



Redis的单机模式仅部署单个实例,一旦节点宕机或网络故障,所有依赖Redis的服务将不可用,这就是所谓的单点故障问题。单节点需承担全部读写请求,并发量高时可能成为性能瓶颈。单节点受限于物理内存容量,无法突破内存物理上限存储海量数据。所有请求都怼到一个实例,磁盘IO、网络IO、带宽、CPU等资源都会成为瓶颈。
主从复制(Master-Replica)通过部署主节点(Master)和多个从节点(Replica),实现数据副本分发:
- 主节点:处理所有写请求,数据变更后异步/半同步复制到从节点。
- 从节点:以只读形式提供数据查询,承担读请求压力。
注意:读写分离并不是Redis自带,需要客户端手动实现。
主从复制的多种拓扑结构
Redis主从复制支持多种拓扑结构,不同结构适用于不同场景,核心目的是实现数据冗余、读写分离和高可用。
一主一从(Master + Single Replica)
单个主节点(Master)搭配一个从节点(Replica),从节点通过 replicaof 命令与主节点建立复制关系。
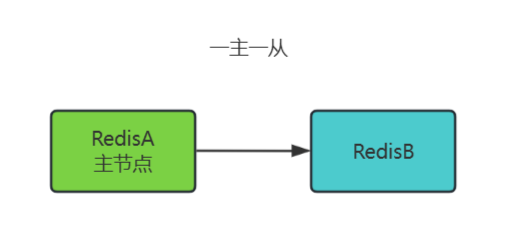
工作原理:
- 主节点处理所有写请求,从节点异步复制主节点数据。
- 从节点可接受只读请求,分担主节点的读压力。
优点:
- 简单易用:配置简单,适合快速搭建备份环境。
- 基础高可用:主节点故障时,可手动将从节点提升为主节点。
- 数据冗余:至少保留一份完整数据副本。
缺点:
- 读扩展有限:仅一个从节点,读性能提升有限。
- 资源利用率低:从节点可能长期处于低负载状态。
适用场景:
- 小型系统的基础数据备份。
- 测试环境验证主从复制功能。
- 对读性能要求不高的容灾场景。
一主多从(Master + Multiple Replicas)
一个主节点(Master)连接多个从节点(Replicas),所有从节点直接复制主节点数据。
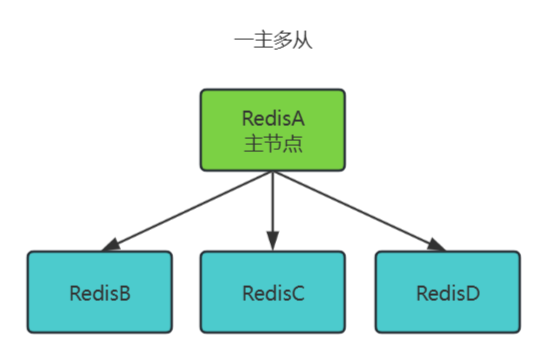
工作原理:
- 主节点处理写请求,所有从节点异步复制主节点数据。
- 读请求可分摊到多个从节点,实现水平扩展。
优点:
- 高读吞吐量:多个从节点并行处理读请求,适合读多写少场景。
- 灵活扩展:按需动态增加从节点,提升读性能。
- 多副本冗余:数据安全性更高,多个从节点可同时故障。
缺点:
- 主节点压力大:所有从节点直接连接主节点,主节点需处理大量复制流量。
- 网络带宽消耗:主节点需向多个从节点发送相同数据,可能成为网络瓶颈。
适用场景:
- 高并发读场景(如热点数据查询、排行榜读取)。
- 多机房部署时,从节点分布在多个机房实现就近读取。
- 需要多副本冗余的高可靠性系统。
级联复制(Chained Replication)
主节点 → 从节点(中间层) → 更多从节点,形成树状层级结构。例如:主节点A复制到从节点B,从节点B再作为“主节点”复制到从节点D、E。
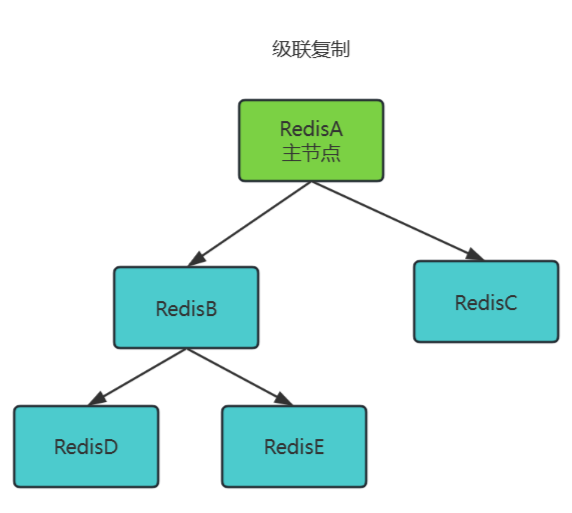
工作原理:
- 中间层从节点既是主节点的副本,又是下级节点的“主节点”。
- 数据从主节点逐级异步复制到下级节点。
优点:
- 降低主节点压力:主节点只需复制到少数中间层节点,减少直接连接的从节点数量。
- 优化网络带宽:分散复制流量,避免主节点成为带宽瓶颈。
- 跨地域复制:中间层节点可部署在不同地域,减少跨区域带宽占用。
缺点:
- 数据延迟累积:层级越深,底层节点数据同步延迟可能越大。
- 故障风险扩散:中间层节点故障会影响其下级所有从节点。
- 运维复杂度高:需监控多层级节点,故障排查难度增加。
适用场景:
- 主节点带宽有限时,需支撑大量从节点。
- 多数据中心部署(如主节点在中心机房,中间层节点分布到边缘节点)。
- 需要层级化管理的企业级架构(如总部-分公司的数据同步)。
对比与选型建议
类型 | 读扩展能力 | 主节点压力 | 数据延迟 | 适用规模 | 典型场景 |
一主一从 | 低 | 低 | 低 | 小型系统 | 数据备份、基础容灾 |
一主多从 | 高 | 高 | 低 | 中型系统 | 高并发读、多副本冗余 |
树状结构 | 高 | 低 | 高(累积) | 大型分布式系统 | 跨地域复制、带宽优化 |
级联主从复制实战部署
Redis节点规划:
- Master: 127.0.0.1:6380
- Slave1: 127.0.0.1:6381(直连Master)
- Slave2: 127.0.0.1:6382(直连Slave1)
在/test/目录分别新建/test/6380、/test/6381、/test/6382三个目录,用来存放redis的数据文件。
启动Master,这里为了便于演示,查看日志情况,都使用非守护进程的方式启动:
启动两个Slave:
现在三台Redis还没有建立任何关系,现在使用REPLICAOF命令对Slave1进行主从复制(旧版本使用slaveof命令):
在Master节点的日志可以看到与slave1建立复制关系:
同样在Slave1节点的日志可以看到:
对Slave2执行同样的操作,同样可以在Slave1和Slave2中日志中观察到建立复制关系。
在主节点(Master)上查看复制状态:
在第一级从节点(Slave1)上查看复制状态:
在第二级从节点(Slave2)上查看复制状态:
这时我们对Master写入一个key,两个Slave是可以访问到的,但是Slave是不能写入的,只能读。
此时如果把Master关掉,Slave1都会报一个如下的错误,Slave2不会报错:
此时Slave1和Slave2的数据还是可以读的(提供读服务):
使用主从复制模式,如果Master挂了,需要人工手动指定其中一个Slave升为Master,这里我把6381升为Master:
然后Slave1的日志就会打印,Master模式开启:
这样原来的Slave1也就是新的Master又可以对外提供写服务了:
核心配置参数详解
主节点相关
从节点相关
主从复制的改进与缺点
主从复制对单机模式的改进:
- 故障恢复与高可用性:从节点可作为主节点的冷备或热备(需配合哨兵Sentinel等监控工具),主节点宕机后可晋升新主,降低系统不可用时间。
- 读写分离提升性能:写请求由主节点处理,读请求分发到多个从节点,充分利用多节点资源,显著提升读吞吐量。
- 数据冗余与备份:主从节点存储相同副本,即使主节点数据丢失,仍可通过从节点恢复,降低数据风险。
- 动态扩展能力:根据业务增长灵活添加从节点,突破单机内存容量限制(需配合集群模式完全解决)。
主从复制的限制与注意事项:
- 异步复制的数据一致性:默认异步复制下,主从数据可能存在短暂延迟(秒级),无法实现强一致性。
- 写操作仍受主节点单点限制:写压力仍集中在主节点,需通过分片(Cluster)解耦。
- 故障切换复杂度:主节点故障需依赖额外组件(如 Sentinel)实现自动切换,否则需人工干预。
主从复制的原理
类型 | 同步方式 | 数据一致性 | 性能影响 |
全量复制 | 首次连接时 | 强一致 | 高IO压力 |
部分复制 | 断线重连后 | 最终一致 | 低资源消耗 |
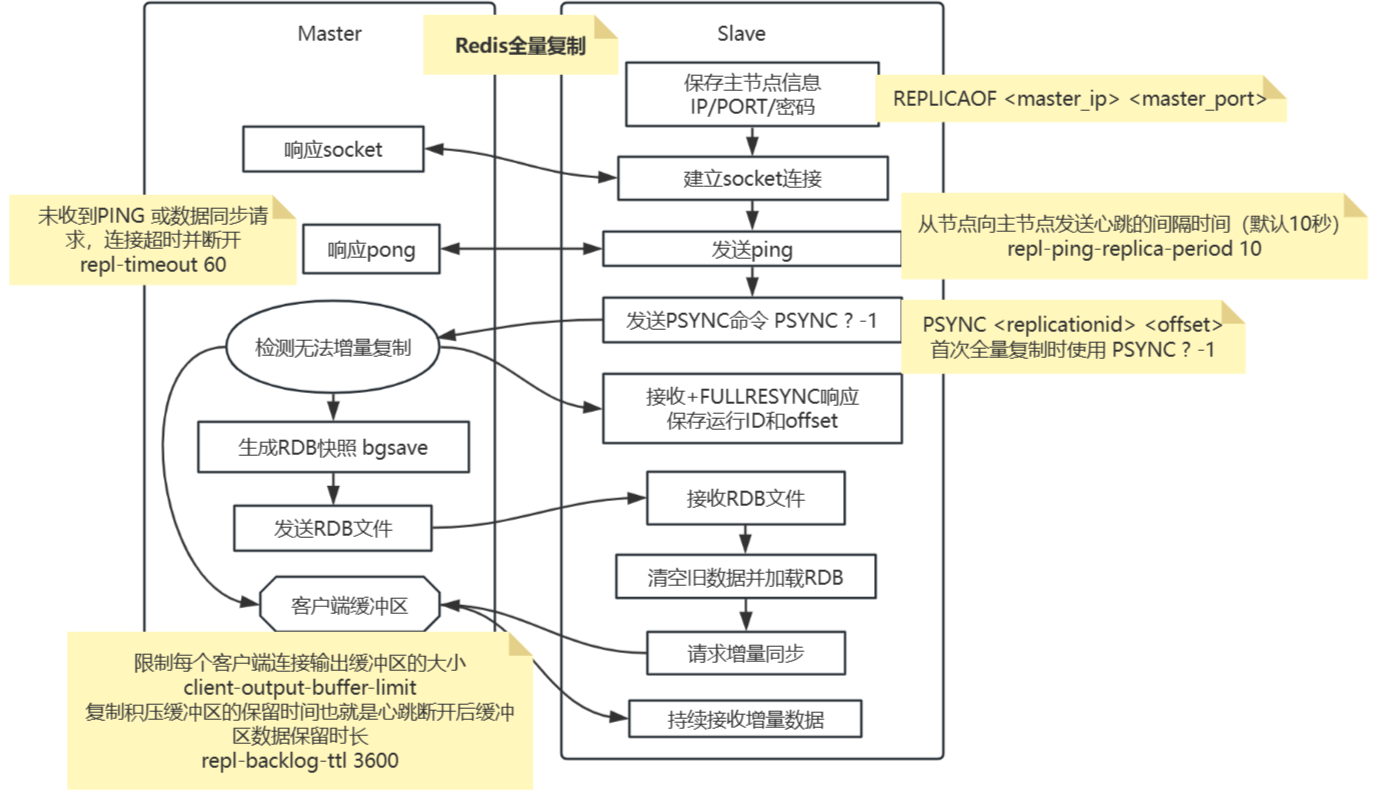
全量复制的触发条件
- 首次建立主从关系:从节点首次执行REPLICAOF命令连接主节点。
- 数据差异过大:从节点落后主节点太多(超出复制积压缓冲区范围)。
- 复制ID不匹配:主节点重启导致复制ID变更,从节点无法增量同步。
全量复制的完整流程
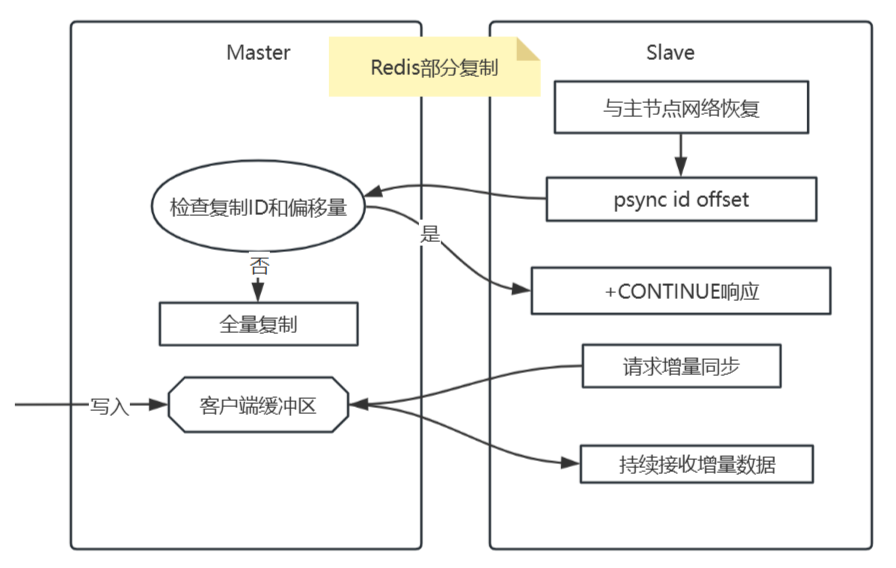
部分复制的触发条件
- 主从节点的复制ID一致
- 从节点的复制偏移量仍在主节点的复制积压缓冲区内。
部分复制的完整流程

















 4596
4596

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









