



作者: 数据源的TiDB学习之路
第一章:HBase 的历史使命与技术瓶颈
1.1 HBase 的核心价值与经典场景
作为 Hadoop 生态的核心组件,HBase 凭借 LSM-Tree 存储引擎 和 Region 分片机制,在 2010 年代成为海量数据存储的标杆。其典型场景包括:
- 日志流处理:支持 Kafka 每日 TB 级数据持久化,写入吞吐达百万级 QPS(如某头部社交平台日均处理 2PB 日志)。
- 实时检索:基于 RowKey 实现用户行为数据毫秒级查询(如电商订单追踪,单表行数超千亿)。
- 时序数据管理:物联网设备监控数据的高并发写入与近实时分析(如某车联网平台每秒写入 10 万条 GPS 数据)。
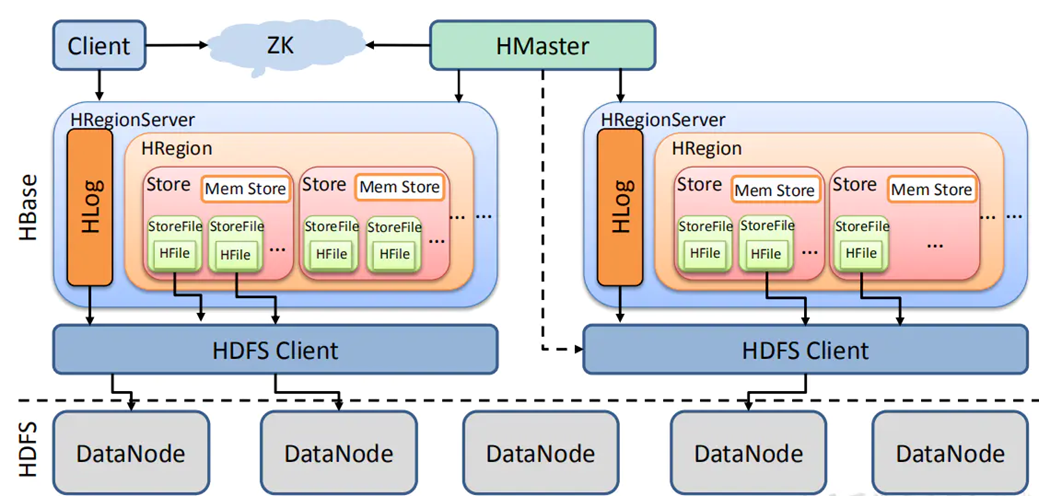
HBase 经典架构(Master-RegionServer)
1.2 HBase 的 “数据黑洞”
随着业务复杂度提升,HBase 的局限性逐渐成为企业发展的 “数据黑洞”:
功能缺失与生态补丁
HBase 的核心设计聚焦于 “存储” 而非 “计算”,导致关键功能缺失:
- 事务支持薄弱:仅支持单行事务,跨行操作需依赖应用层补偿(如幂等设计)。
- 查询能力局限:原生不支持 SQL,复杂查询需通过 Phoenix 等工具扩展,JOIN 操作需手动实现。
- 二级索引缺失:全局索引需自行构建(如 Coprocessor 监听数据变更),维护成本极高。
运维复杂度与隐性成本
- 版本升级困境:跨版本升级常需停机数小时,且配置兼容性问题频发(如 HDFS 与 ZooKeeper 版本依赖)。
- Compaction 性能波动:Minor/Major Compaction 触发时,磁盘 I/O 和 CPU 资源争抢导致查询延迟陡增。
- 跨集群容灾成本:若需构建同城双活,需部署 6 副本(主集群 3 副本 + 灾备集群 3 副本),存储开销翻倍。
社区衰退与替代技术冲击
- 人才断层:HBase 的 API 设计偏向底层(如 Java 原生客户端),学习曲线陡峭,新兴开发者更倾向选择兼容 MySQL 的分布式数据库。
- 生态替代:随着 NewSQL 数据库(如 TiDB、CockroachDB)和 云原生数仓(如 Snowflake、BigQuery)的崛起,HBase 在 HTAP 场景中的竞争力逐渐削弱。
第二章:TiDB 的架构革新与降维优势
2.1 TiDB 的 “三位一体” 架构
随着 Google Spanner 和 NewSQL 理论的提出,以 TiDB 为代表的原生分布式数据库成为技术新趋势。TiDB 不仅继承了 HBase 的水平扩展能力,还深度融合了关系型数据库的 SQL 生态与事务特性。TiDB 以 NewSQL 架构重构分布式数据库范式,实现三大核心突破:
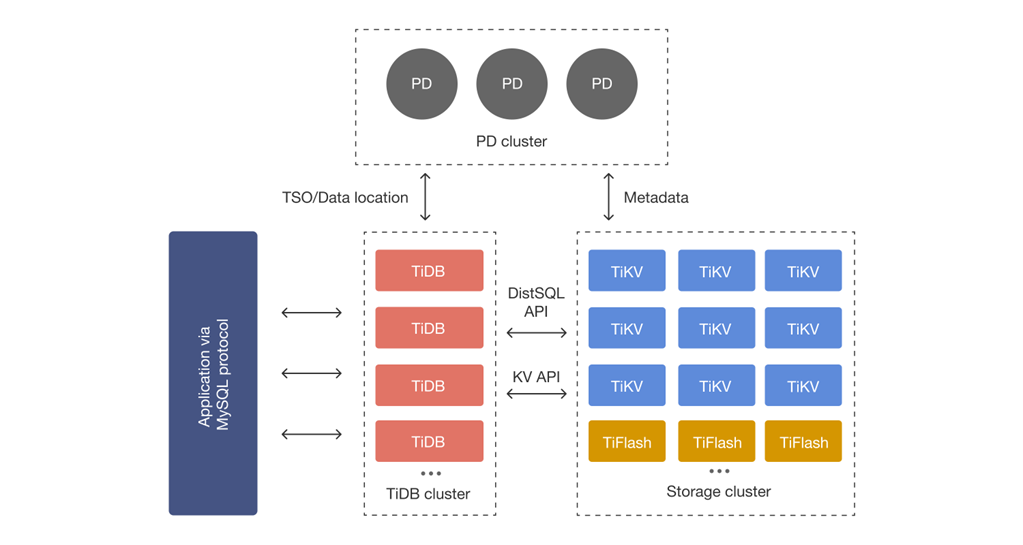
TiDB 分层架构(TiDB Server + TiKV + PD)
突破 1:HTAP 混合引擎
- 行存(TiKV):面向 OLTP,支持 ACID 事务与高并发写入(单集群 TPS 50万+,某支付系统峰值处理 10 万笔/秒交易)。
- 列存(TiFlash):面向 OLAP,列存引擎加速复杂查询(TPC-H 性能提升 10 倍,某物流企业实时分析响应时间从分钟级降至秒级)。
突破 2:弹性扩缩容
- 计算与存储分离:TiDB Server(无状态)与 TiKV(有状态)独立扩展,扩容耗时 <10 分钟(某游戏公司应对活动流量仅需新增 3 节点)。
- 自动负载均衡:PD 实时监控热点,数据分片动态迁移(支持 Region 合并与分裂,某电商平台自动规避热点后查询延迟降低 60%)。
突破 3:全栈生态兼容
- MySQL 协议兼容:支持 JDBC/ORM 框架、BI 工具无缝对接(兼容度 99%,某企业迁移后 BI 报表代码零修改)。
- 多云与信创适配:兼容 AWS/Azure/华为云,支持鲲鹏、飞腾等国产芯片(某政务系统通过 TiDB 完成信创改造,国产化率 100%)。
2.2 TiDB vs HBase:核心能力对比矩阵
架构设计对比
维度 | HBase | TiDB | 说明 |
存储依赖 | 依赖 Hadoop HDFS 存储,ZooKeeper 协调服务 | 自研存储引擎 TiKV 和 TiFlash(RocksDB 优化 + Raft 协议) | TiDB 摆脱 Hadoop 生态依赖,简化架构,降低运维复杂度。 |
存储模型 | 列式存储(KV 模型,基于 LSM-Tree) | 行列混合引擎(HTAP) | TiDB 支持 OLTP 行存与 OLAP 列存,实现实时分析与事务处理一体化。 |
扩展能力 | 水平扩展 RegionServer | 水平扩展 TiKV/TiDB 节点 | 两者均支持无缝扩展,但 TiDB 的自动负载均衡机制更高效。 |
功能特性对比
维度 | HBase | TiDB | 说明 |
SQL 支持 | 不支持 SQL,需通过 Phoenix 扩展 | 完整支持 ANSI SQL(兼容 MySQL 协议) | TiDB 可直接使用 JOIN、子查询等复杂语法,降低开发门槛。 |
二级索引 | 需手动实现(如 Coprocessor) | 支持全局二级索引(强一致性) | TiDB 的索引更新与事务同步,避免 HBase 的最终一致性问题。 |
事务支持 | 仅单行事务 | 分布式强一致性事务(Percolator 协议) | TiDB 支持跨节点 ACID 事务,适用于订单、账户等金融场景。 |
生态兼容性 | 依赖 Hadoop 生态(如 Hive、Spark) | 完全兼容 MySQL 生态(ORM 框架、BI 工具) | TiDB 无缝对接 MySQL 客户端,业务代码无需改造。 |
性能与高可用对比
维度 | HBase | TiDB | 说明 |
查询分析能力 | 弱(仅支持 RowKey 查询) | 强(支持混合负载 HTAP) | TiDB 通过 TiFlash 列存引擎加速 OLAP,性能提升 3-10 倍。 |
性能稳定性 | 因 Compaction 和 Region 分裂导致波动 | 基于 TSO(全局时间戳)保障线性一致性 | TiDB 的查询延迟稳定在毫秒级,规避 HBase 的 Compaction 性能抖动。 |
容灾能力 | 主备容灾(需 6 副本) | 同城双活、两地三中心 | TiDB 支持跨地域多活,RPO=0,RTO<30 秒,满足金融级容灾要求。 |
数据副本机制 | 默认 3 副本 | 默认 3 副本,可扩展至 5 副本 | TiDB 支持灵活副本策略,兼顾成本与可用性。 |
高级功能与生态服务
维度 | HBase | TiDB | 说明 |
向量搜索 | 不支持 | 支持向量索引(ANN 算法) | TiDB 可集成 AI 场景,实现图搜、推荐等向量化检索。 |
多租户 | 不支持 | 基于资源组(Resource Group)隔离 | TiDB 通过 CPU、内存配额限制,实现 SaaS 化多租户管理。 |
全文检索 | 需集成 Solr/Elasticsearch | 新版本将支持全文索引能力 | TiDB 减少外部依赖,简化技术栈。 |
信创支持 | 非国产更非信创数据库 | 入选国家信创目录 | TiDB 适配鲲鹏、飞腾等国产芯片,支持麒麟、统信 OS。 |
社区与企业服务 | 社区活跃度低,无官方企业版 | 活跃社区(AskTug 论坛)+ 企业级 SLA 支持 | TiDB 提供原厂专家服务,保障生产环境稳定性。 |
第三章:迁移评估与方案设计
3.1 现有 HBase 集群现状分析
1. 集群规模与容量
- 某电商案例:
- 节点数:200 台(RegionServer)
- 总数据量:1.2 PB(三副本)
- 日均增量:80 TB
- 痛点:Region 分裂导致查询延迟波动,Compaction 期间 CPU 使用率 90%+。
2. 性能基线
- 写入性能:峰值 20 万 QPS(如秒杀场景)。
- 查询性能:简单 Get 操作平均 5ms,复杂 Scan 操作超时率 25%。
3. 集群架构

3.2 TiDB 容量与资源规划
1. 存储容量评估
2. 节点资源配置
组件 | 数量 | 硬件配置 | 说明 |
TiKV | 30 台 | 96 vCore / 512 GB / 8×3.84TB NVMe | 支持每秒 50 万次写入,P99 延迟 <20ms |
TiDB/PD | 10 台 | 64 vCore / 256 GB / 1TB SSD | 混合部署,PD 选举耗时 <500ms |
3.3 TiDB 架构设计
1. 部署架构
- 核心组件:
- TiKV:30 节点,负责数据存储与分布式事务处理。
- TiDB:10 节点,无状态 SQL 计算层,兼容 MySQL 协议。
- PD:嵌入 TiDB 节点,负责元数据管理与调度。
- 网络要求:万兆内网,保障低延迟通信与数据同步。
2. 高可用与容灾
- 数据副本:默认三副本,支持 Raft 协议自动故障切换。
- 容灾策略:支持同城双活、两地三中心部署,RPO=0,RTO<30 秒。
3. 部署架构图

3.4 数据迁移策略
1. 全量迁移方案
- 方案选择:
- 推荐方案:从源头 Oracle、Greenplum 等直接迁移至 TiDB,规避 HBase 中间层复杂度。
- 替代方案:从 HBase 导出数据至 TiDB(需处理动态列转换)。
- 实施步骤:
- 数据导出(以 Greenplum 为例):
- Greenplum 使用
COPY命令导出 CSV:
- HBase 使用
Export工具导出至 HDFS。
- 数据导入:
- 使用 TiDB Lightning 或
IMPORT INTO高效导入 CSV:
2. 增量同步方案
- 工具选择:
- DataX:定时同步 Greenplum 增量数据(基于
update_at字段)。 - CDC 工具:使用商业工具(如 Canal、Debezium)捕获 Greenplum/HBase 变更日志,实时同步至 TiDB。
3.5 应用迁移策略
1. 数据模型改造
方案1(推荐):从源头(以 Greenplum 为例)迁移到 TiDB
1. 表结构转换
- 数据类型映射:
Greenplum 类型 | TiDB 类型 | 说明 |
|
| 二进制数据直接映射。 |
|
| 高精度数值类型需保持精度一致。 |
|
| 长文本字段兼容。 |
|
| 注意时区处理,需统一使用 UTC 或业务时区。 |
- 主键与索引定义:
- Greenplum 的分布式表通过
DISTRIBUTED BY指定分布键,而 TiDB 自动分片,只需定义主键或唯一索引。 - 若原表无主键,需选择合适字段(如业务唯一标识)或新增自增列作为主键:
2. 约束与默认值调整
- 约束迁移:
Greenplum 的CHECK约束需在 TiDB 中显式定义(TiDB 部分版本可能不兼容复杂约束)。
- 默认值处理:
- Greenplum 的
DEFAULT CURRENT_TIMESTAMP可能需显式指定时区:
方案2:从 HBase 迁移到 TiDB
1. 表结构设计
- 列族与限定符转换:
将 HBase 的列族(Column Family)和列限定符(Column Qualifier)转换为 TiDB 的静态表结构。
- 稀疏列与动态列处理:
- 宽表模式:预定义可能用到的列(适合列数量有限场景)。
- 键值对表:动态列存储为键值对(适合灵活扩展场景)。
2. RowKey 优化
- 主键设计:将 HBase RowKey 转换为 TiDB 主键或唯一索引。
- 索引优化:对高频查询条件(如
user_id、region)添加组合索引。
2. 查询逻辑改造
1. 基础查询模式转换
- RowKey 查询 → 主键查询:
- 范围扫描 → 范围查询:
- 过滤器 → WHERE 子句:
2. 复杂查询优化
- JOIN 操作:
- 分页优化:
- 避免
LIMIT/OFFSET深度分页,改用游标分页(基于主键或索引)。
3、事务与一致性调整
1. 事务支持升级
- HBase 限制:仅支持单行事务。
- TiDB 优势:支持跨行分布式事务(Percolator 协议)。
2. 锁机制调整
- HBase:行锁保障并发安全,但锁粒度粗。
- TiDB:支持行级锁,避免长事务导致的锁竞争。
4、应用层代码改造
1. 客户端替换
- HBase API → JDBC/ORM:
2. ORM 框架适配
- MyBatis 示例:
- Hibernate 实体类:
3.6 迁移验证与回滚
1. 数据一致性校验
- 行数比对:
- 字段值抽样:对比关键字段(如金额、时间戳)是否一致。
2. 灰度发布策略
- 双写验证:并行写入 HBase 和 TiDB,对比结果。
- 流量切换:按业务模块逐步切流,监控延迟与错误率。
3. 回滚保障
- 数据保留:HBase 集群至少保留 1 个月。
- 快速回滚:若 TiDB 出现严重问题,可临时切回 HBase。
第四章:业务迁移标杆案例
案例 1 :中国银联 – T+0 交易综合查询平台
中国银联的 T+0 交易综合查询平台曾面临多重业务挑战:消费终端客户实时查询可疑交易的体验较差,核心交易库(DB2)难以同时满足 OLTP 高并发事务与 OLAP 复杂分析的需求,而原有 HBase 集群因查询时效性不足导致运维成本高企。
通过迁移至 TiDB,中国银联成功将 600 多节点的 HBase 集群压缩至 20 台 TiDB 机器,成本大幅降低;系统性能显著提升,99.9% 的请求延迟缩短至 15 毫秒以内,日均 QPS 达 35000 并实现毫秒级响应,客户查询体验全面优化。同时,TiDB 的 HTAP 混合负载能力支持每天 2 TB 增量数据的高效写入与实时分析,弹性扩容机制轻松应对业务增长,并通过分布式事务、高可用架构保障了数据一致性与服务稳定性。此外,TiDB 支持多源数据统一汇聚与 SQL 语义的高效分页查询,构建了集实时更新、复杂分析和统一查询于一体的综合平台,彻底解决了原有系统的性能瓶颈与功能局限。
案例 2: 微众银行 – MSS 业务
微众银行 MSS 业务作为全行 RMQ 消息报文调用的核心数据存储平台,承担着消息故障跟踪、服务治理等关键任务。原系统基于 HBase 构建,业务场景以高频写入为主(每日峰值 QPS 达 15 万,低峰 4 万,平均 10 万),需支持每天新增 50 TB(三副本)数据并存储 7 天(总量 350 TB),单行数据长度 1.2~2.4 KB。然而,HBase 架构存在显著痛点:不支持 SQL 语法导致开发效率低下,复杂查询需依赖额外关系型数据库;单一 RowKey 设计无法满足多条件检索,二级索引实现复杂且维护成本高;缺乏事务支持难以保障数据一致性;Region 分裂引发性能波动,影响查询稳定性;同时,集群高可用需依赖业务双写,逻辑复杂且运维压力大。此外,未来报表类需求难以在原有架构上扩展。
通过迁移至 TiDB,微众银行实现了全面升级:支持标准 SQL 语法大幅降低开发门槛,业务代码量减少 60% 以上;原生分布式事务确保数据强一致;灵活二级索引与多条件查询替代复杂 HBase 扫描逻辑,简化业务链路;HTAP 混合引擎为未来实时报表提供技术基础;跨机房高可用架构(无需业务双写)降低运维复杂度,资源利用率提升 40%;弹性扩缩容能力有效应对每日 50 TB 数据写入,存储成本较原 21 台 HDD 集群显著优化。TiDB 的引入不仅解决了 HBase 的性能与功能瓶颈,更为业务提供了面向未来的可扩展性支撑。
案例 3: 全球最大图片社交网站 Pinterest – 从HBase 到 TiDB
全球最大图片社交网站 Pinterest 的核心业务曾高度依赖 HBase,其覆盖智能推送、用户消息、广告索引、URL 爬虫、实时监控(Statsboard)等数十个关键场景,日均处理 PB 级数据。然而,HBase 架构的局限性日益凸显:维护成本高,跨版本升级需停机数小时;功能严重缺失,无法支持强一致性事务、全局二级索引,导致业务需额外引入复杂中间件;存储成本翻倍,主备集群 6 副本部署占用大量资源;社区生态衰退,人才稀缺且技术迭代停滞。
通过迁移至 TiDB,Pinterest 实现了革命性升级:融合 NoSQL 水平扩展与 RDBMS 强大能力,单集群即可支持每秒 14,000 次读取、400 次写入的高吞吐场景,并首次以 零停机 方式完成 4 TB 大表迁移;原生支持分布式事务与全局索引,简化业务链路,ACID 特性保障数据强一致;存储成本降低 60%,三副本机制替代原有冗余架构;无缝兼容 MySQL 生态,复杂查询效率提升 5 倍,且无需依赖外部系统。TiDB 的引入不仅解决了 HBase 的功能桎梏,更以弹性扩缩容、HTAP 混合负载等能力,为 Pinterest 构建了面向未来十年的一体化数据引擎。

















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









