






这篇论文最主要的贡献就是提出了:反事实基线(counterfactual line)一种用于解决MARL中信用分配的方法。
此前的方法中使用 ,用于对网络参数进行更新,但是这个方法并没有考虑到个体行动对总体的影响,因为对于所有agent这个V都是相同。
而这个反事实基线就是用于评估个体行动对总体影响的,具体来说这个反事实基线就是针对于与单个智能体,你把除了这个智能体以外的智能体行动固定住,然后这个智能体执行除了原来动作以外的可执行动作,计算中心Q的期望,计算得到的期望就是反事实基线。
也就是
那么得到了反事实基线有什么用呢?答案是它可以与全局的Q作差就能得到优势函数,然后根据策略梯度来更新参数
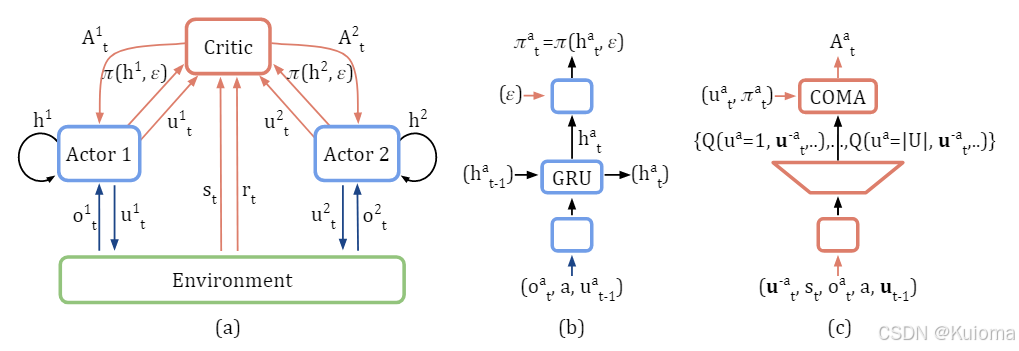
如图为COMA的网络结构,为了更加高效地计算反事实基线,critic网络的输入包括其它智能体的动作 ,全局状态 ,该智能体的局部观测 ,该智能体的ID,以及上一时刻所有智能体的动作 。这样在critic网络的输出端就能够直接得到该智能体各个动作的反事实Q值

















 2314
2314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









