




 本文探讨了Spring中的doScan方法,重点在于findCandidateComponents方法中的scanCandidateComponents扫描逻辑。通过分析过滤器的工作方式,特别是AnnotationTypeFilter的match方法,展示了如何匹配Component注解以确定是否包含在扫描范围内。最后,文章提到了扫描结果如何注册到Spring容器,并预告了后续将深入讲解BeanDefinition如何转换为bean对象的过程。
本文探讨了Spring中的doScan方法,重点在于findCandidateComponents方法中的scanCandidateComponents扫描逻辑。通过分析过滤器的工作方式,特别是AnnotationTypeFilter的match方法,展示了如何匹配Component注解以确定是否包含在扫描范围内。最后,文章提到了扫描结果如何注册到Spring容器,并预告了后续将深入讲解BeanDefinition如何转换为bean对象的过程。
老生谈spring(资深小白谈spring(十三):doScan的扫描原理
1、上一节讲了filter过滤器,这节带大家了解doScan的扫描原理:
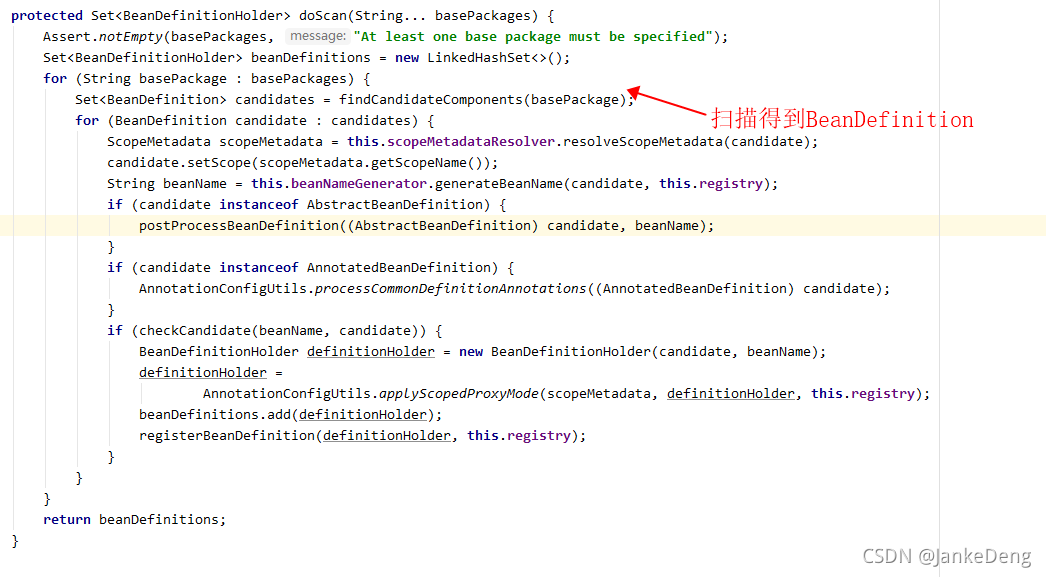 2、在doScan方法中,扫描的主要逻辑就在findCandidateComponents方法中,如果没有特殊配置,findCandidateComponents方法主要是调scanCandidateComponents方法进行扫描。
2、在doScan方法中,扫描的主要逻辑就在findCandidateComponents方法中,如果没有特殊配置,findCandidateComponents方法主要是调scanCandidateComponents方法进行扫描。
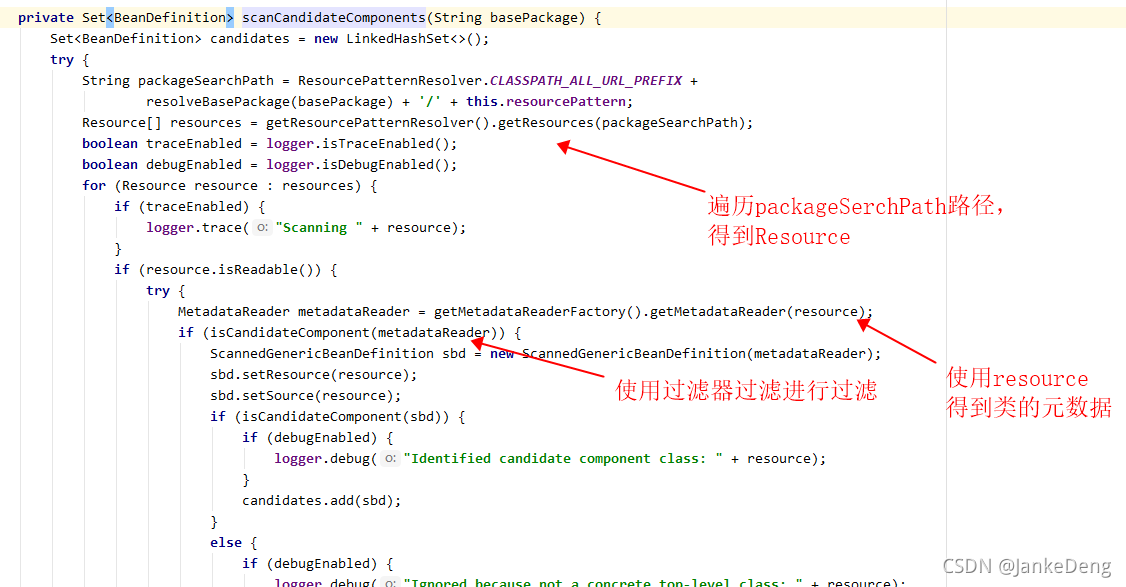
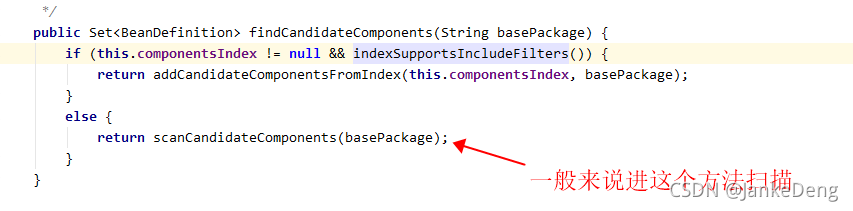 3、遍历路径的代码只是个for循环就不看了,我们主要看的还是过滤器怎么进行过滤的。
3、遍历路径的代码只是个for循环就不看了,我们主要看的还是过滤器怎么进行过滤的。
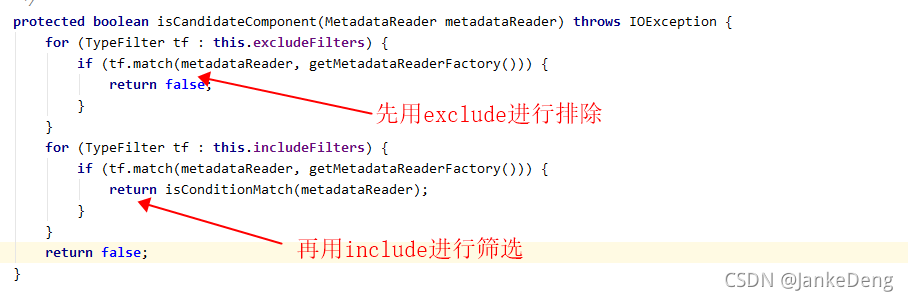
 4、从代码就可以看到,使用match方法进行匹配,exclude匹配的返回false而include匹配的则判断是否含有condiction注解,没有的直接返回true。
4、从代码就可以看到,使用match方法进行匹配,exclude匹配的返回false而include匹配的则判断是否含有condiction注解,没有的直接返回true。
5、先来看spring默认的过滤器AnnotationTypeFilter的match方法,这个方法由父类AbstractTypeHierarchyTraversingFilter给出实现。代码虽然有些长,但匹配逻辑无非就是先匹配自己matchSelf,匹配不上就根据类名匹配matchClassName,再匹配不上则匹配父类,最后匹配接口matchInterface。
@Override
public boolean match(MetadataReader metadataReader, MetadataReaderFactory metadataReaderFactory)
throws IOException {
if (matchSelf(metadataReader)) {
return true;
}
ClassMetadata metadata = metadataReader.getClassMetadata();
if (matchClassName(metadata.getClassName( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1589
1589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









