




 本文介绍了字节跳动在面对ClickHouse在处理复杂查询时遇到的挑战,如协调器压力、不支持Shuffle等问题。为解决这些问题,字节跳动采用了分Stage执行方式,引入了依赖调度和AllAtOnce策略,优化了数据交换和内存控制,并实现了Join的多种优化。此外,还进行了网络连接和传输的优化,如引入RDMA和Runtime Filter。通过这些技术手段,字节跳动显著提高了ClickHouse在复杂查询场景下的性能。
本文介绍了字节跳动在面对ClickHouse在处理复杂查询时遇到的挑战,如协调器压力、不支持Shuffle等问题。为解决这些问题,字节跳动采用了分Stage执行方式,引入了依赖调度和AllAtOnce策略,优化了数据交换和内存控制,并实现了Join的多种优化。此外,还进行了网络连接和传输的优化,如引入RDMA和Runtime Filter。通过这些技术手段,字节跳动显著提高了ClickHouse在复杂查询场景下的性能。
ClickHouse 作为目前业内主流的列式存储数据库(DBMS)之一,拥有着同类型 DBMS 难以企及的查询速度。作为该领域中的后起之秀,ClickHouse 已凭借其性能优势引领了业内新一轮分析型数据库的热潮。但随着企业业务数据量的不断扩大,在复杂 query 场景下,ClickHouse 容易存在查询异常问题,影响业务正常推进。
字节跳动作为国内最大规模的 ClickHouse 使用者,在对 ClickHouse 的应用与优化过程中积累了大量技术经验。本文将分享字节跳动解决 ClickHouse 复杂查询问题的优化思路与技术细节。
项目背景
ClickHouse 的执行模式与 Druid、ES 等大数据引擎类似,其基本的查询模式可分为两个阶段。第一阶段,Coordinator 在收到查询后,将请求发送给对应的 Worker 节点。第二阶段,Worker 节点完成计算,Coordinator 在收到各 Worker 节点的数据后进行汇聚和处理,并将处理后的结果返回。
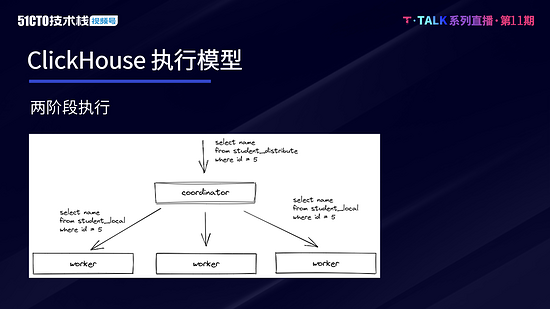
两阶段的执行模式能够较为高效地支持目前许多常见的业务场景,例如各类大宽表单的查询,这也是 ClickHouse 最擅长的场景。ClickHouse 的优点是简单、高效,通常来说,简单就意味着高效。但随着企业业务的持续发展,愈加复杂的业务场景对 ClickHouse 提出了以下三类挑战。
第一类,当一阶段返回的数据较多,且二阶段计算较为复杂时,Coordinator 会承受较大压力,容易成为 Query 的瓶颈。例如一些重计算的 Agg 算子,如 Count Distinct,若采用哈希表的方式进行去重,第二阶段需在 Coordinator 单机上去合并各个 Worker 的哈希表。这个计算量会很重且无法并行。
第二类,由于目前 ClickHouse 模式并不支持 Shuffle,因此对于 Join 而言,右表必须为全量数据。无论是普通 Join 还是 Global Join,当右表的数据量较大时,若将数据都放到内存中,会比较容易 OOM。若将数据 spill 到磁盘,虽然可以解决内存问题,但由于有磁盘 IO 和数据序列化、反序列化的代价,因此查询的性能会受到影响。特别是当 Join 采用 Hash Join 时,如果右表是一张大表,构建也会比较慢。针对构建问题,近期社区也进行了一些右表并行构建的优化,数据按照 Join key 进行 Split 来并行地构建多个 Hash Table,但额外的代价是左右表都需要增加一次 Split 操作。
第三类,则是关于复杂查询(如多表 Join、嵌套多个子查询、window function 等),ClickHouse 对这类需求场景的支持并不是特别友好,由于 ClickHouse 并不能通过 Shuffle 来分散数据增加执行并行度,并且其生成的 Pipeline 在一些 case 下并不能充分并行。因此在某些场景下,难以发挥集群的全部资源。
随着企业业务复杂度的不断提升,复杂查询,特别是有多轮的分布式 Join,且有很多 agg 的计算的需求会越来越强烈。在这种情况下,业务并不希望所有的 Query 都按照 ClickHouse 擅长的模式进行,即通过上游数据 ETL 来产生大宽表。这样做对 ETL 的成本较大,并且可能会有一些数据冗余。

企业的集群资源是有限的,但整体的数据量会持续增长,因此在这种情况下,我们希望能够充分地去利用机器的资源,来应对这种越来越复杂的业务场景和 SQL。所以我们的目标是基于 ClickHouse 能够高效支持复杂查询。
技术方案
对于 ClickHouse 复杂查询的实现,我们采用了分 Stage 的执行方式,来替换掉目前 ClickHouse 的两阶段执行方式。类似于其他的分布式数据库引擎,例如 Presto 等,会将一个复杂的 Query 按数据交换情况切分成多个 Stage,各 Stage 之间则通过 Exchange 完成数据交换。Stage 之间的数据交换主要有以下三种形式。
-
按照单个或者多个 key 进行 Shuffle
-
将单个或者多个节点的数据汇聚到一个节点上,称为 Gather
-
将同一份数据复制到多个节点上,称为 Broadcast 或广播
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









