




利用ESP32低成本芯片结合开源小智后端服务(xiaozhi-esp32-server)研发智能玩偶,核心在于通过ESP32实现语音采集、运动控制、传感器数据读取,并利用小智后端进行AI处理(语音识别、自然语言理解、意图识别)和功能扩展。通过MCP协议,后端指令可驱动ESP32控制电机、舵机实现玩偶运动,结合超声波、红外等传感器实现自动避障,并可通过集成摄像头进行视觉处理。ESP32-S3因其AI加速指令和丰富外设是理想选择。小智后端支持Docker快速部署和源码定制,为不同应用场景(教育、娱乐)和用户群体(儿童、成人)提供了灵活的智能交互平台。

1. 核心功能实现与技术路径
1.1 语音交互与后端服务集成
实现智能玩偶的语音交互功能,核心在于将ESP32微控制器与开源小智后端服务(xiaozhi-esp32-server)进行有效集成。ESP32作为前端设备,负责音频信号的采集与初步处理,例如通过内置的I2S接口连接麦克风阵列,进行声音的拾取。乐鑫官方提供的ESP-SR (Speech Recognition)语音识别框架,其唤醒词引擎(WakeNet)能够在本地运行,持续监听音频流,当检测到预设的唤醒词(如“小智小智”)时,触发设备进入语音交互状态 。这种本地唤醒机制即使在有环境噪声的情况下也能保持较高的准确率,官方数据显示在噪声环境下识别率不低于80% 。唤醒后,ESP32需要将用户的语音数据实时传输到小智后端服务进行处理。为了实现低延迟的流式对话,通常采用WebSocket协议进行全双工长连接通信 。ESP32在检测到唤醒词后,立即通过已建立的WebSocket连接流式发送音频数据到服务器。服务器端(小智后端服务)接收到音频流后,进行语音识别(ASR)、自然语言理解(NLU),并通过集成的LLM(大语言模型)生成回复文本,再通过TTS(文本转语音)服务将文本转换为语音,最后将生成的音频数据通过WebSocket回传给ESP32,由ESP32驱动扬声器播放,完成一次交互。
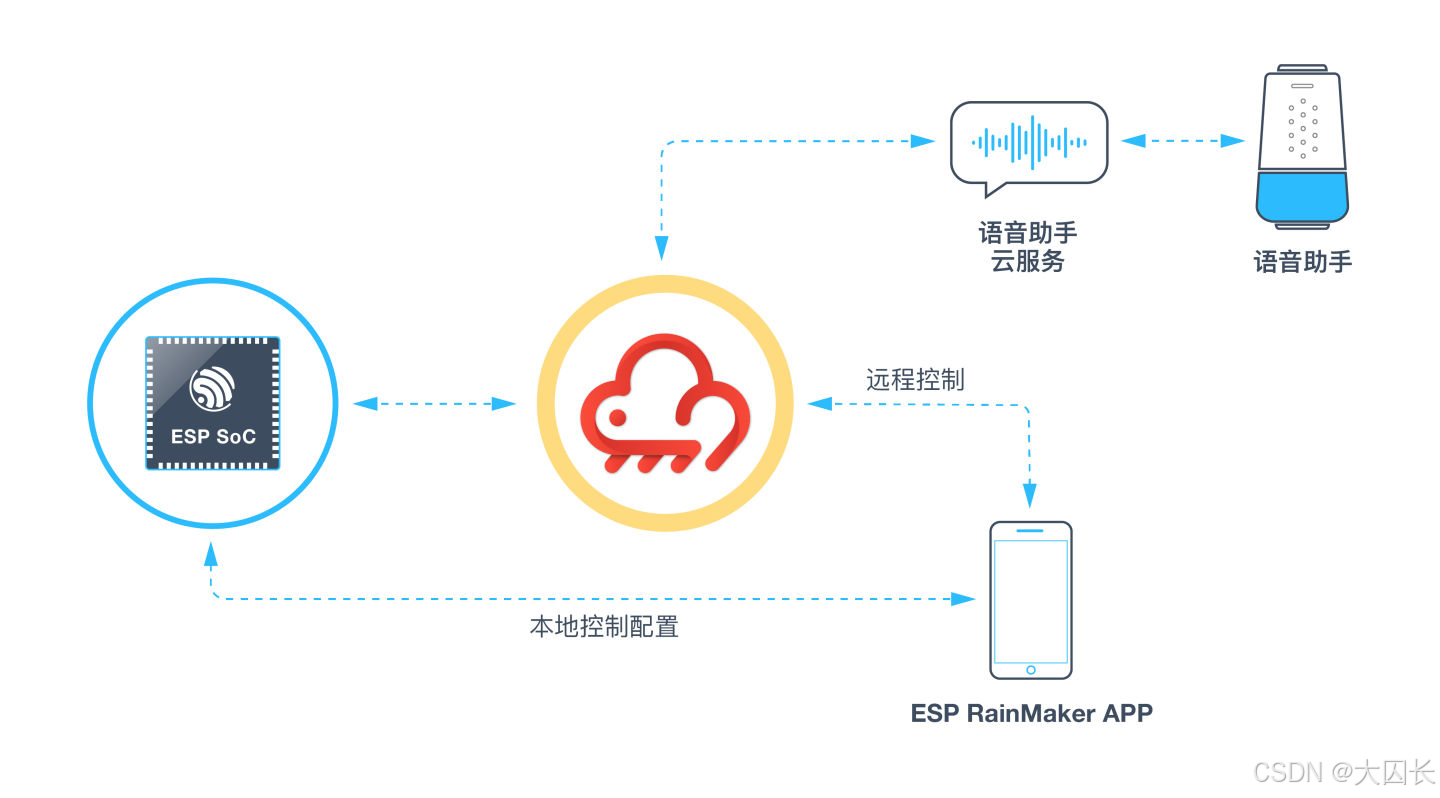
小智后端服务(xiaozhi-esp32-server)是一个关键组件,它基于小智通信协议,为开源智能硬件项目xiaozhi-esp32提供后端技术支撑,支持AI推理服务与API应用的快速部署 。该服务端项目主要由两部分组成:基于Python的 xiaozhi-server(负责核心语音交互逻辑)和基于Java Spring Boot的 manager-api(提供管理接口和数据存储)。xiaozhi-server 的配置文件 config.yaml (或其用户自定义版本 data/.config.yaml) 允许开发者灵活配置ASR、LLM、TTS等模块的提供商和详细参数 。例如,可以选择使用FunASR进行本地语音识别,选择ChatGLMLLM作为大语言模型,以及EdgeTTS进行语音合成 。这种模块化的设计使得开发者可以根据需求选择不同的服务提供商,甚至可以集成自定义的模块。此外,小智后端服务还支持通过管理端API动态获取配置,方便多设备或远程部署场景下的统一管理 。在通信层面,WebSocket消息格式主要使用JSON格式的文本消息和二进制音频数据 。客户端(ESP32)可以向服务端发送 hello、abort、listen 等类型的文本消息,以及包含Opus编码音频数据的二进制帧。服务端则可以向客户端发送欢迎消息、STT识别结果、TTS音频数据以及服务器控制消息等 。通过这种标准化的通信协议和可配置的后端服务,开发者可以构建出功能丰富、响应及时的语音交互体验。
1.2 运动能力实现
智能玩偶的运动能力实现,依赖于ESP32微控制器对电机、舵机等执行器的精确控制,并结合小智后端服务下发的指令或本地传感器反馈进行决策。一个关键的实现路径是借鉴已有的智能小车项目,例如DF创客社区上基于FireBeetle 2 ESP32-P4和小智AI的智能小车项目 。该项目通过ESP32-P4开发板连接TB6612FNG微型双路直流电机驱动模块,进而驱动两个N20减速电机,实现了小车的前进、后退、停止、左转和右转等基本运动功能。其核心在于集成了 xiaozhi-mcp 库,该库专为ESP32设备设计,用于无缝接入小智AI平台的MCP(模型上下文协议)服务器 。通过 xiaozhi-mcp 库,ESP32设备能够以较低的成本实现与小智AI平台的稳定通信,支持复杂的JSON-RPC协议,并具备自动重连机制,确保了通信的可靠性 。
在软件层面,开发者需要在Arduino IDE中编写ESP32的控制程序,加载 xiaozhi-mcp 库,并配置WiFi和MCP服务器地址 。程序的核心逻辑包括初始化WiFi和MCP客户端,注册运动控制相关的“工具”(tools)。当用户通过语音(例如,连接到小智AI平台的行空板K10)发出指令,如“前进”,小智AI平台会将此语音指令解析,并通过MCP协议将相应的JSON-RPC消息发送给ESP32。ESP32端的 xiaozhi-mcp 库接收到消息后,会调用预先注册的运动控制工具的回调函数。在该回调函数中,程序解析JSON参数,获取具体的运动指令(如“state”: “前进”),然后通过ESP32的GPIO引脚控制TB6612FNG驱动模块,从而改变电机的转动状态和方向,实现玩偶的相应动作 。例如,当解析到“前进”指令时,回调函数会设置相应的电机控制引脚电平,使两个电机同时正转。这种架构将语音识别和意图理解放在云端(小智AI平台),而将具体的运动控制逻辑放在本地ESP32执行,既利用了云端AI的强大能力,也保证了本地控制的实时性。对于智能玩偶,可以根据其具体的机械结构和自由度,设计更复杂的运动序列,并通过类似的方式,将语音指令映射到这些预定义的运动序列上。
1.3 自动避障功能实现
在智能玩偶的研发过程中,自动避障功能是确保其能够在复杂环境中安全、自主移动的关键。通过对现有ESP32相关项目的调研,可以发现多种实现自动避障的技术路径,主要依赖于不同类型的传感器和相应的控制算法。一种常见的方案是使用超声波传感器,例如HC-SR04模块,其工作原理是通过发射超声波并计算遇到障碍物后反射回来的时间差来确定距离 。当玩偶前方的障碍物距离小于预设的安全阈值时,控制系统会触发避障动作,例如停止、后退或转向。为了提高避障的灵活性和可靠性,可以将超声波传感器与舵机结合,通过舵机控制传感器的探测方向,从而实现对玩偶周围多个方向的障碍物进行扫描和测距 。这种方案能够更全面地感知环境,但需要注意的是,超声波传感器在探测角度较小或表面不规则的障碍物时,可能会出现测量不准确或无法探测的情况 。
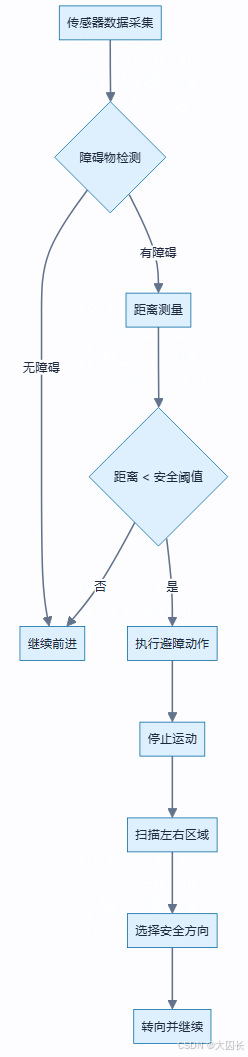
另一种广泛应用的避障传感器是红外避障模块。这类模块通常包含一对红外发射管和接收管,当发射出的红外线遇到障碍物被反射回来并被接收管接收时,模块会输出相应的信号 。红外避障模块的探测距离相对较短,一般在十几厘米以内,并且其性能容易受到环境光线和障碍物颜色的影响 。因此,在一些项目中,红外避障模块常被用作超声波避障的辅助手段,例如安装在玩偶的侧面,用于检测在前进过程中可能缓慢接近的侧面障碍物 。当一侧的红外传感器检测到障碍物时,控制系统可以调整该侧轮子的转速,使玩偶偏向另一侧行驶,从而避免碰撞 。此外,还有项目提及使用激光雷达(Lidar)等更高级的传感器来实现更精确的环境感知和避障,但这通常会带来成本的增加 。
在控制算法层面,简单的避障策略可以是基于阈值的判断,例如当检测到障碍物距离小于某个值时执行预设的避障动作。更复杂的策略可能涉及到路径规划算法,如根据传感器数据将前方区域划分为不同的区间(如左、中、右),然后根据障碍物的分布情况决定转向哪个方向 。例如,如果前方有障碍,则先判断右侧,无障碍则右转;如果右侧也有障碍,则判断左侧,无障碍则左转;如果左右都有障碍,则可能执行调头动作 。模糊逻辑控制也是一种被提及的避障算法,它能够更好地处理传感器数据的不确定性和模糊性,从而做出更柔和的避障决策 。在实际的ESP32项目中,避障功能的实现通常涉及到GPIO口的读写(用于控制电机和读取传感器状态)以及PWM(脉宽调制)信号的使用(用于控制电机速度和舵机角度)。例如,通过digitalWrite()函数控制电机的转动方向,通过analogWrite()或ESP32的LEDC控制器生成PWM信号来控制电机转速或舵机角度 。
1.4 视觉处理功能实现
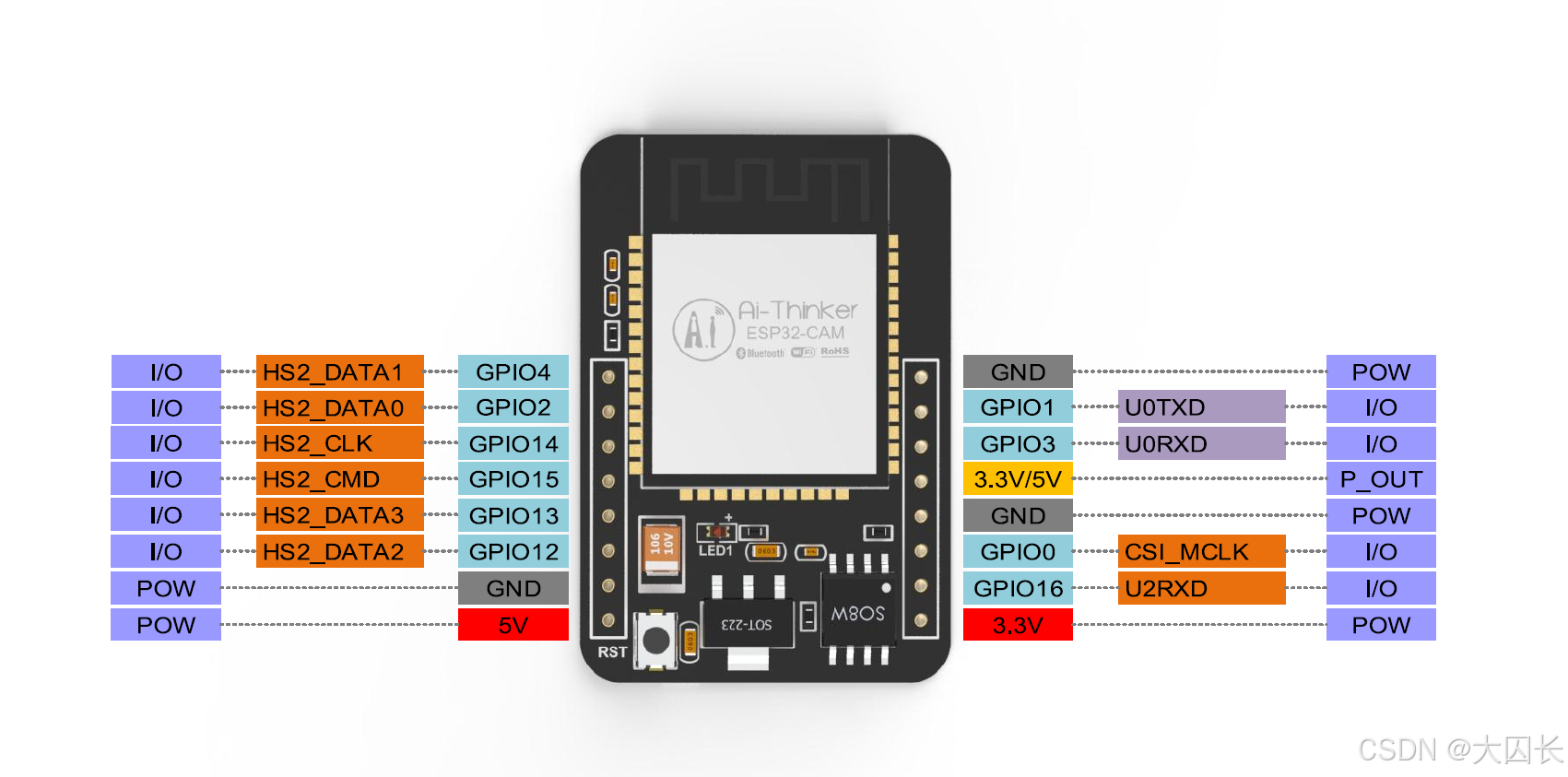
视觉处理是智能玩偶实现高级交互和环境感知的关键功能之一。通过集成摄像头模块和相应的图像处理算法,玩偶可以识别物体、人脸,甚至进行简单的场景理解。在ESP32平台上实现视觉处理功能,需要综合考虑芯片的处理能力、内存限制以及可用的开源算法库。一种可行的技术路径是利用ESP32-CAM这类集成了摄像头接口和ESP32芯片的模块。例如,DFRobot推出的ESP32-S3 AI智能摄像头模块,集成了OV3660摄像头,并支持TensorFlow Lite、YOLO和OpenCV等边缘AI计算框架,为开发者提供了本地化AI推理的能力 。该模块还提供了小智AI固件和OpenAI接入教程,这意味着可以将视觉信息与小智AI的语音交互能力相结合,实现更丰富的多模态交互体验 。例如,玩偶可以通过摄像头识别用户的面部表情,并通过小智AI进行情感分析和回应。
在具体的实现上,可以利用开源项目如“ESP32-CAM Simple AI Robot”作为参考 。该项目展示了如何利用ESP32-CAM模块构建能够执行对象检测、目标追踪和车道追踪的智能机器人。虽然该项目主要面向机器人应用,但其核心的视觉处理逻辑和代码实现对于智能玩偶的视觉功能开发具有重要的借鉴意义。例如,可以借鉴其使用OpenCV或TensorFlow Lite进行图像处理和模型推理的方法。此外,Edge Impulse等无代码/低代码AI开发平台也为ESP32提供了图像识别模型的训练和部署工具,进一步降低了视觉功能开发的门槛 。通过这些工具,开发者可以收集图像数据,训练自定义的视觉模型(如识别特定玩具、手势等),并将其部署到ESP32上运行。结合小智后端服务,可以将视觉识别结果上传至云端进行更复杂的分析,或者根据识别结果触发玩偶的特定行为或语音反馈。例如,小智后端服务支持通过MCP协议调用视觉能力,当用户有图片识别需求时,服务端识别到这种意图,会通过MCP向客户端(ESP32设备)发送请求。客户端调用摄像头拍照,然后请求视觉识别模型(可以是本地部署的多模态大模型,也可以是云端API),获得当前图片的描述。客户端再通过MCP把“当前看到的”信息发给服务端,由服务端的LLM进行总结后回答用户 。
2. ESP32芯片选型与硬件设计考量
2.1 ESP32系列芯片选型建议
选择合适的ESP32系列芯片对于智能玩偶的性能、成本和功耗至关重要。乐鑫科技提供了多种ESP32系列芯片,各有侧重。对于需要AI功能的智能玩偶,ESP32-S3是一个值得重点考虑的型号。ESP32-S3搭载Xtensa® 32位LX7双核处理器,主频高达240MHz,集成了用于AI加速的向量指令,拥有512KB SRAM,并支持外部PSRAM(如8MB Octal SPI PSRAM)和Flash(如8MB Octal SPI Flash)。这些特性使其能够较好地支持轻量级的AI任务,如图像识别、语音识别等。例如,ESP-SparkBot和ESP-Spot项目均基于ESP32-S3设计,并实现了语音交互、图像识别等功能 。全国大学生物联网设计竞赛的乐鑫命题也指定使用ESP32-S3作为主控芯片,强调其AI加速能力 。字节跳动的AI玩具“显眼包”也采用了乐鑫的ESP32-S3芯片 。
如果项目对成本有更严格的限制,或者AI功能需
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









