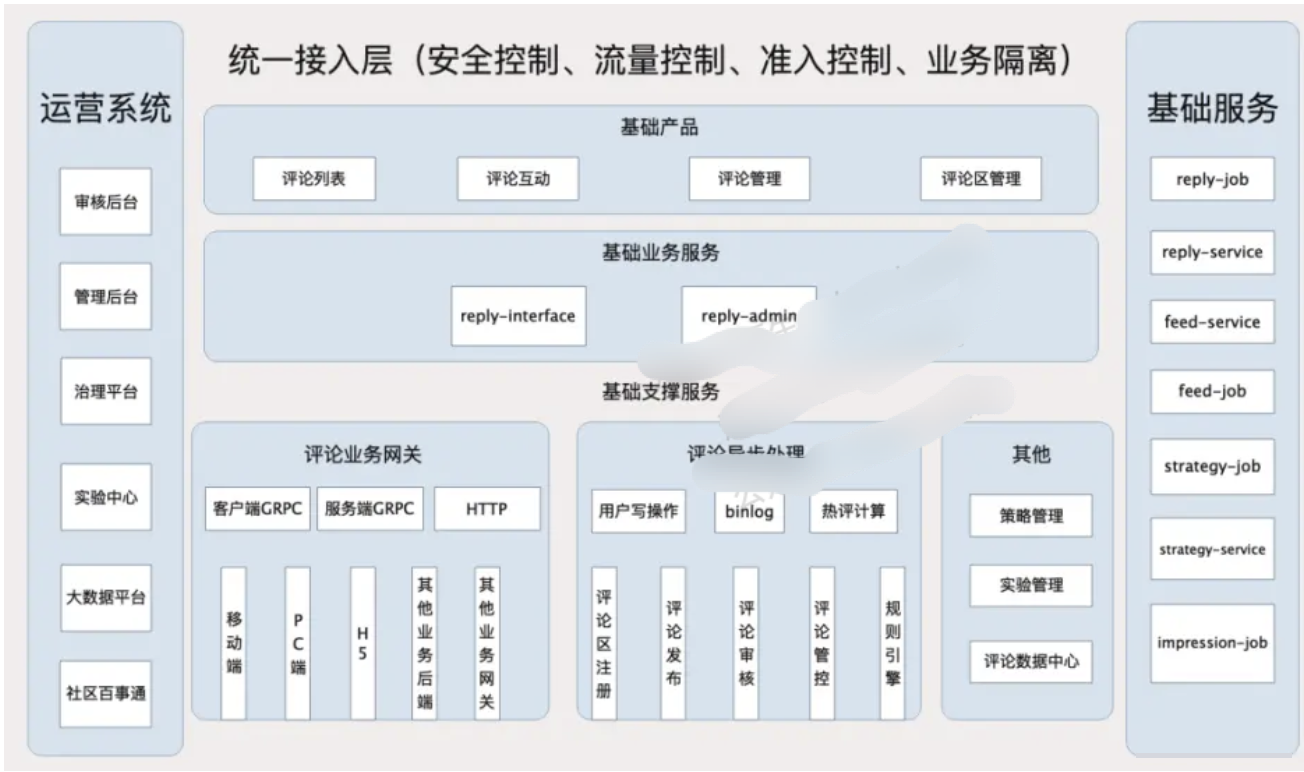
7.2 接入层架构 reply-interface
reply-interface是评论系统的接入层,主要服务于两种调用者:
一是客户端的评论组件,
二是基于评论系统做二次开发或存在业务关联的其他业务后端。
面向移动端/WEB场景,设计一套基于视图模型的API,利用客户端提供的布局能力,接入层负责组织业务数据模型,并转换为视图模型,编排后下发给客户端。
面向服务端场景,接入层设计的API需要体现清晰的系统边界,最小可用原则对外提供数据,同时做好安全校验和流量控制。
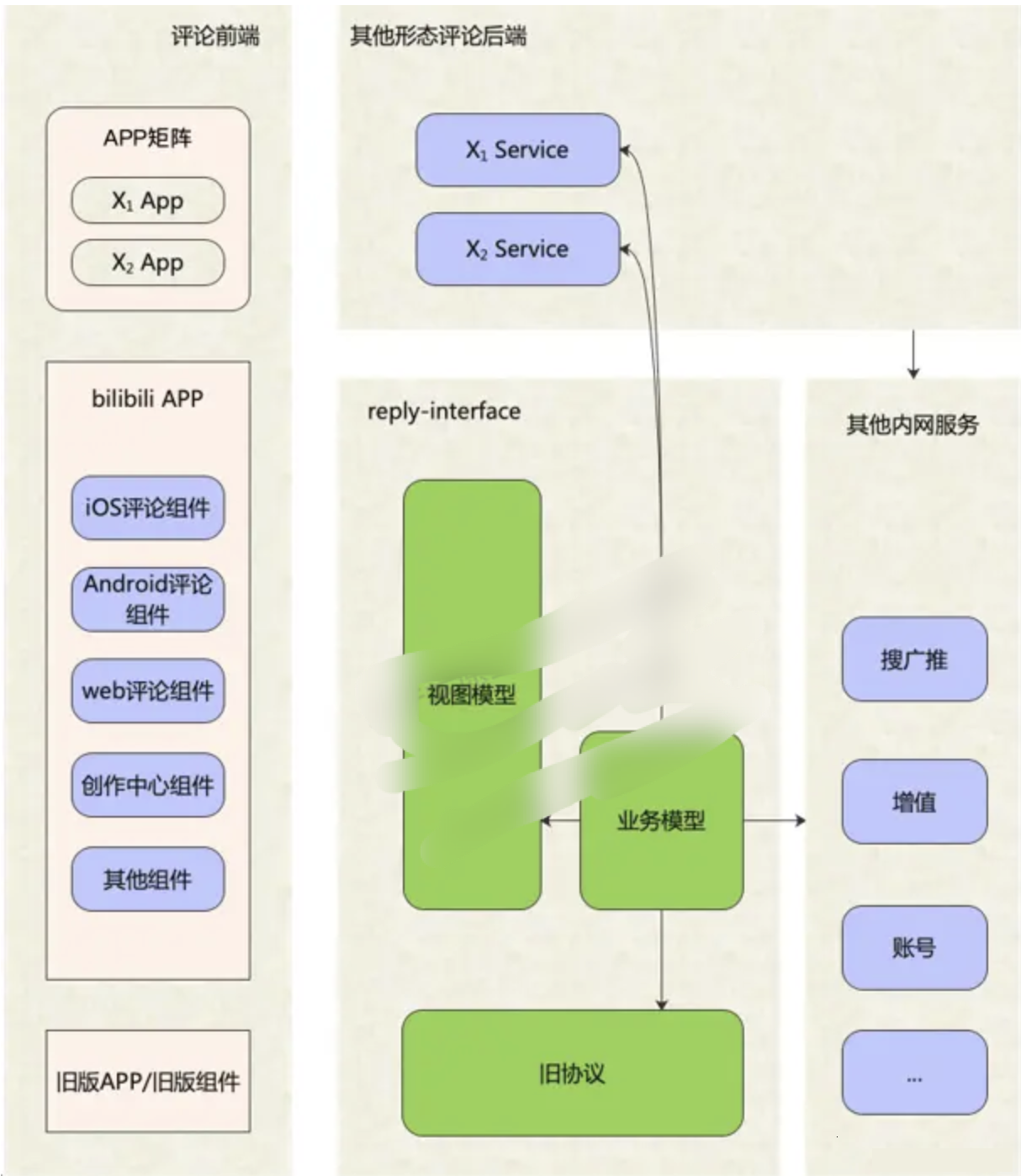
接入层整个业务数据模型组装,分为两个步骤:
一是服务编排,
二是数据组装。
服务编排拆的架构为:
(1)对服务进行分层,分为若干个层级,
(2)前置依赖通过流水线调用,
(3)同一层级的可以并发调用,结构性提升了复杂调用场景下的接口性能下限;
(4)针对不同依赖服务所提供的SLA不同,设置不同的降级处理、超时控制和服务限流方案,保证少数弱依赖抖动甚至完全不可用情况下评论服务可用。
SLA一般指服务级别协议。服务级别协议是指提供服务的企业与客户之间就服务的品质、水准、性能等方面所达成的双方共同认可的协议或契约。
7.3 服务层架构
7.3.1 评论管理服务层reply-admin
评论管理服务层,为多个内部管理后台提供服务。
运营人员的数据查询具有:
- 组合、关联查询条件复杂;
- 刚需关键词检索能力;
- 写后读的可靠性与实时性要求高等特征。
此类查询需求,ES几乎是不二选择。
但是由于业务数据量较大,需要为多个不同的查询场景建立多种索引分片,且数据更新实时性不高。
因此,我们基于ES做了一层封装,提供统一化的数据检索能力,并结合在线数据库刷新部分实时性要求较高的字段。
7.3.2 评论基础服务 reply-service 架构设计
评论基础服务层,专注于评论功能的原子功能,例如:
- 查询评论列表
- 删除评论等。
这一层的特点是:
- 较少做业务逻辑变更的,
- 极高的可用性
- 极高性能吞吐。
这一层采用了多种高性能方案:
- 多级缓存
- 布隆过滤器
- 热点探测等。
7.3.3 异步任务层reply-job 架构设计
异步任务层,主要有两个职责:
- 为原子的业务操作操作,提供异步协助
与reply-service协同,为评论基础功能的原子化实现做架构上的补充。
- 异步削峰处理
为 长耗时/高吞吐的调用, 做异步化/削峰处理
职责1:提供异步协助
为原子的业务操作操作,提供异步协助, 最典型的案例就是缓存的更新。
一般采用Cache Aside模式,先读缓存,再读DB;
Cache Aside模式下的缓存的重建策略:就是读请求未命中缓存穿透到DB,从DB读取到内容之后反写缓存。
这一套流程对外提供了一个原子化的数据读取功能。
但由于部分缓存数据项的重建代价较高,比如评论列表。
为啥呢?
由于列表是分页的,缓存重建时会启用预加载,也就是要多加载几页,
如果短时间内大量请求缓存未命中,并且多个服务节点的同时重建缓存,容易造成DB抖动。
解决方案是啥?
利用消息队列+reply-job ,实现单个评论列表异步重建,只重建一次缓存。
另外呢,reply-job还作为数据库binlog的消费者,执行缓存的更新操作。
职责2:异步削峰处理
与reply-interface协同,为 长耗时/高吞吐的调用,做异步化/削峰处理
诸如评论发布等操作,基于安全/策略考量,会有非常重的前置调用逻辑。
对于用户来说,这个长耗时几乎是不可接受的。同时,时事热点容易造成发评论的瞬间峰值流量。
因此,reply-interface在处理完一些必要校验逻辑之后,会通过消息队列送至reply-job异步处理,包括送审、写DB、发通知等。
那么异步处理后用户体验是如何保证的呢?
首先是当次交互,返回最新数据。
C端的发评接口会返回展示新评论所需的数据内容,客户端据此展示新评论,完成一次用户交互。
其次,控制延迟时长,如果太长则进行预警和调优
若用户重新刷新页面,因为发评的异步处理端到端延迟基本在2s以内,此时所有数据已准备好,不会影响用户体验。
7.3.4 消息队列的保证有序
利用了消息队列的「有序」特性,将单个评论区内的发评串行处理,避免了并行处理导致的一些数据错乱风险。
一个有趣的问题是,早年间评论显示楼层号,楼层号实际是计数器,且在一个评论区范围内不能出现重复。
因此,这个楼层发号操作必须是在一个评论区范围内串行的(或者用更复杂的锁实现),否则两条同时发布的评论,获取的楼层号就是重复的。
而分布式部署+负载均衡的网关,处理发评论请求是无法实现这种串行的,因此需要放到消息队列中处理。
7.4 数据存储架构
7.4.1 结构化模型设计
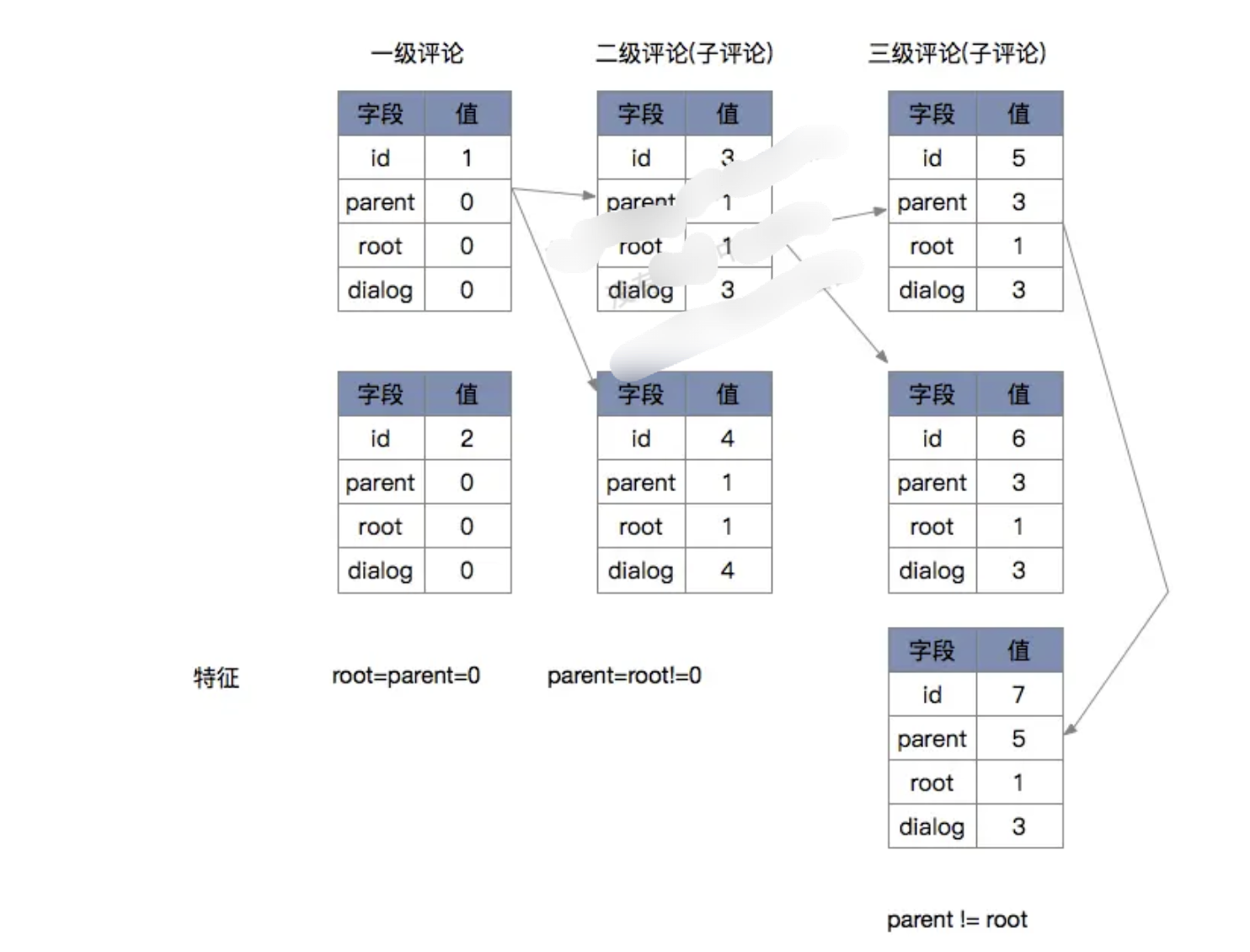
结合评论的产品功能要求,评论需要至少两张表:
(1)首先是评论表,主键是评论id,关键索引是评论区id;
(2)其次是评论区表,主键是评论区id,平台化之后增加一个评论区type字段,与评论区id组成一个”联合主键“。
(3)评论内容表. 由于评论内容是大字段,且相对独立、很少修改,因此独立设计第3张表。主键也是评论id。
评论表和评论区表的字段主要包括4种:
- 关系类,包括发布人、父评论等,这些关系型数据是发布时已经确定的,基本不会修改。
- 计数类,包括总评论数、根评论数、子评论数等,一般会在有评论发布或者删除时修改。
- 状态类,包括评论/评论区状态、评论/评论区属性等,评论/评论区状态是一个枚举值,描述的是正常、审核、删除等可见性状态;评论/评论区属性是一个整型的bitmap,可用于描述评论/评论区的一些关键属性,例如UP主点赞等。
- 其他,包括meta等,可用于存储一些关键的附属信息。
评论回复的树形关系,如下图所示:
以评论列表的访问为例,我们的查询SQL可能是(已简化):
- 查询评论区基础信息:SELECT * FROM subject WHERE obj_id=? AND obj_type=?
- 查询时间序一级评论列表:SELECT id FROM reply_index WHERE obj_id=? AND obj_type=? AND root=0 AND state=0 ORDER BY floor=? LIMIT 0,20
- 批量查询根评论基础信息:SELECT * FROM reply_index,reply_content WHERE rpid in (?,?,...)
- 并发查询楼中楼评论列表:SELECT id FROM reply_index WHERE obj_id=? AND obj_type=? AND root=? ORDER BY like_count LIMIT 0,3
- 批量查询楼中楼评论基础信息:SELECT * FROM reply_index,reply_content WHERE rpid in (?,?,...)
7.4.2 分库分表架构
评论系统对数据库的选型要求,有两个基本且重要的特征:
- 必须有事务;
- 必须容量大。
一开始,B站采用的是MySQL分表来满足这两个需求。MySQL分库分表数据量起来之后,原来的MySQL分表架构很快到达存储瓶颈。
提示:
mysql 不停服在线扩容实际非常复杂,很多公司选择停服切换, 估计B站为了不停服, 或者不愿意发生停服的风险, 选择了 专门的商用 分布式 TiDB, 毕竟这个是花了钱的。
于是从2020年起,我们逐步迁移到TiDB,从而具备了在线水平扩容能力。
7.4.3 高并发写入架构,TPS提升了10倍以上
面对10Wqps的并发写入超大规模吞吐量,做了如下优化:
方案一:内存聚合+ 批量写入评论区评论计数的更新,先做内存合并再更新,可以减少热点场景下的SQL执行条数;评论表的插入,改成批量写入。
方案二:核心逻辑和非核心异步化,为核心操作瘦身
非数据库写操作的其他业务逻辑,拆分为前置和后置两部分,
其他业务逻辑从数据写入主线程中剥离,交由其他的线程池并发执行。
总之,采用新的高并发写入架构之后,性能得到极大提升。
写入架构调整之后,系统的并发处理能力有了极大提升,同时支持配置并行度/聚合粒度,在吞吐方面具备更大的弹性,热点评论区发评论的TPS提升了10倍以上。
7.5 缓存层架构
7.5.1 数据的缓存模型架构
主要有3项缓存:
- subject,对应于「查询评论区基础信息」,
redis string类型,value使用JSON序列化方式存入。
- reply_index,对应于「查询xxx评论列表」,
redis sorted set类型。
member是评论id,score对应于ORDER BY的字段,如floor、like_count等。
- reply_content,对应于「查询xxx评论基础信息」
存储内容包括同一个评论id对应的reply_index和reply_content表的两部分字段。
7.5.2 缓存的一致性架构
缓存的一致性依赖binlog刷新,主要两个要点:
- 消息队列,保证 同一个评论区内有序
binlog投递到消息队列,分片key选择的是评论区,保证单个评论区和单个评论的更新操作是串行的,消费者顺序执行,保证对同一个member的zadd和zrem操作不会顺序错乱。
- 采用删除缓存而非直接更新的方式
程序主动写缓存和binlog刷缓存,都采用删除缓存而非直接更新的方式,避免并发写操作时,特别是诸如binlog延迟、网络抖动等异常场景下的数据错乱。
7.5.3 缓存击穿解决方案
那大量写操作后读操作缓存命中率低的问题如何解决呢?
读缓存的时候, 可以利用 锁的机制,进行同步控制,防止缓存击穿。
7.5.4 热点探测架构
除了写热点,评论的读热点也有一些典型的特征:
- 由于大量接口都需要读取评论区基础信息,存在读放大,因此该操作是最先感知到读热点存在的。
- 由于评论业务的下游依赖较多,且多是批量查询,对下游来说也是读放大。此外,很多依赖是体量相对小的业务单元,数据稀疏,难以承载评论的大流量。
- 评论的读热点集中在评论列表的第一页,以及热评的热评。
- 评论列表的业务数据模型也包含部分个性化信息。
在读取评论区基础信息阶段探测热点,并将热点标识传递至服务层;
服务层实现了页面请求级的热点本地缓存,感知到热点后即读取本地缓存,然后再加载个性化信息。
热点探测的实现基于单机的滑动窗口+LFU,那么如何定义、计算相应的热点条件阈值呢?
首先,我们进行系统容量设计,列出容量计算的数学公式,主要包括各接口QPS的关系、服务集群总QPS与节点数的关系、接口QPS与CPU/网络吞吐的关系等;
然后,收集系统内部以及相应依赖方的一些的热点相关统计信息,通过公式,计算出探测数据项的单机QPS热点阈值。
最后通过热点压测,来验证相应的热点配置与代码实现是符合预期的。

















 3774
3774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









