




 本文介绍了Hive的SQL查询功能、基于Hadoop的数据仓库结构、服务端组件如Driver和Metastore,以及与Spark的对比,特别是SQL运行架构和表的管理。Hive主要适用于离线分析,而Spark在实时性和速度上更具优势。
本文介绍了Hive的SQL查询功能、基于Hadoop的数据仓库结构、服务端组件如Driver和Metastore,以及与Spark的对比,特别是SQL运行架构和表的管理。Hive主要适用于离线分析,而Spark在实时性和速度上更具优势。
Hive通俗的特性
- 结构化数据文件变为数据库表
- sql查询功能
- sql语句转化为MR运行
- 建立在hadoop的数据仓库基础架构
- 使用hadoop的HDFS存储文件
- 实时性较差(应用于海量数据)
- 存储、计算能力容易拓展(源于Hadoop)
支持这些特性的架构
CLI(command line interface)、JDBC/ODBC、Thrift Server、WEB GUI、metastore和Driver(Complier、Optimizer和Executor)
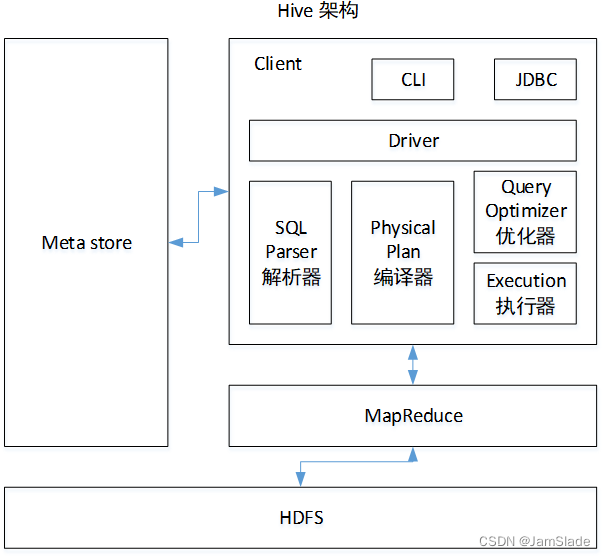
服务端
- Driver:包括了Complier、Optimizer和Executor。将Hive sql解析,编译,优化,生成执行计划
- Metastore:存储hive元数据(描述数据的数据,比如一行数据里面,单个数据的名字叫啥,类型是啥,注释是啥,以及表本身的框架) 解耦hive服务和metastore服务
- Thrift:可扩展且跨语言的服务的开发,hive集成服务支持不同编程语言调用hive的接口、
客户端
- CLI: 命令行接口
- Thrift客户端: hive架构的接口基于thrift客户端(如 JDBC, 面向java的连接; ODBC 开放数据连接)
- WEBGUI:网页访问Hive服务接口
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1451
1451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









