 11步实践:用大语言模型构建知识图谱
11步实践:用大语言模型构建知识图谱





知识图谱作为一种高效的数据表示方法,能够将大数据中分散的信息连接成结构化、可查询的格式,显著提升数据发现效率。实践表明,采用知识图谱技术可将数据探索时间减少多达70%,从而极大地优化数据分析流程。
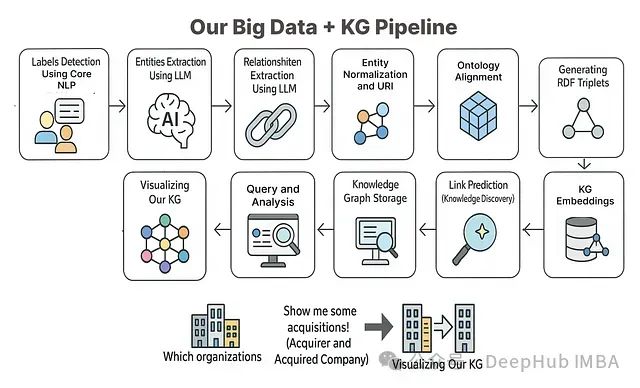
本文将基于相关理论知识和方法构建一个完整的端到端项目,系统展示如何利用知识图谱方法对大规模数据进行处理和分析。
环境配置与依赖安装
首先,我们需要安装必要的Python库以支持后续的开发工作。以下是所需的关键依赖包:
安装完成后,为确保所有依赖正常加载,可能需要重启Jupyter内核或运行环境。接下来,我们导入所有必要的库:
至此,我们已完成开发环境的准备工作,所有必要的库已成功导入。
数据集概述与加载
本项目使用CNN/DailyMail数据集作为研究对象。该数据集包含超过30万篇新闻文章及其对应的人工撰写摘要,是进行实体、关系和事件提取的理想资源。
使用Hugging Face datasets库加载数据集:
我们选择版本"3.0.0",这是该数据集的最新稳定版本。下面打印数据集的基本信息:
通过输出可知,该数据集包含311,971篇新闻文章,这是一个相当庞大的语料库。从中提取有价值的洞察确实是一项具有挑战性的任务,而知识图谱正是解决此类问题的有效工具。
数据获取与预处理
构建知识图谱时,直接处理整个包含30万多篇文章的数据集既不高效也不切实际,因为并非所有内容都具有相关性。更为合理的做法是将数据按主题或领域分割为子集,如技术新闻、体育新闻等,分别构建相应的知识图谱。
在大数据处理流程的早期阶段,将数据分解为更易管理的部分是一项关键步骤。对于新闻文章数据集,我们可以采用基于关键词的方法进行初步筛选。
首先定义与技术公司收购相关的关键词集合:
这些关键词是在文本分析中常见的术语,我们预先定义它们以简化处理流程。接下来,使用这些关键词从训练集中筛选相关文章:
现在检查过滤后的文章数量并查看其中一个样本:
通过关键词筛选,我们将数据集缩减至约65,000篇文章。接下来需要对这些文章进行清洗处理,移除不必要的信息。这一步骤尤为重要,因为这些数据将作为输入传递给大语言模型(LLM),过多的冗余信息会影响处理效率和成本。
在新闻数据清洗过程中,我们需要移除链接、不必要的特殊字符、发布渠道名称等元素:
这些清洗步骤基于对数据的观察和分析,旨在保留关键信息的同时最大限度地减少每篇文章的大小,为后续的知识图谱构建做好准备。
使用核心NLP技术定义实体标签
步骤1:实体标签检测
当前我们有65,000多篇新闻文章,从中提取实体是一项具有挑战性的任务。尽管可以使用大语言模型(LLM)从每个文本段落中提取实体,但首先需要确定LLM应该关注哪些类型的实体。
如果没有明确的指导,LLM可能会从每个文本块中提取不同类型的实体,导致结果不一致。为解决这个问题,我们需要使用自然语言处理(NLP)技术来定义一个固定的实体类型集合,作为LLM的提取依据。
虽然有多种方法可以实现这一目标,包括使用嵌入和其他高级技术,但本项目将采用预训练的SpaCy模型作为基础方法。该模型将分析我们的数据,提取实体标签,然后我们将使用这些标签指导LLM提取特定类型的实体:
打印实体计数情况:
为了更直观地了解数据中的实体分布情况,我们可以绘制这些标签的柱状图:
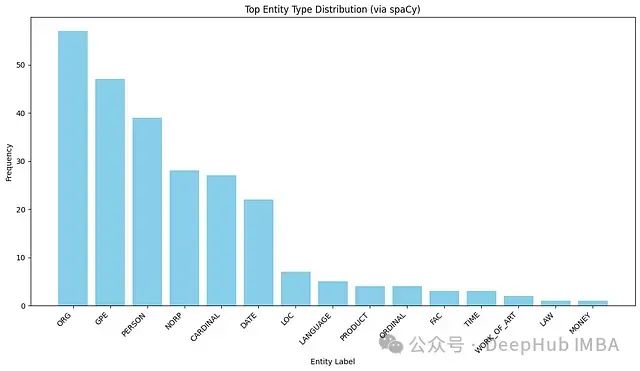
目前我们使用的是SpaCy的小型模型(en_core_web_sm),如需提取更深入、更准确的实体标签,可以考虑切换到更大的模型。这些实体标签将作为指导,帮助我们的大语言模型(如Microsoft的Phi-4)从文章中提取相关实体。
步骤2:实体(节点)提取
实体作为知识图谱中的节点,需要从文本中精确提取。为此,我们需要定义一个系统提示(指导LLM如何处理使用SpaCy提取的实体类型)、用户提示(即文章内容)以及其他必要组件。
首先,建立与LLM的连接:
接下来,创建一个辅助函数,用于打包请求并发送给LLM。该函数接收系统提示、用户提示(文章文本)和模型名称作为参数:
现在,我们需要创建一个系统提示。我们将使用Python的f-string格式化,动态插入从entity_counts.keys()获取的实体类型列表:
此系统提示将指导LLM以有效的JSON格式输出实体数据。在创建主处理循环前,我们需要一个JSON解析器函数,将文本输出转换为有效的JSON格式:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2491
2491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









