






 本文介绍了五个Python库,如SweetViz、PandasProfiling、LazyPredict、FLAML和PyCaret,它们简化数据分析和模型构建过程,包括数据预处理、报告生成、模型比较和超参数优化,以提升工作效率。
本文介绍了五个Python库,如SweetViz、PandasProfiling、LazyPredict、FLAML和PyCaret,它们简化数据分析和模型构建过程,包括数据预处理、报告生成、模型比较和超参数优化,以提升工作效率。

简介
数据科学既鼓舞人心又具有挑战性。对数据进行预处理、清洗,并通过绘制各种图表从数据中生成洞察力,以及微调模型以获得最佳结果都是相当艰巨的工作。
在本文中,将介绍五个能够自动化这些过程的Python库,从而节省时间并提高工作效率。
只需几行代码,就可以生成全面的报告、调整超参数,甚至部署机器学习模型。言归正传,接下来开始阅读本文。
为了进行数据分析和模型搭建,本文将使用鸢尾花数据集。可以在如下链接中找到数据。本文将使用如下存储库来预览HTML文件。
【鸢尾花数据集】:https://www.kaggle.com/datasets/uciml/iris
【存储库】:https://github.com/htmlpreview/htmlpreview.github.com

# 导入pandas库
import pandas as pd
# 加载数据
data = pd.read_csv('Iris.csv')
以下是提高工作效率的五个库:
SweetViz
这是一个开源的Python库,主要用于探索性数据分析(EDA)。只需几行代码,该库就能生成带有图表和可视化的全面报告。
这些报告以HTML或Jupyter Notebook格式生成,便于查看和分享。此外,报告还包括相关性分析(HeatMaps)、直方图和各种其他可视化效果。
还可以通过指定目标变量、更改图表类型甚至改变布局来自定义报告。此外,还可以比较两个不同的数据集,并生成有用的洞察。
要安装该库,请在命令提示符中输入以下代码:
pip install sweetviz
要为数据集生成报告,可以使用analyze函数。
# 导入SweetViz
import sweetviz
# 生成报告
report = sweetviz.analyze(data)
# 要保存报告的HTML格式,请使用以下代码:
report.show_html()
# 要在Jupyter Notebook中查看报告,请使用以下代码:
report.show_notebook()
HTML报告的样式如下:
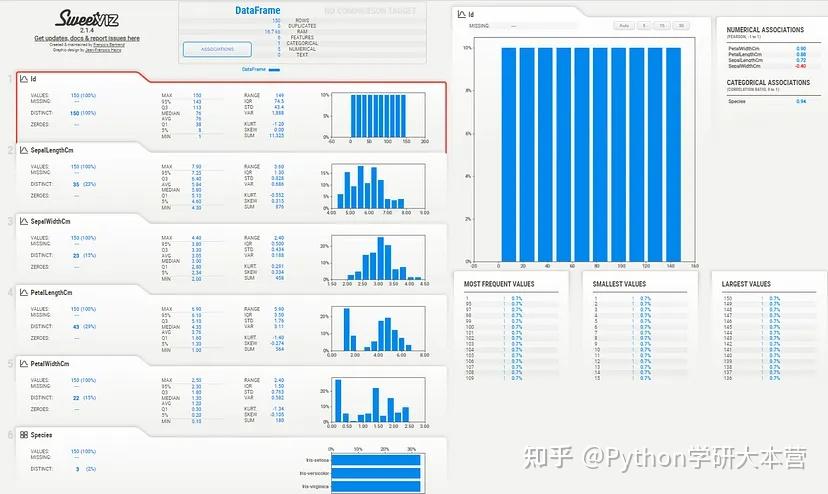
SweetViz HTML报告
要了解更多关于该库及其功能的信息,可以查看如下链接的文档。
【文档】:https://pypi.org/project/sweetviz/
Pandas Profiling
Pandas库提供了各种函数用于分析数据,包括data.info()、data.isnull()、data.describe()等。然而,逐个应用这些函数可能需要相当长的时间。
通过使用Pandas Profiling库将这些过程自动化,可以仅凭几行代码就生成全面的报告。该库与SweetViz非常相似,但它提供了更多的功能。
要安装该库,请在命令提示符中输入以下代码:
pip install pandas-profiling
可以使用ProfileReport生成报告。
# 导入ProfileReport
from pandas_profiling import ProfileReport
# 生成报告
report = ProfileReport(data)
报告分为多个部分,包括:
- 概述部分:
在这个部分,可以找到变量的类型、重复行、缺失值以及观测值的总数等信息。
- 警报部分:
在这一部分,可以了解到变量的分布、变量之间的相关性以及与数据集相关的问题。
- 重现:
它提供了有关分析开始和结束日期的信息。此外,它还告诉我们执行整个分析所花费的时间。
- 变量:
在这个部分,可以对所选的任何特征执行单变量分析。它提供了有关特征的信息,如平均值、中位数、不同值的数量等。
- 交互:
此部分的目的是执行双变量分析。使用它,可以绘制任意两个特征之间的散点图。
- 相关性:
这个部分包括一个热力图,显示两个变量之间的相关性。
- 缺失值:
在这个部分,展示了一个缺失值矩阵,可以可视化数据集中的缺失值。
- 样本:
允许查看数据集的前10行和后10行,类似于data.head(10)和data.tail(10)。
要了解更多关于该库及其功能的信息,可以使用如下链接查看文档。
【文档】:https://ydata-profiling.ydata.ai/docs/master/index.html
LazyPredict
在某些情况下,希望对数据集应用不同的机器学习模型,并确定哪个模型能提供最佳结果。手动导入模型并对其进行训练可能是一个费时费力的过程。在这种情况下,LazyPredict库非常有用。
LazyPredict是一个自动机器学习的开源Python库,可以在不调整超参数的情况下对各种模型进行比较。只需几行代码,就可以训练和比较各种机器学习模型。它既可用于分类问题,也可用于回归问题。
要安装该库,请在命令提示符中输入以下代码:
pip install lazypredict
使用该库,找到Iris数据集的最佳模型:
# 分离目标变量和其他数据
y = data['Species']
data.drop('Species',inplace=True,axis=1)
X = data
# 将数据集拆分为训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=.5,random_state =1)
clf = LazyClassifier(verbose=0,ignore_warnings=True, custom_metric=None)
# 训练模型
models,predictions = clf.fit(X_train, X_test, y_train, y_test)
# 输出结果
models
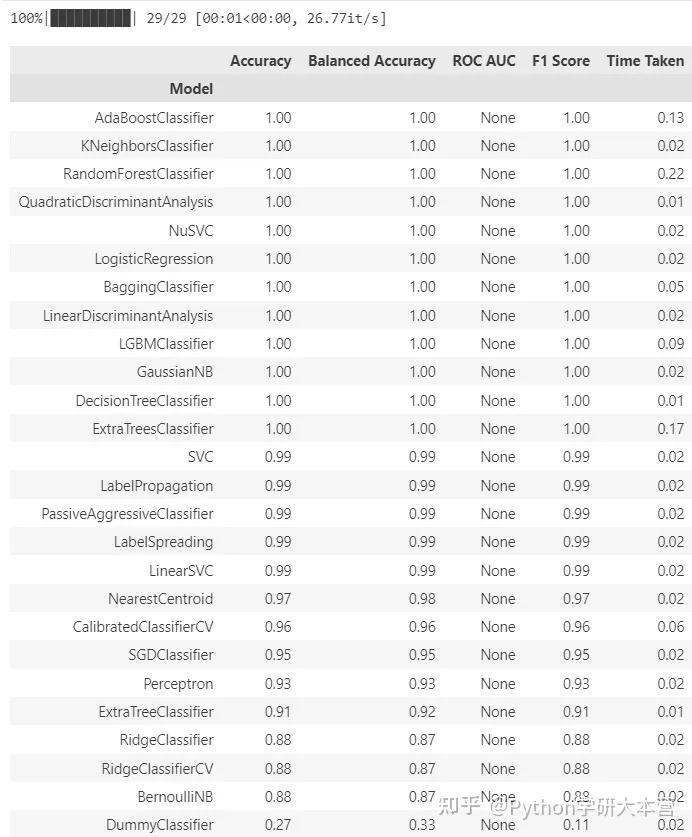
LazyPredict输出
它根据多种指标对模型进行比较,包括准确率、F1分数和执行时间等。
要了解更多关于该库及其功能的信息,可以查看如下GitHub存储库。
【GitHub存储库】:https://github.com/shankarpandala/lazypredict
FLAML
与LazyPredict类似,FLAML允许比较不同的机器学习模型,但它也能帮助调整超参数并选择最佳模型。
FLAML是由微软开发的,使用了微软研究院开发的超参数优化和模型选择系统。
在FLAML中,默认模型为LightGBM、XGBoost、随机森林等。用户还可以添加模型并指定训练模型的时间限制。
要安装该库,请在命令提示符中输入以下代码:
pip install flaml
使用FLAML寻找最佳模型:
from flaml import AutoML
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
# 分离目标变量和其他数据
y = data['Species']
data.drop('Species',inplace=True,axis=1)
X = data
# 使用Label Encoder将分类变量转换为数值变量
label_endcoder = LabelEncoder()
y = label_endcoder.fit_transform(y)
# 将数据集拆分为训练数据和测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=.5,random_state =1)
automl = AutoML()
# 训练模型
automl.fit(X_train, y_train, task="classification")
要找出最佳模型,请使用以下代码:
automl.best_estimator
在这种情况下,最佳模型是xgb_limitdepth。
要获取最佳模型的超参数信息,请输入以下代码:
automl.best_config

最佳模型的超参数信息
要了解有关该库及其功能的更多信息,请点击如下链接查看文档。
【文档】:https://microsoft.github.io/FLAML/
PyCaret
开发PyCaret的初衷是减少编码时间,将更多时间用于分析数据。它是一款端到端的模型管理工具,可以帮助实现机器学习流程的自动化。
PyCaret可自动完成特征工程、缺失值估算、超参数调整甚至部署模型。
作为数据准备过程的一部分,PyCaret允许执行归一化、缩放、使用主成分分析(PCA)进行特征选择、离群值去除以及许多其他功能。
在训练阶段,可以添加和移除模型,指定时间限制,比较不同的模型,并绘制各种图表,例如ROC曲线。
该模型可以部署在AWS、Google Cloud Platform(GCP)或Microsoft Azure上。还可以将转换流程和训练后的模型对象保存为pickle文件,并随时检索它们。
要安装该库,请在命令提示符中输入以下代码:
pip install pycaret
准备数据:
from pycaret.classification import *
# 加载数据,定义目标变量,并使用z-score对数据进行归一化处理
clf = setup(data = data, target = 'Species',normalize=True,
normalize_method='zscore'))

设置数据
寻找最佳模型:
# 比较模型
compare_models()

最佳模型
绘制逻辑回归的ROC曲线:
lr = create_model('lr')
# 绘制ROC曲线
plot_model(lr, plot = 'auc')
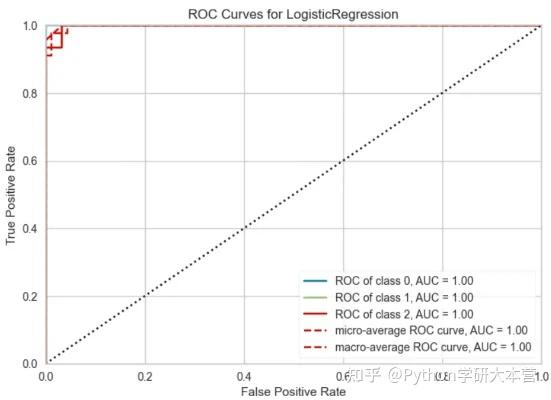
ROC曲线
保存模型:
# 将模型保存为pikle文件(pipeline.pkl)
save_model(lr,'pipeline')

保存模型
要了解更多关于该库及其功能的信息,可以点击如下链接查看文档。
【文档】:https://pycaret.gitbook.io/docs/
关于Python学习指南
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
👉Python所有方向的学习路线👈
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取)

👉Python学习视频600合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉Python70个实战练手案例&源码👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉Python大厂面试资料👈
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉Python副业兼职路线&方法👈
学好 Python 不论是就业还是做副业赚钱都不错,但要学会兼职接单还是要有一个学习规划。

👉 这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方优快云官方认证二维码或者点击链接免费领取【保证100%免费】


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









