






刚刚入门深度学习,仅谈论我自己对与autograd的一点认识,如有错误还请大佬指正
autograd 的数学基础就是链式法则,学过高数的应该多多少少有一定概念,这里也就不在多说了
Pytorch在autograd的时候主要分为两步走,第一步也就是forward pass 也就是前向传播,第二步是backward pass 也就是反向传播
在前向传播时主要干了两件事
- 一步一步计算网络的结果,并进行保存
- 会把当前进行操作的导函数保存到变量的grad_fn这个属性中,之前进行的操作的导函数保存到此变量的grad_fn属性的next_function属性中。
在进行反向传播的时候主要干三件事
- 根据储存的值和导函数算出梯度
- 在各自张量的grad属性中累计
- 根据链式法则计算出输入对于输出的导
用一个具体的例子来说明:
对于 这样一个公式 要求 w对于Z的导就是这样一个流程
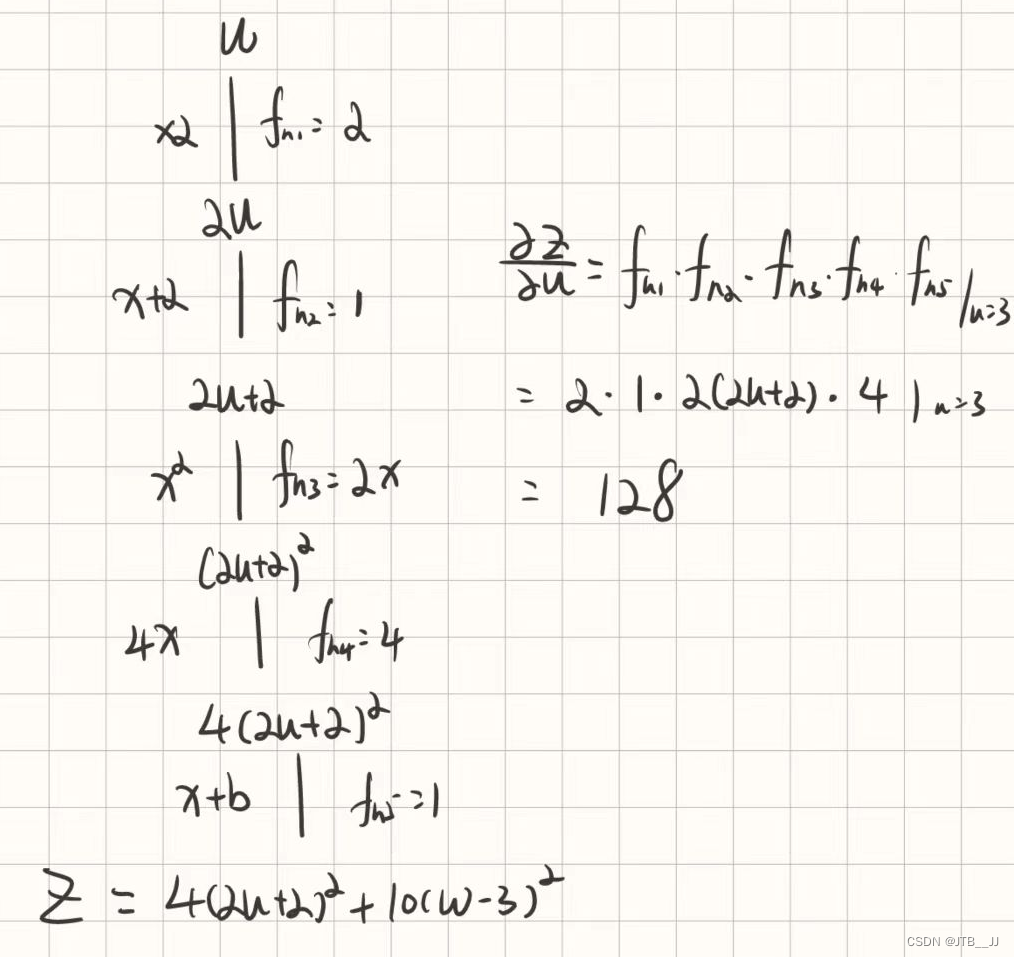
代码实现:
def net(x,y):
x = x*2
x = x+2
x = x**2
x = 4*x
y = y-3
y = y**2
y = y*10
return x+y
if __name__ =="__main__":
x = torch.tensor([3.0],requires_grad=True)
y = torch.tensor([6.0],requires_grad=True)
out = net(x,y)
out.backward()
print(x.grad)结果:![]()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









