



引言
Amazon DynamoDB 是一种完全托管式、无服务器的 NoSQL 键值数据库,旨在运行任何规模的高性能应用程序。在保证高性能的同时,RTO(恢复时间目标)和RPO(恢复点目标)也是数据库最需要重视的问题。本文将详细介绍 DynamoDB 的数据备份、复制与恢复等多个场景的操作细节,帮助您选择最适合业务需求的解决方案。
备份与恢复解决方案概览
DynamoDB 提供了多种备份和恢复选项,以满足不同的业务需求:
- DDB On-demand backup - 按需备份
- PITR (Point-In-Time Recovery) - 时间点恢复
- DDB Export to S3 - 导出到 S3
- DDB Enhanced AWS Backup - 增强型 AWS 备份
- DDB Import from S3 - 从 S3 导入
- DDB Stream + Lambda → S3 - 使用流和 Lambda 归档到 S3
环境准备
在开始测试各种备份和恢复选项之前,我们需要准备测试环境:
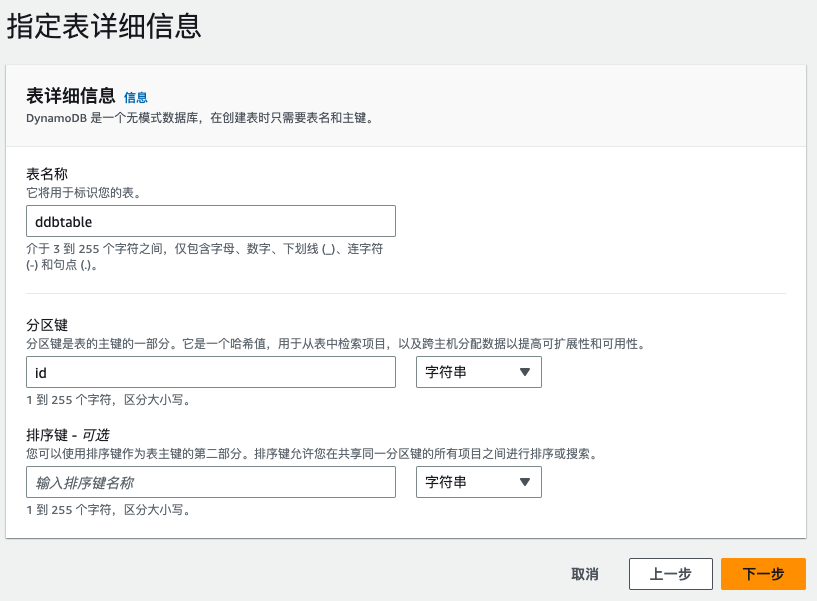
- 创建 DynamoDB 表
ddbtable - 将 WCU 和 RCU 设置为按需模式
- 生成并导入 200 万条测试数据
- 批量导入数据到ddbtable表
- 持续插入数据到 DynamoDB 的 Python 代码示例,为后续测试使用
1. DDB On-demand backup (按需备份)
您可以使用 DynamoDB 按需备份功能创建表的完整备份以进行长期保留和存档,从而满足监管合规性需求。按需备份的优势在于操作简单且对系统影响小:
- 通过 AWS 管理控制台单击或使用单个 API 调用即可完成
- 执行备份和还原操作对表性能或可用性没有任何影响
- 适合定期备份和长期数据保留需求
- 支持完整表数据的备份,包括所有表项目和属性
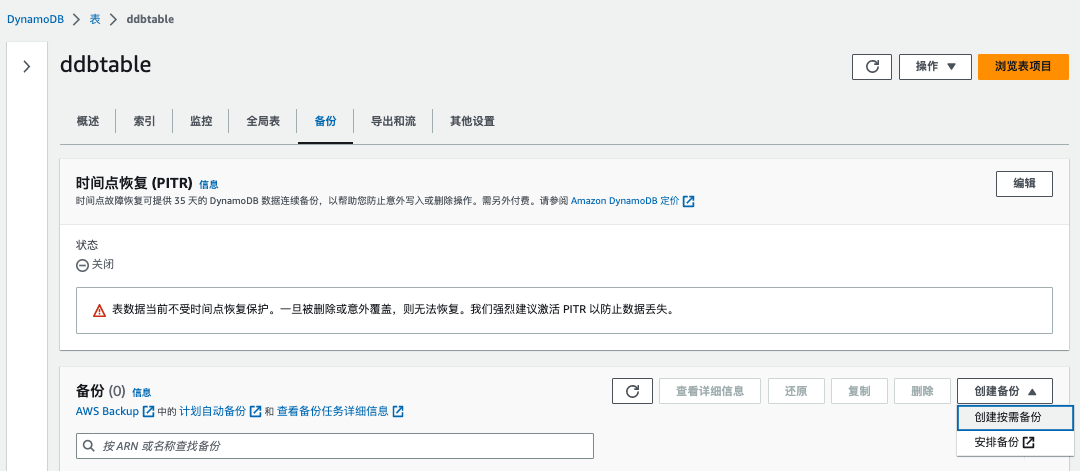
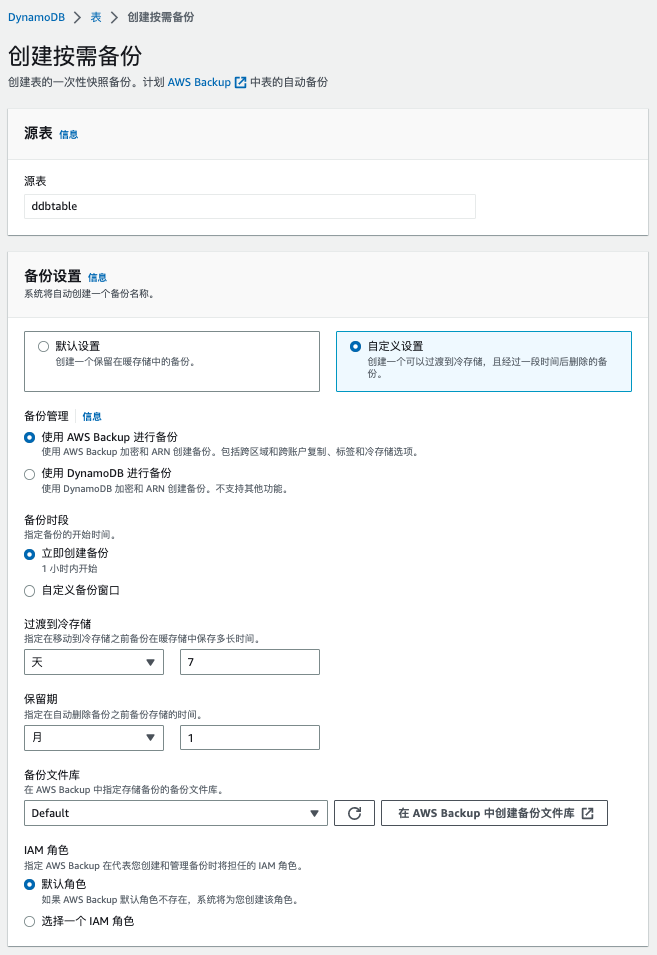
创建按需备份
- 登录 AWS 管理控制台,导航至 DynamoDB 服务
- 选择要备份的表
- 点击"备份"选项卡,然后选择"创建备份"
- 输入备份名称,点击"创建"
从备份恢复
- 在 DynamoDB 控制台中,选择"备份"选项卡
- 选择要恢复的备份,点击"恢复"
- 指定新表名称和其他所需设置
- 点击"恢复"开始恢复过程
图示如下:
创建按需备份
使用DynamoDB进行备份
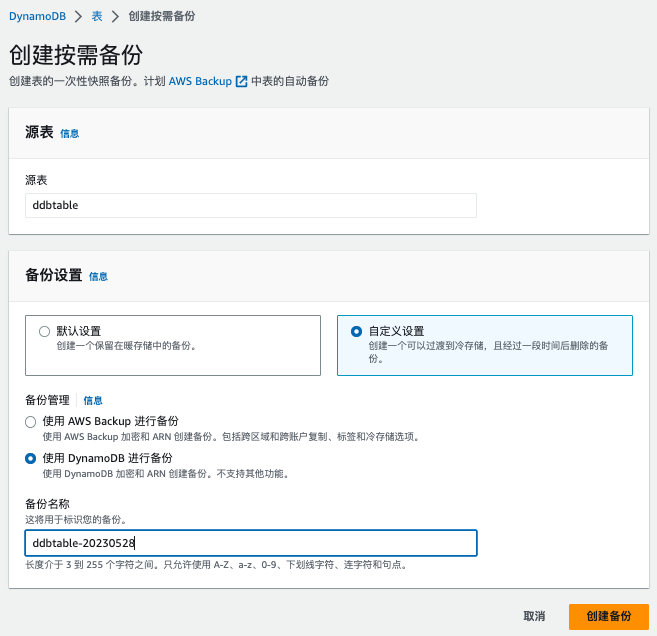
使用AWS Backup进行备份

2. PITR (时间点恢复)
PITR (Point-In-Time Recovery) 允许您将 DynamoDB 表恢复到过去 35 天内的任何时间点。这个功能对于意外写入或删除操作的恢复非常有价值。
PITR 的主要特点:
- 持续备份最近 35 天的数据变更
- 可以精确到秒级别的恢复点
- 不影响表性能
- 恢复操作会创建一个新表,原表保持不变
- 适合应对人为错误、应用程序错误或数据损坏情况
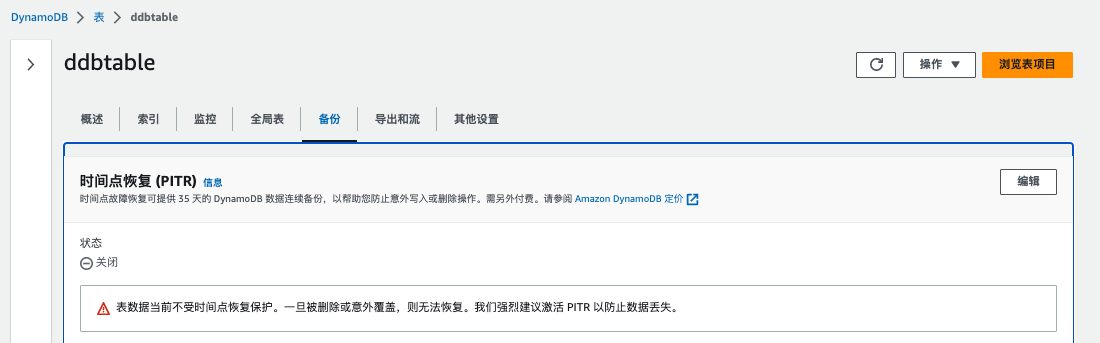
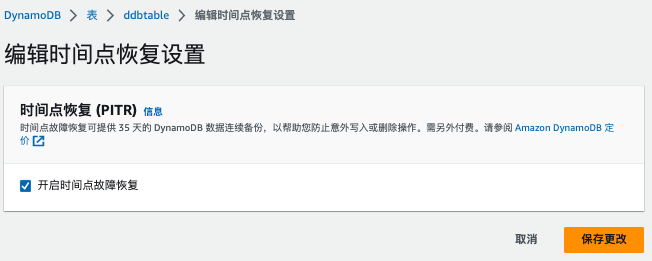
启用 PITR
- 在 DynamoDB 控制台中选择目标表
- 点击"备份"选项卡
- 在"时间点恢复"部分,点击"启用"
- 确认启用
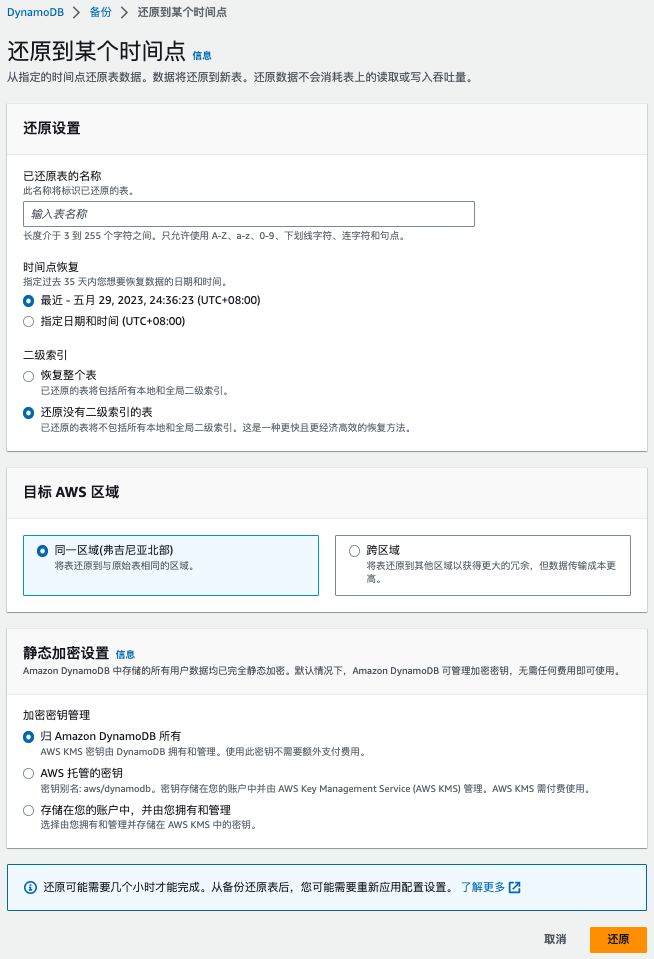
PITR 恢复操作
- 在 DynamoDB 控制台中选择启用了 PITR 的表
- 点击"备份"选项卡,然后选择"恢复到时间点"
- 选择要恢复到的确切时间点
- 指定新表名称和其他设置
- 点击"恢复"开始恢复过程
图示如下:
还原到某个时间点
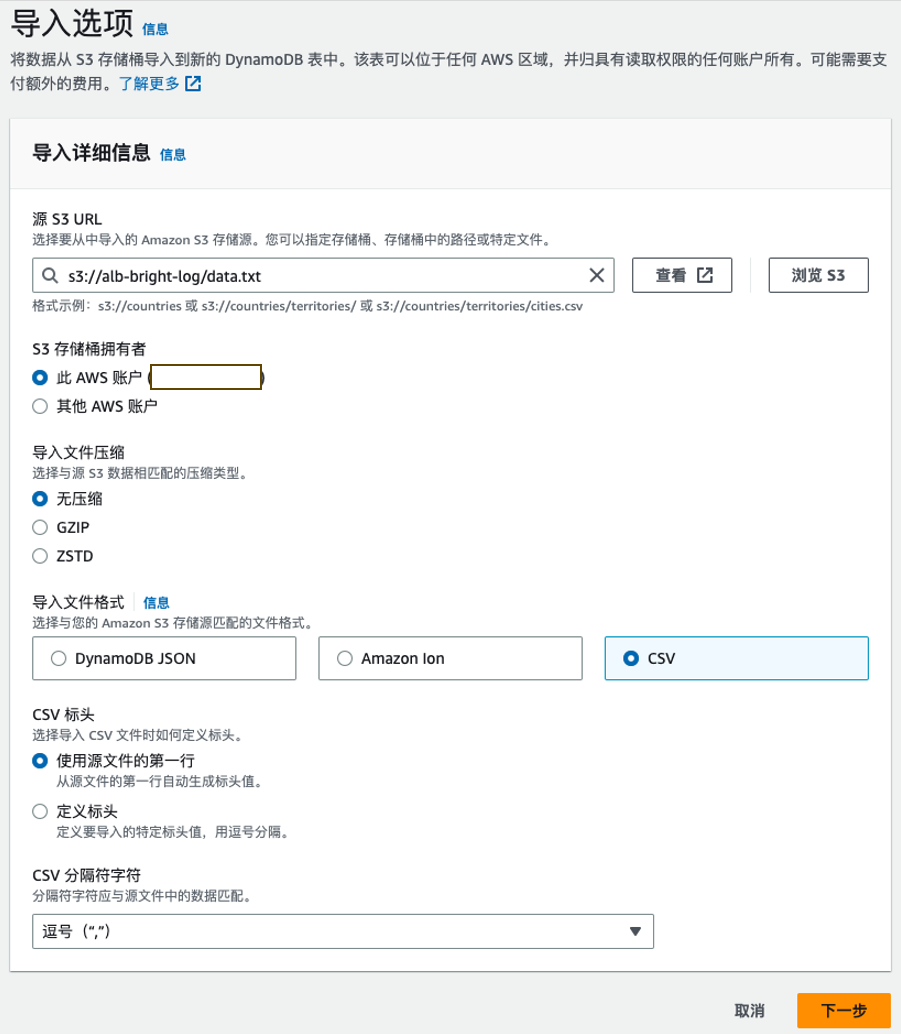
3. DDB Export to S3 (导出到 S3)
DynamoDB 提供了将表数据导出到 S3 的功能,这对于数据分析、长期归档和跨账户数据共享非常有用。
导出到 S3 的优势:
- 以 DynamoDB JSON 或 Amazon Ion 格式导出
- 导出过程不消耗表的读取容量
- 可以导出完整表数据或时间点快照
- 导出的数据可用于分析、备份或迁移
执行导出操作:
- 在 DynamoDB 控制台中选择目标表
- 点击"导出到 S3"选项
- 选择目标 S3 存储桶和导出格式
- 配置加密选项和权限
- 启动导出任务并监控进度
4. DDB Enhanced AWS Backup (增强型 AWS 备份)
Enhanced AWS Backup 为 DynamoDB 表提供了集中式备份管理,并支持跨区域和跨账户备份复制。
增强型备份的主要功能:
- 集中管理多个 AWS 服务的备份
- 自动备份计划和生命周期管理
- 跨区域和跨账户备份复制
- 标签支持和访问控制
- 与 AWS Organizations 集成
设置增强型备份:
- 在 AWS Backup 控制台中创建备份计划
- 添加 DynamoDB 表作为资源
- 配置备份频率、保留期和其他策略
- 启用跨区域复制(如需要)
- 监控备份状态和合规性
5. DDB Import from S3 (从 S3 导入)
DynamoDB 允许您从 S3 导入数据,这对于数据迁移、恢复和批量数据加载非常有用。
从 S3 导入的特点:
- 支持 DynamoDB JSON 和 Amazon Ion 格式
- 可以导入到新表或现有表
- 自动处理架构转换
- 可以并行导入大量数据
执行导入操作:
- 确保 S3 中的数据格式正确
- 在 DynamoDB 控制台中选择"导入"选项
- 指定 S3 源位置和导入格式
- 配置目标表设置
- 启动导入任务并监控进度
6. DDB Stream + Lambda → S3
这种方法使用 DynamoDB Streams 和 Lambda 函数将数据变更实时归档到 S3。这对于数据分析、审计跟踪和细粒度备份特别有用。
DDB Stream + Lambda 架构的优势:
- 实时捕获数据变更
- 可以筛选特定类型的事件
- 灵活的数据转换和处理
- 成本效益高,只处理需要的数据
- 与其他 AWS 服务轻松集成
实现步骤:
1. 开启 DynamoDB Stream
首先,我们需要为 DynamoDB 表启用流:
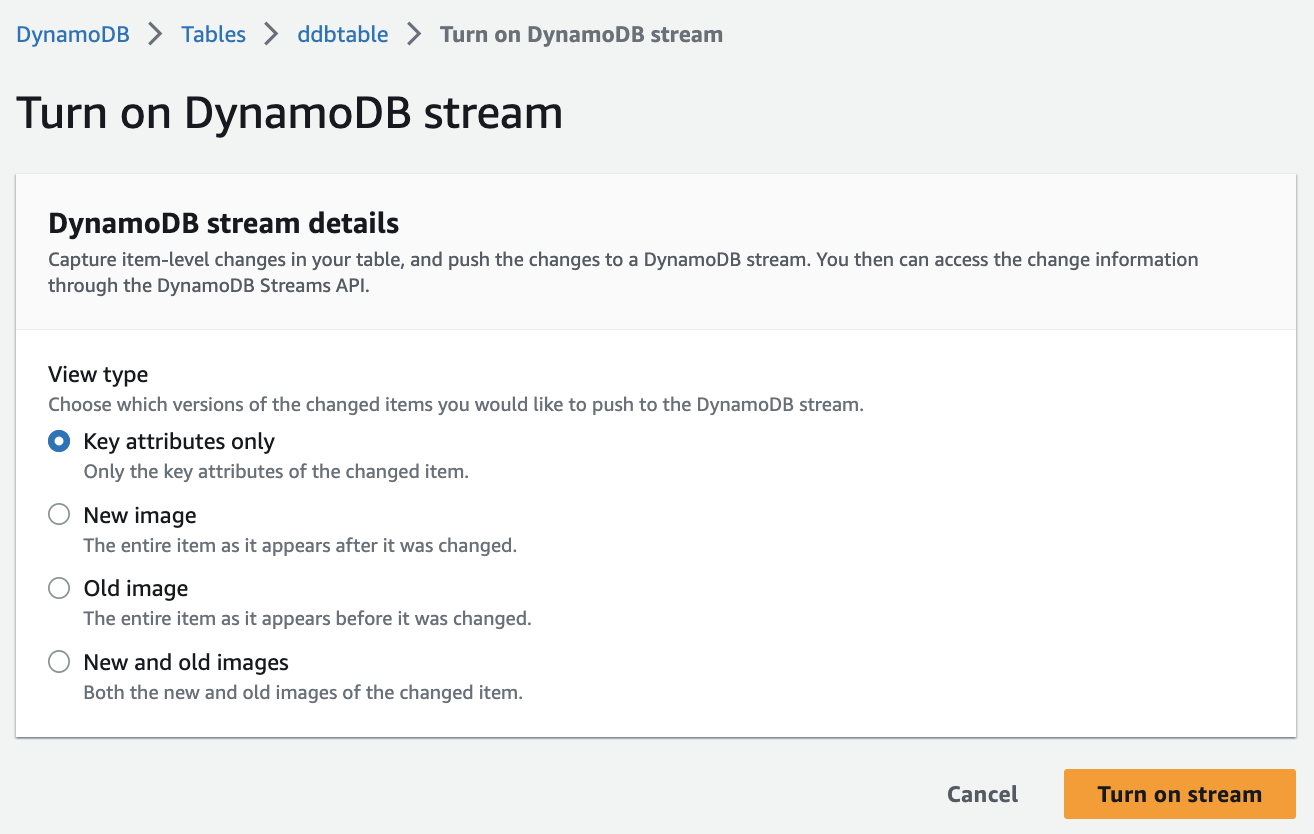
- 在 DynamoDB 控制台中选择目标表
- 点击"表详细信息",然后选择"Exports and streams"选项卡
- 在 DynamoDB Streams 部分,点击"Enable"
- 选择"New and old images"作为视图类型
- 保存设置
图示如下:
2. 创建 IAM 角色和策略
为 Lambda 函数创建具有适当权限的 IAM 角色:
3. 创建 Lambda 函数
以下是一个将 DynamoDB 流数据归档到 S3 的 Lambda 函数示例:
4. 配置 Lambda 触发器和事件筛选
- 在 Lambda 控制台中,为您的函数添加 DynamoDB 触发器
- 选择您的 DynamoDB 流作为事件源
- 配置批处理大小和批处理窗口
- 添加事件筛选条件以只处理特定类型的事件:
- 启用触发器
5. 优化和监控
- 设置适当的批处理大小和批处理窗口以平衡性能和成本
- 添加 CloudWatch 警报以监控 Lambda 错误和延迟
- 考虑使用 S3 生命周期策略管理归档数据
- 定期审查 Lambda 日志以确保正常运行
使用 DynamoDB Streams 和 Lambda 归档 TTL 删除的项目
结合使用 DynamoDB 存活时间 (TTL)、DynamoDB Streams 和 AWS Lambda 可以帮助简化数据归档、降低 DynamoDB 存储成本并降低代码复杂性。使用 Lambda 作为流使用者提供了许多优势,最明显的是与 Kinesis Client Library (KCL) 等其他使用者相比,降低了成本。
当通过 Lambda 来使用事件时,对 DynamoDB 流的 GetRecords API 调用不向您收费,并且 Lambda 可以通过识别流事件中的 JSON 模式来提供事件筛选。借助事件模式内容筛选,您可以定义多达五个不同的筛选条件来控制将哪些事件发送到 Lambda 进行处理。这有助于减少对 Lambda 函数的调用、简化代码并降低总体成本。
尽管 DynamoDB Streams 包含所有数据修改,例如 Create、Modify 和 Remove 操作,但这可能导致不必要地调用归档 Lambda 函数。例如,假设一个每小时有 200 万项数据修改的表流入流中,但其中不到 5% 的数据修改是将在 TTL 流程中过期而需要归档的项目删除。使用 Lambda 事件源筛选条件,Lambda 函数每小时只调用 100,000 次。事件筛选的结果是,您只需为所需的调用付费。在没有事件筛选的情况下,您需要为获得的 200 万次调用付费。
结论与最佳实践
选择合适的 DynamoDB 备份和恢复解决方案需要考虑多个因素:
- 恢复时间目标 (RTO) - 如果需要快速恢复,PITR 或按需备份是较好选择
- 恢复点目标 (RPO) - 如果需要最小的数据丢失,PITR 提供最精确的恢复点,而流式归档可提供实时数据保护
- 成本考量 - 按需备份和 PITR 会产生额外存储费用,而导出到 S3 可能更经济实惠
- 数据量 - 对于大型表,导出/导入 S3 可能比完整表恢复更高效
- 操作复杂性 - 按需备份和 PITR 最简单,而流式归档需要更多设置但提供更大的灵活性
各选项比较表
备份选项 | 最大保留期 | 恢复粒度 | 性能影响 | 复杂度 | 适用场景 |
按需备份 | 无限制 | 表级别 | 低 | 低 | 长期合规性存档 |
PITR | 35天 | 秒级 | 低 | 低 | 意外删除恢复 |
导出到S3 | 无限制 | 表级别 | 低 | 中 | 数据分析和长期存储 |
AWS增强备份 | 可配置 | 表级别 | 低 | 中 | 集中式备份管理 |
从S3导入 | N/A | N/A | 中 | 中 | 数据迁移和批量加载 |
流+Lambda归档 | 无限制 | 项目级别 | 低 | 高 | 实时归档和审计 |
多区域数据复制策略
对于需要高可用性和灾难恢复的应用程序,DynamoDB 提供了多种跨区域数据复制选项:
1. DynamoDB 全局表
DynamoDB 全局表是一种多区域、多主数据库解决方案,提供完全托管的复制:
- 双向复制,支持多区域写入
- 通常低于1秒的复制延迟
- 自动解决冲突(最新写入获胜)
- 无需编写复制代码
配置步骤:
- 在主区域创建 DynamoDB 表
- 确保启用了流(新旧映像)
- 在 DynamoDB 控制台中,选择"全局表"选项卡
- 添加要复制到的区域
- 监控复制状态和指标
2. AWS Database Migration Service (DMS)
对于更复杂的复制需求,AWS DMS 提供了更多控制:
- 支持持续复制
- 可以筛选和转换数据
- 支持异构数据库迁移
- 提供详细的监控和故障排除
3. 自定义复制解决方案
对于特定需求,可以构建自定义复制解决方案:
- 使用 DynamoDB Streams 和 Lambda
- 实现自定义冲突解决策略
- 支持选择性数据复制
- 可以与其他服务集成
成本优化建议
备份和复制解决方案可能会增加 DynamoDB 的总体成本。以下是一些优化建议:
- 选择性备份 - 不是所有表都需要相同级别的备份。根据数据重要性和变更频率调整备份策略
- 利用 S3 存储类 - 对于长期归档,将导出数据移至 S3 Glacier 或 Glacier Deep Archive
- 优化流处理 - 使用事件筛选仅处理必要的记录
- 自动化生命周期管理 - 实施自动删除过期备份的策略
- 监控使用情况 - 定期审查备份和复制成本,调整策略以优化支出
安全最佳实践
保护备份数据与保护生产数据同样重要:
- 加密 - 确保所有备份和导出都使用 AWS KMS 或客户管理的密钥加密
- 访问控制 - 实施最小权限原则,限制谁可以创建和恢复备份
- 审计 - 启用 AWS CloudTrail 以记录所有备份和恢复操作
- 定期测试 - 定期测试恢复过程以确保备份有效
- 跨账户保护 - 考虑将关键备份复制到单独的 AWS 账户以增加安全层
实际案例研究
案例1:电子商务平台的灾难恢复
一家大型电子商务公司使用 DynamoDB 存储产品目录和订单信息。他们实施了以下策略:
- 使用全局表在三个地理区域之间复制关键数据
- 为所有表启用 PITR,以防意外数据删除
- 每周将完整数据导出到 S3,然后转移到 Glacier 进行长期存档
- 使用 Lambda 和流将订单历史记录实时归档到数据湖
结果:在一次区域性服务中断期间,他们能够在不到 5 分钟的时间内将流量转移到备用区域,没有数据丢失,对客户体验的影响最小。
案例2:金融服务数据合规性
一家金融服务公司需要保留交易数据 7 年以满足监管要求:
- 使用 DynamoDB Streams 和 Lambda 将每个交易实时归档到 S3
- 实施严格的 S3 生命周期策略,将数据从标准存储转移到 Glacier
- 使用 AWS Backup 进行额外的加密备份,具有严格的访问控制
- 定期执行恢复演习,以验证合规性和数据完整性
结果:他们能够满足所有监管要求,同时将存储成本降低 60%,并简化了审计流程。
结语
DynamoDB 提供了多种备份、复制和恢复选项,可以满足从简单应用到企业级工作负载的各种需求。通过了解每种方法的优缺点,您可以设计一个满足您特定业务需求的数据保护策略。
关键是要定期评估您的备份和恢复策略,确保它们随着应用程序的发展而扩展,并定期测试恢复流程以确保在需要时能够正常工作。通过结合使用本文中讨论的不同方法,您可以为 DynamoDB 数据构建一个强大、高效且经济实惠的保护系统。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









