







找工作一直在找机器学习的岗位,最近在博客上看到一些面试题,做了一下,对自己不懂的地方做了一些总结:
1. 假设X公司的员工收入分布中位数为$35,000,25%和75%比例处的数值为$21,000 和$53,000。收入$1会被认为是异常值吗?
答案:需要更多信息
解析:异常值是指样本中的个别值明显偏离其余观测值,也叫离群值。目前人们对异常值的判别与剔除主要采用物理判别法和统计判别法两种方法。所谓物理判别法就是根据人们对客观事物已有的认识,判别由于外界干扰、人为误差等原因造成实测数据值偏离正常结果,在实验过程中随时判断,随时剔除。统计判别法是给定一个置信概率,并确定一个置信限,凡超过此限的误差,就认为它不属于随机误差范围,将其视为异常值剔除。当物理识别不易判断时,一般采用统计识别法。该题中,所给的信息量过少,无法肯定一定是异常值。
2.我们可以通过一种叫“正规方程”的分析方法来计算线性回归的相关系数,下列关于“正规方程”哪一项是正确的?
1.我们不必选择学习比率 (ok)
2.当特征值数量很大时会很慢 (ok)
3.不需要迭代 (ok)
注释:正规方程可替代梯度下降来计算相关系数
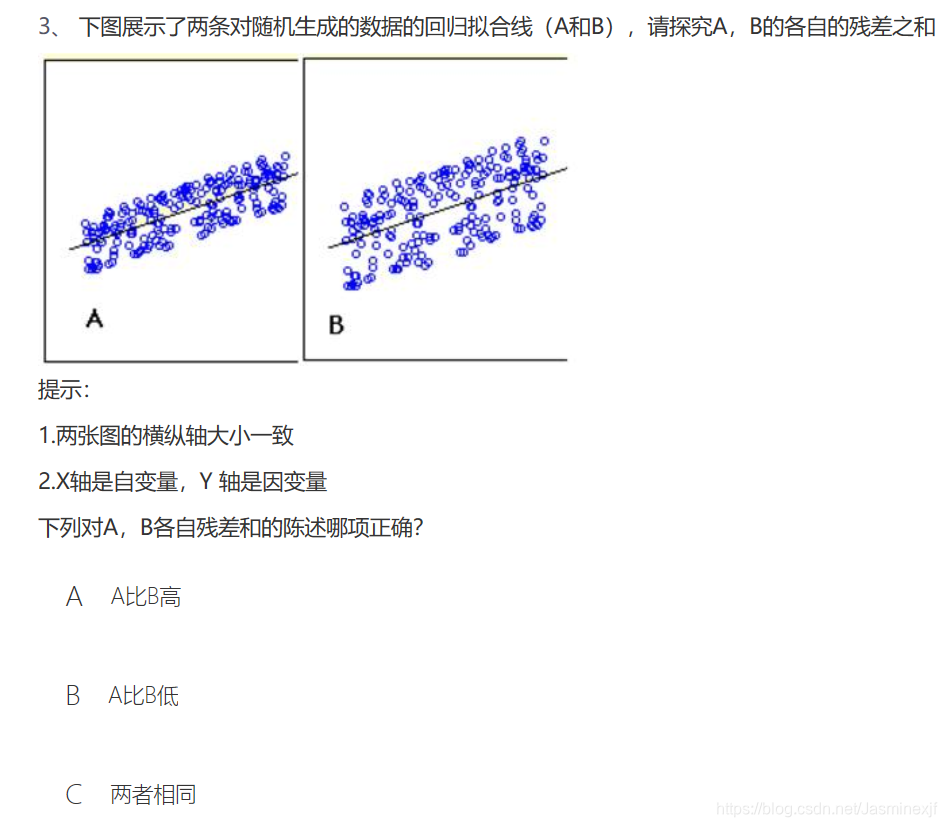
答案:C 因为残差之和总为零
4.在简单线性回归模型中(单自变量),如果改变输入变量1单元,输出变量会变化多少?
答案:斜率值 [简单线性回归公式为Y=a+bx,如果给x增加1,y就变成了a+b(x+1),即y增加了b]
5.下列哪一种回归方法的相关系数没有闭式解?
答案:Lasso回归没有闭式解,Lasso不允许闭式解,L1-penalty使解为非线性的,所以需要近似解
6.
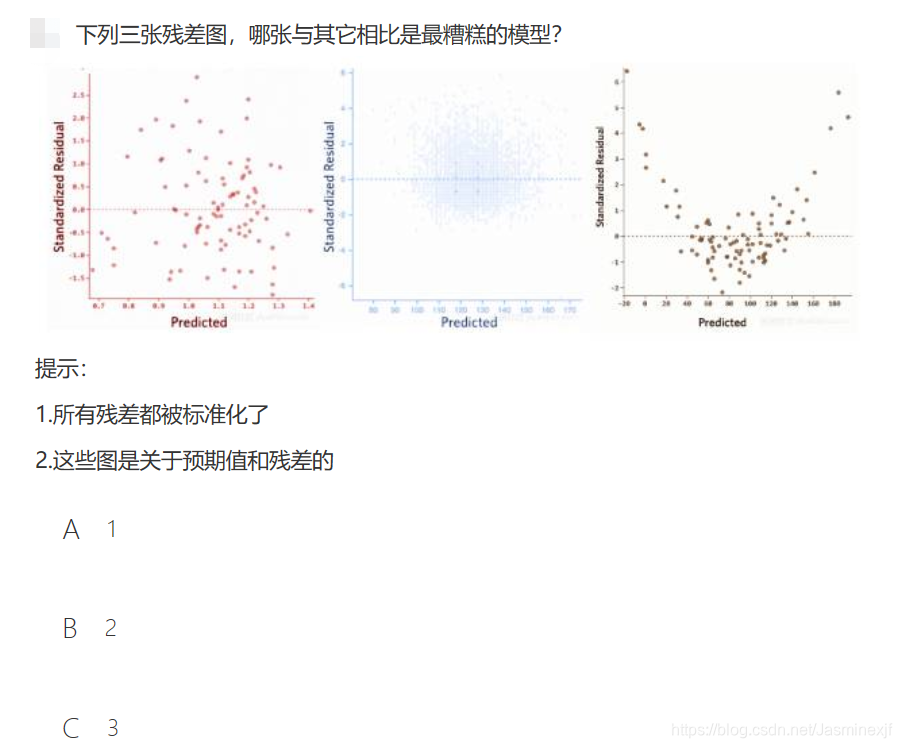
预测值与残差之间不应该存在任何函数关系,若存在函数关系,表明模型拟合的效果并不很好。对应在图中,若横坐标是预测值,纵坐标是残差,残差应表现为与预测值无关的随机分布。但是,图 3 中残差与预测值呈二次函数关系,表明该模型并不理想
7.假设有如下一组输入并输出一个实数的数据,则线性回归(Y = bX+c)的留一法交叉验证均方误差为?
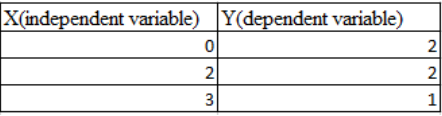
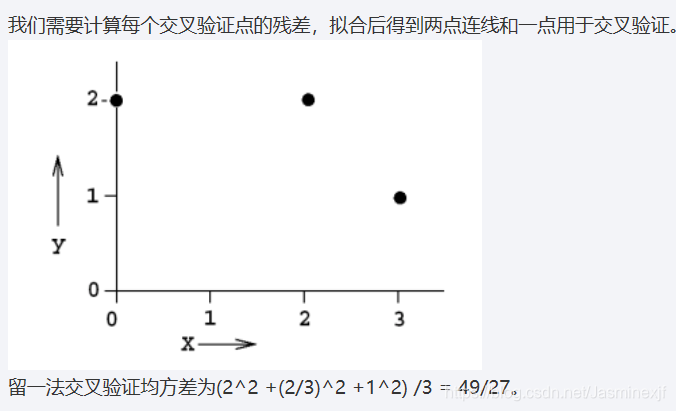
8.线性回归和逻辑回归中,关于损失函数对权重系数的偏导数,下列说法正确的是?
线性回归和逻辑回归对权重系数的偏导数都相同。
线性回归的损失函数为:
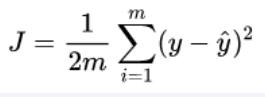
逻辑回归的损失函数为:
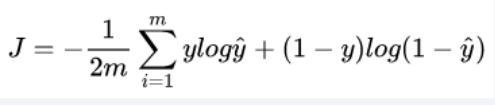
线性回归输出值Z经过sigmoid函数就是逻辑回归输出值,结合上述损失函数表达式可知,逻辑回归的损失函数对Z求偏导数与线性回归的损失函数对Z求偏导数是一样的,且两者的Z=(权重向量和特征向量的内积),故线性回归和逻辑回归中,关于损失函数对权重系数的偏导数是一样的。
9.下列哪种方法被用于预测因变量? 1.线性回归 2.逻辑回归
答案:逻辑回归 [逻辑回归的输出是因变量Y取值的概率,用于分类问题,而不是对因变量的取值进行预测,而线性回归的输出是模型对因变量Y的取值进行预测和估计]
10.Y的预期值是关于变量X(X1,X2….Xn)的线性函数,回归线定义为Y = β0 + β1 X1 + β2 X2……+ βn Xn,下列陈述哪项正确? 1.如果Xi的变化量为 Xi,其它为常量,则Y的变化量为βi Xi,常量βi可以为正数或负数 (ok)
2. βi 的值都是一样的,除非是其它X的βi (ok)
3.X对Y预期值的总影响为每个分影响之和 提示:特征值间相互独立,互不干扰 (ok)
11.假设对数据提供一个逻辑回归模型,得到训练精度X和测试精度Y。在数据中加入新的特征值,则下列哪一项是正确的?
提示:其余参数是一样的
A. 训练精度总是下降 【向模型中加入更多特征值会提高训练精度,低偏差;如果特征值是显著的,测试精度会上升。】
12.以下哪一种方法最适合在n(n>1)维空间中做异常点检测 [马氏距离]解释:马氏距离是是一种有效的计算两个未知样本集的相似度的多元计量方法,以卡方分布为基础,表示数据的协方差距离。与欧氏距离不同的是它考虑到各种特性之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是关联的)。因此马氏距离常用于多元异常值检测。
13.
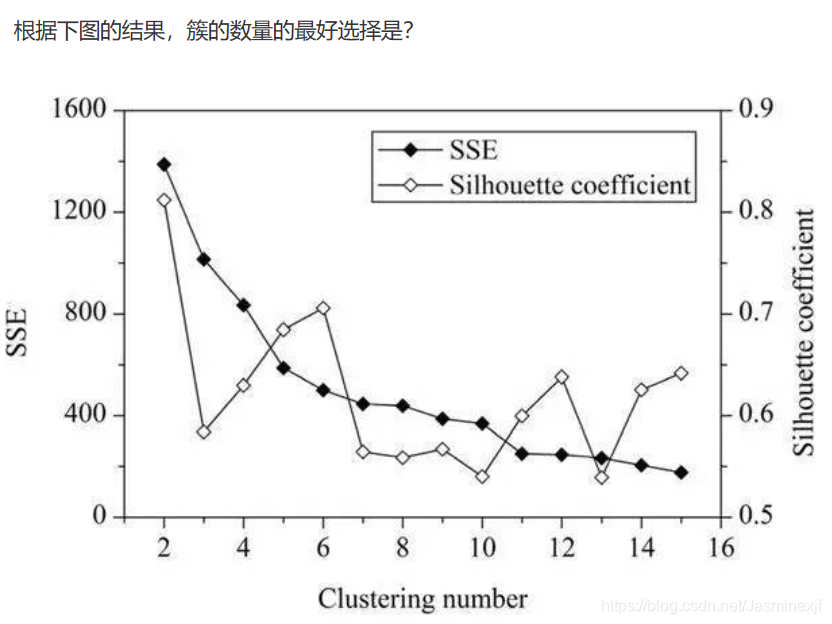
一般来说,平均轮廓系数越高,聚类的质量也相对较好。在这道题中,对于研究区域的网格单元,最优聚类数应该是2,这时平均轮廓系数的值最高。但是,聚类结果(k=2)的 SSE 值太大了。当 k=6 时,SEE 的值会低很多,但此时平均轮廓系数的值非常高,仅仅比 k=2 时的值低一点。因此,k=6 是最佳的选择。
14. 在进行聚类分析之前,给出少于所需数据的数据点,下面哪种方法最适合用于数据清理? 1 限制和增加变量 2 去除异常值
答案:1 [在数据点相对较少的时候,不推荐去除异常值,在一些情况下,对变量进行剔除或增加更合适]
15.决策树算法可以用于数据分析中的聚类分析,本质上是一种分类算法
16.答案:【1,2,3】
电影推荐系统是以下哪些的应用实例:
1 分类
2 聚类
3 强化学习
4 回归解释:一般来说,电影推荐系统会基于用户过往的活动和资料,将用户聚集在有限数量的相似组中。然后,从根本上来说,对同一集群的用户进行相似的推荐。 在某些情况下,电影推荐系统也可以归为分类问题,将最适当的某类电影分配给特定用户组的用户。与此同时,电影推荐系统也可以视为增强学习问题,即通过先前的推荐来改进以后的电影推荐。
17. 一个SVM存在欠拟合问题,下面怎么做能提高模型的性能:A
A.增大惩罚参数C
B.减小惩罚参数C
C.减小核函数系数(gamma值)
解释:C >0称为惩罚参数,是调和二者的系数,C值大时对误差分类的惩罚增大,
当C越大,趋近无穷的时候,表示不允许分类误差的存在,margin越小,容易过拟合。
C值小时对误差分类的惩罚减小,当C趋于0时,表示我们不再关注分类是否正确,只要求margin越大,容易欠拟合。
18.频率派和贝叶斯派的区别,说法正确的是 :贝叶斯学派考虑先验概率
19.以下对朴素贝叶斯算法说法错误的是:D
A.适合多分类任务
B.对于大训练数据集运行速度快
C.属于生成模型
D.特征有缺失值时无法计算
解释:朴素贝叶斯对数据的训练和分类也仅仅是特征概率的数学运算而已,就算缺失了某个特征,顶多不用计数而已,还是可以计算的
20.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









