




 本文详细介绍了Python的requests模块,包括安装、response对象、get和post请求的使用、处理中文乱码、携带参数、设置headers、cookies、proxies等。通过实例解析requests的常用方法,帮助理解如何在爬虫中进行网络请求。
本文详细介绍了Python的requests模块,包括安装、response对象、get和post请求的使用、处理中文乱码、携带参数、设置headers、cookies、proxies等。通过实例解析requests的常用方法,帮助理解如何在爬虫中进行网络请求。
requests模块简介
用于发送请求、获取响应,有很多替代模块,比如urllib,但requests代码简洁易懂
requests在底层实际上封装了urllib
requests模块的文档
1. 安装模块(省略)
2. response响应对象
import requests
url = 'http://www.baidu.com'
response = requests.get(url)
# <class 'str'>
print(type(response.text))
# 打印源码
print(response.text)
源码中有乱码的情况

response.text是requests模块按照chardet模块推测出的编码字符集进行编码的结果,所以输出中会有乱码
response.text = response.content.decode(‘推测的编码字符集’)
网络中,字符串以bytes类型传输,response.content是bytes类型的响应源码
response.content解决中文乱码问题
打印二进制源码
import requests
url = 'http://www.baidu.com'
response = requests.get(url)
# 打印二进制源码
print(response.content)

- encoding改一下编码就不会出现乱码
import requests
url = 'http://www.baidu.com'
response = requests.get(url)
# ISO-8859-1 是推测的编码字符集
print(response.encoding)
response.encoding = 'utf8'
print(response.text)

- content.decode() 和**content.decode(‘GBK’)**也能解决乱码问题
decode默认’utf8’
decode()中还可选:gb2312,ascii,iso-8859-1
import requests
url = 'http://www.baidu.com'
response = requests.get(url)
# content能解码
print(response.content.decode())

response.content 和 response.text
- 类型不同
- content没有指定解码类型,text的解码类型由requests模块推测
3. response响应对象的其他常用属性/方法
- response.text
- response.content
- response.url
响应的url,请求的url不一定返回响应,有可能重定向 - reponse.status_code
状态码 - response.request.headers
响应对象对应的请求的请求头(不是响应头) - response.headers
响应头 - response.request._cookies
响应对应的请求的cookies,返回cookieJar类型 - response.cookies
响应的cookie(经过了Set-cookie动作,返回CookieJar类型) - requests.json()
自动将json字符串类型的响应内容转换为Python对象(dict或list)
import requests
url = 'http://www.baidu.com'
response = requests.get(url)
print(response.request.headers)
print(response.headers)
print(response.request._cookies)
print(response.cookies)
注意请求头的User-Agent,很容易被识别为爬虫
Cookie中的BDORZ是需要特别注意的

4. requests发送get请求
在url中携带参数
方法一:url中直接带搜索的关键参数wd
import requests
url = 'http://www.baidu.com/s?wd=python'
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Mobile Safari/537.36',}
response = requests.get(url, headers = headers)
with open('baidu.html', 'wb') as f:
f.write(response.content)
params参数
方法二:发送请求时设置字典参数,请求时赋值给params
就是把wd放到一个dict中
import requests
url = 'http://www.baidu.com/s?'
# 构建参数字典
data = {'wd': 'python'}
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Mobile Safari/537.36',}
response = requests.get(url, headers = headers, params=data)
# 可以看到和url直接带参数一样的
# http://www.baidu.com/s?wd=python
print(response.url)
with open('baidu1.html', 'wb') as f:
f.write(response.content)
headers参数
可以发现浏览器的响应源码要远比requests请求得到的多
response = requests.get(url, headers = {})
改掉请求头的User-Agent能获取更多源码
import requests
url = 'http://www.baidu.com'
response0 = requests.get(url)
print(len(response0.content.decode()))
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Mobile Safari/537.36',}
response = requests.get(url, headers = headers)
print(len(response.content.decode()))
输出:
2287
287725
timeout参数
requests.get(url, timeout = t)
verify参数
requests.get(url, verify = False)
用于忽略CA证书
访问网站报错“你的链接不是私密连接”,需要点击继续访问才能访问
原因:该网站的CA证书没有经过受信任的根证书颁发机构的认证
import requests
url = 'https://sam.huat.edu.cn:8443/selfservice/'
response = requests.get(url)
print(response.content)
报错:
requests.exceptions.SSLError: HTTPSConnectionPool(host='sam.huat.edu.cn', port=8443): Max retries exceeded with url: /selfservice/ (Caused by SSLError(SSLError("bad handshake: Error([('SSL routines', 'tls_process_server_certificate', 'certificate verify failed')])")))
将代码改成verify = False,出现Warning但能成功请求
import requests
url = 'https://sam.huat.edu.cn:8443/selfservice/'
response = requests.get(url, verify = False)
print(response.content)
cookies参数
携带cookie的方法:
方法一:headers中带cookie,用法同User-Agent,能保持登录
方法二:用cookies参数保持会话,请求时赋值给cookies参数
cookie需要分割为字典,分割方法一:
import requests
url = 'https://github.com/'
cookie = '_octo=GH1.1.108074185.1569543012; _ga=GA1.2.145473203.1569543014; _device_id=630902b10fa46511a88190035faf7b04; user_session=x-nmU_NSgT9CkHqSfEsWfcdZ7-z1gp8WF_sMNVdgpSyhlTOl; __Host-user_session_same_site=x-nmU_NSgT9CkHqSfEsWfcdZ7-z1gp8WF_sMNVdgpSyhlTOl; logged_in=yes; dotcom_user=gbx993; has_recent_activity=1; _gat=1; tz=Asia%2FShanghai; _gh_sess=Bl4EsOZo55epFgz64rn%2FEqJk1HQ69ah2%2BGyWkHNY6S0q9kIm%2B11rpstFha53ZSwLyEsCJYtXlT4KwkVjiQ5y1h0KQMftCtRcdSAfV46sb4zNPfwQ4PDblvBWHg7qiqyjlnhHqV%2BIcZhdSrKTqSzK2FbwHmTTDQZ2yek7ftxNg2U2SAinESpQD0SIyMtvwszA--9FTOdo47nJBdBQuJ--qk%2F9r2L2y6Jl0T2i7xGX1A%3D%3D'
cookie_list = cookie.split('; ')
cookie_dict = dict()
for item in cookie_list:
temp = item.split('=')
cookie_dict[temp[0]] = temp[1]
headers = {'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Mobile Safari/537.36',}
response = requests.get(url, headers = headers, cookies=cookie_dict)
print(response.url)
with open('gh.html', 'wb') as f:
f.write(response.content)
分割方法二:
cookie_dict = {data.split('=')[0]:data.split('=')[1] for data in cookie_list}
cookieJar对象与字典的转换
import requests
url = 'https://baidu.com'
response = requests.get(url)
print(response.cookies)
dict_cookies = requests.utils.dict_from_cookiejar(response.cookies)
print(dict_cookies)
jar_cookies = requests.utils.cookiejar_from_dict(dict_cookies)
print(jar_cookies)
输出:
<RequestsCookieJar[<Cookie BDORZ=27315 for .baidu.com/>]>
{'BDORZ': '27315'}
<RequestsCookieJar[<Cookie BDORZ=27315 for />]>
proxies参数
代理
代理服务器可以为我们向目标服务器转发请求
- 正向代理
为客户端发送请求,浏览器知道最终处理请求的服务器真实ip地址,如VPN - 反向代理
不为客户端转发请求,而是为最终处理请求的服务器转发请求,浏览器不知道服务器的真实地址,如Nginx,Nginx不处理请求,做负载均衡,而是转发给后台的某台服务器,客户端不知道请求发给谁了
代理IP的分类
-
根据代理IP的匿名程度:对于目标服务器,这个代理的匿名程度
透明:目标服务器能透过代理,看到发送请求的那一方
匿名:目标服务器知道代理是代理,但看不到发送请求的那一方
高匿:目标服务器不知道这个代理是不是代理 -
根据网站所用协议:目标url的协议
http
https
socks隧道代理:速度更快,在socket层设置,不关心是何种协议
假如代理请求失败则卡住/报错
proxies = {
"http":"http://12.123.123.12:987"
"https":"https://34.34.23.45:765"
}
requests.get(url, proxies = p)
这里的proxies是一个字典 { 代理协议:代理IP与端口号 }
url只支持http的,不能用https的
支持https的,可以用http的
5. requests发送post请求
POST请求比GET安全:
- 登陆注册
- 需要传输大文本内容(POST请求对数据长度没有要求)
data 是字典,除了这个参数,其他都和get一样
requests.post(url, data)
一个实践
对翻译网站发送post请求
- 确认需要发送POST请求
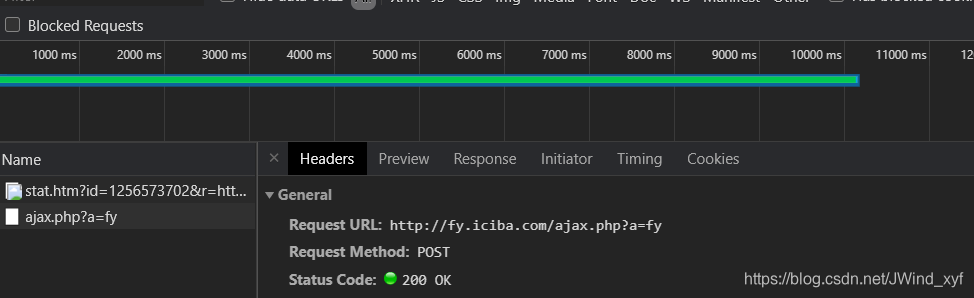
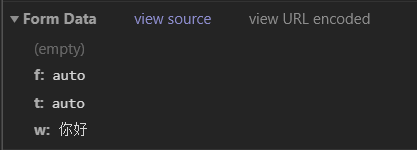
- 确认需要传入的data
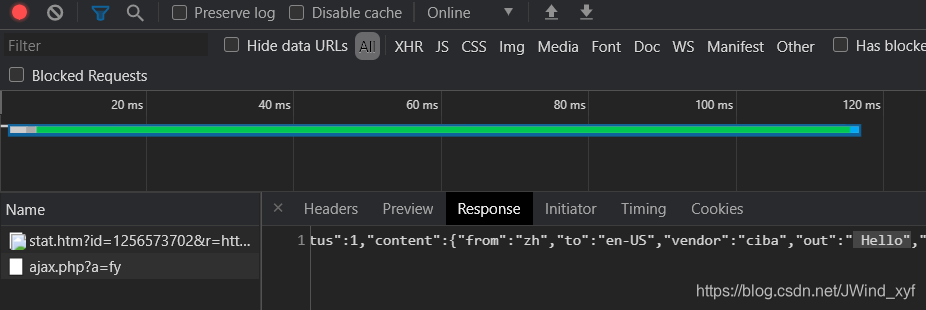
- 确认response中有我们需要的结果Hello
- 构造headers
- 完成代码
import requests
import json
class fy(object):
def __init__(self, word):
self.url = 'http://fy.iciba.com/ajax.php?a=fy'
self.headers = {'User-Agent':'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/84.0.4147.135 Mobile Safari/537.36'}
self.data = {'f': 'auto',
't':'auto',
'w':word,
}
def get_res(self):
response = requests.post(self.url, data = self.data,
headers =self.headers,
)
return response.content
def parse_res(self,data):
# loads方法将json字符串转换成python字典
dict_data = json.loads(data)
print(dict_data['content']['out'])
# 编写爬虫逻辑
def run(self):
response = self.get_res()
self.parse_res(response)
if __name__ == '__main__':
w = input('输入需要翻译的内容')
f = fy(w)
f.run()
输出:
输入需要翻译的内容你好
Hello
post请求data来源
- 固定值 抓包比较,不变值
- 输入值 抓包比较,根据需求变化
- 预设值-静态文件 如token,需要从之前的包的response获取
- 预设值-发请求 需要提前单独对某个地址发送请求
- 在客户端生成的 分析js,模拟生成数据
在客户端生成的比如有道翻译:


右边的salt和lts,其实是时间戳相关
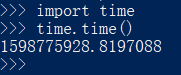
尝试多次就会发现lts比salt多的一位数字是随机生成的,重新打开一次:
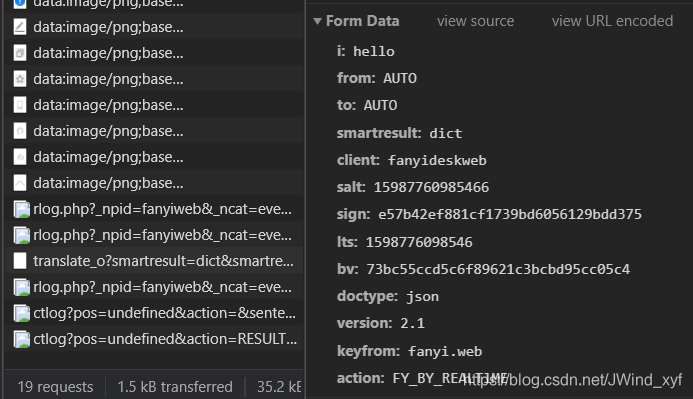
可以猜测bv可能是相对不变的,sign实际上是js生成的,获取sign比较麻烦,需要分析js
6. requests.session
requests.session用于保持会话,能自动处理发送请求获取响应过程中的Cookie,下一次请求会带上前一次的Cookie
用法:
其中get post方法和requests的一样
session = requests.session() # 实例化session对象
response = session.get(url, headers, params,...)
response = session.post(url, headers, data,...)

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









