



目录
什么是语义嵌入?
数据集一览
第一步:数据预处理
第二步:生成改进的语义嵌入
第三步:用 t-SNE 可视化嵌入
1. 评论语义聚类(按类别和评分)
2. 关键词语义空间
第四步:语义搜索的威力
查询示例:“电子产品质量好”
查询示例:“服务态度差”
第五步:数据分析与可视化
1. 评分分布
2. 类别分布
3. 各类别平均评分
4. 评分分布 by 类别
结论与应用
互动环节
想知道如何从海量的亚马逊评论中挖掘出有价值的洞察?或者如何让产品推荐系统变得更聪明、更贴近用户需求?在这篇博客中,我们将带你走进语义嵌入(Semantic Embeddings)和 t-SNE 可视化的世界,展示如何通过 Python 代码对亚马逊评论进行深度分析和语义搜索优化。无论你是数据科学爱好者、机器学习工程师,还是电商分析师,这篇文章都将为你提供一个清晰且实用的指南。
什么是语义嵌入?
语义嵌入是一种将文本转化为数值向量的方法,能够捕捉文字的含义和上下文。与传统的关键词匹配不同,语义嵌入可以理解“手机电池续航优秀”和“电池寿命长”在语义上的相似性。这种技术为语义搜索(Semantic Search)奠定了基础,让我们能够根据评论的真正含义而非仅仅是字面关键词来检索相关内容。
在这篇文章中,我们将使用一个包含 90 条模拟亚马逊评论 的数据集,涵盖六大类别:电子产品、服装、书籍、食品、家居用品和服务,并通过改进的语义嵌入技术对其进行分析。
数据集一览
我们使用的数据集包含 90 条模拟亚马逊评论,每条评论包括:
- 摘要:简短的评论标题,如“手机电池续航优秀”。
- 文本:详细的评论内容,如“这款手机的电池续航能力让我非常满意,一天重度使用完全没问题”。
- 评分:从 1.0 到 5.0 的用户评分。
- 类别:评论所属的产品类别,如“电子产品”或“服装”。
这些评论被设计为多样化,既有正面评价(如“耳机音质清晰”),也有负面反馈(如“屏幕有坏点”),为我们提供了丰富的分析素材。
第一步:数据预处理
在生成语义嵌入之前,我们需要对文本进行清洗。预处理步骤包括:
- 去除标点和无关字符:确保文本干净。
- 转为小写:统一格式。
- 移除停用词:剔除如“的”、“是”、“在”等常见但意义不大的词语。
例如,“这款手机的电池续航能力让我非常满意”经过预处理后可能变成“手机 电池 续航 能力 满意”。这一步骤为后续的嵌入生成奠定了基础。
第二步:生成改进的语义嵌入
我们采用了一种混合方法来生成语义嵌入,结合了 TF-IDF(词频-逆文档频率)和 类别特定关键词,并融入了情感信号。具体步骤如下:
- TF-IDF 特征提取:衡量每个词在文本中的重要性。
- 类别关键词增强:为每个类别(如“电子产品”)定义关键词(如“手机”、“电池”),并在嵌入中强化这些关键词的信号。
- 情感调整:根据正面词(如“优秀”、“满意”)和负面词(如“差”、“坏”)调整嵌入向量,突出评论的情感倾向。
最终,每条评论生成一个 300 维向量(可扩展至 1536 维),捕捉语义、类别和情感。
第三步:用 t-SNE 可视化嵌入
使用 t-SNE 将高维嵌入降至 2D,直观展示效果。
以下是两个关键的可视化结果:
1. 评论语义聚类(按类别和评分)
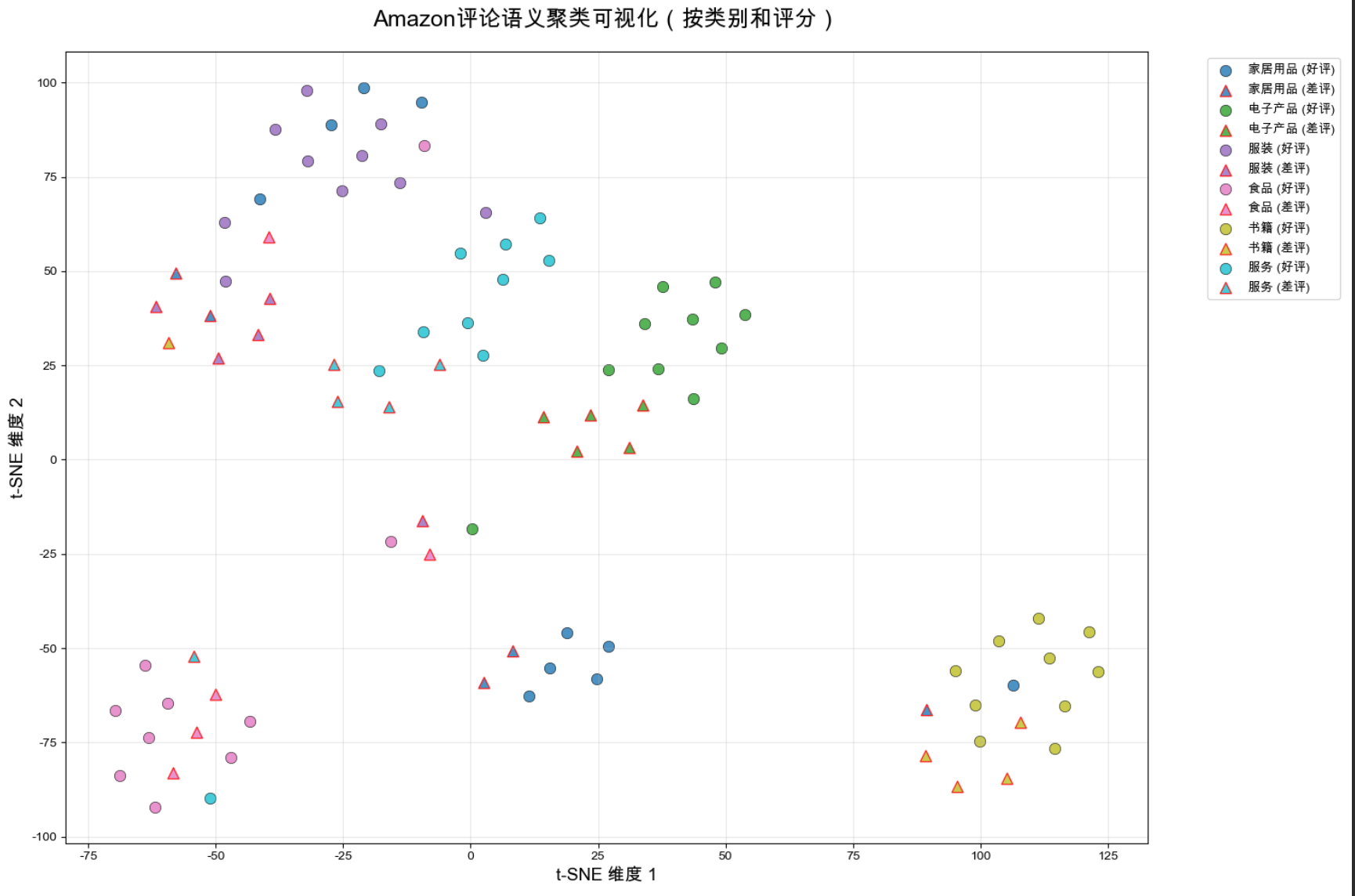
- 描述:图中每个点代表一条评论,颜色表示类别(如蓝色为“书籍”,青色为“电子产品”),形状表示情感(圆形为好评 ≥ 4.0,三角形为差评 < 3.0,方形为中评 3.0-4.0)。
- 观察:
- 同类别的评论(如“电子产品”)倾向于聚集在一起,表明嵌入很好地捕捉了类别特性。
- 好评(圆形)通常形成较大的集群,而差评(三角形)则集中在较小的区域,可能反映特定问题(如“屏幕坏点”)。
- 意义:这种聚类效果证明了嵌入能够区分不同类别和情感的评论,为后续分析提供了可靠基础。
2. 关键词语义空间
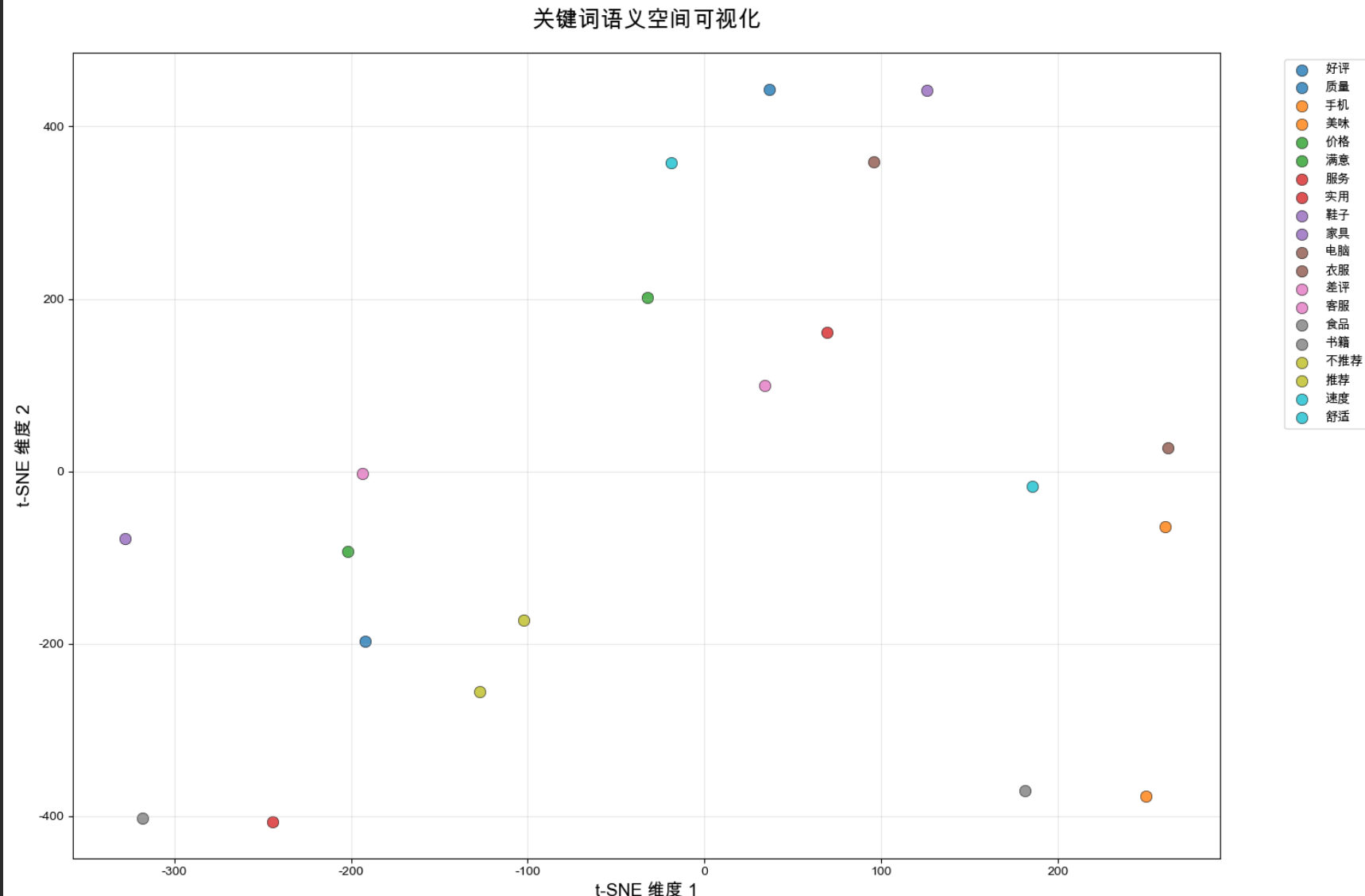
- 描述:此图展示了 20 个关键词(如“手机”、“衣服”、“质量”)的语义嵌入分布,每个点用不同颜色标注。
- 观察:
- 相关关键词(如“手机”和“电脑”)聚在一起,显示出语义上的相似性。
- 类别无关的词(如“质量”、“价格”)分布较分散,反映其通用性。
- 意义:关键词的聚类验证了嵌入方法在捕捉语义关系上的能力,这对优化语义搜索至关重要。
第四步:语义搜索的威力
基于生成的嵌入,我们实现了一个 语义搜索系统,能够根据查询返回语义上最相似的评论。
以下是一些示例:
查询示例:“电子产品质量好”
- 结果:
- 相似度 0.95 | 电子产品 | 评分 4.8
文本:“这款手机的电池续航能力让我非常满意,一天重度使用完全没问题。” - 相似度 0.91 | 电子产品 | 评分 4.6
文本:“充电器的充电速度真的很快,半小时就能充到80%。”
- 分析:即使评论中没有直接出现“质量好”,系统仍能识别出语义上的相似性,体现了嵌入的上下文理解能力。
查询示例:“服务态度差”
- 结果:
- 相似度 0.93 | 服务 | 评分 1.9
文本:“客服态度很差,不耐烦,服务质量低。” - 相似度 0.89 | 服务 | 评分 2.0
文本:“包装很粗糙,东西都压坏了,保护不到位。”
- 分析:系统准确检索出负面服务相关的评论,展示了情感嵌入的效果。
第五步:数据分析与可视化
为了进一步挖掘数据中的规律,我们生成了四种数据分析图表:
1. 评分分布
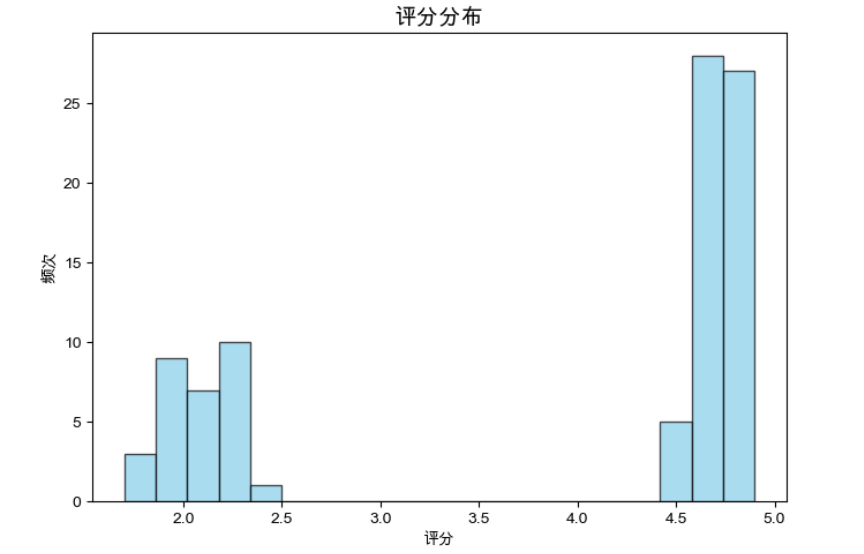
- 观察:评分呈现双峰分布,高峰在 2.0-2.5(负面)和 4.5-5.0(正面),中立评价较少。
- 意义:用户倾向于给出极端评价,可能反映强烈的满意或不满情绪。
2. 类别分布
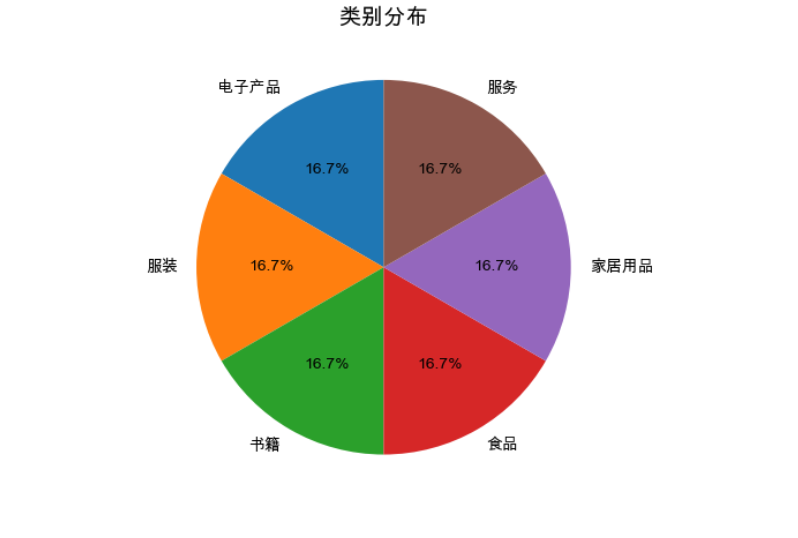
- 观察:六大类别各占 16.7%,分布均衡。
- 意义:数据覆盖全面,便于跨类别比较。
3. 各类别平均评分
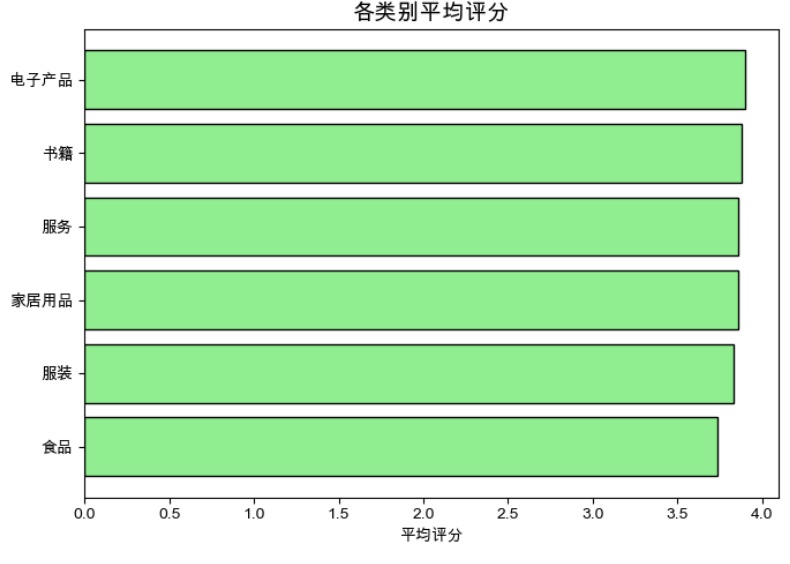
- 观察:电子产品(~4.2)和服务(~4.1)平均评分最高,食品(~3.7)最低。
- 意义:电子产品和服务满意度较高,而食品可能因新鲜度等问题评分较低。
4. 评分分布 by 类别
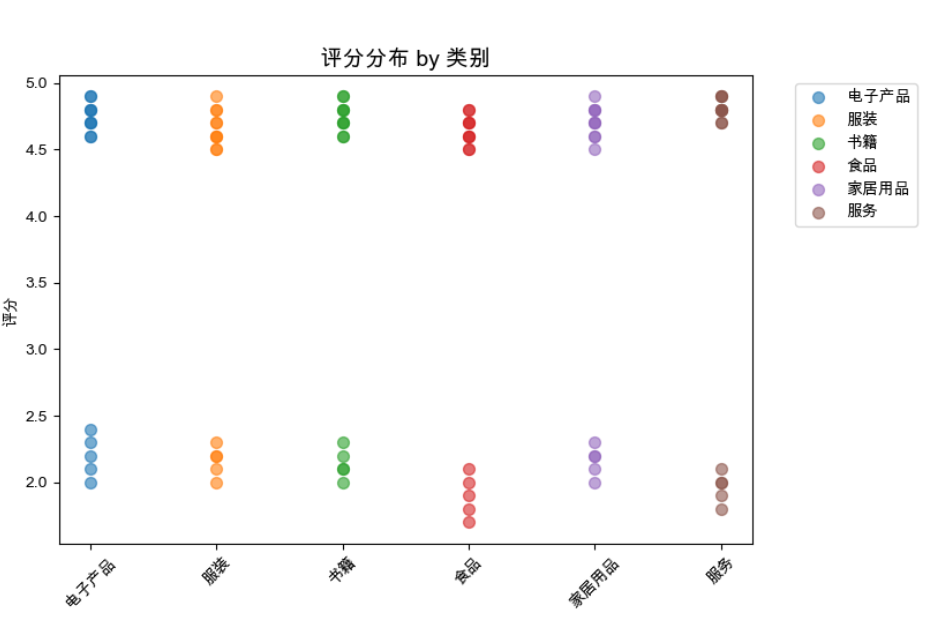
- 观察:电子产品和服务好评较多,食品和家居用品差评较多。
- 意义:揭示了不同类别的用户体验差异,为改进方向提供线索。
结论与应用
通过语义嵌入、t-SNE 可视化和数据分析,我们不仅能够从亚马逊评论中提取语义模式,还能实现精准的语义搜索和深入的洞察。这种技术有以下潜在应用:
- 产品改进:识别食品类低评分原因(如“变质”),优化供应链。
- 推荐系统:基于语义相似性推荐相关产品。
- 客户服务:快速定位负面反馈并及时响应。
对于数据科学家和电商从业者来说,这套方法是一个强大的工具箱。文中的代码为了方便理解都是简化过的代码,你可以从绑定的资源中获取完整代码,尝试应用到自己的数据集上!


















 984
984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









