




 本文探讨了Kafka如何通过内存池设计优化JVM的GC问题,防止full GC导致的性能影响。KafkaProducer使用线程安全的BufferPool,通过批量处理和循环利用内存空间减少GC频率,提升大数据场景下的消息发送速度和吞吐量。
本文探讨了Kafka如何通过内存池设计优化JVM的GC问题,防止full GC导致的性能影响。KafkaProducer使用线程安全的BufferPool,通过批量处理和循环利用内存空间减少GC频率,提升大数据场景下的消息发送速度和吞吐量。
大家都知道Kafka是一个高吞吐的消息队列,是大数据场景首选的消息队列,这种场景就意味着发送单位时间消息的量会特别的大,那么Kafka如何做到能支持能同时发送大量消息的呢?
答案是Kafka通过批量压缩和发送做到的。
我们知道消息肯定是放在内存中的,大数据场景消息的不断发送,内存中不断存在大量的消息,很容易引起GC
频繁的GC特别是full gc是会造成“stop the world”,也就是其他线程停止工作等待垃圾回收线程执行,继而进一步影响发送的速度影响吞吐量,那么Kafka是如何做到优化JVM的GC问题的呢?看完本篇文章你会get到。
Kafka的内存池
下面介绍下Kafka客户端发送的大致过程,如下图:
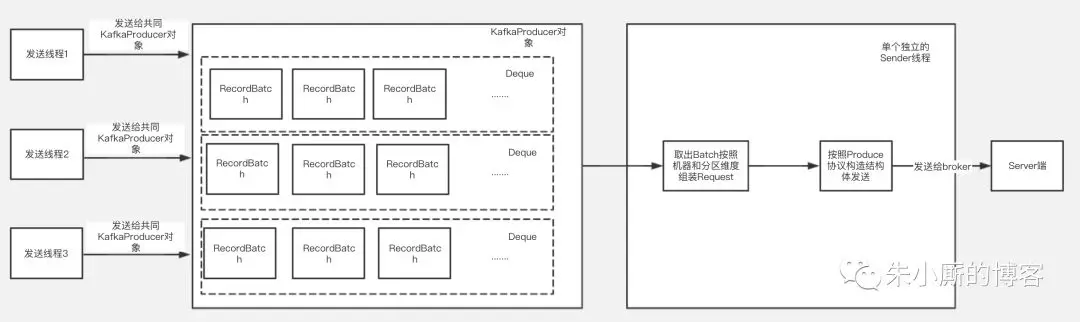
Kafka的kafkaProducer对象是线程安全的,每个发送线程在发送消息时候共用一个kafkaProducer对象来调用发送方法,最后发送的数据根据Topic和分区的不同被组装进某一个RecordBatch中。
发送的数据放入RecordBatch后会被发送线程批量取出组装成ProduceRequest对象发送给Kafka服务端。
可以看到发送数据线程和取数据线程都要跟内存中的RecordBatch打交道,RecordBatch是存储数据的对象,那么RecordBatch是怎么分配的呢?
下面我们看下Kafka的缓冲池结构,如下图所示:
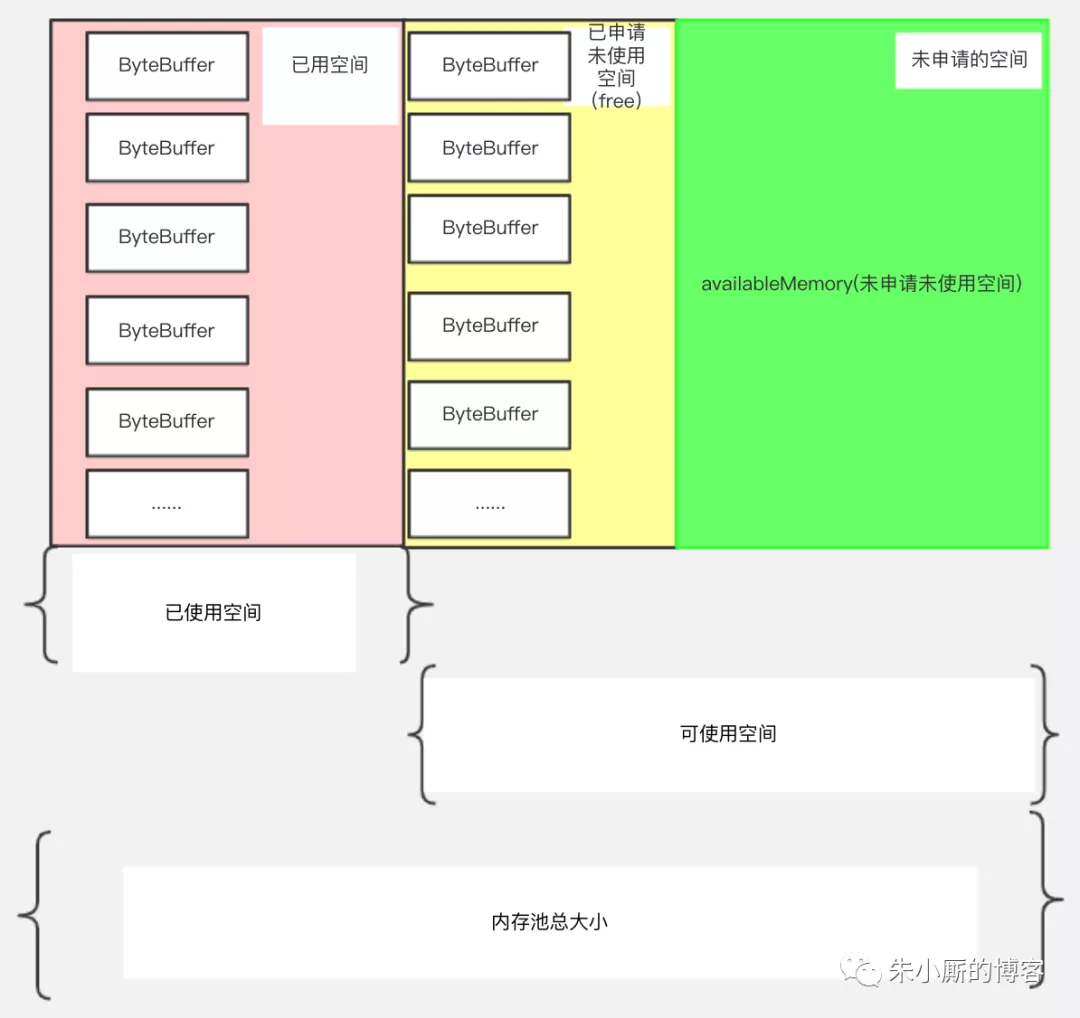
名词解释:缓冲池:BufferPool
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 174万+
174万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









