



大家好,我是“蒋点数分”,多年以来一直从事数据分析工作。从今天开始,与大家持续分享关于数据分析的学习内容。
本文是第 7 篇,也是【SQL 周周练】系列的第 6 篇。该系列是挑选或自创具有一些难度的 SQL 题目,一周至少更新一篇。后续创作的内容,初步规划的方向包括:
后续内容规划
1.利用 Streamlit 实现 Hive 元数据展示、SQL 编辑器、 结合Docker 沙箱实现数据分析 Agent
2.时间序列异常识别、异动归因算法
3.留存率拟合、预测、建模
4.学习 AB 实验、复杂实验设计等
5.自动化机器学习、自动化特征工程
6.因果推断学习
7. ……
欢迎关注,一起学习。
第 6 期题目
题目来源:纯自创题目,受到《The SQL Murder Mystery》的启发,它是一个用 SQL 来寻找凶手的题目;我玩过之后,很受启发,想出一个【SQL 破案系列】,但是我想象力不够、文笔一般。剧情又要设计为 SQL 解题,只能放弃这个方向。今天拿出来一道之前设计的题目:尽管文笔和设计上有很多不足,但有点意思。最关键,我在 8 年的数据分析经历,从来没有在 SQL 中使用过三角函数,而这道题目就需要使用三角函数
一、题目介绍
大家可以先看看故事背景,这是两个多月前写的。写作方法是我提一个梗概,然后让 Deepseek 或者 Qwen 润色和发散;等它们返回来结果,我再吸收和更改;然后再提问再更改,如此往复五次以上。我还没有尝试过 Gemini 2.5 pro 或 GPT 来写。
对故事不感兴趣的同学可以跳过,只是故事情节对题目理解略有帮助:
有一张数据仓库的表,里面是道路影像视频资料根据 CV 算法分析得到的(咱这儿就当小说不管现实可行性)。表里有如下的数据:时间,车牌号,纬度,经度(假设摄像头拍到车牌后,根据单目测距算法和摄像头本身的坐标计算出车辆的坐标)
我们假设这个故事中摄像头密度很高,利用不同摄像头记录的车辆的坐标和时间差,计算这一小段距离的平均速度。如果平均速度在某个范围内视为“疑似踩点”,在另一个范围视为“正常行驶”;并且故事设计犯罪分子会驾车不多不少刚好围着作案地点附近绕行一圈,这样利用坐标的均值就可以求得“质心/中心点”。
题目规定就是求出这个“质心/中心点” —— 也就是谋划犯罪的地点。
列名 | 数据类型 | 注释 |
ts | string | 时间 (为了计算准确,这里精确到微秒) |
licence_plate | string | 车牌 |
lagtitude | double | 纬度 |
longtitude | double | 经度 |
is_case_the_join | tinyint | 是否有为踩点 (做题时不用,为了验证数据的 1-是,0-否) |
部分样例数据(完整生成逻辑参见第三节)
ts | licence_plate | lagtitude | longtitude | is_case_the_joint |
2025-06-01 09:45:40.846060 | J-9876 | 39.116034 | 117.194557 | 0 |
2025-06-01 09:45:44.176520 | J-9876 | 39.116105 | 117.194074 | 0 |
2025-06-01 09:45:47.831298 | J-9876 | 39.116346 | 117.194396 | 0 |
2025-06-01 09:45:52.131025 | J-9876 | 39.116621 | 117.194836 | 0 |
... | ... | ... | ... | ... |
... | ... | ... | ... | ... |
2025-06-01 10:13:39.177957 | J-9876 | 39.115997 | 117.195361 | 0 |
2025-06-01 10:13:43.865901 | J-9876 | 39.11603 | 117.194675 | 0 |
注意,模拟数据时为了简化,只设置了一个辆车即一个车牌,但是我写 SQL 的时候没有忽略掉这个维度,按照有多辆车的写法来处理。 另外,我在模拟数据时,让这个车绕了多个地点 —— 多个地方“踩点”。
二、题目思路
想要答题的同学,可以先思考答案🤔。
.……
.……
.……
我来谈谈我的思路,这道题目其实还是“断点分组”类问题 1.“断点分组”类问题,顾名思义,里面有两个词一个是“断点”一个是“分组”。“分组”最容易想到将一类有相同“维度”(分组标识)的数据放在一起统计,对于这道题目来说,就是“踩点”的某个“点”,那么这个属于这个“踩点”的所有轨迹点应该放在同一组,进而求平均得到“中心点”
2.“断点”体现在哪里?题目设计时,规定了犯罪分子驾车会有两个速度范围,一个是正常驾驶范围,一个是“踩点”低速驾驶行为(忽略在现实中的不合理性,因为这道题设计更偏趣味)。所以这两个速度范围的切换点,就是那个“断点”。就需要先求出来速度
3.摄像头拍到车,并给出坐标和时刻 —— 速度就是距离除以时间差,而距离需要用坐标来计算。如果是 Postgre、SQL Server 或者某些数据库,可能利用 GIS 的插件/函数来计算,我没有用过。而且此题目本意也是为了练习 Hive 三角函数,根据搜索,推荐使用 Haversine公式 来处理。
其中
对这个公式证明感兴趣的同学,可以自行搜索。说实话,我没看证明。我还尝试了类似平面坐标系中计算欧式距离和曼哈顿距离的方法:在 Python 中我验证了后两者的 Haversine 的差距,因为这些坐标之间本身就很近,使用欧式距离也可以处理。
有人论述过反正切计算开销大,若非必要可以近似求解 —— 感兴趣的同学可以自行搜索
下面,我用 NumPy 和 Scipy 生成模拟的数据集:
三、用 Python 生成模拟数据
只关心 SQL 代码的同学,可以跳转到第四节(我在工作中使用 Hive 较多,因此采用 Hive 的语法)
模拟代码如下: 1.引入必要的包,定义“踩点”和正常的速度范围,前者4~6m/s,后者8~16m/s:
2.path 指向的文件,里面存的数据是我在某网站一个一个点的坐标轨迹。使用 shift 函数移动一行,方便计算两个相邻行的距离:
3.定义 haversine 和近似计算 approx_distance的函数,并求结果进行对比。其中 haversine 的代码,抄的 —— 来源是,“模型视角”的《学点几何 | 计算球面距离的哈弗塞恩公式》;approx_distance 近似计算的方法,是我自己写的:
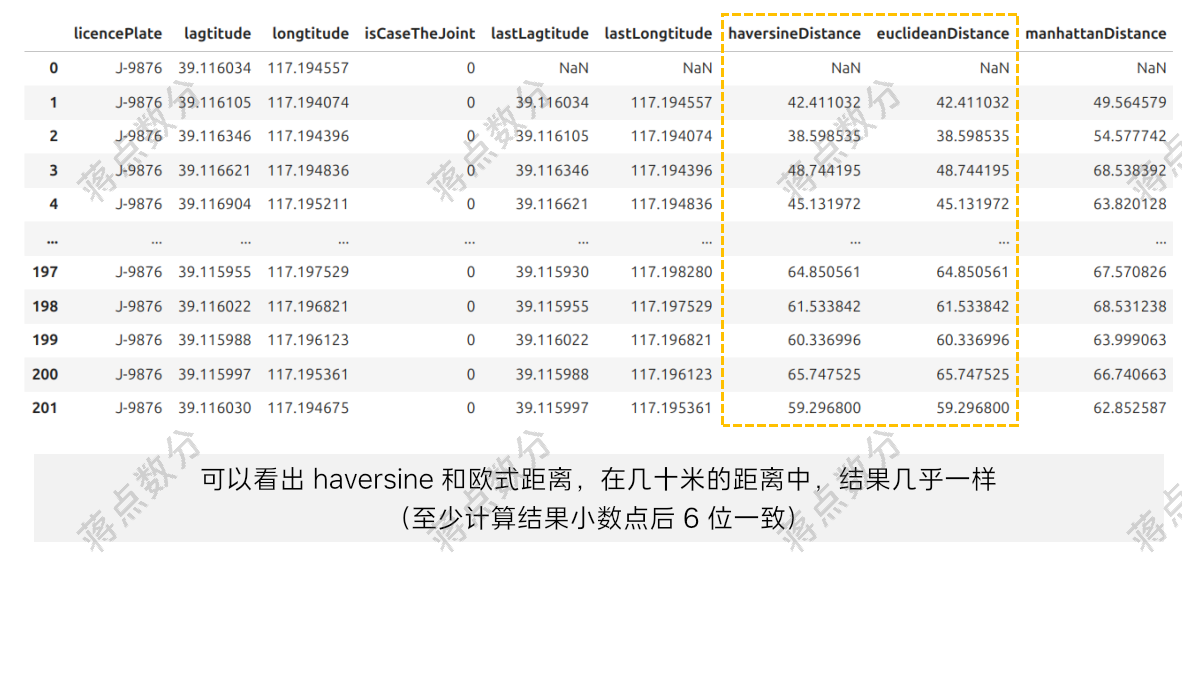
从图中可以看出可以看出 haversine 和欧式距离,在几十米的距离中,结果几乎一样(至少计算结果小数点后 6 位一致)
4.使用标准正态分布,并使用线性变换,随机生成踩点和正常驾驶的速度,使用 clip 裁剪避免数据超出这个范围;假设 4~6m/s 之间是踩点的速度,8~16m/s 之间是正常驾驶的速度:
5.利用距离和速度,求出时间差。随机生成起始点出发的时间,并用 cumsum 实现累加,生成 csv 文件:
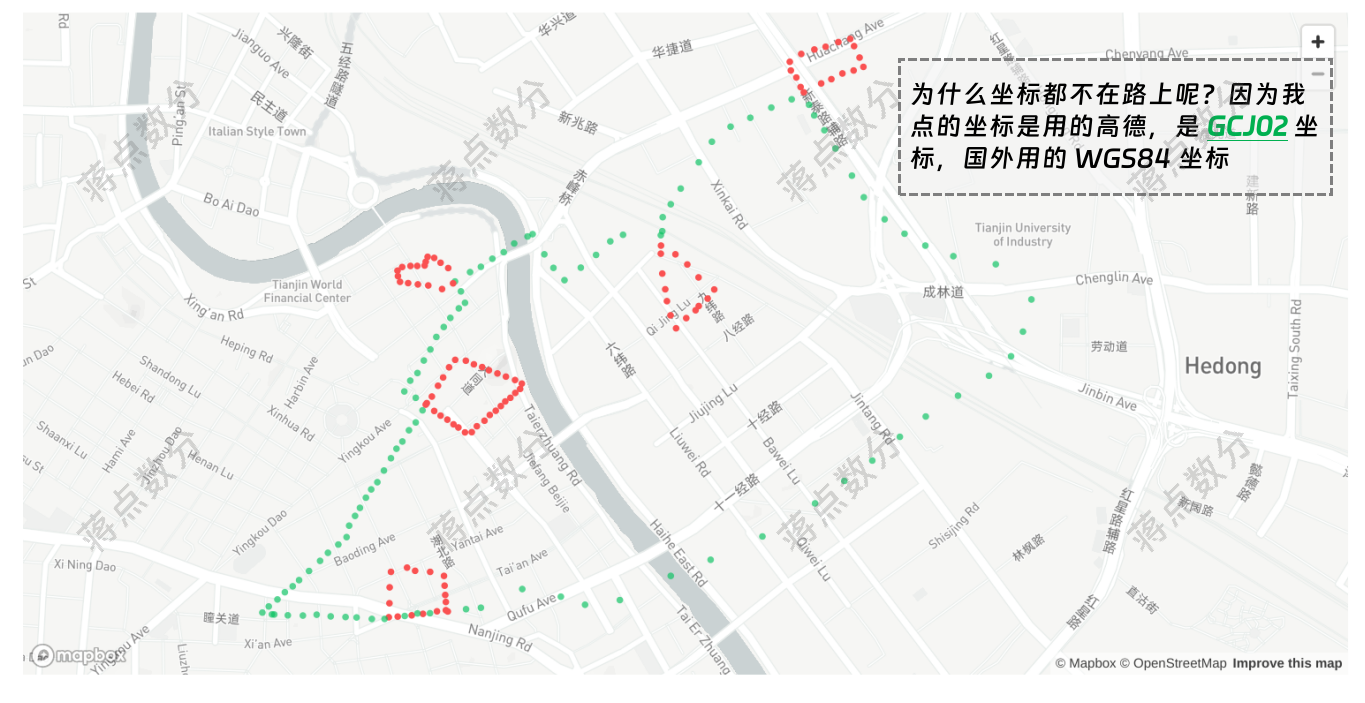
图中的数据是我在 Streamlit 中使用 st.map 绘制,该部分代码我没有贴进来,在另外 py 文件中。st.map 底层用的 mapbox,而后者这里用的 OpenStreetMap。这里就涉及到高德使用的是 GCJ02 坐标系,国外是 WGS84 坐标系。需要进行转换,我也是网上找的转换代码(我将在最后结果展示时,进行转换)为什么不直接使用高德地图(因为暂时没有这方面的需求,没有申请;后续有需求再说 | 我是在网上别人开发的网站手工点的坐标,人家的底图用的是高德)
6.利用 pyhive 创建新的 Hive 表,并将数据 load 到表中:
我通过使用
PyHive包实现 Python 操作Hive。我个人电脑部署了Hadoop及Hive,但是没有开启认证,企业里一般常用Kerberos来进行大数据集群的认证。
四、SQL 解答
我使用 CTE 的语法,这样将步骤串行展示,逻辑比较清晰,下面分成几部分解释 SQL 语句:
1.这部分代码的逻辑是,先做基本的数据处理:比如将字符串格式的时间转为时间戳,unix_timestamp 返回精度到秒,因此需要将微秒部分的提取出来单独转换;使用 lag 提取上一行的坐标,用来后续计算;第二部分使用 haversine 公式计算距离,注意三角函数使用前要将坐标用 radians 转换为弧度
split 函数的官方文档说明,“Splits str around pat (pat is a regular expression)”。即它是用正则表达式来切分,而不是简单的字符串,所以需要对'.'转义,为什么要用两个反斜杠来转义,可以自行搜索原因。
2.这部分代码计算速度,并打标,没啥说的:
3.实现“断点分组”的逻辑,也是 SQL 常见的考题。套路还是那个套路,最后将坐标点求平均就得到中心点 —— 这需要坐标均匀分布(转整数圈是基本要求):
4.完整的 SQL 语句:
最终结果可视化展示:
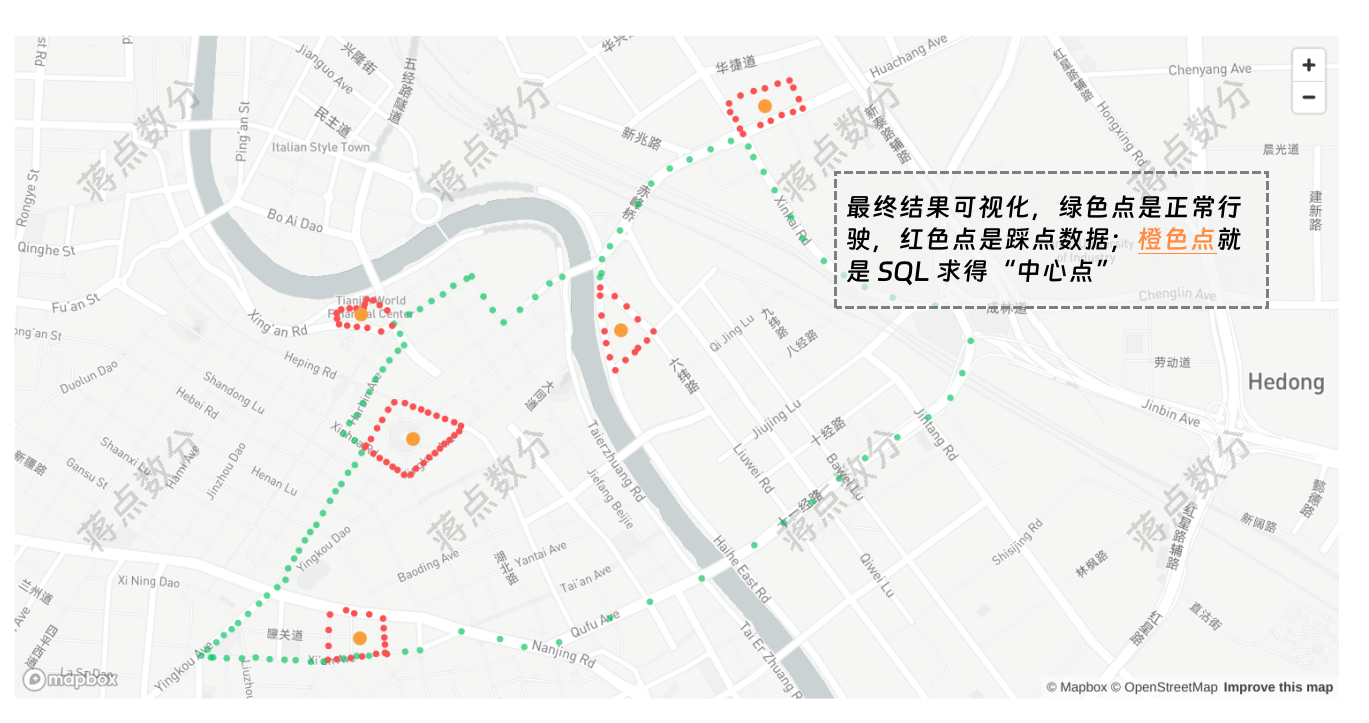
绿色点是正常行驶,红色点是踩点数据;橙色点就是 SQL 求得“中心点”
😁😁😁 我现在正在求职数据类工作(主要是数据分析或数据科学);如果您有合适的机会,即时到岗,不限城市。

















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









