







🧠 大模型蒸馏全解析:原理通俗易懂,代码实操详细,真实可落地!
近年来,大模型如 ChatGPT、Claude、文心一言、LLaMA 等风头无两,它们拥有上亿甚至上千亿参数,智能惊艳世界。然而,这些大模型也有一个明显问题——太“重”了:部署门槛高、运行慢、成本贵。
有没有办法让普通开发者、企业、小团队也用得起 AI 的“聪明大脑”?答案就是:大模型蒸馏技术!
🌡️ 通俗理解:什么是模型蒸馏?
我们用一个“厨师教学”的比喻来形象说明:
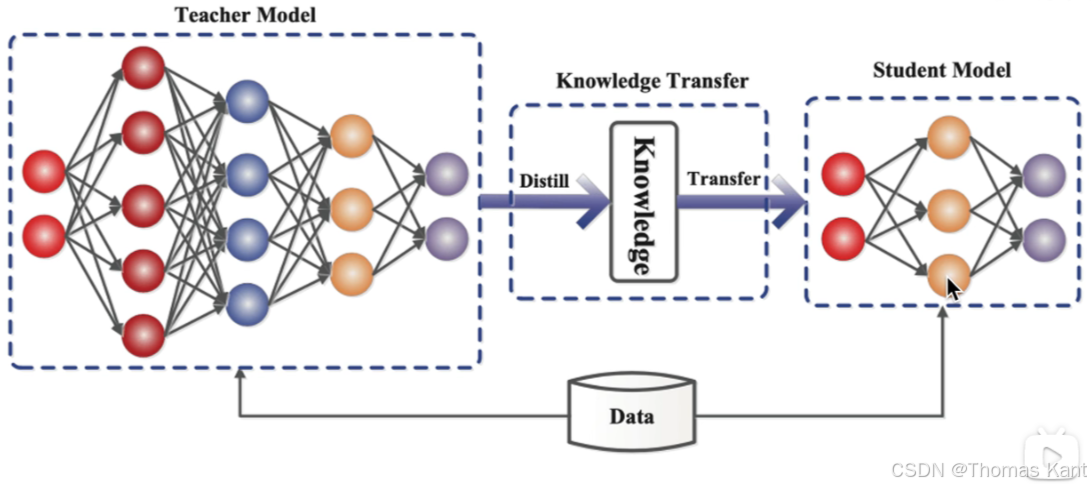
你是一个米其林厨师(大模型),技术精湛。但你要把手艺教给一个学徒(小模型)。你不光告诉他怎么做菜(预测结果),还告诉他每道工序的技巧(中间过程)和判断依据(概率输出)。结果,虽然他经验不足,但也能做出 80% 水准的佳肴!
这就是 模型蒸馏(Knowledge Distillation) 的核心思想:
通过教师模型(Teacher)训练学生模型(Student),让后者学习前者的知识、思维方式、输出风格,从而获得“以小博大”的能力。
🧠 模型蒸馏的技术原理
这一概念最早由 Hinton 等人提出(Distilling the Knowledge in a Neural Network, 2015),本质是用 soft targets(软标签) 来辅助学生模型的训练:
- Soft targets 是教师模型对每个类别输出的概率分布(如“这张图片是狗的概率 0.9,猫是 0.1”)
- 相较于 hard labels(如 1 或 0),soft targets 携带更多“灰度信息”,帮助学生模型更细致地学习
🎯 为什么要蒸馏?
| 问题 | 蒸馏如何解决 |
|---|---|
| 🧱 模型太大 | 学生模型可将参数压缩 5~20 倍 |
| 🐢 推理太慢 | 蒸馏后响应速度提高 2~10 倍 |
| 💰 运行太贵 | 可部署在 CPU、边缘设备、手机上 |
| 🔒 数据隐私 | 支持私有化部署,本地运行 |
🔍 蒸馏方式详解 + 使用场景
1. 🥤 Soft Target 蒸馏(Logits 蒸馏)
- 学习教师模型的输出概率分布(logits)
- 典型使用: 图像分类、文本分类、NER
- 技术代码(含注释):
import torch.nn.functional as F
def distillation_loss(student_logits, teacher_logits, labels, T=2.0, alpha=0.5):
"""
学生模型的知识蒸馏损失函数(Soft Target + Hard Label 结合)
参数说明:
- student_logits: 学生模型输出的 logits(未经过 softmax)
- teacher_logits: 教师模型输出的 logits
- labels: 原始的 hard 标签(如 [1, 0, 1...])
- T: 蒸馏温度(temperature),用于软化概率分布,T 越大分布越平滑,建议值 1~5
- alpha: 权重因子,控制 hard loss 与 soft loss 的比例,常用范围 0.3 ~ 0.7
"""
soft_loss = F.kl_div(
F.log_softmax(student_logits / T, dim=1),
F.softmax(teacher_logits / T, dim=1),
reduction='batchmean'
) * (T * T)
hard_loss = F.cross_entropy(student_logits, labels)
return alpha * hard_loss + ( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











